👋 大家好!欢迎来到我们全新的《数据处理》系列专栏。
在如今这个“言必称AI,动辄大模型”的时代,很多人急于追求酷炫的算法,却往往忽略了数据科学的灵魂——统计学。拿到一份数据,如果不先做EDA(Exploratory Data Analysis,探索性数据分析),不了解数据的分布特征,再复杂的模型也只会是“Garbage In, Garbage Out”(垃圾进,垃圾出)。
因此,本系列的第一阶段,我们将用三节内容,带大家学习统计学基础。第一节内容,我们从最基础、却最能反映业务现状的描述性统计(Descriptive Statistics)开始。这不仅仅是算个平均数那么简单,我们将带你从集中趋势、离中趋势、数据形状三个维度,外加Python实战可视化,彻底看透一堆杂乱无章的数据。👇
一、 动手之前,先摸清数据的“底细”(数据分类)
不同类型的数据,决定了后续能使用什么样的数据处理方法和机器学习模型。在统计学和数据处理中,数据通常分为两大类四个层级:
1. 定性数据(类别数据 / Categorical Data)
用来描述事物属性,不能进行加减乘除。
- 定类数据(Nominal): 只有类别的区别,没有高低大小之分。比如:性别(男/女)、商品类目(3C/美妆/服装)、城市。处理方式: 建模时通常需要做独热编码(One-Hot Encoding)。
- 定序数据(Ordinal): 类别之间有顺序或等级之分,但差距无法精确量化。比如:用户满意度(非常不满意/一般/非常满意)、会员等级(青铜/白银/黄金)。处理方式: 建模时通常做标签编码(Label Encoding)。
2. 定量数据(数值数据 / Numerical Data)
用来衡量事物大小或多少,可以进行严格的数学运算。
- 离散型数据(Discrete): 只能取整数,通常是“数”出来的。比如:每天网页的访问人数、用户的购买次数。
- 连续型数据(Continuous): 可以在一定区间内取任意值(包含小数),通常是“量”出来的。比如:用户的停留时长、订单金额、身高等。
💡 业务启示: 在日常业务中,将“连续数据”转化为“定序数据”(即数据分箱/离散化,例如将年龄数值转化为“青年/中年/老年”类别),是特征工程中极常用的手段。
二、 寻找数据的“重心”:集中趋势
当我们拿到一列连续型数值时(比如100万个用户的客单价),最想知道的是:大家的普遍水平是多少?
1. 算术平均数(Mean)与 加权平均数(Weighted Mean)
- 加权均值: 考虑到不同数据点的重要性不同。比如计算公司的整体毛利率,不能把各个部门的毛利率简单相加除以部门数,而是要以各部门的“营收占比”作为权重(Weight)来计算。
- 致命弱点: 极易受极端值(Outliers)影响。你和马云的平均资产是几百亿,但这毫无业务参考价值。
2. 中位数(Median)
- 定义: 将所有数据从小到大排列后,处于正中间位置的数(即50%分位数)。
- 优势: 极度抗干扰!不受极端值影响。在描述国民收入、大城市的房价时,中位数永远比均值更有说服力。
3. 众数(Mode)
- 应用场景: 除了数值,它更常用于定性数据的描述。比如统计今天卖得最好的是哪个尺码的鞋子。
三、 衡量数据的“波动”:离中趋势
假设A、B两个电商平台的商家平均日流水都是1万元。但A平台所有商家都是1万左右;B平台少数头部主播日流水百万,底部商家开不了张。光看均值,你会被骗。这就需要衡量数据的“离中趋势”。
1. 极差(Range)
最大值减去最小值。最粗略的标准,同样容易受极端值影响。
2. 方差(Variance)与 标准差(Standard Deviation)
- 标准差(Std): 方差的平方根(为了将单位还原成与原数据一致)。
- 业务意义: 标准差越大,说明数据波动越大、风险越高(金融领域常用来衡量波动率);标准差越小,说明数据越集中、越稳定。
3. 四分位数(Quartiles)与 四分位距(IQR)—— 寻找异常值的利器
- 我们将数据切成四等份,得到 Q1(25%)、Q2(50%,中位数)、Q3(75%)。
- IQR(Interquartile Range):
IQR = Q3 - Q1。它代表了中间最核心的50%数据的跨度。 - 👑 统计学经典应用:1.5 IQR 法则(箱线图原理)
- 凡是大于上限或小于下限的数据,在统计学上我们通常将其判定为“异常值(Outliers)”!
四、 刻画数据的“长相”:分布形状(偏度与峰度)
除了重心和波动,高级的数据分析师还会关注数据的分布形态。
1. 偏度(Skewness):数据是对称的吗?
偏度衡量了数据分布的不对称性。
- 偏度 = 0: 绝对对称分布(如标准的正态分布),此时 均值 = 中位数 = 众数。
- 偏度 > 0(右偏 / 正偏): 尾巴拖在右边。说明大部分数据集中在左侧较低的数值,但有少数极高的极端值把“均值”往右拉。(特征:均值 > 中位数。绝大多数人的收入分布就是典型的右偏!)
- 偏度 < 0(左偏 / 负偏): 尾巴拖在左边。(特征:均值 < 中位数。)
2. 峰度(Kurtosis):极端事件多不多?
峰度衡量了数据分布曲线顶端的“尖锐”程度和尾部的“厚度”。
- 在实际应用中,我们常看“超额峰度”(相对于正态分布)。
- 正峰度(尖峰厚尾): 说明数据中间更集中,且两端(极端值)比正态分布更多。金融市场收益率经常呈现“尖峰厚尾”,这意味着“黑天鹅”(极端行情)发生的概率比我们想象的要大。
五、 Python实战综合演练:一键生成全维度数据体检报告 💻
理论必须落地。接下来,我们将用Python模拟一份真实的“电商用户客单价”数据,并结合 pandas 和可视化库 seaborn,全方位展示今天学习的所有指标!
📝 实战代码与解析:
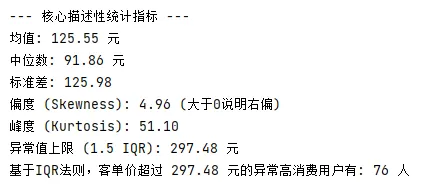
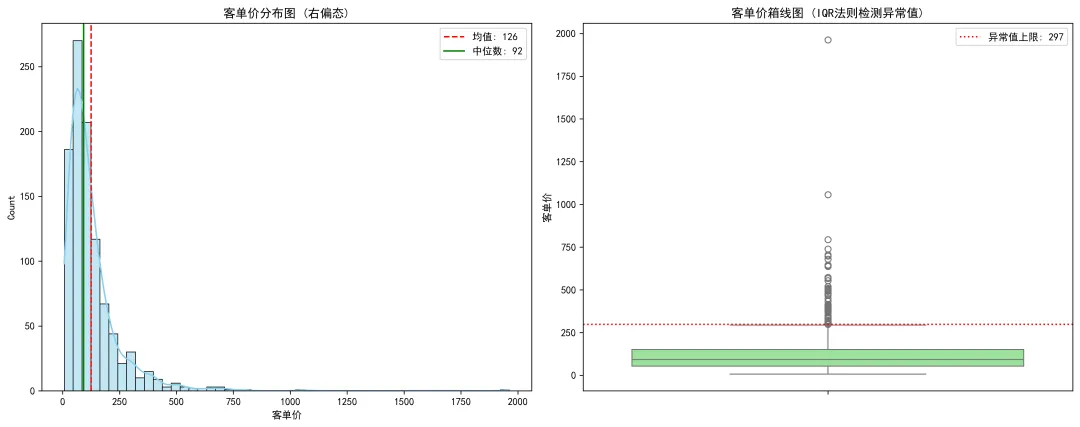
# 导入强大的数据处理和可视化库import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# 设置中文字体,防止图表中的中文显示为方块plt.rcParams['font.sans-serif'] =['SimHei'] # Windows用黑体plt.rcParams['axes.unicode_minus'] = False# 正常显示负号# ==========================================# 1. 模拟业务数据:生成 1000 个用户的客单价数据# 我们使用对数正态分布来模拟,因为它非常符合真实世界中“右偏”的收入/消费数据# ==========================================np.random.seed(42) # 保证每次运行结果一致# 生成右偏数据,并四舍五入保留两位小数order_amounts = np.round(np.random.lognormal(mean=4.5, sigma=0.8, size=1000), 2)df = pd.DataFrame({'客单价': order_amounts})print(f"数据量: {len(df)} 条")# ==========================================# 2. 计算所有描述性统计指标# ==========================================mean_val = df['客单价'].mean()median_val = df['客单价'].median()std_val = df['客单价'].std()skewness = df['客单价'].skew() # 偏度kurtosis = df['客单价'].kurt() # 峰度# 计算四分位数和上限Q1 = df['客单价'].quantile(0.25)Q3 = df['客单价'].quantile(0.75)IQR = Q3 - Q1upper_bound = Q3 + 1.5 * IQRprint("\n--- 核心描述性统计指标 ---")print(f"均值: {mean_val:.2f} 元")print(f"中位数: {median_val:.2f} 元")print(f"标准差: {std_val:.2f}")print(f"偏度 (Skewness): {skewness:.2f} (大于0说明右偏)")print(f"峰度 (Kurtosis): {kurtosis:.2f} ")print(f"异常值上限 (1.5 IQR): {upper_bound:.2f} 元")# 统计异常值数量outliers_count = len(df[df['客单价'] > upper_bound])print(f"基于IQR法则,客单价超过 {upper_bound:.2f} 元的异常高消费用户有: {outliers_count} 人")# ==========================================# 3. 数据可视化:直方图与箱线图# ==========================================# 创建一个 1行2列 的画板fig, axes = plt.subplots(1, 2, figsize=(15, 6))# 图1:直方图与核密度估计曲线 (看分布形状)sns.histplot(df['客单价'], bins=50, kde=True, ax=axes[0], color='skyblue')axes[0].axvline(mean_val, color='red', linestyle='--', label=f'均值: {mean_val:.0f}')axes[0].axvline(median_val, color='green', linestyle='-', label=f'中位数: {median_val:.0f}')axes[0].set_title('客单价分布图 (右偏态)')axes[0].legend()# 图2:箱线图 (看离散程度与异常值)sns.boxplot(y=df['客单价'], ax=axes[1], color='lightgreen')axes[1].axhline(upper_bound, color='red', linestyle=':', label=f'异常值上限: {upper_bound:.0f}')axes[1].set_title('客单价箱线图 (IQR法则检测异常值)')axes[1].legend()plt.tight_layout()plt.show()
📊 代码运行结果解读:
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
