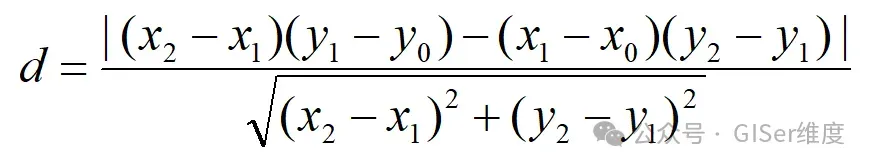目标:假设数据库里有一条河流的10个坐标数据,地图缩小时不需要显示全部坐标,这个时候可以对河流进行简化道格拉斯-普克算法(Douglas-Peucker algorithm)是一种用于简化折线(由一系列点组成的曲线)的经典算法。它的核心目的是:在保持曲线整体形状特征的前提下,通过减少点的数量来降低数据的复杂度。该算法广泛应用于计算机图形学和数据压缩。| 假设有一条由n个点组成的折线,设定简化的阈值为E: |
| 1)连接首尾:在折线的起始点A和终止点B之间连一条直线段AB(作为基准线)。 |
| 2)找最远点: 遍历起始点和终止点之间的所有中间点,计算每个点到直线AB的垂直距离。找到这些点中距离直线AB最大的点,记为P,其距离为 dmax。如果 dmax≤ E: 说明该段折线上所有的点与基准线的偏差都很小,那么这段中间的点全部可以剔除,直接用直线AB代替。如果 dmax> E: 说明点P是一个重要的特征点,必须保留。此时以点P为界,将原折线分割成AP和PB两部分。 |
| 3)递归处理: 对分割出的两部分折线分别重复上述步骤1)-3),直到所有点都被处理完毕。 |
|
数据:P1(0,0), P2(1,1), P3(2,-1), P4(5,10), P5(6,9), P6(7,11), P7(10,0), P8(12,1), P9(14,-1), P10(15,0) | |
| |
| P2:1, P3:1, P4:10, P5:9, P6:11, P7:0, P8:1, P9:1 |
| |
| |
| 结果:保留p6,分割成[p1,p6]和[p6,p10] |
| |
| |
| P2:0.31, P3:2.22, P4:1.15, P5:0.23 |
| |
| |
| 结果:保留p3,分割成[P1,P3] 和 [P3,P6] |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| P7:4.04, P8:1.84, P9:1.40 |
| |
| |
| 结果:保留p7,分割成[P6,P7] 和 [P7,P10] |
| |
| |
| |
| |
| |
| |
| |
| |
import pandas as pdimport numpy as np
data = pd.read_csv("douglas_peucker.csv", encoding='utf-8')
4)如果是直线段则无需化简,所有点都需保留,所以keeppts的所有元素都为trueif len(data) > 2: # 初始化保留标记,首尾两点默认保留 keeppts = [False] * len(data) keeppts[0] = True keeppts[len(data) - 1] = True
5)根据栈递归,距离判断,保留距离直线的距离大于阈值的点 zhongjiandian = [(0, len(data) - 1)] while zhongjiandian: start, end = zhongjiandian.pop() # 如果区间内没有中间点,跳过 if end - start < 2: continue dmax = -1 farthestidx = -1 # 获取当前区间的起点和终点坐标 x1, y1 = float(data.iloc[start, 0]), float(data.iloc[start, 1]) x2, y2 = float(data.iloc[end, 0]), float(data.iloc[end, 1]) # 在当前区间内寻找最远点 for i in range(start + 1, end): x0, y0 = float(data.iloc[i, 0]), float(data.iloc[i, 1]) #计算每个中间点到直线的距离 # 分子: |(x2-x1)(y1-y0) - (x1-x0)(y2-y1)| fenzi = abs((x2 - x1) * (y1 - y0) - (x1 - x0) * (y2 - y1)) # 分母: sqrt((x2-x1)^2 + (y2-y1)^2) fenmu = np.sqrt((x2 - x1)**2 + (y2 - y1)**2) # 计算距离(处理分母为0的极端情况) dis = fenzi / fenmu if fenmu != 0 else 0 # 记录本区间内的最远点 if dis > dmax: dmax = dis farthestidx = i if dmax > eps: keeppts[farthestidx] = True # 标记保留该特征点 # 递归分裂:将左侧区间和右侧区间分别压入栈中 zhongjiandian.append((start, farthestidx)) zhongjiandian.append((farthestidx, end))
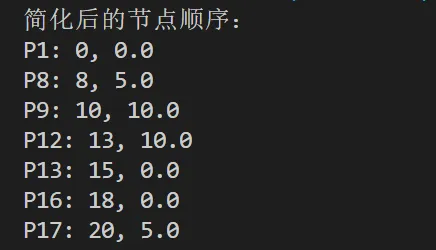
# 输出结果 print("简化后的节点顺序:") for i in range(len(keeppts)): if keeppts[i]: print(f"P{i+1}: {data.iloc[i, 0]}, {data.iloc[i, 1]}")elif len(data) == 2: print("就 2 个点,不用简化啦!")else: print("坐标点个数不对!")
import pandas as pdimport numpy as np# 1. 加载数据data = pd.read_csv("douglas_peucker.csv", encoding='utf-8')eps = 2 # 阈值E设为 2,if len(data) > 2: # 初始化保留标记,首尾两点默认保留 keeppts = [False] * len(data) keeppts[0] = True keeppts[len(data) - 1] = True # 使用栈模拟递归,存储待处理的区间 (start_index, end_index) zhongjiandian = [(0, len(data) - 1)] while zhongjiandian: start, end = zhongjiandian.pop() # 如果区间内没有中间点,跳过 if end - start < 2: continue dmax = -1 farthestidx = -1 # 获取当前区间的起点和终点坐标 x1, y1 = float(data.iloc[start, 0]), float(data.iloc[start, 1]) x2, y2 = float(data.iloc[end, 0]), float(data.iloc[end, 1]) # 在当前区间内寻找最远点 for i in range(start + 1, end): x0, y0 = float(data.iloc[i, 0]), float(data.iloc[i, 1]) #计算每个中间点到直线的距离 # 分子: |(x2-x1)(y1-y0) - (x1-x0)(y2-y1)| fenzi = abs((x2 - x1) * (y1 - y0) - (x1 - x0) * (y2 - y1)) # 分母: sqrt((x2-x1)^2 + (y2-y1)^2) fenmu = np.sqrt((x2 - x1)**2 + (y2 - y1)**2) # 计算距离(处理分母为0的极端情况) dis = fenzi / fenmu if fenmu != 0 else 0 # 记录本区间内的最远点 if dis > dmax: dmax = dis farthestidx = i # 找完整个区间的最远点后,再与阈值比较 if dmax > eps: keeppts[farthestidx] = True # 标记保留该特征点 # 递归分裂:将左侧区间和右侧区间分别压入栈中 zhongjiandian.append((start, farthestidx)) zhongjiandian.append((farthestidx, end)) # 输出结果 print("简化后的节点顺序:") for i in range(len(keeppts)): if keeppts[i]: print(f"P{i+1}: {data.iloc[i, 0]}, {data.iloc[i, 1]}")elif len(data) == 2: print("就 2 个点,不用简化啦!")else: print("坐标点个数不对!")