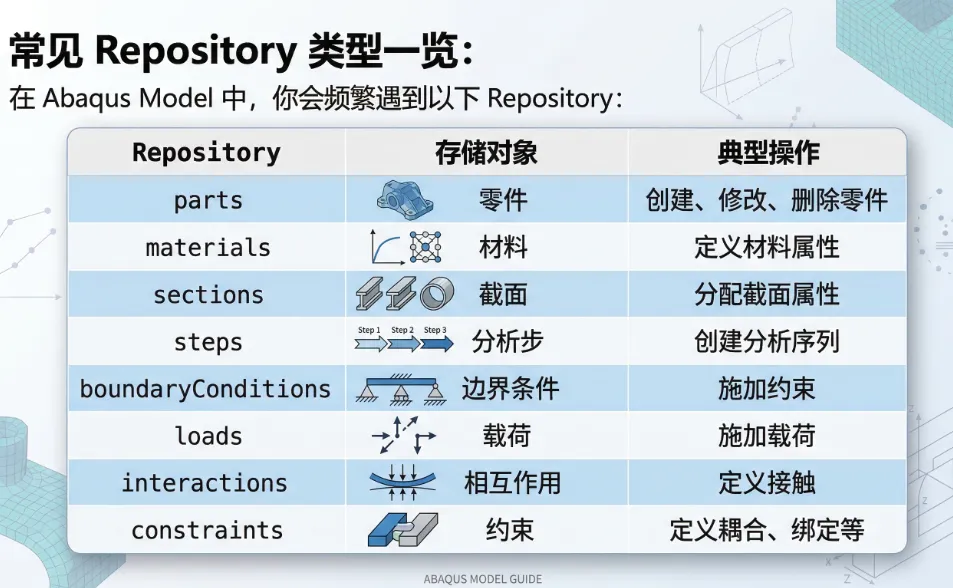
2. "批量处理"的艺术:keys() 与 values()Repository 提供了几个神级方法:`.keys()` 返回所有对象的名字,`.values()` 返回所有对象本身。
如果你想删除模型里所有的分析步(除了 Initial 步),你不需要写一万行代码:
all_steps = mdb.models['Model-1'].steps.keys()
for name in all_steps:
if name != 'Initial':
del mdb.models['Model-1'].steps[name]
这就像是你手里拿到了仓库的总清单。你扫一眼清单,发现所有带"旧版"字样的货全部一键标记。通过一个简单的 for 循环,你就从"体力劳动者"变成了"数据指挥官"。
批量操作的实战案例:
案例 1:批量重命名零件
假设你导入了一个装配体,所有零件的名字都带有前缀 "Import-",你想批量去掉这个前缀:
from abaqus import mdb
model = mdb.models['Assembly-Model']
parts_to_rename = []
# 第一步:收集需要重命名的零件
for part_name in model.parts.keys():
if part_name.startswith('Import-'):
parts_to_rename.append(part_name)
# 第二步:批量重命名
for old_name in parts_to_rename:
new_name = old_name.replace('Import-', '')
model.parts.changeKey(fromName=old_name, toName=new_name)
print(f"已重命名:{old_name} -> {new_name}")
案例 2:批量修改材料属性
假设你需要将所有钢材的弹性模量从 210GPa 调整为 200GPa:
model = mdb.models['Material-Model']
for mat_name in model.materials.keys():
mat = model.materials[mat_name]
# 检查材料是否有弹性属性
if hasattr(mat, 'elastic') and mat.elastic is not None:
# 获取当前弹性模量
current_E = mat.elastic.table[0][0]
# 如果是 210GPa 附近的值,就修改为 200GPa
if 205e9 <= current_E <= 215e9:
mat.Elastic(table=((200e9, 0.3),))
print(f"材料 {mat_name} 的弹性模量已更新")
案例 3:批量检查边界条件
在提交计算前,你想检查所有边界条件是否都正确施加到了 Initial 步:
def check_boundary_conditions(model_name):
"""检查所有边界条件的创建步"""
model = mdb.models[model_name]
print(f"\n检查 {model_name} 的边界条件:")
print("-" * 60)
for bc_name in model.boundaryConditions.keys():
bc = model.boundaryConditions[bc_name]
create_step = bc.createStepName
region = bc.region
# 检查是否施加在 Initial 步
if create_step != 'Initial':
print(f"⚠️ 警告:'{bc_name}' 创建在 '{create_step}' 步,而非 Initial 步")
else:
print(f"✅ '{bc_name}' 正确施加在 Initial 步")
# 打印作用区域信息
if hasattr(region, 'nodes'):
print(f" 作用节点数:{len(region.nodes)}")
print()
# 使用示例
check_boundary_conditions('Model-1')
遍历 Repository 的最佳实践:
# 安全删除的模式
model = mdb.models['Model-1']
# 先复制 keys 列表
keys_to_delete = list(model.parts.keys())
for part_name in keys_to_delete:
if 'TEMP' in part_name: # 删除所有带 TEMP 的零件
try:
del model.parts[part_name]
print(f"已删除:{part_name}")
except Exception as e:
print(f"删除 {part_name} 失败:{e}")
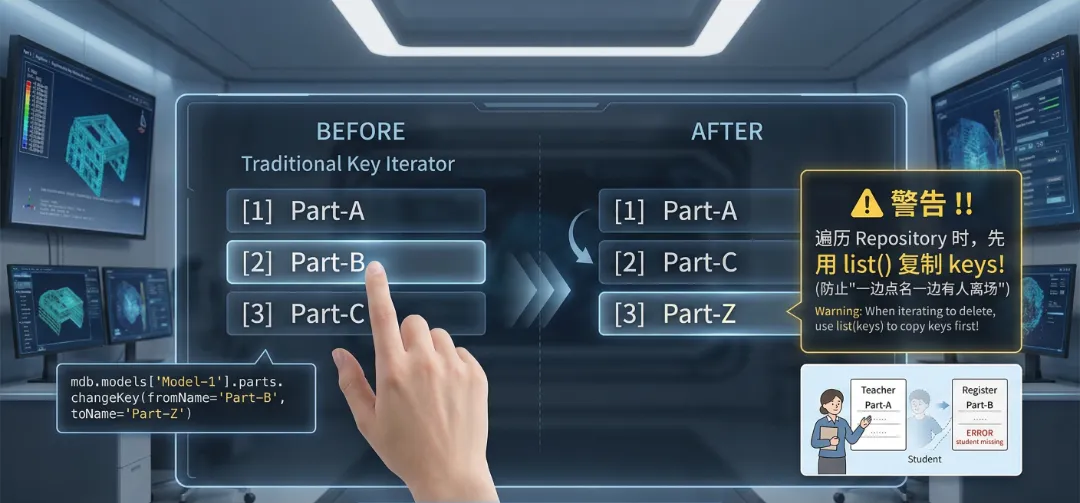
在 Repository 里,对象的 Key 和 Value 是绑定的。如果你通过 API 修改了一个零件的名字(使用 changeKey 方法),它在 Repository 里的位置也会自动更新。
由于 Repository 是动态的,在遍历它的时候如果要删除元素,最好先用 `list()` 把 keys 存下来,否则会发生"一边点名一边有人离场"的尴尬报错。
Repository 就像一个实时更新的班级名册。如果有同学改了名字,名册会自动重新排序。你可以随时随地通过 `len(mdb.models['Model-1'].parts)` 来查查你的"兵工厂"里现在到底有多少个精兵强将。
动态管理的进阶技巧:
技巧 1:使用 changeKey 安全重命名
model = mdb.models['Model-1']
# 重命名零件
old_name = 'Part-1'
new_name = 'Bracket-Base'
if old_name in model.parts.keys():
model.parts.changeKey(fromName=old_name, toName=new_name)
print(f"重命名成功:{old_name} -> {new_name}")
else:
print(f"零件不存在:{old_name}")
# 验证重命名
print("当前零件列表:", list(model.parts.keys()))
技巧 2:检查对象引用关系
在删除对象前,最好检查它是否被其他对象引用:
def check_part_references(model_name, part_name):
"""检查零件是否被其他对象引用"""
model = mdb.models[model_name]
part = model.parts[part_name]
print(f"\n检查零件 '{part_name}' 的引用情况:")
# 检查是否在装配中存在实例
for instance_name in model.rootAssembly.instances.keys():
instance = model.rootAssembly.instances[instance_name]
if instance.partName == part_name:
print(f"⚠️ 在装配中有实例:{instance_name}")
# 检查是否被截面引用
for section_name in model.sections.keys():
section = model.sections[section_name]
# 某些截面类型会引用零件
# 检查是否在分析步中被引用
for step_name in model.steps.keys():
step = model.steps[step_name]
# 检查边界条件、载荷等是否引用该零件的区域
print("检查完成")
check_part_references('Model-1', 'Bracket-Base')
技巧 3:实时监控 Repository 变化
class RepositoryMonitor:
"""Repository 变化监控器"""
def __init__(self, model_name):
self.model_name = model_name
self.model = mdb.models[model_name]
self.snapshots = {}
def take_snapshot(self, repo_name):
"""拍摄 Repository 快照"""
repo = getattr(self.model, repo_name)
self.snapshots[repo_name] = set(repo.keys())
print(f"已拍摄 {repo_name} 快照,包含 {len(self.snapshots[repo_name])} 个对象")
def compare_snapshot(self, repo_name):
"""比较当前状态与快照的差异"""
if repo_name not in self.snapshots:
print("没有可用的快照")
return
repo = getattr(self.model, repo_name)
current_keys = set(repo.keys())
old_keys = self.snapshots[repo_name]
added = current_keys - old_keys
removed = old_keys - current_keys
if added:
print(f"新增对象:{added}")
if removed:
print(f"删除对象:{removed}")
if not added and not removed:
print("无变化")
# 使用示例
monitor = RepositoryMonitor('Model-1')
monitor.take_snapshot('parts')
# ... 执行一些操作 ...
monitor.compare_snapshot('parts')
技巧 4:批量操作的原子性
对于重要的批量操作,建议实现"回滚"机制:
def batch_delete_parts(model_name, part_names, dry_run=True):
"""
批量删除零件(支持预演模式)
参数:
model_name: 模型名称
part_names: 要删除的零件名称列表
dry_run: 如果为 True,只预演不实际删除
"""
model = mdb.models[model_name]
print(f"{'[预演模式]' if dry_run else '[执行模式]'}")
print(f"准备删除 {len(part_names)} 个零件:")
for name in part_names:
if name not in model.parts.keys():
print(f"⚠️ 零件不存在:{name}")
continue
if dry_run:
print(f" - {name}")
else:
try:
del model.parts[name]
print(f"✅ 已删除:{name}")
except Exception as e:
print(f"❌ 删除失败 {name}: {e}")
if dry_run:
print("\n预演结束,未进行实际删除")
print("确认无误后,设置 dry_run=False 执行删除")
# 使用示例
parts_to_delete = ['TEMP-1', 'TEMP-2', 'TEMP-3']
batch_delete_parts('Model-1', parts_to_delete, dry_run=True) # 先预演
# batch_delete_parts('Model-1', parts_to_delete, dry_run=False) # 再执行
在 Abaqus 建模中,"看不见的代码结构比看得见的几何图形更重要"。
很多新手喜欢在脚本里写死坐标、写死名称(Hard Coding),一旦模型变复杂就彻底乱套。而高手会利用 Repository 的遍历能力,写出通用的、参数化的"神仙代码"。
Repository 最佳实践清单:
进阶思考:Repository 的设计哲学
Repository 的设计体现了几个重要的软件工程原则:
理解了这些原则,你不仅能用好 Abaqus 的 Repository,还能将这些思想应用到自己的代码设计中。
掌握了 Repository,你就不再是那个在屏幕前点鼠标的"画图仔",而是那个在代码背后调兵遣将、指挥千万网格大军的数字架构师。
👉互动话题:你有没有遇到过因为零件太多,找个名字找半天的经历?或者你最希望用脚本实现什么样的"一键批量操作"?在评论区告诉我,我来帮你写出那个关键的 for 循环!