一句话总结:Meta的研究者将Python程序的执行轨迹“喂”给大语言模型,教会它像真正的调试器一样“单步执行”、“设置断点”,甚至能“时光倒流”反推程序输入。
大家好,我是AI论文热榜的小编。今天给大家解读一篇来自Meta FAIR和约翰内斯·开普勒大学林茨分校的精彩论文。他们提出并实现了一个名为神经调试器的全新概念。简单来说,这是一个可以模拟Python程序交互式调试过程的大型语言模型。
想象一下,未来的AI编程助手不仅能生成代码,还能像资深程序员一样,在你思考“这里为什么报错”时,立刻模拟运行,告诉你变量x在第15行变成了什么值,甚至能推测出“什么样的输入会导致这个错误”。这就是这篇论文描绘的蓝图。
作者与机构
- Maximilian Beck (Johannes Kepler University Linz, Institute for Machine Learning)*
- Jonas Gehring (Meta FAIR CodeGen Team)
- Jannik Kossen (Meta FAIR CodeGen Team)
- Gabriel Synnaeve (Meta FAIR CodeGen Team) 等
(* 在Meta FAIR实习期间完成的工作)
引言:从静态代码理解到交互式执行模拟
传统的代码大模型(如Code Llama, StarCoder)主要擅长处理静态代码,即生成、补全、解释源码。但真正的编程和调试是一个动态过程。为了解决这个问题,此前的研究(如 Code World Model, CWM)已经开始训练模型学习程序的执行轨迹,使其成为一个“神经解释器”,能够预测程序从头到尾的逐行执行状态。
然而,论文作者敏锐地指出一个关键缺陷:真实的开发者调试程序时,从不会傻傻地从头跑到尾。我们会设置断点、单步步入函数、跳出循环、查看局部变量——这是一个交互式、非顺序的过程。
现有的“神经解释器”缺乏对这种交互式控制的建模能力。为此,研究者们提出了神经调试器。它不仅仅能顺序预测,更能根据开发者发出的调试指令(如“单步执行”、“运行到第30行”),精确地预测执行流将导向的下一个程序状态。
这项工作的核心价值在于:它为大语言模型注入了对程序动态执行语义的深刻理解,使其不仅能“看到”代码,更能“运行”和“操控”代码。这为未来构建具备自主调试和推理能力的AI编码智能体奠定了关键的“世界模型”基础。
核心方法:如何教会模型“调试”?
1. 将调试器建模为马尔可夫决策过程
研究者将调试过程形式化为一个马尔可夫决策过程:
- 状态 (State):程序在某一时刻的“快照”,包含当前执行的源代码行、局部变量字典、函数参数或返回值等。
- 动作 (Action):模仿真实调试器的命令,主要包括:
step_over:步过(不进入函数)或执行下一行。
 图:神经调试器与CWM的状态-动作结构对比。CWM的动作是固定的(执行下一行),而神经调试器的动作由用户控制,决定了状态的跳转方式。
图:神经调试器与CWM的状态-动作结构对比。CWM的动作是固定的(执行下一行),而神经调试器的动作由用户控制,决定了状态的跳转方式。
2. 构建“状态树”与定义跳转规则
从Python的sys.settrace捕获到的顺序执行轨迹中,研究者巧妙地重建了程序的调用栈树。这棵树记录了函数调用、返回的嵌套关系。
调试器的每个动作,都对应在这棵树上的一次移动。例如:
step_into:移动到当前节点的下一个子节点(进入函数)或兄弟节点(执行下一行)。breakpoint:在树上向前搜索,跳转到第一个包含目标源码行的节点。step_return:跳转到当前函数层级中的“返回”节点。
 图:状态树与转换规则。左:Python代码。中:由执行轨迹构建的正向状态树(缩进表示调用深度)。右:对应的逆向状态树。蓝色数字表示正/逆向树节点间的对应关系。
图:状态树与转换规则。左:Python代码。中:由执行轨迹构建的正向状态树(缩进表示调用深度)。右:对应的逆向状态树。蓝色数字表示正/逆向树节点间的对应关系。
3. 逆向执行:让模型“时光倒流”
这是本文最酷的创新点之一!传统的“反向调试器”需要先完整地正向执行一遍,记录所有状态,然后才能回退。而神经调试器可以直接从任意一个程序状态出发,预测可能导致这个状态的前置状态或输入。
研究者通过构建逆向状态树(将正向树反转并做适当调整)来实现这一点。这赋予了模型强大的反推能力。例如,给定一个排序函数的输出[1,2,3],模型可以推测出可能的原始输入[3,1,2]或[2,1,3]等。这对于测试用例生成、程序分析等任务极具价值。
4. 数据流水线与模型训练
要让模型学会这些,需要海量、结构化的训练数据。
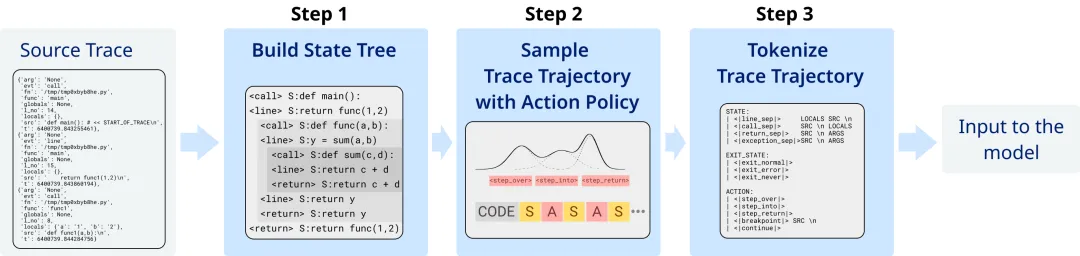 图:神经调试器数据生成流水线。从原始执行轨迹 -> 构建状态树 -> 按策略采样调试轨迹 -> 格式化为模型可理解的文本序列。
图:神经调试器数据生成流水线。从原始执行轨迹 -> 构建状态树 -> 按策略采样调试轨迹 -> 格式化为模型可理解的文本序列。
数据来源:基于CWM的工作,使用了来自超过120M个不同函数、21k个可执行仓库镜像和262k个代码竞赛解决方案的Python执行轨迹。
轨迹采样策略:为了让模型见识到各种调试场景,研究者设计了一个随机策略来模拟调试行为(例如,以一定概率选择“单步执行”还是“跳转到断点”)。这确保了数据的多样性。
模型格式:他们设计了一套正式的文本语法来序列化状态-动作对,使其可以被标准的自回归语言模型理解和生成。
 图:神经调试器数据的正式语法。定义了状态和动作如何被序列化为特殊的标记序列。
图:神经调试器数据的正式语法。定义了状态和动作如何被序列化为特殊的标记序列。
模型训练:
- 微调大模型:对一个已预训练过代码执行轨迹的 32B 参数 CWM 模型,使用纯调试器轨迹数据进行了 50B token 的微调。
- 从头训练小模型:从头开始预训练了一个 1.8B 参数的 Transformer 模型,使用了 150B token 的调试器轨迹数据。
实验结果:模型表现如何?
1. 基础能力:预测下一个状态
研究者首先评估了模型在给定当前状态和调试动作后,预测下一个状态的准确性。
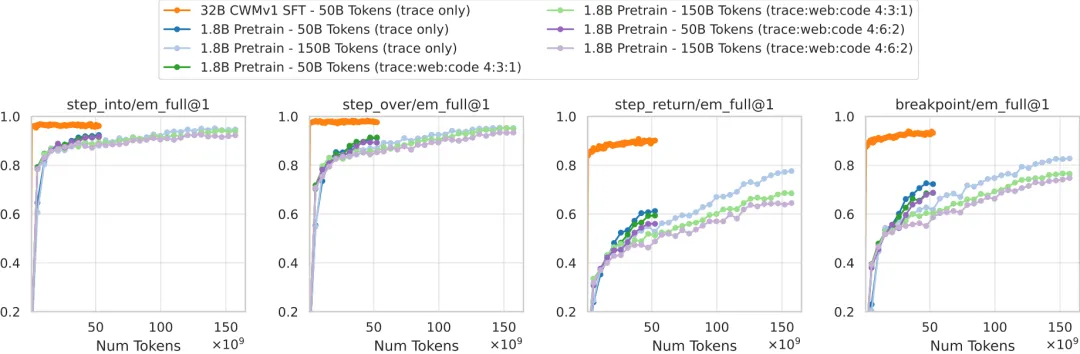 图:在函数级验证集上,不同模型随训练步数增加,执行各类调试动作后预测下一个状态的准确率变化。
图:在函数级验证集上,不同模型随训练步数增加,执行各类调试动作后预测下一个状态的准确率变化。
关键发现:
- “单步”动作比“跳转”动作更容易学:
step_into、step_over这类单步动作的准确率很快达到90%以上,而breakpoint、step_return这类需要跨越多行的跳转动作学习起来更慢,但最终也能达到不错水平。 - 小模型也能成为不错的调试器:从头训练的1.8B小模型,在经过足够数据训练后(150B tokens),其单步动作的准确率与微调后的32B大模型差距不大。这说明神经调试器的能力主要来自于对执行轨迹数据的学习,而非单纯的模型规模。
- 逆向执行是可学习的:无论是大模型还是小模型,在逆向执行预测任务上,准确率都随着训练稳步提升,证明了让模型学习“时光倒流”是可行的。
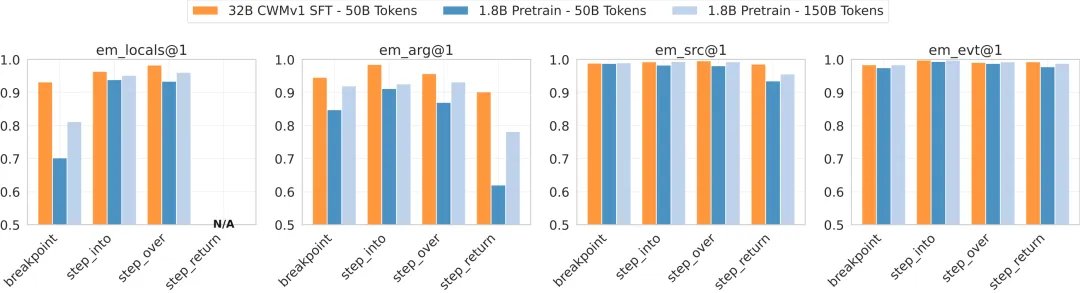 图:针对函数级数据,按状态成分拆解的预测准确率。
图:针对函数级数据,按状态成分拆解的预测准确率。em_src(源码行)和em_evt(事件类型)预测得最好;em_locals(局部变量)和em_arg(参数)是主要错误来源。
预测错误分析:模型最容易出错的地方在于预测局部变量的精确值,而预测下一行要执行的源代码和事件类型则非常可靠。这表明模型先掌握了程序的控制流,再学习复杂的数据流变化。
2. 高级能力:输入/输出预测(CruxEval基准测试)
为了检验模型是否真正理解了程序语义,研究者在著名的 CruxEval 基准上进行了测试。该基准要求模型:1) 给定代码和输入,预测输出;2) 给定代码和输出,预测输入。
他们将CruxEval任务巧妙地转化为了神经调试器的“动作”:
- 输出预测:相当于让模型执行一个
breakpoint(断点)动作,直接跳到函数返回的那一行,并预测返回值。 - 输入预测:相当于让模型执行一个
inv_step_call(逆向步入调用)动作,反推出函数调用前的输入参数。
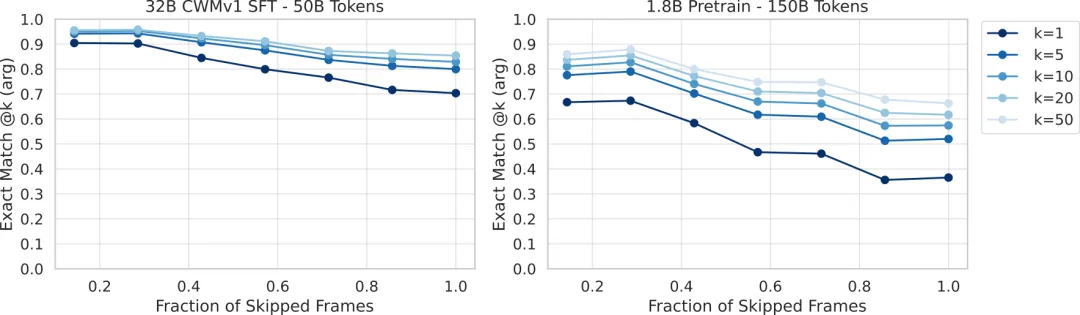 表:CruxEval基准测试上的表现(pass@1)。神经调试器格式显著提升了模型对程序执行的理解能力。
表:CruxEval基准测试上的表现(pass@1)。神经调试器格式显著提升了模型对程序执行的理解能力。
惊艳的结果:
- 微调后的32B神经调试器,在输出预测任务上达到了83.2% 的准确率,比原版CWM模型(58.1%)提升了超过25个百分点!
- 即使是从头训练的1.8B小模型,在输出预测上也达到了57.7% 的准确率,显著优于许多未专门学习执行轨迹的同规模甚至更大规模的通用代码模型。
- 在更具挑战性的输入预测任务上,模型也展现出了强大能力(32B模型达到66.5%),证明了其逆向推理的有效性。
预测准确性随“跨度”增加而下降:研究者还测试了“一步到位”预测和“多步交互后”预测的区别。如图6所示,当要求模型直接预测函数最终的输入/输出(相当于“预测跨度”为1)时,难度最大,准确率最低。如果允许模型通过多个step_over动作逐步接近目标(“预测跨度”变小),准确率会显著提升。这模拟了真实调试中“逐步逼近问题点”的过程。
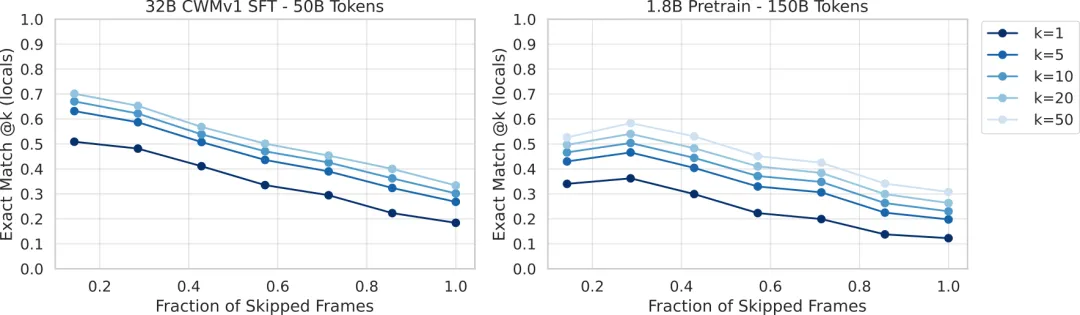 图:输入预测准确率随预测跨度(需跳过的中间状态比例)的变化。跨度越大(越接近1),预测越难;通过采样多个结果(@k)可以缓解这一问题。
图:输入预测准确率随预测跨度(需跳过的中间状态比例)的变化。跨度越大(越接近1),预测越难;通过采样多个结果(@k)可以缓解这一问题。
结论与展望
这项工作成功地将交互式程序调试的过程“编译”进了大语言模型的参数中,创造出了第一个真正意义上的“神经调试器”。它不仅支持传统调试器的所有核心操作,还开创性地实现了近似的逆向程序执行预测。
核心贡献总结:
- 概念创新:首次提出并形式化了“神经调试器”,将其建模为MDP。
- 方法创新:设计了从执行轨迹生成调试器交互数据的数据流水线、状态树结构以及支持正/逆向执行的统一文本格式。
- 实证验证:通过微调和预训练实验,证明了不同规模的模型都能有效学习成为神经调试器,并在CruxEval基准上取得了突破性表现。
未来方向:
- 智能体编程:将神经调试器作为AI编码智能体的“世界模型”,使其能自主规划调试步骤、定位并修复bug。
- 数据生成优化:设计更智能的调试动作采样策略,模仿人类调试习惯,并扩展到更多编程语言。
- 逆向调试增强:开发更好的评估指标来处理逆向预测中的多解歧义问题。
- 对象表示:研究如何更高效地在大模型中表示复杂的Python对象(如大型数据结构)。
神经调试器代表了一条通往具备深度程序执行理解能力的AI系统的清晰路径。它不仅仅是一个研究原型,更预示着下一代AI编程工具的形态——能够理解、模拟、甚至操控程序运行时的动态行为,从而在代码生成、审查、测试和调试的各个环节带来革命性的提升。
这篇论文的代码、模型和数据是否开源,将是业界关注的下一个焦点。无论如何,它已经为“让AI真正理解代码在做什么”这个宏伟目标,迈出了坚实而巧妙的一步。
本文由AI论文热榜根据论文《Towards a Neural Debugger for Python》编译解读,想要获取更详细的信息,请查阅原论文。
关注「AI论文热榜」,紧跟最前沿、最硬核的AI技术进展!
如有论文辅导、项目开发等需求,请联系小编,微信号: GCgcong
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
