试用阿里云ARMS服务定位python服务OOM问题
背景
- 部署python常驻任务服务, 消费MQ消息执行耗时任务, 服务配置 0.5C1G
- SAE事件订阅 -> 收到OOM告警, 可以用
dmesg -T 查看内核OOM日志 - SAE基础监控 -> 监控为一段时间内的统计, 最小粒度是
分钟, 而OOM是峰值, 日常内存占用500M
尝试代码添加内存使用日志
- 只添加atexit订阅 -> 增加
signal订阅, 兼容SAE中服务重启/OOM等场景 -> 定时输出, 方便发布后查看日志确认是否满足需求
最短路径原则: 问AI给下日志输出样例 -> 本地验证 -> 发布后查看日志
日志样例:
content:2026-02-26T13:05:05.571691857+08:00 stdout F 2026-02-26 13:05:05.570|INFO|cf5bf2da3a1d436596b39f63cbc759db|2:139636675693440:2|print_memory_snapshot:utils.memory_monitor:37|===== mem_top3 (total=1.13MB) =====content:2026-02-26T13:05:05.57369726+08:00 stdout F 2026-02-26 13:05:05.573|INFO|cf5bf2da3a1d436596b39f63cbc759db|2:139636675693440:2|print_memory_snapshot:utils.memory_monitor:40|0.037MB - /usr/local/lib/python3.10/urllib/request.py:474 - /usr/local/lib/python3.10/urllib/request.py:474: size=37.7 KiB, count=552, average=70 B
完善后的版本如下:
# utils/memory_monitor.pyimport asyncioimport atexitimport signalimport sysimport tracemallocfrom typing import Optionalfrom utils.log_util import loggerclassMemoryMonitor: _initialized: bool = False _monitor_task: Optional[asyncio.Task] = None @classmethoddefinit( cls, enable_tracing: bool = True, enable_periodic_check: bool = True, check_interval: int = 300, ):if cls._initialized: logger.warning("MemoryMonitor already initialized")returnif enable_tracing: tracemalloc.start() logger.info("Memory tracing started")defprint_memory_snapshot(top_n: int = 10):ifnot tracemalloc.is_tracing():return snapshot = tracemalloc.take_snapshot() top_stats = snapshot.statistics("lineno") total_size = sum(stat.size for stat in top_stats) total_mb = total_size / 1024 / 1024 logger.info(f"===== mem_top{top_n} (total={total_mb:.2f}MB) =====")for stat in top_stats[:top_n]: size_mb = stat.size / 1024 / 1024 logger.info(f"{size_mb:.3f}MB - {stat.traceback[0]} - {stat}")defsignal_handler(signum, frame): logger.info(f"Received signal {signum}, printing memory snapshot...") print_memory_snapshot() sys.exit(0) signal.signal(signal.SIGTERM, signal_handler) signal.signal(signal.SIGINT, signal_handler) atexit.register(print_memory_snapshot) cls._initialized = True cls._print_memory_snapshot = print_memory_snapshot cls._check_interval = check_interval cls._enable_periodic_check = enable_periodic_check logger.info("MemoryMonitor initialized") @classmethodasyncdefperiodic_check(cls, stop_event: Optional[asyncio.Event] = None):ifnot cls._initialized ornot cls._enable_periodic_check:return logger.info(f"Starting periodic memory check every {cls._check_interval}s")whileTrue:if stop_event and stop_event.is_set():breaktry: cls._print_memory_snapshot(top_n=3)except Exception as e: logger.error(f"Failed to print memory snapshot: {e}")await asyncio.sleep(cls._check_interval) @classmethoddefprint_snapshot_now(cls, top_n: int = 10):if cls._initialized and hasattr(cls, "_print_memory_snapshot"): cls._print_memory_snapshot(top_n)
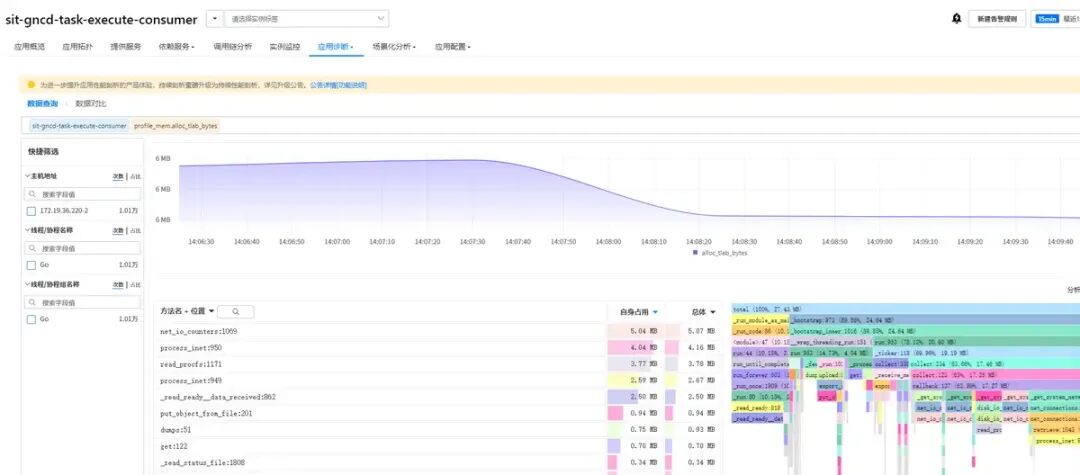
试用ARMS-性能剖析-内存热点
上一步发现, 增加日志打印查看到到内存, 和SAE-基础监控中的内存占用差异很大, OOM时也没查看到对应的日志
尝试 memory profile 相关方案, 发现 ARMS 有相关功能: 为Python应用开启持续剖析并分析性能数据
记录下尝试过程的一些弯路:
- 推荐使用阿里云提供的
chat-AI助理, 阿里云帮助文档作为知识库, 准确性和效率比自己查帮助文档快多了 - 注意验证引用的文档, AI助理的回复没有
引用文档的地方要注意辨认
- ARMS-性能剖析 是否支持python -> 文档入口是说的java, 虽然问了AI助理说明支持, 由于一直没找到的上面的文档, 纠结了很久
- 现有服务之前使用过arms, 但是探针版本较低, 需要升级 探针(Python Agent)版本说明
- 如何升级, 直接使用阿里云提供chat, 能很快查询到升级命令
- 使用ARMS探针, 应用内存占用从 500M->1G, 原配置只有0.5C1G, 很容易OOM, 要注意升级SAE应用规格
aliyun-bootstrap -a uninstall && aliyun-bootstrap -a install -v 2.4.1
实际使用后, 和上面增加内存使用日志一样, 监控到的内存占用和服务实际使用的内存占用, 差异很大, 发生OOM时也无法定位到实际内存热点
- OOM是内存峰值, 建议查看内存使用中的
最大值而非平均值
- ARMS-性能剖析-内存热点监控的内存占用很小
写在最后
本次针对 Python 服务 OOM 问题定位的尝试, 虽然通过 tracemalloc 自研监控和引入 ARMS 持续剖析都没有直接定位到导致 OOM 的具体业务代码行, 但总结了以下经验教训:
- 应用层 vs 系统层内存差异: Python 的
tracemalloc 或 ARMS 探针捕获的是 Python 虚拟机管理的堆内存, 而非进程总内存. 如果问题出在 C 扩展 (如 numpy/pandas 底层), 外部二进制调用或大文件读取产生的缓冲区, 应用内监控往往会有巨大的观测偏差 - 监控工具的副作用: 在资源极其有限的实例 (如 0.5C1G) 上, 开启 ARMS 持续剖析或开启详细的内存追踪会引入显著的内存开销 (本次观察到探针本身占用约 300-500 MB), 这可能导致服务在捕获到现场前就因监控工具本身而加速 OOM
- 善用云平台 AI 助理: 阿里云 Chat-AI 在处理 "探针升级命令", "特定云产品文档索引" 等指令性任务时效率远高于手动查阅, 但需注意其在缺乏引用时的信息准确性
- AICoding 直接辅助分析: 面对复杂的业务逻辑, 可以直接让 AICoding 工具 (如 GitHub Copilot) 扫描代码文件. AI 能够比开发者更快速地识别出潜在的 OOM 风险点 (如缺失的对象销毁、异常重试中的内存累积、循环中的闭包陷阱等), 提供直截了当的代码修复建议
- 分而治之: 若应用层工具失效, 应回归系统层使用
valgrind 或 py-spy 等外部观察器 - 升配观察: 先将实例规格翻倍, 留足监控工具的运行空间, 观察内存上涨斜率和触发的任务特征, 往往比深挖代码更有效
- 关注并发与重试: 消费 MQ 任务时, 往往是并发数过高或单条大消息处理失败进入死循环重试导致的瞬时峰值内存超限, 建议从流控和任务分片入手优化
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
