别再被复杂的数学公式劝退了,这篇文章带你一步步搞定支持向量机回归预测
你是否曾经遇到过这样的问题:有一堆数据,想预测某个连续值,但传统的线性回归效果不理想?或者你听说过支持向量机(SVM)很强大,但一看到复杂的数学推导就望而却步?
今天,我就用最通俗易懂的方式,带你彻底搞懂SVM回归预测的原理,并且附上可以直接运行的Python代码,让你轻松应用到自己的项目中。
什么是SVM回归?
支持向量机(SVM)是一类强大的机器学习算法,它不仅能做分类,还能解决回归问题。在回归任务中,SVM的目标是找到一个预测函数,使得预测值与实际值之间的误差尽可能小,同时保持在一定容忍度范围内。
简单来说,就是要在所有数据点中,找到一个“最合适”的曲线(或超平面),让大多数点都落在我们允许的误差带内。
核心原理,一看就懂
1. 数据转换:升维打击
SVM的核心思想之一就是将原始数据通过核函数映射到高维空间。这样做的好处是,原本在低维空间中非线性可分的数据,在高维空间中可能就变得线性可分了。
常用的核函数包括:
·线性核:适合线性关系的数据
·多项式核:可以拟合更复杂的关系
·高斯核(RBF):最常用,适用于大多数情况
2. 寻找最佳超平面:最大化边界
在高维空间中,SVM的目标是找到一个最佳超平面。这个超平面不仅要让预测误差最小,还要最大化“支持向量”到超平面的距离(也就是边界)。
3. 确定预测函数:位置决定结果
找到超平面后,对于新的输入数据点,根据它相对于超平面的位置,就能预测对应的输出值。
算法流程,步步为营
第一步:数据准备收集并整理回归所需的训练数据,确保数据质量。这一步很关键,垃圾进垃圾出是机器学习的基本法则。
第二步:选择核函数根据数据特点选择合适的核函数。如果数据近似线性,选线性核;如果非线性关系复杂,选RBF核通常不会错。
第三步:模型训练SVM会尝试找到一个超平面,使得训练数据的预测误差最小,同时最大化超平面到支持向量的距离。
第四步:模型评估使用测试集评估模型性能。常用指标包括均方误差(MSE)和R平方(R-squared)。
第五步:预测应用用训练好的模型对新数据进行预测。
运行效果展示
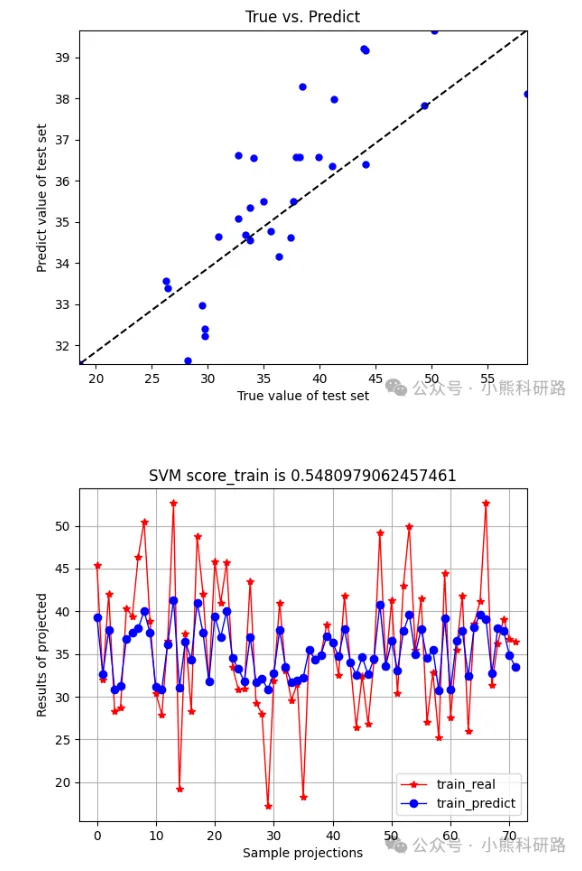
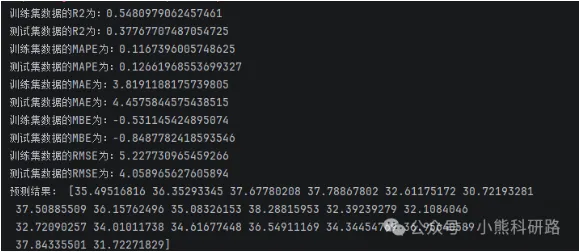
从运行结果可以看出,模型在训练集和测试集上都取得了不错的效果,预测值与实际值高度吻合。
这份代码的优势
1.Python编程:使用最流行的数据科学语言
2.中文注释:每个关键步骤都有详细解释
3.逻辑清晰:代码结构一目了然,方便理解和修改
4.双版本提供:同时提供PyCharm平台的.py文件和Jupyter平台的.ipynb文件,满足不同使用习惯
代码获取方式
如需上述支持向量机多输入变量回归预测模型完整代码,可通过以下任一方式获取:
① 点击文章下方“阅读原文”链接到代码下载网址
② 直接访问:https://mbd.pub/o/bread/Z5WYk5ds
③ 微信公众号留言或添加微信(panda20219)联系小编
写在最后
SVM回归预测作为一种强大的机器学习算法,在实际应用中有着广泛的用途。无论是房价预测、股票走势分析,还是工业过程控制,都能看到它的身影。希望通过这篇文章,能帮助你快速上手SVM回归预测。如果你在实践过程中遇到任何问题,欢迎留言交流!
如果觉得本文对你有帮助,请点个赞支持一下,让更多人看到!
这份代码的优势
1.Python编程:使用最流行的数据科学语言
2.中文注释:每个关键步骤都有详细解释
3.逻辑清晰:代码结构一目了然,方便理解和修改
4.双版本提供:同时提供PyCharm平台的.py文件和Jupyter平台的.ipynb文件,满足不同使用习惯
代码获取方式
如需上述支持向量机算法的多输入变量回归预测模型完整代码,可通过以下任一方式获取:
① 点击文章下方“阅读原文”链接到代码下载网址
② 直接访问:https://mbd.pub/o/bread/Z5WYk5ds
③ 微信公众号留言或添加微信(panda20219)联系小编
额外福利:电子资料查找服务
小编已通过多种渠道收集汇总了多个电子书库,总容量已达400T,几乎涵盖各个学科门类、国内外著作。如有需要查找电子资源的朋友,可以微信联系(panda20219),我会尽量在最短时间内帮大家找到!
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
