- 超级块:存储分区操作系统版本、块大小、文件系统;
- 块位图(block bitmap):占用1 block,每个比特位表示一个数据块是否被标记使用;1:已使用,0:未使用;
- inode 位图(inode bitmap):占用1 block,每一个比特位表示一个inode节点。1:已使用,0:未使用;
- inode节点:分为文件属性部分和数据指针部分。数据指针指向数据块。
- 数据块:存储文件的内容。对于普通文件而言,数据块中保存的是文件的具体内容;而对于目录文件而言,它的数据块中保存的是目录项(什么是目录项?请往下看)。
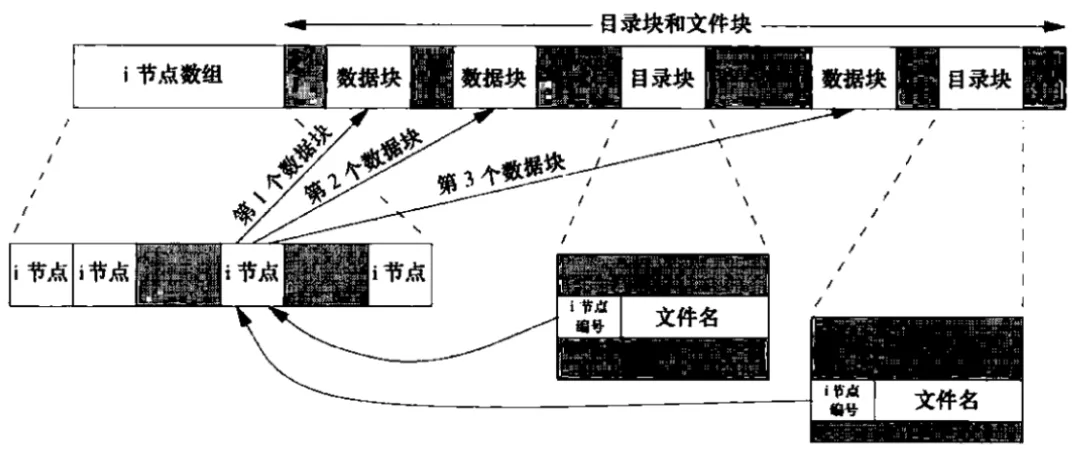
普通文件结构:
由图可以看出,对于普通文件类型的inode, 它所指向的数据块里保存的是文件的具体内容。
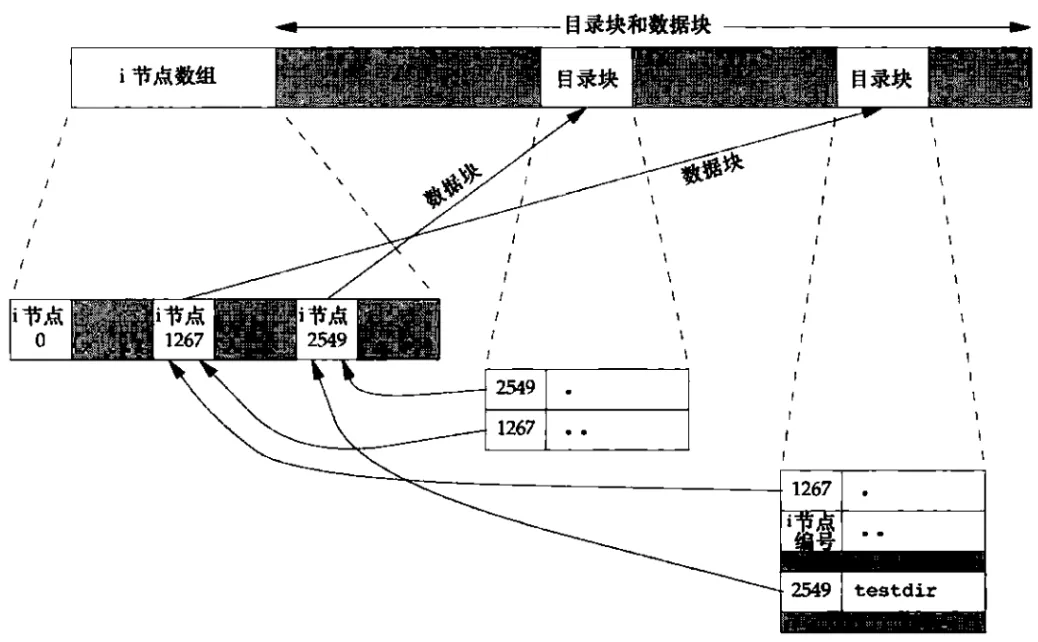
目录文件结构:(比如创建/testdir目录以后)
由图可见,对于目录类型的inode,它所指向的是目录块(目录块也属于数据块),目录块里保存的是一个一个的目录项,一个具体的目录项里保存的是inode节点号和目录的对应关系。目录项用于目录和
文件查找。
linux内核里分别用struct inode和struct dentry来表示inode结构和目录项结构。
文件查找:
以/home/john/kernel.c为例,我们来看看在文件系统中通过文件名搜索某个文件的全过程:
(1)找到/的inode,比如是2。由于inode 2是目录类型,所以inode 2指向的数据块里保存的都是dentry(也就是目录项)
(2)找到home对应的inode,比如是12。由于inode 12也是目录类型,所以inode 12指向的数据块里保存的也是dentry
(3)找到john对应的inode,比如是112。由于inode 112也是目录类型,所以inode 112指向的数据块里保存的也是dentry
(4)找到kernel.c对应的inode,比如是1112。由于inode 1112是文件类型,所以到这里就寻找结束了。下一步如果需要读取数据,可以从inode 1112指向的数据块里读取文件内容。
以上就是文件和目录在文件系统化的磁盘上的存储格式。接下来,我们来看看linux内核把某个文件加载到内存的时候做了什么事情。
二、文件缓存:快慢平衡和延迟满足的产物
当我们在linux应用程序代码里对某个文件执行read()的时候,会陷入linux内核的read()系统调用,这个时候内核就开始了将数据从磁盘到内存的加载过程了。
对于文件的加载而言,秉承着尽量满足进程需要和尽量节省物理内存的双重考量,linux内核是按需加载的。我们知道一般情况下,一个物理块是4K。所以,内核在加载的时候,会把read()的length换算成4k大小的块,然后申请相应数量的pages,接着调用io子系统把磁盘文件的相应offset处的数据加载到内存(也就是page cache)中,最后再copy到应用层的read buffer中。
所以,我们说应用层的read()是【双重拷贝】,与之相对应的是性能更高的mmap(),它只需要【一次拷贝】,这个我们后续再讲。
到此为止我们明白了,文件缓存就是磁盘文件在内存里的缓存。
如果你认为内核仅仅如此,那你就太小瞧内核了。应用层的需求千变万化,内核必须做万全的考量。在内核中,除了这种常规的文件加载之外,内核还提供了预取的机制。比如你的应用程序现在正在从某个文件读取4096个字节(刚好一个page),那么内核判断你从该文件读取接下来的文件内容的概率也很大,所以,它会提供预取机制,在你的应用层还未针对后续的offset调用read()读取的时候,可能内核就已经把数据准备好并放置到文件缓存了,这样可以节省io时间,提高文件读取的速度。
但是应用层的读取不一定全部是顺序读,还可能会有随机读取,比如lseek()的调用。当应用层调用lseek()的时候,就意味着前面的预取完全失效,内核底层会实打实地重新调度io去读取lseek()指定的文件内存,预取失效会在一定程度上造成性能的瓶颈。所以,如果你的应用有性能瓶颈,那么先看看程序里面对文件的读取是顺序读取还是随机读取,如果是随机读取,那就就要引起注意了。
到这里,我们该总结一下了,为了解决磁盘读写和内存读写的不平衡性、加速文件的读取速度,linux内核会把文件缓存到内存里,这部分内存会被统计到/proc/meminfo输出的Cached分类里。(在我的linxu系统下,Cached占用的内存可不少唷)

但是内存是有限的,而且也没必要缓存整个文件,只需要当文件的某部分内容真正被访问到时,再将这部分内容调入内存缓存起来就可以了,把对需求的满足延迟到最后一刻,很懒很实用。
linux内核会在内存里重造磁盘文件,然而为了节省内存,又不会简单机械地把文件的所有内容全部缓存到内存,那内核里势必要有一种机制来管理某个文件相关的文件缓存,考虑到文件缓存都是一个一个的page,所以就涉及到对这些pages的管理。linux内核(我研究的内核版本是4.9.229)通过基数树来对某个文件的所有page cache进行管理。
最后,我们想一想linux内核要做到对文件缓存的管理,需要考虑哪些细节呢?
- 这种管理应该是针对某个文件的;
- linux内核对文件并非全部缓存,而是按需缓存的,所以,对这些不一定是按顺序排列的pages要怎么来管理呢?链表吗?数组吗?
- 随着对文件的不断操作,这些pages的状态也发生了变化,有些是PG_dirty,有些是PG_writeback,不同的状态会影响回收,为了快速的回收,又要做哪些设计呢?
带着以上的问题,我们接下来讲一讲linux文件缓存管理之基数树的原理和实现。
叮!您的新一批技术干货正在派送中!先点击【关注】,收取更顺利哦~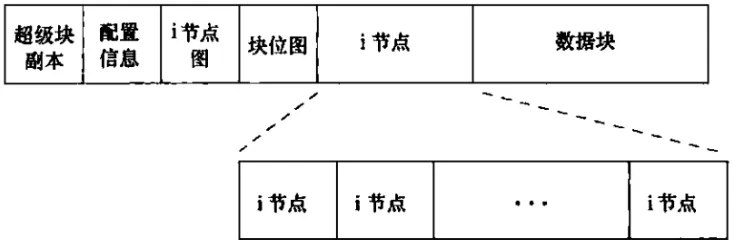
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
