10分钟掌握 2026版 Python爬虫 之selenium 动态网页解析模块
- 2026-06-28 20:48:47
概述
还在为动态网页抓不到数据头疼?Selenium 来救场!从驱动安装、元素定位,到模拟交互、无界运行,手把手带你搞定那些 “反爬小调皮”,让动态网页乖乖听话~
selenium 动态网页解析模块
(一)selenium 模块简介
有些网站的数据是 js 动态渲染的,我们无法通过网页源码直接找到数据,只能通过找接口方式来获取数据,但是很多时候,数据又是 json 格式的,给我们爬数据增加成本。
比如 https://www.csdn.net/ 这个网站 就是 js 动态渲染的首页数据。
这时候,使用 selenium,我们可以通过模拟真实浏览器的用户操作行为,来获取 js 动态渲染后的网页数据,在进行解析网页,获取我们需要的数据。能大大提高我们的抓取效率。
Selenium 是一个用于 Web 应用程序测试的工具。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括 IE (7, 8, 9, 10, 11) ,Mozilla Firefox,Safari,Google Chrome,Opera,Edge 等。
我们使用 Selenium,模拟浏览器功能,自动执行网页中的 js 代码,实现动态加载,然后再进行数据抓取。
(二)selenium 驱动下载,模块安装以及基本使用
我们以谷歌浏览器为例讲解。首先我们要去下载谷歌浏览器驱动。
谷歌浏览器驱动下载地址:https://vikyd.github.io/download-chromium-history-version
查看谷歌浏览器版本 右上角三个点 -> 帮助 -> 关于
我们下载解压后的驱动,放到项目代码同级目录即可,方便测试。
安装下 selenium 模块
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple

知识点:
导入selenium的webdriver模块和time模块,使用time.sleep(5)设置 5 秒固定延时,等待 CSDN 首页(JS 动态渲染页面)完全加载,避免因页面未加载完成导致获取的源码不完整。
通过webdriver.Chrome()实例化 Chrome 浏览器操作对象,启动本地 Chrome 浏览器。
调用浏览器对象的get()方法访问 CSDN 首页,模拟浏览器加载网页并自动执行页面中的 JS 代码,实现动态内容渲染。
利用browser.page_source属性获取浏览器执行 JS 后完整的页面 HTML 源码(区别于requests获取的未渲染原始源码),解决 JS 动态渲染网站的数据获取问题。
打印获取到的页面源码,验证动态渲染后的网页内容是否成功获取。
核心应用:针对 JS 动态渲染的网站(如 CSDN),使用 selenium 模拟真实浏览器行为,获取静态请求无法得到的完整页面内容。
(三)selenium 元素的定位
知识点:
单元素定位方法:使用find_element()方法定位页面中第一个匹配条件的元素,返回单个元素对象。
多元素定位方法:使用find_elements()方法定位页面中所有匹配条件的元素,返回元素列表。
ID 定位:通过By.ID结合元素 id 属性值(如'su')精准定位单个元素。
标签名定位:通过By.TAG_NAME结合标签名称(如 'input')获取所有匹配该标签的元素列表。
name 属性定位:通过By.NAME结合标签 name 属性值(如 'wd')获取所有匹配该属性的元素列表。
XPath 定位:通过By.XPATH结合 XPath 表达式(如 //input [@id='su'])获取匹配的元素列表,支持基于属性的精准筛选。
CSS 选择器定位:通过By.CSS_SELECTOR结合类选择器(.s_ipt_wr)、ID 选择器(#su)定位单个元素。
链接文本定位:By.LINK_TEXT匹配完整链接文本(如 "新闻")定位单个元素;By.PARTIAL_LINK_TEXT匹配部分链接文本(如 "新")获取所有匹配的元素列表。
类名定位:通过By.CLASS_NAME结合元素 class 属性值(如's_ipt')定位单个元素。
元素类型查看:打印定位到的元素及对应的类型,区分单元素对象与多元素列表的类型差异。


(四)selenium 获取元素信息
知识点:
使用 selenium 库进行浏览器自动化操作,通过 webdriver.Chrome() 创建 Chrome 浏览器对象。
调用 browser.get(url) 实现打开指定网页的操作。
使用 find_element(By.ID, 值) 按照 ID 选择器定位页面元素。
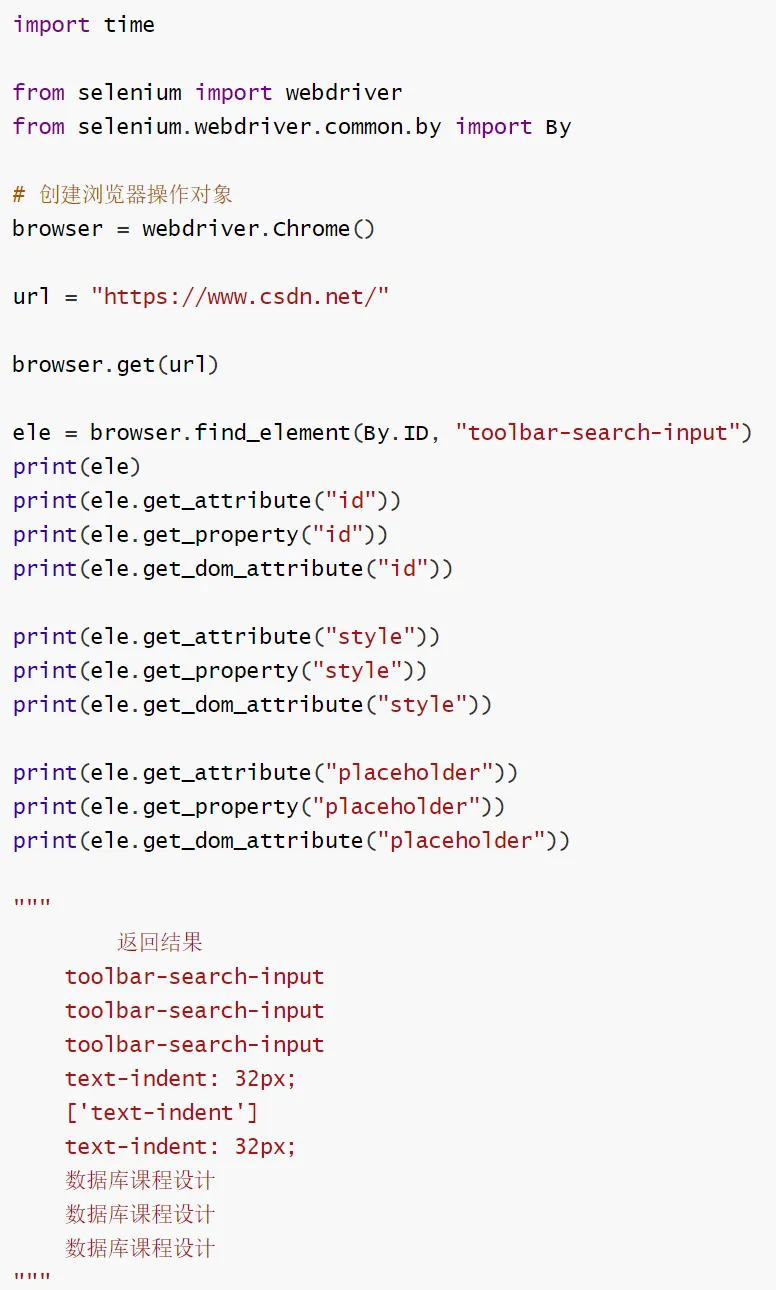
掌握 get_attribute 方法:获取元素HTML 标签上的属性值。
掌握 get_dom_attribute 方法:获取元素原始的 DOM 属性。
掌握 get_property 方法:获取元素DOM 对象的属性(动态属性也能获取)。
了解三类获取属性方法在 id、placeholder、style 等常见属性上的表现与区别。
导入并使用 time 模块,为后续延时、等待操作提供支持。
理解 selenium 中元素定位与属性提取的基本流程。
三个方法的区别及解释
get_attribute():相当于「直接看 HTML 源码里写了啥」,比如`,它就取源码里id/style`的字面值。
get_dom_attribute():相当于「浏览器刚解析完 HTML,还没执行 JS 时,DOM 节点里存的原始值」,和源码值基本一致,但仅针对 HTML 声明的属性。
get_property():相当于「浏览器运行时,DOM 对象实际的属性值」,可能是 JS 动态改的、浏览器自动加的(比如checked属性,源码是checked="checked",但 property 值是True)。
总结
get_attribute 取HTML 源码声明的属性值(字符串),是通用首选;
get_dom_attribute 取DOM 解析后的原始属性值,与源码高度一致,极少单独使用;
get_property 取DOM 对象的运行时属性值(可能是布尔 / 对象 / 数组),仅适配动态属性场景。
(五)selenium 交互
知识点:
元素定位:使用By.ID定位文本输入框和提交按钮,使用By.XPATH定位下一页按钮。
元素交互操作:通过send_keys()方法向文本输入框输入指定内容(Python),通过click()方法模拟鼠标点击按钮(提交按钮、下一页按钮)。
执行 JavaScript 代码:调用execute_script()方法执行 JS 语句实现页面滚动,包括滚动到底部(window.scrollTo/document.documentElement.scrollTop)和滚动到顶部(document.documentElement.scrollTop=0)。
浏览器历史记录控制:使用back()方法模拟浏览器返回上一页操作,使用forward()方法模拟浏览器前进下一页操作。
浏览器资源释放:通过quit()方法关闭浏览器并释放相关资源,完成自动化操作后的收尾。
自动化操作流程控制:通过多次延时和有序的交互、页面控制操作,模拟真实用户的浏览、输入、点击、翻页、滚动等行为。


(六)selenium 无界面 headless
知识点:
Chrome 无头模式高级配置:启用新版--headless=new参数(渲染效果更贴近有界面模式),配置--disable-gpu参数并修正符号格式,添加--window-size=1920,1080参数设置浏览器窗口尺寸,优化无头模式下元素交互的兼容性。
自定义 Chrome 浏览器路径:通过Options对象的binary_location属性手动指定本地 Chrome 可执行文件的绝对路径,解决 selenium 自动识别浏览器路径失效的问题。
浏览器实例化:结合自定义配置的Options对象创建 Chrome 浏览器操作对象,实现个性化的浏览器启动参数设置。
元素点击的容错处理:优先尝试原生click()方法模拟真实用户点击元素,捕获点击异常后,采用执行 JavaScript 代码的备用方案触发元素点击,绕过元素可见性、可交互性等限制。
JavaScript 代码执行:调用浏览器对象的execute_script()方法执行 JS 语句,传入元素参数实现对指定元素的精准点击操作。




结束语
1
后续我会持续输出优质、实用的内容,也欢迎大家在评论区留言,说说你们最想学习的内容、遇到的困惑,我们一起交流、一起进步。
愿每一位软件人,都能在这里收获知识、突破自我,在自己的赛道上发光发热✨
以上内容仅做学习所用,如有侵权联系必删

