Linux使用cgroup管理资源限制
一、cgroup结合systemd针对服务做资源限制
使用 ulimit 限制系统资源 限制系统资源的传统方法是使用 ulimit 命令。设置的限制是系统级别的,会在登录和会话初始化时由可插拔认证模块(PAM)身份验证机制强制执行。ulimit 命令是 BASH 内置命令,用于限制 shell 及其子进程可用的资源。这种方法适用于限制失控的资源使用,但不足以处理资源争用问题。 可以使用 ulimit 命令行工具查询(和设置)限制。要获取完整的限制列表,请参考 ulimit(1)手册页(属于 bash(1)手册页的一部分)。 配置持久化 ulimit 规则 交互式使用 ulimit 只会将限制作用于单个用户 shell。pam_limits PAM 模块会在登录时设置 POSIX 资源限制。在默认的 /etc/pam.d/system-auth 文件中,有一个会话调用以运行 pam_limits。该 PAM 模块会在用户登录时解析并应用来自 /etc/security/limits.conf 和 /etc/security/limits.d/*.conf 的 ulimit 设置。文件语法在 limits.conf(5)手册页中有描述。PAM 模块还可以设置常规 POSIX ulimit 列表之外的限制。 例如,要将 managers 组中的用户限制为最多 3 个同时登录,/etc/security/limits.d/managers.conf 中应包含如下设置: @managershardmaxlogins3 上面的示例展示了硬限制的配置。也可以配置软限制,软限制不应超过硬限制。这些软限制同样会被强制执行,用户无法超出。软限制和硬限制的区别在于:非 root 用户可以配置软限制,但只有拥有 root 权限的用户才能修改硬限制。 为服务设置限制 POSIX 限制也可通过系统单元文件 [Service] 区块中的 Limit*= 条目应用到 systemd 服务。例如,若要将 example.service 服务的 CPU 时间限制为最多 30 秒,超时即终止,需创建如下文件来定义该限制: [root@host ~]# cat /etc/systemd/system/example.service.d/10-cpulimits.conf [Service] LimitCPU=30 使用 systemctl daemon-reload 命令通知 systemd 配置已更改。同时必须重启该服务,才能使配置变更生效。 之前的示例使用了 systemd 插入式文件(drop-in file)。插入式文件用于添加或覆盖个别设置,而无需修改位于 /usr/lib/systemd 中的原始单元配置。切勿修改 /usr/lib/systemd 目录下的文件,因为软件包升级会覆盖你的自定义配置。相反,应在 /etc/systemd/system/ 目录下创建一个以原单元名加 .d 后缀命名的子目录。在该子目录中放置的插入式配置文件必须以 *.conf 结尾。文件会按字母数字顺序解析,且 /etc/systemd/system/service.d 目录下的文件优先级高于 /etc/systemd/system/service 单元文件或 /usr/lib/systemd/system/service 默认配置。
描述控制组 控制组(cgroups)是 Linux 内核中用于细粒度控制资源的机制。通过 cgroups,资源被归类到代表资源类型的控制器中;例如,cpu 对应 CPU 时间,memory 对应内存使用,blkio 对应磁盘 I/O。 控制器可以进一步细分,表现为树形结构,不同的权重或限制关联到 cgroups 的分支和叶子节点。每个 cgroup 关联零个或多个进程。默认情况下,cgroup 内的资源会被平均分配,但只要不超过父 cgroup 的限制,就可以为子 cgroup 设置不同的限制和权重。新 cgroup 会继承父 cgroup 设置的限制,除非显式覆盖。 控制组与 systemd 通过 systemd 守护进程管理 cgroups 是处理复杂资源配置的简单方式。默认情况下,systemd 将 cpu、cpuacct、blkio 和 memory cgroups 划分为三个均等的切片(slice):system 用于系统服务和守护进程,machine 用于虚拟机和容器,user 用于用户会话。 警告 红帽企业 Linux 的早期版本使用已弃用的 cgconfig 和 cgred 服务,这些服务位于 libcgroup-tools 软件包中。当前默认的资源控制器已使用上述 systemd。为避免冲突,仅使用 libcgroup 工具管理 systemd 当前不支持的控制器,例如 net_prio。在使用 libcgroup 工具前,请查阅 systemd-system.conf(5)手册页获取相关信息。 三个默认的 systemd 切片 默认创建三个父切片。管理员可以创建额外的*.slice 单元,设置各自的限制,并将服务分配到这些切片中。要创建作为另一个切片子节点的切片,命名时需包含父名称、短横线和子名称,格式为 <parent>-<child>.slice。新切片将创建在 <parent>.slice 切片内部。 system.slice 默认情况下,所有由 systemd 启动的服务都会被放入此切片的一个新子组中。 user.slice 每登录系统的用户,都会在此切片中创建一个新的子切片。该用户的每个会话都会被放入该子切片的新子切片中。 machine.slice 由 libvirt 管理的虚拟机会自动分配到此切片的新子切片中。machine.slice 切片会在第一台虚拟机启动时才创建。Linux 容器也会被放入 machine.slice 切片中。
检查控制组 systemd 包含两个用于检查当前 cgroup/切片布局的工具:systemd-cgtop 和 systemd-cgls。systemd-cgtop 命令会以类似 top 的方式展示不同 cgroup 的概览,可按名称、任务数、CPU 使用率、内存使用率或 I/O 活动排序。按下 ? 键可获取交互式帮助。systemd-cgls 命令会输出所有切片、cgroup 及其包含进程的完整列表。在命令行中指定 cgroup 树路径,可将输出限制为指定的 cgroup 或切片。 注意:除非为某个切片或 cgroup 启用了 CPU、内存或 I/O 统计,否则只会报告 cgroup 中的任务数量。为某个服务启用统计功能,可能会同时为同一切片中的其他服务启用该功能。 也可以通过 systemd-run 命令并使用 --slice= 选项,在 systemd 切片中运行交互式命令。使用 systemd-run 执行的命令会作为 system.slice 切片的子进程。以下示例使用名为 example.slice 的切片,若该切片不存在则会自动创建。 [root@host ~]# systemd-run --slice=example.slice sleep 10d Running as unit run-4321.service [root@host ~]# systemd-cgls /example.slice/run-4321.service /example.slice/run-4321.service: └─4322 /bin/sleep 10d 使用 systemd-run 启动临时命令,管理员可以通过 systemctl 等 systemd 工具控制长时间运行的命令,同时限制其资源使用。 运行时应用资源限制 使用 systemctl set-property 命令可在运行时设置指定单元的属性。支持的属性列表可在 systemd.resource-control(5)手册页中查阅。变更会立即生效并持久保存。 以下示例为正在运行的服务应用并验证内存子系统的资源控制属性: [root@host ~]# systemctl set-property example.service MemoryAccounting=yes [root@host ~]# systemctl set-property example.service MemoryLimit=2048M [root@host ~]# cat /sys/fs/cgroup/memory/system.slice/example.service/memory.limit_in_bytes 2147483648
管理 systemd 控制组设置 自 RHEL 7 引入 systemd 以来,资源管理设置已通过将控制组层级体系与 systemd 单元树绑定,从进程级迁移到了应用级。systemd 提供 systemctl 命令和服务单元文件,以简化并标准化系统资源管理控制。 可通过以下三种方式控制 systemd 切片和控制组: - 为服务或切片启用 CPU、内存和/或块 I/O 统计。 - 对单个服务或切片设置资源限制。 - 在自定义切片中运行服务。 启用统计功能 在资源控制器中启用统计功能后,可通过 systemd-cgtop 命令或查看控制组虚拟文件系统,观察准确的资源使用量。 要为服务启用 CPU、内存和块 I/O 统计,可在目标服务的 [Service] 区块或目标切片的 [Slice] 区块中添加 CPUAccounting=true、MemoryAccounting=true 和 BlockIOAccounting=true 配置项。统计功能确实会给内核带来些许管理开销,但在常规系统中,这种开销应不易察觉。 向单元添加这些设置的简单方法是使用插入式文件(drop-in file)。可通过在 /etc/systemd/system/ 下创建以目标单元名加 .d 后缀命名的目录来配置插入式文件。例如,sshd.service 的插入式目录为 /etc/systemd/system/sshd.service.d/。 在此目录中创建*.conf 文件,以覆盖或添加该单元的特定选项。文件按字母数字顺序读取。例如,此文件及其内容用于为 sshd.service 服务启用内存统计。 [root@host ~]# cat /etc/systemd/system/sshd.service.d/20-accounting.conf [Service] MemoryAccounting=true 强制限制 控制资源使用的机制称为强制限制。限制的创建方式与启用统计相同,即将相关的 systemd 指令放入单元插入式文件中。可在 systemd.resource-control(5)手册页中查看完整的指令列表。 典型的资源限制示例如下: CPU Shares 使用 cgroups 时,CPU 时间不会被直接限制,而是为各个 cgroup 设置权重。在一个 cgroup 内部,CPU 资源会被平均分配;而在不同 cgroup 之间,当 CPU 资源紧张时,份额数量决定了最大分配比例。 例如,如果三个 cgroup 都在请求 CPU 时间,且它们的 CPU Shares 分别设置为 1024、1024 和 512,那么前两个 cgroup 各自将获得约 40% 的可用 CPU 时间,第三个 cgroup 仅获得约 20%。CPU Shares 的默认值为 1024。 注意:与所有 cgroup 限制一样,CPU Shares 是嵌套的。在高负载系统中,如果 system.slice 仅能获得约 33% 的可用 CPU 时间,那么在该切片中运行的所有 cgroup(系统服务)将共享这 33% 的 CPU 时间。 CPU Quota 为执行的进程分配指定的 CPU 时间配额。该百分比用于指定单元在最大负载下,相对于单个 CPU 总可用时间所能获得的 CPU 时间量。可使用大于 100% 的百分比值来分配超过一个 CPU 的时间。 例如,CPUQuota=25% 可确保执行的进程在单个 CPU 上的 CPU 时间永远不会超过 25%。 Memory Limit 用于设置该单元中进程或任务所使用内核内存的硬限制。此设置可用于 cgroup、切片或服务。值以字节为单位指定,也可通过追加 K、M、G 或 T 来表示 KiB、MiB、GiB 或 TiB。 当 cgroup 达到硬限制时,将触发内存溢出(OOM)操作。 BlockIO* 块 I/O 可通过相对权重、按设备的相对权重,或指定每个设备的最大读写带宽来限制。 在自定义切片中运行服务 默认情况下,systemd 会在 system.slice 切片下为每个服务创建一个新的 cgroup,名称与服务的单元文件一致。要将服务运行在其他切片中,可在 [Service] 区块中使用 Slice=other.slice 设置,其中 other.slice 是自定义切片的名称。如果指定的切片不存在,会在服务启动时自动创建。新切片将采用所有限制和统计的默认设置。 系统资源的粒度控制和分配公平性是使用自定义切片的主要优势。为了更精细地控制自定义切片,可在 /etc/systemd/system/ 目录下创建新的 *.slice 文件。一个示例切片文件如下: [Unit] Description=Example Custom Slice [Slice] CPUShares=2048 MemoryAccounting=true 要创建作为另一个切片子节点的切片(除非显式覆盖,否则继承父切片的所有设置),切片必须命名为 parent-child.slice。例如,要创建一个名为 flops 的切片作为 system.slice 的子节点,新单元文件必须命名为 system-flops.slice。创建多层嵌套切片时,无需手动创建每一级。创建类似 system-a-b-c-d.slice 的切片会自动生成所有所需层级:system-a.slice、system-a-b.slice、system-a-b-c.slice 以及 system-a-b-c-d.slice。
二、cgroup v2
预览 cgroups v2 cgroups v2 项目,是为了改进 cgroups v1 的成果,并为资源管理引入更简洁的层级结构。 控制组中的层级结构 层级结构是每个控制组实现中的关键设计要点,也是推荐从 libcgroups 切换到 systemd 的主要原因之一。在新的 cgroups v2 中,层级结构是核心特性,旨在简化资源管理,并消除因多个 cgroup 控制器间资源条目重复而造成的混淆。
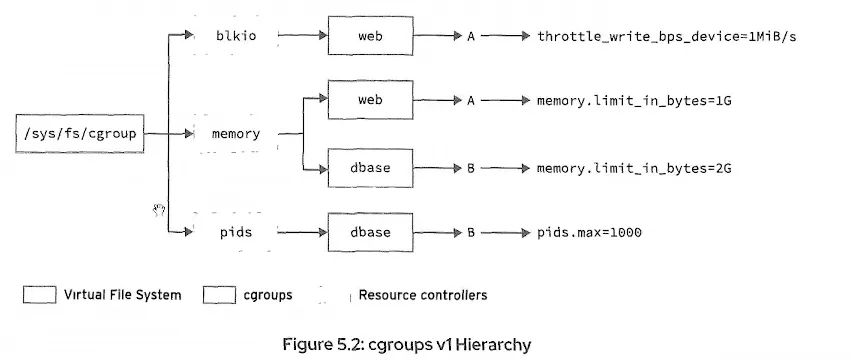
cgroups v1 的层级结构中,控制组与资源控制器相关联,cgroups v1 会挂载资源控制器,且控制组创建在控制器层级内部。在上方的图示中,web 控制组在层级里存在重复条目,分别位于内存和块 I/O 资源控制器下。同样,dbase 控制组也有重复条目,不过是在内存和进程数(pids)资源控制器下。
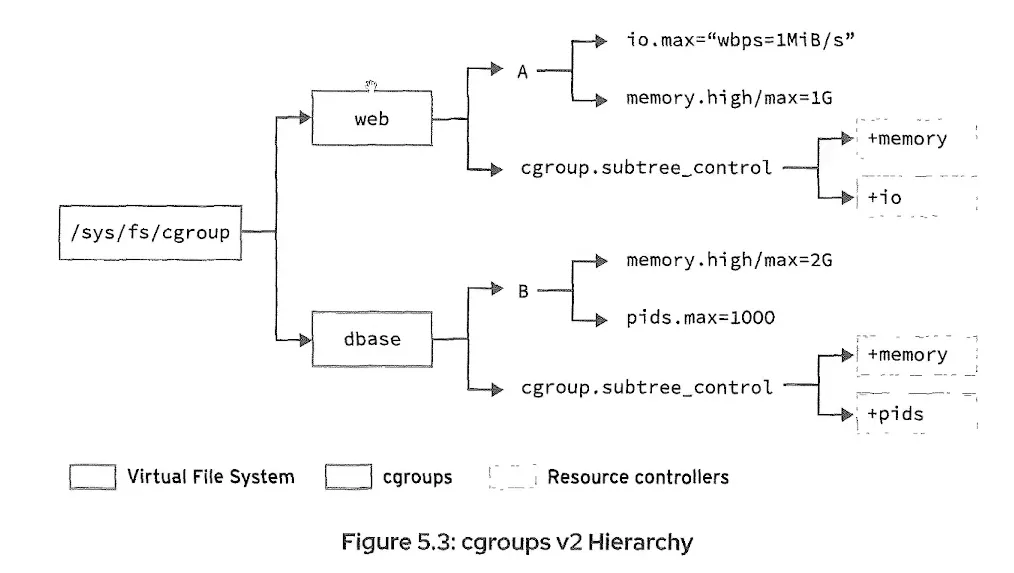
cgroups v2 的层级结构中,控制器与控制组相关联。cgroups v2 先创建控制组,再通过 cgroup.subtree_control 文件将所需控制器关联到控制组。在上方的图示中,web 和 dbase 控制组仅存在一次,它们关联的资源控制器会列在 cgroup.subtree_control 文件内。 cgroups v2 注意事项 以下是 cgroups v2 的主要注意事项: - cgroups v2 为所有资源控制器提供单一控制组层级结构。 - 不支持也不建议同时挂载 cgroups v1 和 cgroups v2。 - 启用 cgroups v2 需要在内核启动参数中添加 systemd.unified_cgroup_hierarchy=1。 - cgroups v2 目前仅包含 CPU、IO、内存、RDMA 和 PID 控制器。 - 为保持向后兼容,RHEL 8 中 cgroup v1 仍为默认设置。

