Python | 数据压缩 | 八面体高斯网格规则化
- 2026-07-04 02:03:12

起因
从买不起硬盘,到开始抠每个字节
前一篇里我讲了一个「消费降级」的故事:Python | 压缩近3倍netcdf文件大小
新的问题
由于最近的工作:需要处理数十万文份ERA5 137 层数据。
然后,很自然地,我碰到了下一个更 “狠” 的问题。
需要处理 数十万个 ERA5 的 137 层数据。 典型工作流大概是这样:
先下载数据; 先做插值 / 预处理(比如转成规则网格); 存成 netCDF 方便后续分析,结果一算存储空间,直接傻眼:
单个 F96 full Gaussian 网格转换成nc数据:一个文件就能到 1 GB 的量级; 同样日期的 N96 reduced grid 使用CCSDS压缩算法的GRIB2数据:也要 ~200 MB; 而 O96 octahedral grid:大概是 ~160 MB 左右。 这还只是 一个时间步、几个变量。如果你像我一样,打算对「 数十万文件 × 137 层」做系统处理,不做任何设计的话:
❝硬盘会被你喂到直接“超重爆炸”。 所以,这次不但得动脑子压缩数据,还得从「网格本身」下手。
即使是放在服务器上,也要花费不小的空间。

高斯网格
从 F96 / N96 到 O96:为硬盘省点命 简单回顾一下三个网格的差别(以 N=96 为例):
F:Full Gaussian / 规则经纬网
每一圈纬线都有相同的经向点数,比如 384 列; 好处:规则,傻瓜都会用; 坏处:极区冗余严重,总点数最多,文件最大。
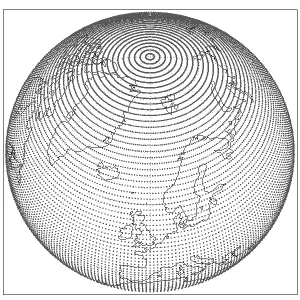
N:传统 reduced Gaussian(N-grid)
每一圈的点数 pl[j] 不同,高纬更少、赤道多一些(但没 O-grid 那么多); 对比 F96:同样分辨率下,总点数更少,文件明显小一些。
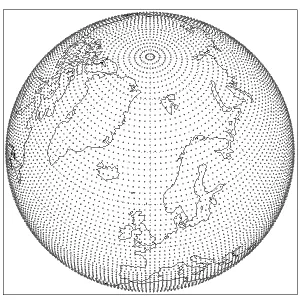
O:Octahedral reduced Gaussian(O-grid)
它是一种缩减高斯网格的形式,其纬线数量及所在的纬度值与原始高斯网格相同,但在极点与赤道之间的每个纬线圈上,经度点的数量是根据以下公式计算的:
也是 reduced grid,但设计成更接近等面积 / 等间距; 赤道附近点数比 N96 更密(理论上赤道行是4N+16个点),但全局分布更均匀; 关键点:在满足数值精度的前提下,总点数比 N96 和 F96 都少一些,所以文件体积也更小。
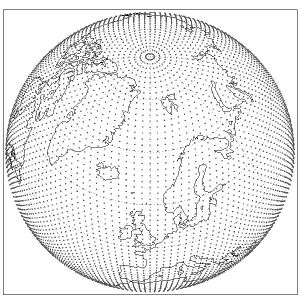
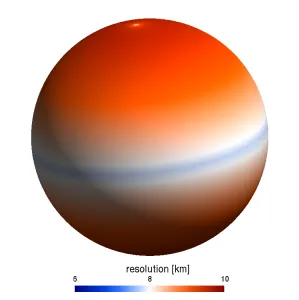
处理了几个用于测试的 ERA5 文件,大概是这样的(粗略示意):
F96:lat × lon ≈ 192 × 384,文件 ~257 MB N96:lat × lon ≈ 192 × 384(规则化后),原始 reduced pl 较长,文件 ~197 MB O96:lat × lon ≈ 192 × 400(规则化后),但 reduced pl 总点数更少,实际文件 ~160 MB
也就是说:
仅仅换成 八面体网格,在保持分辨率的前提下,整体存储就能再省一截。
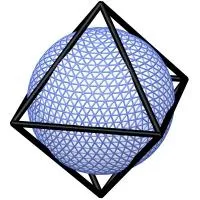
八面体高斯网格 O96 是什么鬼?
❝用大白话说:传统 N-grid 在极区点太挤、赤道点不够“均匀”,对谱模式来说有些不理想; O-grid 通过设计一个“八面体结构”的 reduced Gaussian grid,在 球面上格点分布更均匀(更接近等面积); 格点数稍微减少,但对数值精度影响很小甚至更好; 仍然保持高斯纬度的优点(方便谱-格点变换)。
但高斯网格并不好用:要规则网格
现实问题是:
大部分人更习惯规则经纬网(lat-lon regular grid); O/N 这类 reduced Gaussian grid 虽然在存储和数值上很好,但直接用起来就很麻烦。
面对数以十万计的 ERA5 文件,如果采用传统的常规流程:
先用 CDO 命令行把原文件插值成规则网格 存出一个巨大的中间 NetCDF 文件 用 Python 读进来做物理量计算 最后保存结果。
这会带来一个致命问题:极其恐怖的硬盘 I/O(读写)瓶颈,你的硬盘大部分时间都在痛苦地来回搬运中间临时文件,处理速度会被严重拖垮。
为了极限压榨计算性能,保护我那可怜的硬盘,我的计划是全程在运行内存(RAM)中“空手套白狼”:
直接读取原始的 O/N 缩减网格数据进入内存;
在内存中“即时(On-the-fly)” 完成到规则网格的插值重构;
直接进行所需的物理量诊断与计算;
最后只把计算好的目标变量保存。
全程绝不输出任何未经处理的中间网格文件,把沉重的读写负担全部转移到高速运行内存中
想法很美好,但实操起来却卡壳了:
强大的 CDO 严重依赖本地文件的读写,很难丝滑地嵌入这种纯内存的 Python 数据流中。
如果用 xarray 和 scipy 自己写插值,不仅要手动解析反人类的 pl 数组和缩减网格逻辑,代码还会变得极其啰嗦且运行缓慢。
GaussRegular

为了彻底打通这个“内存级”的网格转换瓶颈,干脆自己造了个极速小轮子:
gaussregular——一个专门将 reduced Gaussian 网格(包括最新的 O-grid)极速转换为规则高斯网格的轻量库。
系统要求:
Python版本:3.9 - 3.14 操作系统:Windows (x64)、macOS (Apple Silicon)、Linux (x86_64)
要安装gaussregular库,可以使用pip:
pip install gaussregular或者使用以下命令:
pip install -U --index-url https://pypi.org/simple/ gaussregular库的仓库在这里:
❝https://github.com/QianyeSu/GaussRegular
功能很简单也很聚焦:
输入:N-grid / O-grid 的 reduced Gaussian 场(通常从 GRIB + cfgrib 来); 输出:规则高斯网格(regular Gaussian grid),保留时间、层、变量维度;
我们用 O96 的来看:
import xarray as xrimport gaussregular as grpath_o96 = r"era5_reanalysis_O96.grib2"# 读取 O96 reduced Gaussian gridds = xr.open_dataset( path_o96, engine="cfgrib")print("raw dims:", ds.dims)da = ds["t"] # 举例用温度print("raw var:", da.name, da.dims, da.shape)print("GRIB_gridType:", da.attrs.get("GRIB_gridType"))print("GRIB_N:", da.attrs.get("GRIB_N"))# 创建 regularizer,指定 N=96 方便全局/区域判断engine = gr.GaussRegularizer(method="linear", cache=True, grid_number=96)# 直接对 DataArray 做规则化插值regular_da = engine.regularize_xarray(da, method="linear") # 或 "nearest"print("regularized shape:", regular_da.shape)print("dims:", regular_da.dims)在我的测试里,大致会输出类似:
原始:('time', 'hybrid', 'values') 形状 (24, 137, 40320) 规则化后:('time', 'hybrid', 'latitude', 'longitude') 形状 (24, 137, 192, 400) 也就是: 192 条纬线 × 400 个经度点的规则网格; time 和 hybrid 维度保持不变。 如果你想对整个 xr.Dataset 一次性处理多个变量,可以这样写:
regular_ds = engine.regularize_dataset(ds, method="linear")print(regular_ds)它会自动:
找出看起来像 reduced Gaussian 的变量(有 GRIB_pl 等标记); 把这些变量规则化; 其他变量(标量、坐标类)保持不变。
最后
这样算下来,大约又省了十倍的空间,原先存储需要1GB的数据,现在只需要100多MB就可以存储相同的数据量。
❝详细使用方法请看:https://github.com/QianyeSu/GaussRegular
Reference
https://cds.climate.copernicus.eu/

