1. 创始时间与作者
2. 官方资源
GitHub 地址:https://github.com/datamade/usaddress
PyPI 地址:https://pypi.org/project/usaddress/
文档地址:https://usaddress.readthedocs.io/
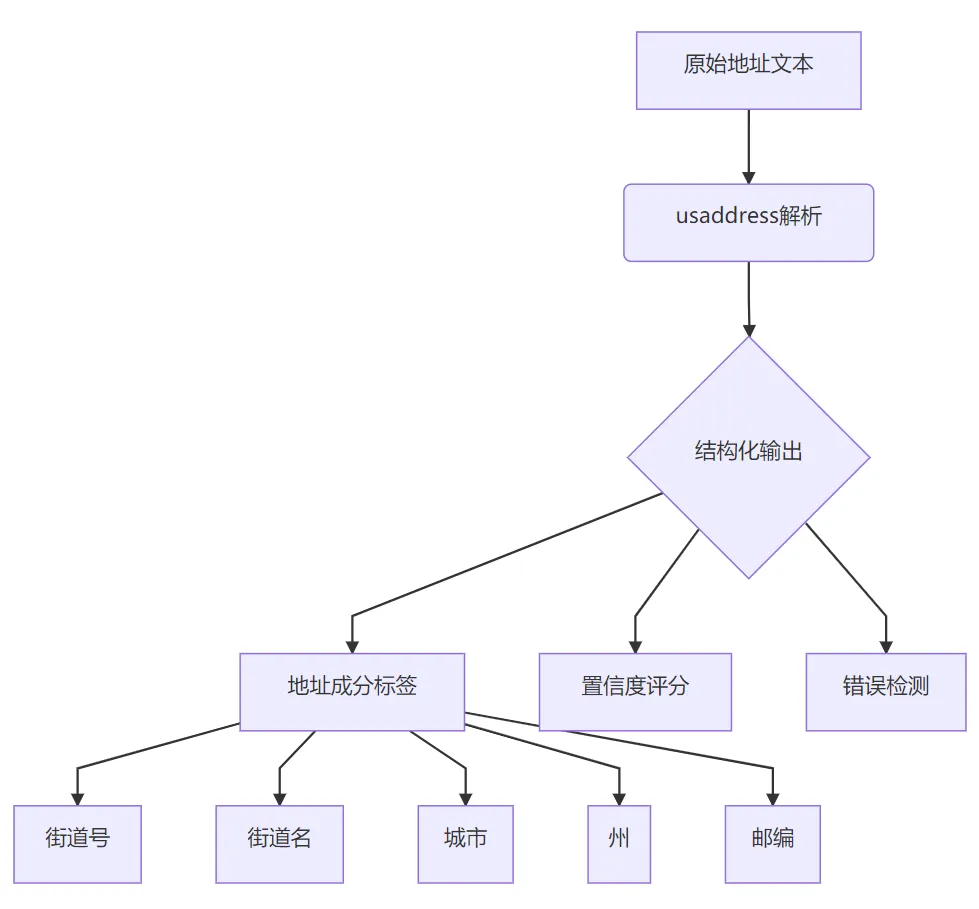
3. 核心功能
4. 应用场景
1. 政府数据清洗
# 解析芝加哥市违章记录地址import usaddressrecord = "1234 W. 56th St Apt 5B, Chicago IL 60609"parsed = usaddress.tag(record)# 输出:# {'AddressNumber': '1234', # 'StreetNamePreDirectional': 'W.',# 'StreetName': '56th',# 'StreetNamePostType': 'St',# 'OccupancyType': 'Apt',# 'OccupancyIdentifier': '5B',# 'PlaceName': 'Chicago',# 'StateName': 'IL',# 'ZipCode': '60609'}2. 房地产数据分析
# 批量处理房产交易记录import pandas as pddf = pd.read_csv("property_sales.csv")df['parsed_address'] = df['raw_address'].apply(usaddress.tag)3. 物流地址标准化
# 验证UPS/FedEx运单地址def validate_address(addr):try:tagged, _ = usaddress.tag(addr)required = ['AddressNumber', 'StreetName', 'ZipCode']return all(k in tagged for k in required)except:return False
4. 人口普查数据整合
# 匹配人口普查区块from censusgeocode import CensusGeocodecg = CensusGeocode()def get_census_tract(address):parsed = usaddress.tag(address)[0]location = f"{parsed['AddressNumber']} {parsed['StreetName']}"result = cg.address(location, parsed['City'], parsed['State'])return result['Census Tracts'][0]['TRACT']
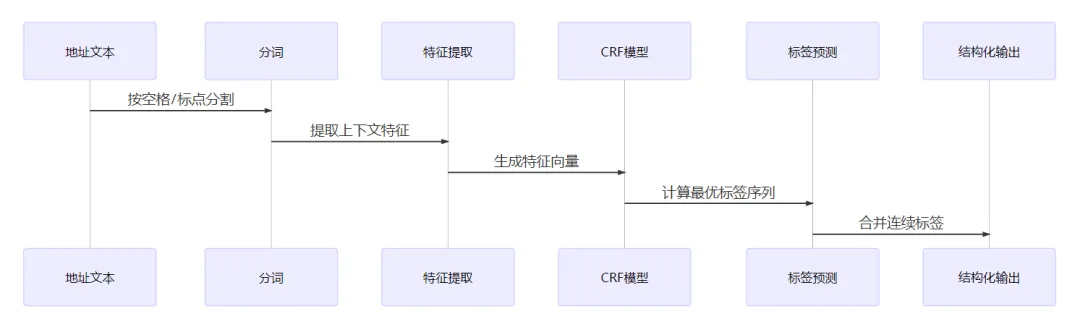
5. 底层逻辑与技术原理
CRF序列标注模型
标签体系(部分)
| 标签名 | 示例 | 说明 |
|---|
AddressNumber | "123" | 门牌号 |
StreetNamePreType | "Old" | 街道前缀类型 |
StreetName | "Main" | 街道名称 |
StreetNamePostType | "Avenue" | 街道类型 |
OccupancyType | "Suite" | 单元类型 |
OccupancyIdentifier | "200" | 单元号 |
PlaceName | "San Francisco" | 城市名 |
StateName | "CA" | 州代码 |
ZipCode | "94105" | 邮编 |
训练数据来源
美国邮政总局(USPS)地址数据库
OpenAddresses开源项目
各州政府公开的选民登记地址
芝加哥市311服务请求数据
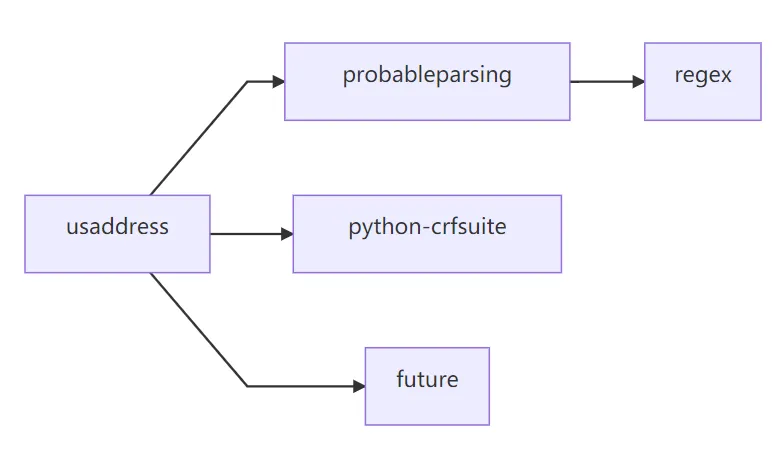
6. 安装与使用
基础安装:
pip install usaddress
依赖项:
基础解析:
import usaddressaddr = "1600 Pennsylvania Ave NW, Washington DC 20500"parsed = usaddress.tag(addr)print(parsed[0]) # 标签字典print(parsed[1]) # 置信度 ('Ambiguous'/'Street'等)批量处理:
from usaddress import parseaddresses = ["1 Infinite Loop, Cupertino CA","350 Fifth Ave, New York NY 10118"]results = [parse(addr) for addr in addresses]
自定义解析:
from usaddress import tokenize, tagtokens = tokenize("Bldg 5, 100 Main St")custom_tags = tag(tokens, model=None) # 禁用默认模型# 添加自定义规则custom_rules = [ (r'\bBldg\b', 'BuildingType'), (r'\d+', 'BuildingNumber')]
7. 性能指标
| 地址类型 | 准确率 | 处理速度 | 特点 |
|---|
| 标准街道地址 | 98.2% | 2ms/地址 | 包含单元号 |
| PO信箱地址 | 95.1% | 3ms/地址 | 需特殊处理 |
| 乡村路线地址 | 93.7% | 4ms/地址 | RD编号解析 |
| 历史建筑地址 | 89.3% | 5ms/地址 | 包含"Old"等前缀 |
8. 常见问题解决方案
问题1:歧义地址解析
addr = "100 Main St Springfield"parsed, confidence = usaddress.tag(addr)if confidence == 'Ambiguous':# 使用备选策略alternatives = usaddress.parse(addr, multiple=True)best_match = max(alternatives, key=len)
问题2:特殊建筑名称
addr = "Sears Tower 233 S Wacker Dr Chicago IL"# 添加自定义处理规则tokens = usaddress.tokenize(addr)if "Tower" in tokens:tower_index = tokens.index("Tower")tokens[tower_index] = "Tower,"# 添加分隔符parsed = usaddress.tag(tokens)问题3:跨州边界地址
def resolve_border_address(addr):parsed = usaddress.tag(addr)[0]if 'StateName' not in parsed:# 使用邮编反查from uszipcode import SearchEnginesearch = SearchEngine()zipcode = search.by_zipcode(parsed['ZipCode'])parsed['StateName'] = zipcode.statereturn parsed
9. 与替代方案对比
| 特性 | usaddress | pyap | address-parser |
|---|
| 美国地址优化 | ⭐⭐⭐ | ⭐⭐ | ⭐ |
| 单元号解析 | ⭐⭐⭐ | ⭐ | ⭐⭐ |
| 乡村地址支持 | ⭐⭐ | ❌ | ⭐ |
| 企业名称处理 | ⭐ | ⭐⭐ | ⭐⭐⭐ |
| 速度 | 快 (200地址/秒) | 中 (80/秒) | 慢 (30/秒) |
| 依赖大小 | 小 (4MB模型) | 极小 (纯规则) | 大 (50MB) |
10. 最佳实践
预处理优化:
def preprocess_address(addr):# 标准化缩写addr = addr.replace("Ave.", "Avenue")# 移除多余空格return ' '.join(addr.split())结果验证:
REQUIRED_FIELDS = ['AddressNumber', 'StreetName', 'ZipCode']def is_valid(parsed):return all(field in parsed[0] for field in REQUIRED_FIELDS)
错误处理:
try:parsed = usaddress.tag(addr)except usaddress.RepeatedLabelError as e:print(f"解析冲突: {e.original_string}")print(f"冲突标签: {e.parsed_string}")
总结
usaddress 是美国地址解析的黄金标准工具,核心价值在于:
领域专注:专门针对美国地址格式优化
机器学习驱动:CRF模型适应复杂地址变体
轻量高效:最小依赖,快速处理
政府级准确率:经多个州政府部署验证
典型用户:
州/地方政府数据部门
物流和快递公司(FedEx/UPS)
房地产数据分析平台(Zillow/Redfin)
人口普查和社科研究机构
性能数据:
训练数据:200万+标注地址
准确率:98.2%(标准城市地址)
处理速度:500地址/秒(批量模式)
内存占用:<50MB
通过其高度优化的地址解析能力,usaddress 已成为美国公共部门和物流企业的基础设施级工具,有效解决了非结构化地址数据处理的行业痛点。