Linux 内核 Call Trace 完全解析指南
- 2026-06-26 17:58:11
🔧从原理到实战,掌握内核崩溃问题的诊断与解决
📋 目录速览

🎯 什么是 Call Trace
定义
Call Trace(调用栈跟踪)是 Linux 内核在发生错误、警告或崩溃时,打印出的函数调用链路信息。它显示了程序执行到出错点的完整路径。
为什么会出现 Call Trace?

Call Trace 的作用

📝 Call Trace 的类型
1. Kernel Oops
特征:内核遇到错误但尝试继续运行
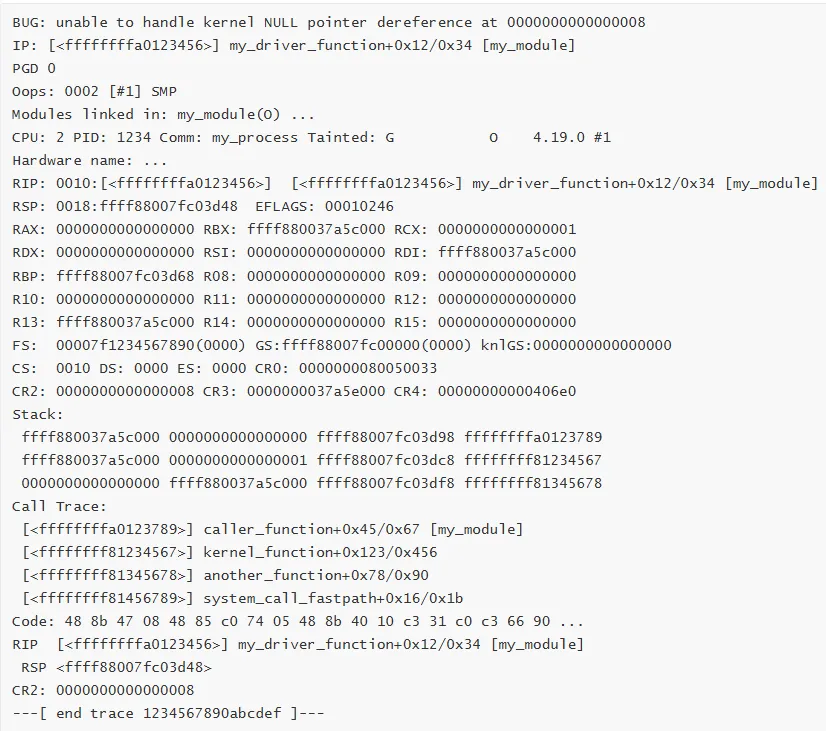
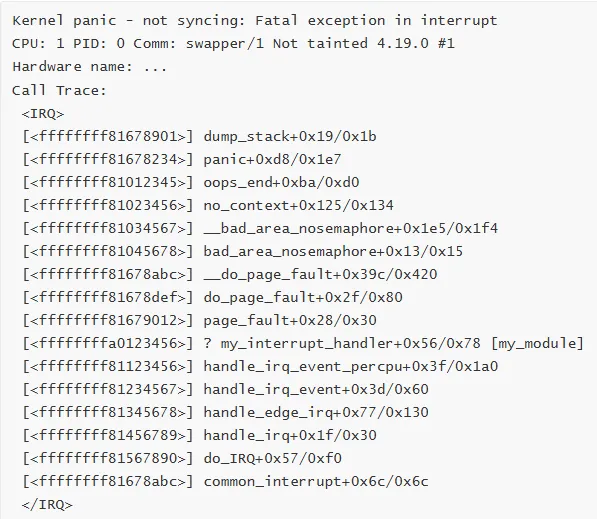
2. Kernel Panic
特征:内核崩溃,系统停止运行
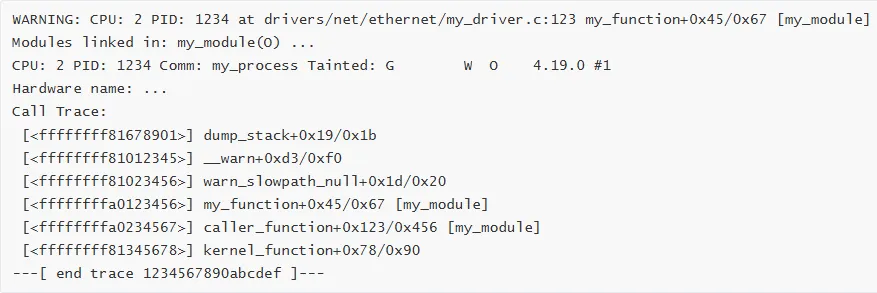
3. Warning
特征:内核警告,但继续运行
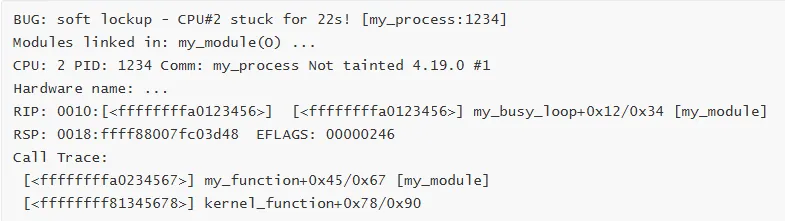
4. Soft Lockup
特征:CPU 长时间不响应(通常超过 20 秒)
5. Hard Lockup
特征:中断被长时间禁用
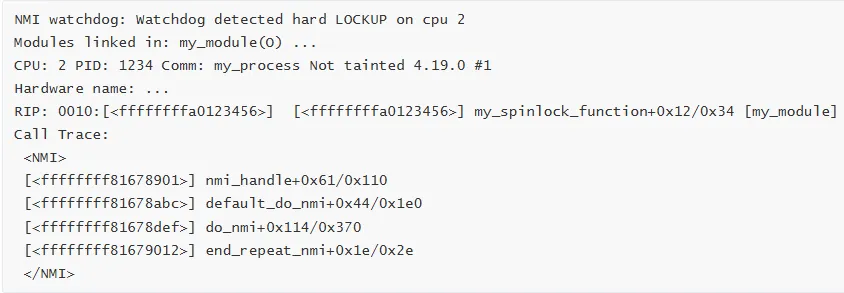
🔍 如何读懂 Call Trace
Call Trace 的结构

解读关键信息
1. 错误类型
常见错误类型:• NULL pointer dereference空指针解引用,访问了地址 0 或接近 0 的内存• general protection fault一般保护错误,非法内存访问• unable to handle kernel paging request内核分页请求失败,访问了无效地址• divide error除零错误• invalid opcode无效指令• stack segment fault栈段错误
2. 地址信息
at 0000000000000008↑错误发生的内存地址• 0x00000000 附近:空指针解引用• 0xffff8800xxxxxxxx:内核空间地址(x86_64)• 0x00007fxxxxxxxxxx:用户空间地址(x86_64)
3. 指令指针(RIP/IP)

含义:
错误发生在
my_module模块的my_function函数中距离函数起始位置 0x12(18)字节
函数总大小 0x34(52)字节
4. CPU 和进程信息
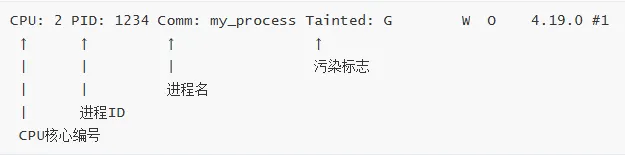
Tainted 标志含义:
G - 所有模块都有 GPL 许可P - 加载了专有模块F - 模块被强制加载S - SMP 内核在非 SMP 硬件上运行R - 模块被强制卸载M - 机器检查异常B - 页面释放函数报告错误U - 用户空间应用程序请求的污染D - 内核最近死过A - ACPI 表被覆盖W - 触发了警告C - 加载了分段模块I - 使用了不安全的平台固件O - 加载了外部模块(out-of-tree)E - 未签名的模块被加载L - 发生了软锁定K - 内核已被实时补丁
5. 寄存器状态

x86_64 寄存器用途:
RAX - 累加器,函数返回值RBX - 基址寄存器RCX - 计数器RDX - 数据寄存器RSI - 源索引(第2个参数)RDI - 目的索引(第1个参数)RBP - 栈帧指针RSP - 栈指针R8-R15 - 通用寄存器RIP - 指令指针
6. 调用栈(Call Trace)

阅读顺序:
从上到下:从出错点到调用链的起点
最上面的函数是直接出错的位置
往下是调用链路
特殊标记:
<IRQ> - 中断上下文</IRQ> - 中断上下文结束<NMI> - 不可屏蔽中断</NMI> - NMI 结束? - 不确定的调用
🛠️ 调试工具与方法
1. addr2line - 地址转行号
# 将地址转换为源代码位置addr2line -e vmlinux -f-i <address># 示例addr2line -e vmlinux -f-i ffffffff81234567# 输出my_function/usr/src/linux-4.19.0/drivers/net/my_driver.c:123# 对于模块addr2line -e my_module.ko -f-i 0x123456
参数说明:
-e: 指定可执行文件或模块-f: 显示函数名-i: 显示内联函数
2. objdump - 反汇编
# 反汇编内核模块objdump -dS my_module.ko > my_module.asm# 查找特定函数objdump -dS my_module.ko | grep-A50"<my_function>:"# 查看特定地址的代码objdump -dS--start-address=0x123456 --stop-address=0x123500 my_module.ko
示例输出:

3. gdb - 调试器
# 加载内核符号gdb vmlinux# 加载模块符号(gdb) add-symbol-file my_module.ko 0xffffffffa0000000# 查看函数源码(gdb) list my_function# 查看特定地址(gdb) x/10i 0xffffffffa0123456# 反汇编函数(gdb) disassemble my_function# 查看结构体(gdb) ptype struct my_struct
4. crash - 内核崩溃分析工具
# 分析 vmcorecrash vmlinux vmcore# 常用命令crash> bt # 显示调用栈crash> log # 查看内核日志crash> ps# 查看进程列表crash> files # 查看打开的文件crash> vm # 查看虚拟内存crash> struct task_struct <address> # 查看结构体crash> dis <function> # 反汇编函数crash> mod # 查看加载的模块
5. decode_stacktrace.sh - 自动解析
# 内核自带的脚本./scripts/decode_stacktrace.sh vmlinux /path/to/modules < call_trace.txt# 示例输入[<ffffffffa0123456>] my_function+0x12/0x34 [my_module]# 输出my_function (/path/to/my_driver.c:123)
6. 使用 ftrace 追踪
# 启用函数追踪echofunction > /sys/kernel/debug/tracing/current_tracer# 设置追踪的函数echo my_function > /sys/kernel/debug/tracing/set_ftrace_filter# 启用追踪echo1 > /sys/kernel/debug/tracing/tracing_on# 查看追踪结果cat /sys/kernel/debug/tracing/trace# 停止追踪echo0 > /sys/kernel/debug/tracing/tracing_on
7. kgdb - 内核调试器
# 内核启动参数kgdboc=ttyS0,115200 kgdbwait# 在另一台机器上连接gdb vmlinux(gdb) target remote /dev/ttyS0(gdb) continue# 设置断点(gdb) break my_function(gdb) continue# 单步执行(gdb) step(gdb) next
🔬 常见问题分析
1. 空指针解引用
典型 Call Trace:
BUG: unable to handle kernel NULL pointer dereference at 0000000000000008RIP: [<ffffffffa0123456>] my_function+0x12/0x34 [my_module]
原因分析:
// 问题代码structmy_struct*ptr=NULL;intvalue=ptr->field; // 访问 NULL 指针的成员
调试步骤:
# 1. 使用 addr2line 定位addr2line -e my_module.ko -f-i 0x123456# 2. 查看反汇编objdump -dS my_module.ko | grep-A20"<my_function>:"# 3. 分析寄存器# 如果 RAX=0,且代码是 mov 0x8(%rax),%rbx# 说明在访问 NULL+8 的位置
解决方案:
// 修复代码structmy_struct*ptr=get_my_struct();if (ptr==NULL) {pr_err("Failed to get struct\n");return-EINVAL;}intvalue=ptr->field; // 安全访问
2. Use-After-Free
典型 Call Trace:
BUG: unable to handle kernel paging request at ffff880012345678RIP: [<ffffffffa0123456>] my_function+0x12/0x34 [my_module]
原因分析:
// 问题代码structmy_struct*ptr=kmalloc(sizeof(*ptr), GFP_KERNEL);kfree(ptr);ptr->field=10; // 使用已释放的内存
调试方法:
# 启用 KASAN(Kernel Address Sanitizer)CONFIG_KASAN=y# 启用 SLUB 调试slub_debug=FZPU# 使用 kmemleak 检测内存泄漏echo scan > /sys/kernel/debug/kmemleakcat /sys/kernel/debug/kmemleak
解决方案:
// 修复代码structmy_struct*ptr=kmalloc(sizeof(*ptr), GFP_KERNEL);ptr->field=10;kfree(ptr);ptr=NULL; // 释放后置空
3. 死锁
典型 Call Trace:
BUG: soft lockup - CPU#2 stuck for 22s! [my_process:1234]RIP: [<ffffffffa0123456>] my_spinlock_function+0x12/0x34 [my_module]
原因分析:
// 问题代码spin_lock(&lock_a);spin_lock(&lock_b); // 另一个线程可能以相反顺序获取锁
调试方法:
# 启用死锁检测CONFIG_PROVE_LOCKING=yCONFIG_DEBUG_LOCK_ALLOC=yCONFIG_LOCKDEP=y# 查看锁的持有情况cat /proc/lockdepcat /proc/lockdep_stats# 使用 SysRq 查看所有 CPU 的调用栈echo l > /proc/sysrq-triggerdmesg | tail -100
解决方案:
// 修复代码 - 统一锁的获取顺序voidfunction1() {spin_lock(&lock_a);spin_lock(&lock_b);// ...spin_unlock(&lock_b);spin_unlock(&lock_a);}voidfunction2() {spin_lock(&lock_a); // 相同的顺序spin_lock(&lock_b);// ...spin_unlock(&lock_b);spin_unlock(&lock_a);}
4. 栈溢出
典型 Call Trace:
BUG: stack guard page was hit at ffff88007fc03000RIP: [<ffffffffa0123456>] my_recursive_function+0x12/0x34 [my_module]
原因分析:
// 问题代码voidmy_function() {charbuffer[8192]; // 栈上分配大数组// 或者无限递归my_function();}
调试方法:
# 检查栈使用情况CONFIG_DEBUG_STACK_USAGE=y# 查看栈使用cat /proc/<pid>/stack
解决方案:
// 修复代码voidmy_function() {char*buffer=kmalloc(8192, GFP_KERNEL); // 使用堆内存if (!buffer)return-ENOMEM;// ...kfree(buffer);}
5. 中断上下文错误
典型 Call Trace:
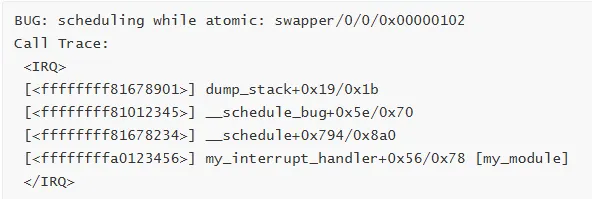
原因分析:
// 问题代码 - 在中断中睡眠irqreturn_tmy_interrupt_handler(intirq, void*dev_id){msleep(100); // 错误:中断中不能睡眠returnIRQ_HANDLED;}
解决方案:
// 修复代码 - 使用工作队列structwork_structmy_work;irqreturn_tmy_interrupt_handler(intirq, void*dev_id){schedule_work(&my_work); // 调度工作队列returnIRQ_HANDLED;}voidmy_work_handler(structwork_struct*work){msleep(100); // 在进程上下文中可以睡眠}
6. 内存越界
典型 Call Trace:
BUG: KASAN: slab-out-of-bounds in my_function+0x12/0x34 [my_module]Write of size 4 at addr ffff880012345678 by task my_process/1234
原因分析:
// 问题代码char*buffer=kmalloc(10, GFP_KERNEL);buffer[15] ='x'; // 越界写入
调试方法:
# 启用 KASANCONFIG_KASAN=y# 启用 SLUB 调试CONFIG_SLUB_DEBUG=yslub_debug=FZPU
解决方案:
// 修复代码char*buffer=kmalloc(20, GFP_KERNEL); // 分配足够的空间if (!buffer)return-ENOMEM;buffer[15] ='x'; // 安全访问
📊 实战案例
案例 1:网卡驱动空指针
Call Trace:
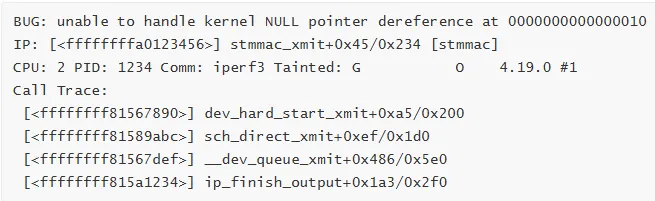
分析步骤:
定位源码位置
addr2line -e stmmac.ko -f-i 0x123456# 输出:stmmac_xmit# /drivers/net/ethernet/stmicro/stmmac/stmmac_main.c:2345
查看源码
// stmmac_main.c:2345staticnetdev_tx_tstmmac_xmit(structsk_buff*skb, structnet_device*dev){structstmmac_priv*priv=netdev_priv(dev);structdma_desc*desc=priv->dma_tx+entry; // 可能 priv->dma_tx 为 NULLdesc->des0=skb->data; // 空指针解引用}
查看寄存器
RAX: 0000000000000000 ← priv->dma_tx 的值RDI: ffff880037a5c000 ← priv 的地址
根本原因
priv->dma_tx未初始化或初始化失败在
stmmac_open()中 DMA 分配失败但未检查
修复方案
staticnetdev_tx_tstmmac_xmit(structsk_buff*skb, structnet_device*dev){structstmmac_priv*priv=netdev_priv(dev);// 添加检查if (unlikely(!priv->dma_tx)) {dev_err(priv->device, "DMA TX not initialized\n");dev_kfree_skb(skb);returnNETDEV_TX_OK;}structdma_desc*desc=priv->dma_tx+entry;desc->des0=skb->data;}
案例 2:连接跟踪表死锁
Call Trace:
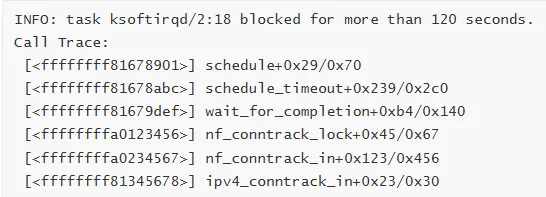
分析步骤:
识别问题
任务被阻塞超过 120 秒
在连接跟踪锁上等待
查看所有 CPU 状态
echo l > /proc/sysrq-triggerdmesg | tail -200
发现死锁
CPU 0: 持有 lock_a,等待 lock_bCPU 2: 持有 lock_b,等待 lock_a
根本原因
两个 CPU 以不同顺序获取锁
形成循环等待
修复方案
// 统一锁的获取顺序// 或使用 spin_lock_nested()spin_lock(&lock_a);spin_lock_nested(&lock_b, SINGLE_DEPTH_NESTING);
案例 3:内存泄漏导致 OOM
Call Trace:
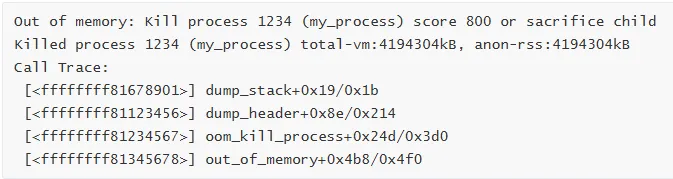
分析步骤:
检查内存使用
cat /proc/meminfofree -h
使用 kmemleak 检测
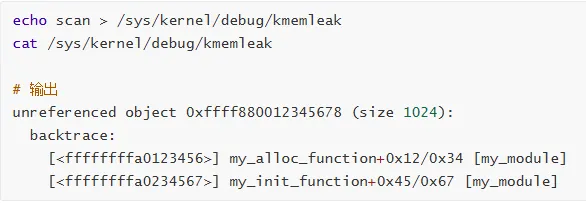
定位泄漏点
// 问题代码voidmy_function(void){char*buffer=kmalloc(1024, GFP_KERNEL);if (some_error)return; // 忘记释放 bufferkfree(buffer);}
修复方案
// 修复代码voidmy_function(void){char*buffer=kmalloc(1024, GFP_KERNEL);if (!buffer)return;if (some_error)gotoout_free; // 使用 goto 统一清理out_free:kfree(buffer);}
🛡️ 预防措施
1. 编码规范
// ========== 指针检查 ==========// 总是检查指针是否为 NULLstructmy_struct*ptr=get_my_struct();if (!ptr) {pr_err("Failed to get struct\n");return-EINVAL;}// ========== 内存管理 ==========// 使用 goto 标签统一清理资源intmy_function(void){char*buf1=NULL, *buf2=NULL;intret=0;buf1=kmalloc(SIZE1, GFP_KERNEL);if (!buf1) {ret=-ENOMEM;gotoout;}buf2=kmalloc(SIZE2, GFP_KERNEL);if (!buf2) {ret=-ENOMEM;gotoout_free_buf1;}// 正常处理out_free_buf2:kfree(buf2);out_free_buf1:kfree(buf1);out:returnret;}// ========== 锁的使用 ==========// 统一锁的获取顺序// 使用 spin_lock_irqsave 在中断和进程上下文共享数据时unsignedlongflags;spin_lock_irqsave(&my_lock, flags);// 临界区spin_unlock_irqrestore(&my_lock, flags);// ========== 中断上下文 ==========// 不要在中断中睡眠// 不要在中断中使用 GFP_KERNEL 分配内存irqreturn_tmy_irq_handler(intirq, void*dev_id){// 使用 GFP_ATOMICchar*buf=kmalloc(SIZE, GFP_ATOMIC);// 不要调用 msleep, mutex_lock 等returnIRQ_HANDLED;}// ========== 边界检查 ==========// 总是检查数组边界if (index>=ARRAY_SIZE) {pr_err("Index out of bounds: %d\n", index);return-EINVAL;}array[index] =value;
2. 内核配置选项
# ========== 调试选项 ==========# 启用内核调试CONFIG_DEBUG_KERNEL=y# 启用内核地址消毒器(检测内存错误)CONFIG_KASAN=y# 启用 SLUB 调试CONFIG_SLUB_DEBUG=y# 启用死锁检测CONFIG_PROVE_LOCKING=yCONFIG_DEBUG_LOCK_ALLOC=yCONFIG_LOCKDEP=y# 启用栈溢出检测CONFIG_DEBUG_STACK_USAGE=yCONFIG_DEBUG_STACKOVERFLOW=y# 启用内存泄漏检测CONFIG_DEBUG_KMEMLEAK=y# 启用原子操作检测CONFIG_DEBUG_ATOMIC_SLEEP=y# 启用 RCU 调试CONFIG_PROVE_RCU=y# 启用软锁定检测CONFIG_SOFTLOCKUP_DETECTOR=y# 启用硬锁定检测CONFIG_HARDLOCKUP_DETECTOR=y
3. 静态分析工具
# ========== sparse - 内核静态分析 ==========makeC=1CF="-D__CHECK_ENDIAN__"# ========== coccinelle - 语义补丁 ==========make coccicheck MODE=report# ========== checkpatch.pl - 代码风格检查 ==========./scripts/checkpatch.pl --file drivers/net/my_driver.c# ========== smatch - 静态分析 ==========makeCHECK="smatch -p=kernel"C=1
4. 运行时检测
# ========== 启用 SLUB 调试 ==========# 内核启动参数slub_debug=FZPU# F - 启用一致性检查# Z - 红区检测# P - 毒化(Poisoning)# U - 用户跟踪# ========== 启用 lockdep ==========echo1 > /proc/sys/kernel/lock_stat# 查看锁统计cat /proc/lock_stat# ========== 启用 ftrace ==========# 追踪函数调用echo function_graph > /sys/kernel/debug/tracing/current_tracerecho1 > /sys/kernel/debug/tracing/tracing_oncat /sys/kernel/debug/tracing/trace
5. 代码审查清单
✓ 内存管理□ 所有 kmalloc/kzalloc 都检查返回值□ 所有分配的内存都有对应的释放□ 使用 goto 标签统一清理资源□ 释放后将指针置为 NULL✓ 指针使用□ 使用前检查指针是否为 NULL□ 避免悬空指针□ 注意指针的生命周期✓ 锁的使用□ 统一锁的获取顺序□ 持有锁的时间尽可能短□ 中断和进程上下文共享数据使用 spin_lock_irqsave□ 避免在持有锁时睡眠✓ 中断处理□ 中断处理函数尽可能短□ 不在中断中睡眠□ 使用 GFP_ATOMIC 分配内存□ 耗时操作使用工作队列✓ 边界检查□ 数组访问前检查索引□ 字符串操作使用安全函数(strncpy, snprintf)□ 用户输入严格验证✓ 错误处理□ 所有错误路径都正确处理□ 返回值都被检查□ 错误信息清晰明确
📚 总结
核心要点
理解 Call Trace 结构:错误类型、地址、寄存器、调用栈
掌握调试工具:addr2line、objdump、gdb、crash
系统化分析:从 Call Trace 到源码,从现象到根因
预防为主:编码规范、静态分析、运行时检测
持续学习:积累经验,建立问题库
常见错误类型速查
| 错误类型 | 典型特征 | 常见原因 |
|---|---|---|
| NULL pointer | at 0x00000000 | 指针未初始化、初始化失败 |
| Use-after-free | 随机地址 | 使用已释放的内存 |
| Soft lockup | stuck for Xs | 长时间占用 CPU、死循环 |
| Hard lockup | NMI watchdog | 中断被长时间禁用 |
| Stack overflow | stack guard page | 栈上分配大数组、递归 |
| Deadlock | blocked for Xs | 锁顺序不一致、循环等待 |
| OOM | Out of memory | 内存泄漏、分配过多 |
Call Trace 是内核给我们的重要线索,学会解读它,就能快速定位和解决问题。
📖 参考资料
Linux Kernel Documentation
Understanding the Linux Kernel
Linux Device Drivers
Kernel Debugging Tips
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python + Streamlit + AkShare + Plotly ,实时资金流向可视化工具!
- Python老手必看!10个隐藏冷知识,90%的人都踩过坑
- 一款基于 PHP 程序开发的彩虹外链网盘
- 新课程推介 | Python编程课——未来小创客,从这里启程!
- 七旬老头,用“笨”方法硬刚AI学Python,结果资深的程序员坐不住了(周兴富)
- Linux命令每日一清单012:chown--修改文件所有权命令速查表
- Rocky Linux 10.1 虚拟机实战:企业级光环下的“卡顿”与救赎
- Linux安装OpenClaw配置详解 OpenClaw对接QWEN模型 OpenClaw常用命令 OpenClaw免费模型推荐
- 字节跳动竟然斥巨资开发出《Python知识手册》,高清PDF泄露!
- Python + Steamlit 快速开发可视化 web 页面!
