学习Python基础之前,我们先学习一下关于计算机的基本知识。
第一阶段:计算机底座与环境准备
计算机组成原理回顾
硬件五大部
硬件五大部: 控制器、运算器、存储器、输入设备、输出设备(理解数据流向)。
它们的几大关系如下:
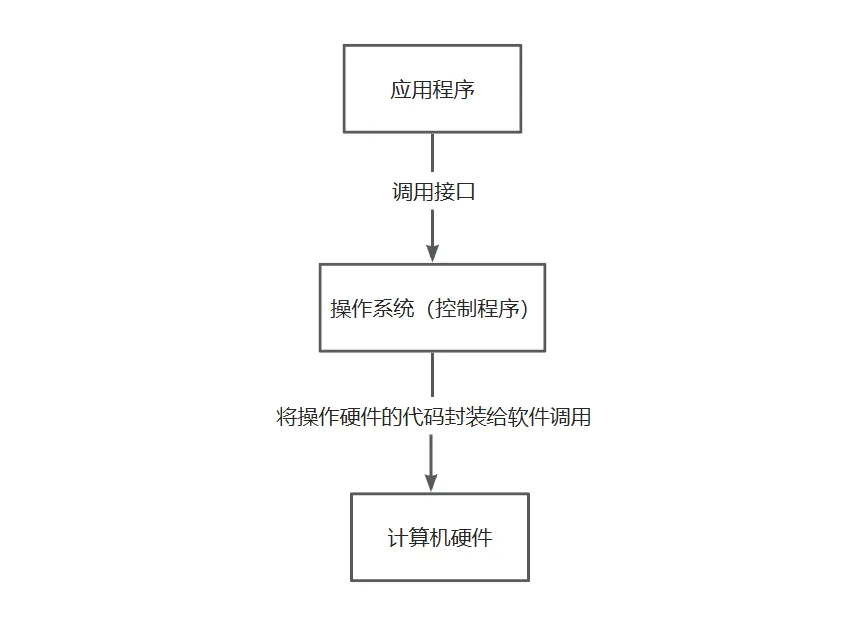
操作系统(OS)的角色
操作系统是什么?
电脑底层只认识 0 和 1 这种极其复杂的电脉冲信号,人类根本看不懂。操作系统把那些复杂的底层代码,变成了你可以用手指点击的“图标”、可以拖拽的“窗口”、可以打字的“键盘”。
主要作用是:屏蔽底层复杂脉冲信号,提供人性化接口。
比如,你在屏幕上点了一个叉号关掉网页,操作系统就会在零点几毫秒内,把它翻译成几万条机器指令,告诉底层硬件去释放内存、切断信号。
应用程序--操作系统---计算机硬件 的关系如下:
编程语言图谱
分类标准:从执行效率 vs 开发效率 vs 跨平台性。
- 机器语言 > 编译语言 > 高级语言(编译型>解释型)
- 机器语言< 编译语言< 高级语言(编译型<解释型)
Python 的定位:解释型、高级、跨平台。
Python 环境与编程素养
多版本共存: 通过重命名可执行文件(如 python2.exe, python3.exe)实现终端灵活切换。
python --->python3的版本python2 --->python2的版本
参考python文件中的pip.exe的多版本实现方式(复制多分pip.exe,修改文件名):
我们也将python.exe进行复制多份,比如python.exe 复制一份python2.exe ,python3同理
这样我们在终端运行 python2.exe 就可以启用python2版本
开发编程习惯
- 注释艺术: 每个代码关键处要写注释(可以理清楚编程的思维逻辑,同时一段时间后看注释可以减轻自己的理解难度)
- 自然语言转译:实现某种功能,学会用注释自然语言转为工具语言
- 命名规范*:变量名的命名要见名知意,可用下划线进行连接表示变量名(如cat_of_age)
第二阶段:Python 核心语法精要
变量与内存本质
核心三要素
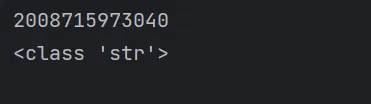
id() (地址)、type() (类型)、value (值)。
name='123'print(id(name)) # 打印变量的内存映射地址print(type(name)) # 打印变量的类型# 地址 (id):变量在内存中的存储位置,如 140234567890# 类型 (type):变量的数据类型,这里是 str(字符串)# 值 (value):变量存储的具体内容,这里是 '123'
变量名: name ↓┌─────────────────────────────┐│ 内存中的对象 │├─────────────────────────────┤│ 地址 (id): 0x7f8a2c1b3e40 │ ← 对象的位置│ 类型 (type): str │ ← 对象的数据类型│ 值 (value): '123' │ ← 对象的实际内容└─────────────────────────────┘
判等逻辑
is 比较的是数据地址是否相同
== 比较的是内容是否相同
name1='123'name2='456'name3='123'print(id(name1) isid(name3)) # is 比较的是内存地址是否相同print(name1==name3) # == 比较的是变量的值是否相同
a = [1, 2, 3]b = [1, 2, 3]c = aprint(a == b) # True (内容一样,都是[1,2,3])print(a is b) # False (不是同一个列表,内存中两份)
总结:"等值用双等,等身用is"
is 比身份,就像比两个人的身份证号(常用 is 用来判断是否为None)
# ✅ 好的做法if result == "success": # 比较字符串内容if count == 10: # 比较数字if data isNone: # 检查None,大部分需要用到的就是这个地方,使用is来判断是否为Noneif obj1 is obj2: # 检查是不是同一个对象# ------------------------------------------------------# ❌ 不好的做法if result is"success": # 不要用is比较字符串if count is10: # 不要用is比较数字if data == None: # 不要用==检查None
常量约定
全大写变量名(逻辑约束而非硬约束)。
基本输入输出(I/O)
输入
input()函数接收到的数据类型都是字符串string,如果需要进行运算就得要进行数据转换
age=input('请输入年龄:')print(age,type(age))age=int(age) # int只能转换整数类型的字符串,浮点型的、或者有其他字符的字符串都不能转换print(age+1,type(age))
格式化输出
f-string方式
name='韩信'height=1.88print(f'姓名:{name},身高:{height:.2f}') # :.2f 表示保留两位小数
数据类型进阶
可变类型和不可变类型
判断是否为可变类型:修改之后是否会开辟新的内存空间
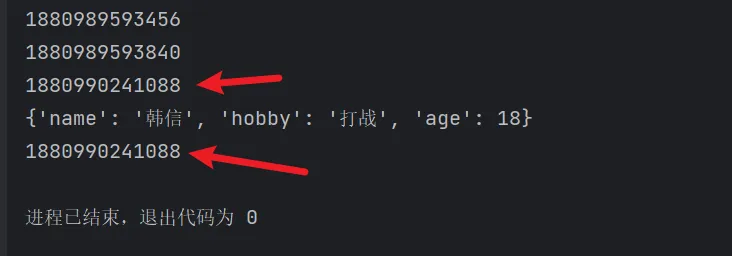
name='韩信'print(id(name))name='刘邦'print(id(name))dict={'name':'韩信','hobby':'打战'}print(id(dict))# 增加一个键值对dict.update({'age':18})print(dict)print(id(dict))
修改字典之后,字典的地址没有发生改变;name的地址发生了改变。
bool逻辑
只有两种类型 True False
会为 False 只有 0,None,空容器( [],{},'' )
剩下其他有值的都是 True
第三阶段:数据容器深度拆解
字符串(String)操作
清理strip()
字符串功能函数 strip,默认去掉字符串两旁的空格,中间有空格是不会被去掉的
hobbies=' a ,b,c'print(hobbies.strip())
指定去除两边的元素
info="!!!!!!!!!!@@@@@@@@ 123@!4 56789 !!!@@@@@@@@!!!!"# print(info.strip()) #1234 56789print(info.strip("!@")) # 123@!4 56789print(info.lstrip("!@")) # 去除左边的print(info.rstrip("!@")) # 去除右边的
切割split与拼接Join
在 Python 中,join 是字符串(String)的方法,处理对象是可迭代对象(列表、元组等),表示拼接字符串(可以理解为万能胶水),不是列表(List)的方法!!!
a=['a','b','c']# 连接字符串.join(可迭代对象)b='-'.join(a)print(b) # 输出结果 a-b-c
split也是String的方法处理对象是字符串,按照指定的分隔符进行分割,返回存储方式为列表
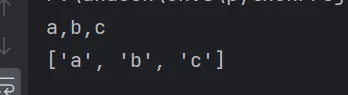
hobbies='a,b,c'print(hobbies)# 把字符串转为列表hobbies=hobbies.split(',') print(hobbies)
name="1,2,3,4,5,6,7,8,9"print(name.split(",")) # ['1', '2', '3', '4', '5', '6', '7', '8', '9']print(name.split(",",1)) # ['1', '2,3,4,5,6,7,8,9']print(name.split(",",1)) # 默认从左往右的print(name.rsplit(",",1)) # 从右往左切分
Join和split合起来的案例
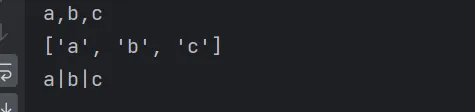
hobbies='a,b,c'print(hobbies)# 把字符串转为列表hobbies=hobbies.split(',') print(hobbies)# 把列表转为字符串hobbies='|'.join(hobbies) # 把可迭代对象拆开,用 | 胶水连接print(hobbies)
字符串变换
info="aBcd"print(info.upper()) # ABCDprint(info.lower()) # abcd
查找替换与判断
startswith(), endswith(), replace()、find、index
startswith() 判断字符串是否以什么开头
- find() 返回查找元素的下标值,不存在返回-1
info="aBcd"print(info.startswith("a")) # Trueprint(info.endswith("d")) # Trueprint(info.replace("a","A",1)) # ABcd 1表示替换一次print(info.find("a"))print(info.index("a"))
切片索引
[start:stop:step],步长为负的翻转技巧。
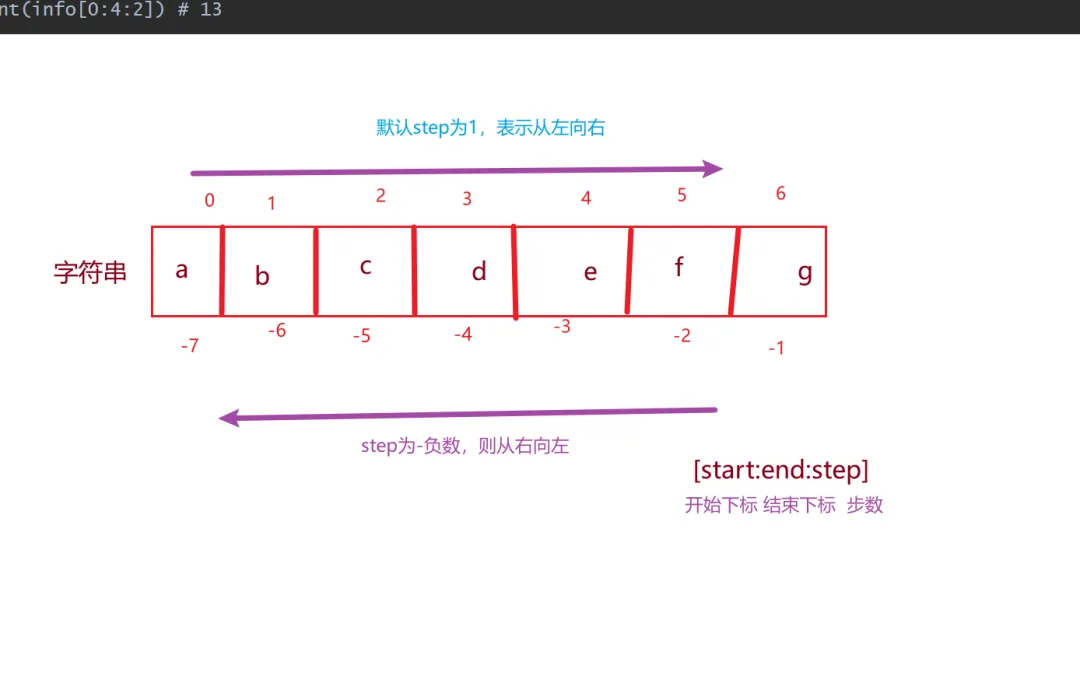
info="abcdefg"# 索引取值print(info[0])# 切片操作print(info[0:2]) # 顾头不顾尾 12print(info[-2:-1]) # 8print(info[0:-1]) # 12345678print(info[0:]) # 123456789 第二个省略表示从头取到尾print(info[::-1]) # 987654321,从后往前取,不修改默认从前往后取print(info[4:0:-1]) # 5432 步长为负,从右向左取值print(info[0:4:2]) # 13
列表list与元组tuple
列表取值
从前往后,和从后往前取值,list列表是靠下标取值的
从前往后下标:0,1,2,3
从后往前下标:-4,-3,-2,-1
a=[1,2,3,4,5,6,7,8]# 取出最后一个值print(a[-1])# 取出倒数第二个值print(a[-2])
列表嵌套取值
# 嵌套列表取值person = [ ['张三', 18, '男', ['喝酒', '足球']], ['李四', '19', '男'], ['王五', '20', '女']]print(f"结果:{person[0][3][1]}")
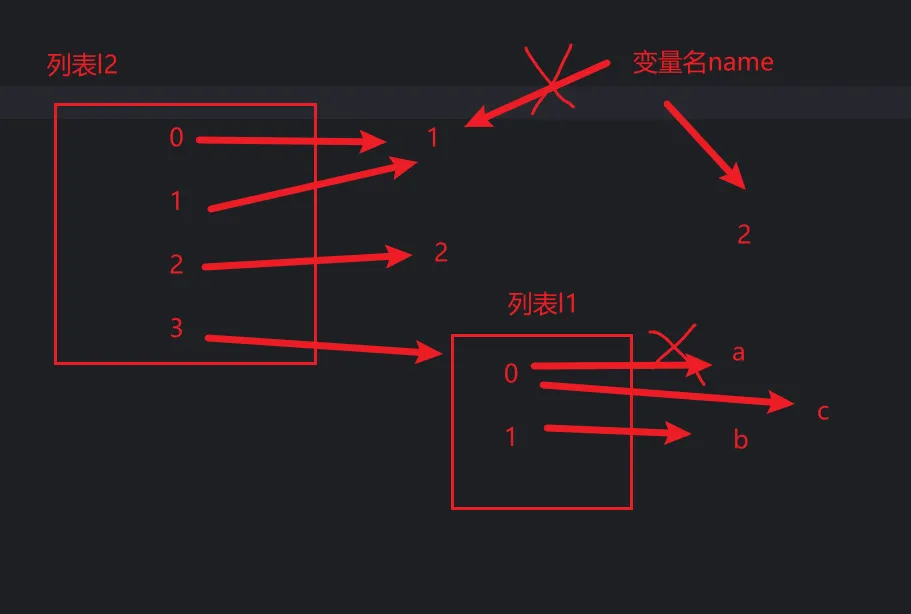
列表本质 存放的是一个地址的目录,通过索引找到对应的数据的值,是一种间接引用
name = 1l1 = ['a', 'b']l2 = [name, 1, 2, l1]# 尝试修改name的值,判断l2是否会被影响name = 2# 修改l1列表判断l2是否被影响l1[0] = 'c'print(l2)
列表转换
s="abcda"s1=["a","b","c","d","a"]s2={"a":1,"b":2,"c":3,"d":4,"a":5}print(list(s)) # ['a', 'b', 'c', 'd', 'a']print(list(s1)) # ['a', 'b', 'c', 'd', 'a']print(list(s2)) # ['a', 'b', 'c', 'd']
列表操作
增
- append(在原有的数据块修改,不会有返回值,一次添加一个元素)
- extend(在原有的数据块修改,不会有返回值,一次添加一个列表list元素)
s1=["a","b","c","d","a"]s2=["aaaaaaaaa","bbbbbbb"]s3=['2222222','3333333']s1.append("e") # 在列表的末尾添加元素eprint(s1)s1.insert(0,"z") # 在索引为0的位置插入zprint(s1)s1.extend(s3) # 将s3列表中的元素添加到s1列表的末尾print(s1)print(s4)
删
s1=["a","b","c","d","a","a"]del s1[0] # 删除索引为0的元素print(s1)s1.pop(0) # 删除索引为0的元素print(s1)s1.remove("a") # 删除第一个出现的元素aprint(s1)
查
s1=["a","b","c","d","e","a"]print(s1.index("a"))print(s1.count("a"))
序
s1=["a","b","c","d","e","a"]s1.sort() # 默认按照升序排s1.reverse() # 反转列表 实现相同的效果 print(s1[::-1])print(s1)
元组特性
元组的内存地址是不能修改的,但如果是嵌入列表,则可以修改,因为本质上列表的内存地址是没有变的(相当于是浅拷贝)
因为元组不会有元素的增加和修改,所以元组比字典更省空间 (业务功能没有那么多),元组更适合只有读取的业务功能。
注意:如果通过 () 这样定义元组,当只有一个元素会被当为字符串或者数字类型
y = (1, 1, 2, ['a', 'b', 'c'])print(y[0])# y[0]=1 # 元组的元素不能被修改print(id(y[3])) # 2015838496512print(y[3][0])y[3][0] = 'A'# 元组的元素是不可变的,但是列表的元素是可变的(只要不改变元组内存地址就可以)print(y)print(id(y[3])) # 2015838496512y1 = (1,)y2 = (1) # 元组只有一个元素时,需要在元素后面添加逗号,否则会被解释为整数print(type(y1), type(y2)) # <class 'tuple'> <class 'int'>
元组类型转换
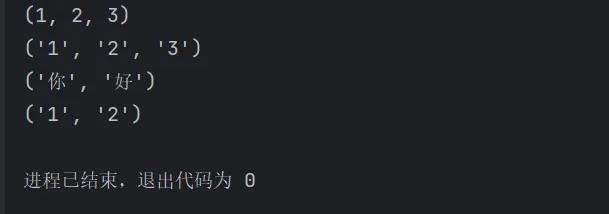
# 元组类型转换print(tuple([1,2,3])) # (1, 2, 3)print(tuple("123")) # ('1', '2', '3')print(tuple("你好")) # ('你', '好')print(tuple({"1":1,"2":2})) # ('1', '2')
查
y=('1','2','3','1')print(y.count('1')) # 计算1数字的数量print(y.index('2')) # 计算2的下标索引
经典模型(list实现)
队:先进先出(坐扶梯)FIFO(First In First Out)
栈:先进后出(坐电梯)LIFO(Last In First Out)
l=['1','3','2']# 实现队列的先进先出 FIFO# print(l.pop(0))# print(l.pop(0))# print(l.pop(0))# 实现栈的先进后出 LIFOprint(l.pop())print(l.pop())print(l.pop())
字典(Dict)与集合(Set)
字典取值
取值方式:
- 按.get 取值(更安全,如果键名不存在,可以默认为空)
# 字典a={'name':'张三','age':18}print(a['name'])print(a.get('name'))print(a.get('work','')) # 如果键不存在,则默认为空
字典+列表的形式 进行取值
# 定义一个字典和列表的嵌套格式数据person={'name':'张三','age':18,'hobbies':['a','b','c']}print(person['hobbies'][1])
列表+字典+列表的形式继续取值
# 定义一个字典和列表的嵌套格式数据,列表中每个元素都是一个字典person = [{'name': '张三','age': 18,'hobbies': ['a', 'b', 'c']}, {'name': '李四','age': 19,'hobbies': ['d', 'e', 'f'] }]print(person[0]['hobbies'][1])
字典更新与删除
update
字典更新操作
d = {"1": "a", "2": "b", "3": "c"}new_d = {"4": "d", "5": "e"}d.update(new_d) # 通过添加字典,实现字典更新print(d)d.update(a="f") # 通过添加关键字参数,实现字典更新print(d)
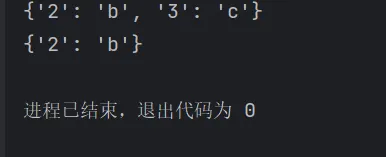
字典删除操作
d = {"1": "a", "2": "b", "3": "c"}d.pop("1") # 删除键名为1的键值对print(d)d.popitem() # 删除最后一个键值对print(d)
遍历技巧
.keys(), .values(), .items()(解包赋值)。
# 字典取值d={"1":"a","2":"b","3":"c"}print(d["1"]) # aprint(d.get("4","d")) # 如果字典中没有这个键,就返回默认值d# 如果不存在这个键,就添加这个键值对d["4"]="d"print(d)# 字典取值d={"1":"a","2":"b","3":"c"}print(d.values()) # dict_values(['a', 'b', 'c']) 迭代器,会下鸡蛋的老母鸡for i in d.values(): # 取键值print(i)for i in d.keys(): # 取键名print(i)for i in d.items(): # items() 方法返回一个包含字典所有键值对,每个元素是一个元组print(i) # ('1', 'a'),返回键值对for i,j in d.items():print(i,j)
集合运算
结合主要是用来排除相同的元素,只保留一个相同的元素,集合内不能有元组、列表,因为在python中集合数据类型要求数据是可被hash计算的固定值,容器类型的hash值都不是固定的。
集合常用来去除重复的元素。
# 定义集合a = {1, 2, 3, 4, 5, 1, 1, 1}print(a) # {1, 2, 3, 4, 5}# 定义空集合b = set()b1 = {}print(type(b)) # <class 'set'>print(type(b1)) # <class 'dict'>for i in a:print(i)c = list(a) # 将集合转为列表print(c)f = {1, 2, [1, 2]}print(f) # 报错,集合中不能有列表
集合运算
hobbies1 = {"篮球", "足球", "跑步"}hobbies2 = {"篮球", "足球", "游泳"}# for循环实现方式# both_like=[]# for i in hobbies1:# if i in hobbies2:# both_like.append(i)# print(both_like)# 取交集print(hobbies2 & hobbies1) # {'篮球', '足球'}# 取并集print(hobbies2 | hobbies1) # {'篮球', '足球', '跑步', '游泳'}# 取差集print(hobbies2 - hobbies1) # {'游泳'}# 取对称差集print(hobbies2 ^ hobbies1) # {'跑步', '游泳'}# 检查是否为子集print(hobbies2 <= hobbies1) # Falseprint(hobbies2 > {"篮球", "足球"}) # True
第四阶段:内存管理与拷贝机制
引用与存储模型
直接引用:
定义:直接引用是指一个变量名(Name)直接绑定到了内存中的某一个对象(Object)上。你可以把变量名看作是贴在对象上的一个标签。
特点:
- 通过直接引用访问对象时,只有一步查找过程:变量名 -> 对象内存地址。
a = 10b = "hello"
在这个例子中,a 直接引用了内存中的整数对象 10,b 直接引用了字符串对象 "hello"。
直接引用的重新绑定:如果你给一个直接引用的变量重新赋值,只是把标签贴到了另一个对象上,不会影响原来的对象。
a = 10b = a # a和b直接引用同一个对象 10a = 20 # a的直接引用变了,指向20。b不受影响,依然是10。
间接引用:
定义: 容器对象存储其他对象的地址。
当一个变量直接引用了一个容器对象,而这个容器对象内部又包含了对其他对象的引用时,我们就说该变量间接引用了容器内部的那些对象。
特点:
- 访问底层对象需要多步查找:变量名 -> 容器对象 -> 内部元素引用 -> 目标对象。
- 这是引发“改动一个变量却影响了另一个变量”现象的根源(特别是在包含可变对象时)。
x = [1, 2, 3] # x 直接引用了这个列表对象y = [x, 4, 5] # y 直接引用了外层列表,但【间接引用】了 x 所代表的那个内层列表
通过间接引用修改可变对象:如果你通过一个变量的间接引用,修改了内部的可变对象(比如列表的 append),那么所有包含该对象引用的变量都会受到影响。
list1 = [1, 2]list2 = [list1, 3] # list2 间接引用了 list1list1.append(99) # 修改原始对象print(list2) # 输出: [[1, 2, 99], 3] -> 间接引用的内容跟着改变了!
深浅拷贝
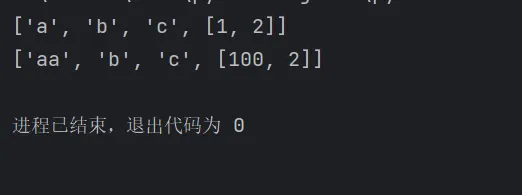
浅拷贝:浅拷贝只复制了列表的第一层(第一层只有是不可变对象才不会被改变),内层可变对象(列表)是共享的
copy()方法
list=["a","b","c",[1,2]]# 浅拷贝只复制了列表的第一层,内层列表是共享的copy_list=list.copy()copy_list[0]='aa'copy_list[3][0]=100print(list)print(copy_list)
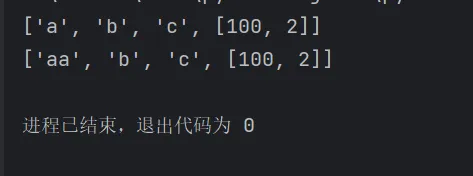
深拷贝:深拷贝会递归复制所有层级对象,内层列表也会被复制
import copylist=["a","b","c",[1,2]]# 深拷贝会递归复制所有层级的对象,内层列表也会被复制copy_list=copy.deepcopy(list)copy_list[0]='aa'copy_list[3][0]=100print(list)print(copy_list)
垃圾回收机制(GC)
Garbage Collection 简称GC:垃圾回收机制
- 标记清除机制(寻找引用为 0 的,内存空间地址,进行清除)
- 垃圾回收器会从根对象(如全局变量)出发,检查每个对象被引用的次数。如果一个对象的引用计数为0(即没有任何变量指向它),它就会被判定为“垃圾”,然后回收其占用的内存。
- 场景举例:假设对象A里有一个属性指向对象B,对象B里也有一个属性指向对象A。这样,A和B的引用计数都至少为1,但它们彼此引用,与外部世界却断开了联系,外部代码已无法访问它们。由于它们的引用计数不为0,基础回收机制就不会清理它们,导致这块内存永远无法被释放,这就是内存泄露。
- 标记清除机制(寻找所有直接或间接引用为 0 的进行直接删除内存空间地址,有效解决了上面的内存循环泄露问题)
- 如何解决问题:回到上面的循环引用例子。因为A和B都不再被根对象(如全局变量)直接或间接引用,所以在标记阶段它们不会被标记。到了清除阶段,它们就会被回收,内存泄露问题也就解决了。
- 主要目的是提升性能。当程序中变量(对象)非常多时,如果每次都扫描所有对象,代价会很大。分代回收可以避免这种情况,把精力重点放在**“新对象”区域**,对**“老对象”区域**则采取低频扫描的策略,从而在保证清理效果的同时,减少对程序运行的影响
- 生活中的例子:类似班主任根据学生统计学生完成的作业次数,根据总的次数一次来减少检查的次数。
循环引用的例子
classNode:def__init__(self, name):self.name = nameself.ref = None# 创建两个节点a = Node("A")b = Node("B")# 相互引用a.ref = bb.ref = a# 删除外部引用del adel b# 此时两个节点对象在内存中互相引用,如果没有垃圾回收机制介入,就无法被回收。
对上面的代码理解:
- 正常情况:两个人分别用手拉着旁边的栏杆(根引用)。
- 切断引用:两个人都松开了栏杆(
objA = null)。 - 循环引用:虽然他们都松开了栏杆,但却互相抓住了对方的手。从外面看,他们已经没有依靠了(外部不可达),但他们自己觉得还有人抓着自己(引用计数不为0),所以就不愿意离开(内存无法释放)。
第五阶段:流程控制与逻辑思维
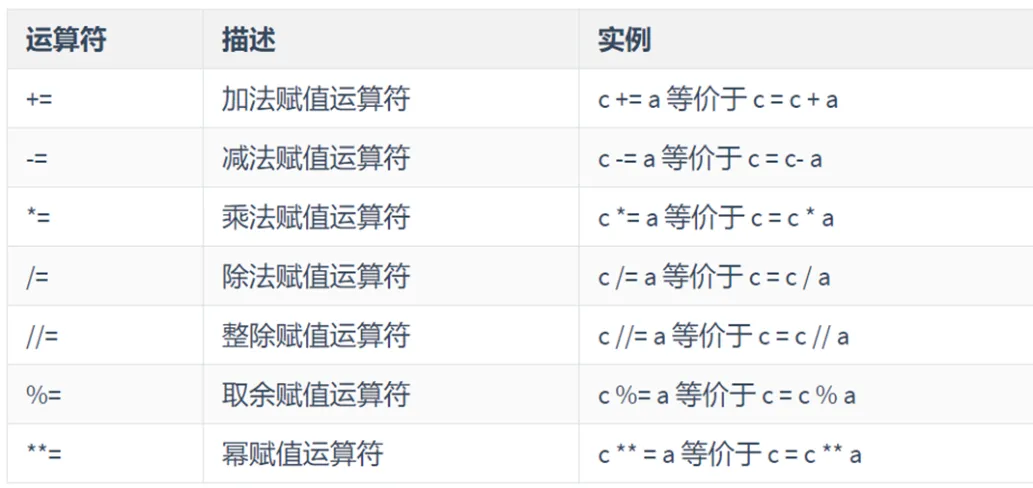
运算符优先级
算术运算符
| 运算符 | 描述 | 实例 |
|---|
| | |
| | |
| | |
| | |
| | |
| | |
| | 2 ** 4 输出结果为 16,即2的4次方,2 * 2 * 2 * 2 |
| | 小括号用来提高运算优先级,即 (1 + 2) * 3 输出结果为 9 |
符合运算符
逻辑运算符优先级
and or not
优先级:()的优先级最后not > and > or
成员运算符
in 判断某个元素或者值是否存在某个容器当中
list=["a","b","c"]print("a"inlist) # 检查元素是否存在于列表中dict={"a":1,"b":2,"c":3}print("a"indict) # 字典默认检查键是否存在print(1indict.values()) # 检查值是否存在
循环的使用
while循环
while 循环
num=0while(num<3): name=input("请输入姓名:")if name =='1':break# 执行了这一步,就不会在执行else部分的代码print("请输入1") num+=1print(f"你输入了{num}次")
while else 循环
当 while 的循环体正常结束,就会执行 else,如果异常结束,就不会执行 else
num=0while(num<3): name=input("请输入姓名:")if name =='1':break# 执行了这一步,就不会在执行else部分的代码print("请输入1") num+=1print(f"你输入了{num}次")else:print("没有输入1")
for循环
range(1000)
python3 中 range 函数是一个迭代器(包含iter和next方法),按需所给,python2 中是直接生成的。
实现案例,用for循环打印一个乘法表
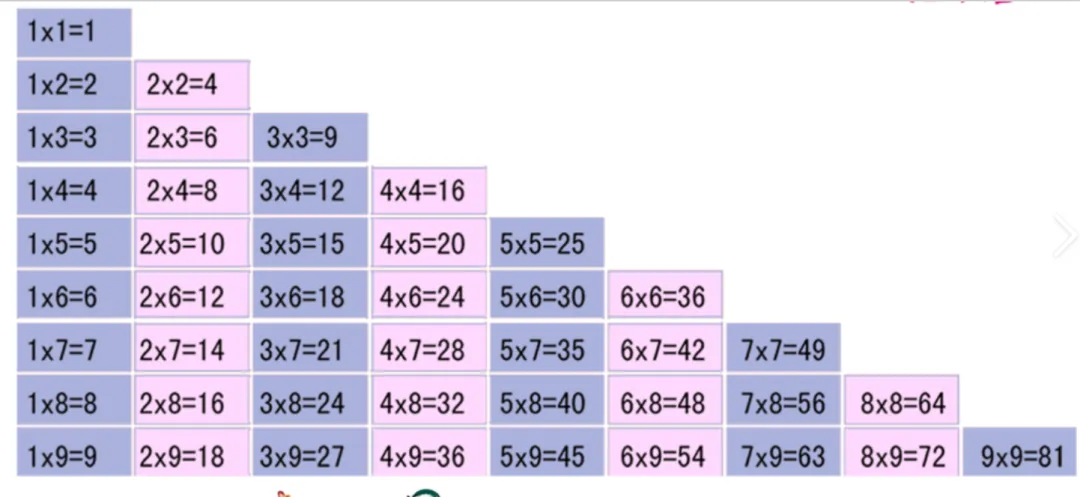
for i inrange(1,10): # 按行看,每一行的第二列数字是不会变化的for j inrange(1,i+1): # 按行看,每一行的第一列数字是递增的小于等于 iprint(f"{j}*{i}={j*i}",end='\t')print("")
数值转换
常见报错:
ValueError: invalid literal for int() with base 10: '22.1'
--->数值错误:对于 10 进制的 int 函数来说,你给的字符串是无效的
# 10进制转为2,8,16进制print(bin(12))print(oct(12))print(hex(12))# 2,8,16进制转为10进制print(int('0b1100',2))print(int('0o14',8))print(int(0xc))# 2进制转为8进制,8进制转16进制print(oct(0b1100))print(hex(int('0o14',8)))
第六阶段:文件系统操作
文件打开模式
操作模式
r, w, a 及增强模式 +。
a 和 w 模式的区别
- 用 a 模式打开存在的文件,会在文件末尾添加文件内容
一、控制文件读写操作r 只读w 只写a 追加+ 增加一个原有的模式功能 r+ 修改已有文件,默认移动光标到文件开头位置(文件指针在最前) w+ 文件不存在时,创建新文件,并且覆盖文件内容(文件指针在最前) a+ 文件不存在时,创建新文件,在文件后添加内容(文件指针在最后)
内容模式
二、控制文件读写内容操作t 文本模式 r默认是rtb 二进制模式
b模式复制图片
withopen('./image.png','rb') as f,open('./image1.jpg','wb') as f1: res=f.read(1024) # 每次读取1024字节print(res)while res: # 循环读取直到文件结束 f1.write(res) res=f.read(1024)
使用b 模式下写入文件字符串
bytes() 等同于 encode()功能
withopen('./user.txt','rb') as f,open('./user1.txt','wb') as f1: res=f.read(1024) # 每次读取1024字节print(res)while res: # 循环读取直到文件结束 f1.write(res) res=f.read(1024) f1.write(bytes("你好哦",encoding="utf-8")) # 写入字符串时需要编码为字节, 等同于 f1.write("",encoding="utf-8")
读取二进制的文本数据需要解码
withopen('./user1.txt','rb') as f: res=f.read().decode('utf-8')print(res)
上下文with管理
文件读写操作
with 表示上下文管理器,读写文件之后自动关闭文件
实现通过读取文件匹配账号密码的案例:
account=input("请输入你的账号")password=input("请输入你的密码")withopen("data.txt","r",encoding="utf-8") as f: # windows默认是gbk编码,所以要指定utf-8编码,什么编码模式,对应什么解码模式for line in f:print(line.strip().split(":")) # 表示去除字符串两边的空格 ac,pa=line.strip().split(":") # 解包赋值if account == ac and password == pa:print("登录成功")breakelse:print("登录失败")# data.txt 内容data.txtlin:123456hh:1q2w3e$R%Ttest:admin测试:测试
文件指针与监控
文件指针:seek() 偏移量、tell() 定位。
'''文件内容123你好'''"""字节分布:'1' → 1字节 (ASCII: 49)'2' → 1字节 (ASCII: 50) '3' → 1字节 (ASCII: 51)'你' → 3字节 (UTF-8: E4 BD A0)'好' → 3字节 (UTF-8: E5 A5 BD)总字节数:1+1+1+3+3 = 9字节字节索引:[0][1][2][3][4][5][6][7][8] '1''2''3' '你' '好'"""withopen('./user.txt','rb') as f:print(f.seek(1,0)) # 从文件开头(0)偏移1个字节print(f.seek(2,1)) # 从当前位置(1)偏移2个字节print(f.seek(-1,2)) # 从文件末尾(2)向前偏移1字节print(f.seek(-2,2)) # 从文件末尾(2)向前偏移2字节
'''文件内容123你好'''withopen('./user.txt','rb') as f:print(f.seek(1,0)) # 从文件开头(0)偏移1个字节print(f.tell()) # 查看当前读取位置的文件指针print(f.read().decode('utf-8'))
案例:利用文件指针实现文件监控功能
# 第二个文件withopen('./log.txt','r',encoding='utf-8') as f: f.seek(0,2) # 文件指针移动到最后while(1): res=(f.readline())if res:print(res,end='') --------------------------# 第一个文件whileTrue: money=input("请输入你要充值的余额:")if money=="-1":breakwithopen('./log.txt','a',encoding='utf-8') as f: f.write(f"小明充值了{money}元\n")
案例:分批次读取文件
withopen('test.txt', 'r', encoding='utf-8') as f:for line in f:print(line.strip()) # 一行一行读取
编码解码知识
解码:其他编码方式解码为 Unicode
编码:Unicode 编码为其他方式(如何UTF-8、ANSI)
windows命令终端默认解码是 ANSI(GBK 系列)
pycharm 终端默认是 UTF-8(Unicode 系列)
python2 的文件头可以解决变量存储的方式,print 是根据终端的解码方式来解码的
python3 的变量存储方式是 Unicode
指定文件头可以管理文件 python 解释器运行指定的解码方式
第七阶段:函数式编程工程化
函数的理解
为什么要用函数:
先是对函数为什么存在理解——》为了能在多处地方调用
如何定义函数:
大体思路就是先实现一个功能——》然后包装为函数——》根据需要替换的数值变为参数
# 第一次a=1b=2print(a+b)# ------------------------# 如果想要多次使用,就得每次复制这个代码,修改参数abdefadd(): a=1 b=1print(a+b)add()# ------------------------# 这样实现了每次都是执行add函数计算1=1的值,因为还想计算不同的值,所以就有了下面的参数defadd(a,b):print(a+b)add(1,1)# 这样就实现了每次调用不同两数之和
参数全家桶
基础参数
形式参数和实际参数
- 关键字参数(可以不按照顺序赋值,保证 key-value 格式即可)
PS:混合使用位置参数和关键字参数时:关键字参数要在位置参数后,优先位置参数。
默认形参:可在函数定义赋值初始值
可变长度形参
可变参数位置形参
defadd(*args): total=0for num in args: total+=numreturn totalres=add(1,2,2,2,2,2)print(res)
可变参数关键字形参
defadd(**kwargs): total=0for key,value in kwargs.items(): total+=valuereturn totalres=add(x=1,y=2,z=3)print(res)
* 和** 的使用方法用在实参中是打散,用在形参中是打包
具体案例如下:
deffunc(x,y,*argus):print(x,y,argus)func(1,2,3,4,5)# 1,2,(3,4,5)func(1,2,[1,2])#1,2,([1,2])func(1,2,*[1,2]) # ---> func(1,2,1,2)# 1,2,(1,2)l=[1,2]func(*l) #---> func(1,2)
deffunc(x,y,**kwargus):print(x,y,kwargus)func(**{'x':1,'y':2,'z':3}) # ---> func(x=1,y=2,z=3)# 1,2,{'z':3}
可变参数的混合使用(关键字参数要位置参数的后面)
deffunc(x,y=2,*argus,**kwargus):print(x,y,argus,kwargus)
下面是重点考察对可变长度参数的理解
deffunc1(x,y,z):print(x,y,z)deffunc2(*argus,**kwargus): func1(*argus,**kwargus)func2(1,2,z=3) # ---> func2 (1,2){'z':'3'}----> *(1,2),**{'z':'3'}-->func1 (1,2,z=3)
函数命名空间
按照优先性:
局部名称空间 > 全局名称空间 > 内置名称空间 (LEGB 原则)
函数引用机制: 定义阶段即确定,与调用位置无关。
闭包函数与装饰器
闭包函数
闭函数:在函数内部的函数,并且能调用外层函数的变量和全局变量
包函数:包含其他函数的函数
闭包函数的典型例子:装饰器(不修改源代码和调用方式下,给函数增加功能)
import timedefoutfunc(func):defwrapper(*args, **kwargs): # 位置参数、关键字参数 start = time.time() func(*args, **kwargs) # 接收原函数的参数 time.sleep(2) end = time.time()print(f"函数运行时间:{end - start}秒")return wrapper@outfuncdefgame(group, time):print("欢迎来到王者荣耀")print(f"你出生在{group}方,敌军还有{time}秒到达战场")game("红", 10)
语法糖
语法糖 @: 在不改变源码的前提下增加功能(如时间统计、权限校验)。
未使用语法糖的时候
import timedefoutfunc(func):defwrapper(*args, **kwargs): # 位置参数、关键字参数 start = time.time() func(*args, **kwargs) # 接收原函数的参数 time.sleep(2) end = time.time()print(f"函数运行时间:{end - start}秒")return wrapperdefgame(group, time):print("欢迎来到王者荣耀")print(f"你出生在{group}方,敌军还有{time}秒到达战场")game=outfunc(game)game('red','10')
使用语法糖的时候,本质相当于是替换game=outfunc(game)
import timedefoutfunc(func):defwrapper(*args, **kwargs): # 位置参数、关键字参数 start = time.time() func(*args, **kwargs) # 接收原函数的参数 time.sleep(2) end = time.time()print(f"函数运行时间:{end - start}秒")return wrapper@outfunc # 语法糖的作用就相当于 game=outfunc(game)defgame(group, time):print("欢迎来到王者荣耀")print(f"你出生在{group}方,敌军还有{time}秒到达战场")game('red','10')
匿名函数的使用
匿名函数是一种没有名字的函数,用lambda关键字定义,适用于简单的一次性使用场景。
基本语法:
lambda 参数: 表达式# 相当于:def函数名(参数):return 表达式
使用方法案例:
add=lambda x,y:x+yprint(add(1,5))
第八阶段:模块化与包管理
模块
模块module:就是 python 文件中多个功能的集合
python3 中规定模块名全是小写的,导入模块顺序是 内置模块、第三方模块、自定义模块
导入模块操作的过程:
1、执行对应的文件代码
2、将文件执行产生的变量名、函数名存入一个名称空间
3、创建一个模块对象,指向那个名称空间
模块引用案例
'''module.py 文件内容def func(x:str,y:int)->None: print(x+y) name='module-name'print('hah')def get_name()->str: print(name)'''# m=module # 模块名称空间可以赋值给一个变量,这个变量就指向了模块名称空间import module as m # 产生一个模块名称空间指向module.py文件m.func(1,2)name=111# 一个函数能看到哪些变量,取决于它被定义在哪里,而不是它在哪里被调用。m.get_name() # 获取模块中的name变量,名称空间的查找顺序是按照定义的顺序,先查找 当前名称空间,再查找模块名称空间print(name)
导入逻辑:import 与 from...import 的区别。
- from 模块名 import 函数/变量,直接导入的就是变量地址
from module import func
from module import * 易覆盖原有的变量名空间,指定模块内的 __all__来导入想导入的函数和变量
__all__=['func','get_name'] # 指定导入的函数或变量deffunc(x:str,y:int)->None:print(x+y) name='module-name'# print('hah')defget_name()->str:print(name)# print(f"module.py的{__name__}")if __name__=='__main__':print("module.py直接运行")
判断模块是被导入还是自己执行
deffunc(x:str,y:int)->None:print(x+y) name='module-name'print('hah')defget_name()->str:print(name)print(f"module.py的{__name__}")if __name__=='__main__':print("module.py直接运行")else:print("module.py被导入")
模块循环导入错误的情况
from m2 import yx = 1
from m1 import xy = 2
即从第一个文件执行 from m2 import y会去第二个文件中找y,但是第二个文件 from m1 import x 又会回到第一个文件中找x,而此时第一个文件还没有执行到第二行,所以就报错了
解决方法:
模块查找的顺序查看
import sysprint(sys.path)sys.path.append('') # 添加环境路径
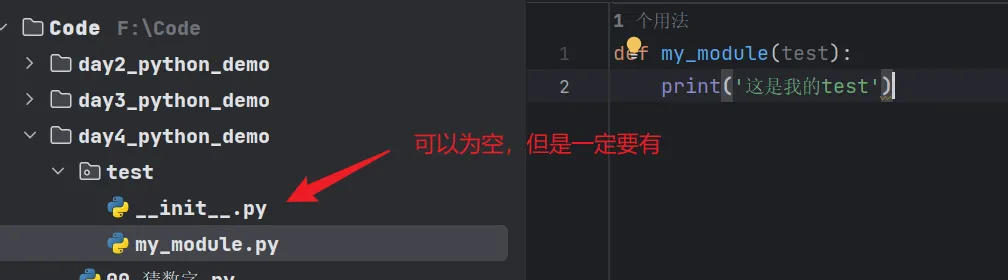
包
包package:把文件夹当作模块使用,文件夹必须要有 init.py 功能
package 就是文件夹下有一个 __init__.py 文件的文件夹,当进行 import 文件夹的时候,就会自动执行这个 init 文件。
这个的原理:把相同的功能文件分配到其他文件,然后在 init.py 文件中进行导入,外界在导入这个 package 就会运行 init.py,从而实现以为导入一个文件的效果。
导入方式:
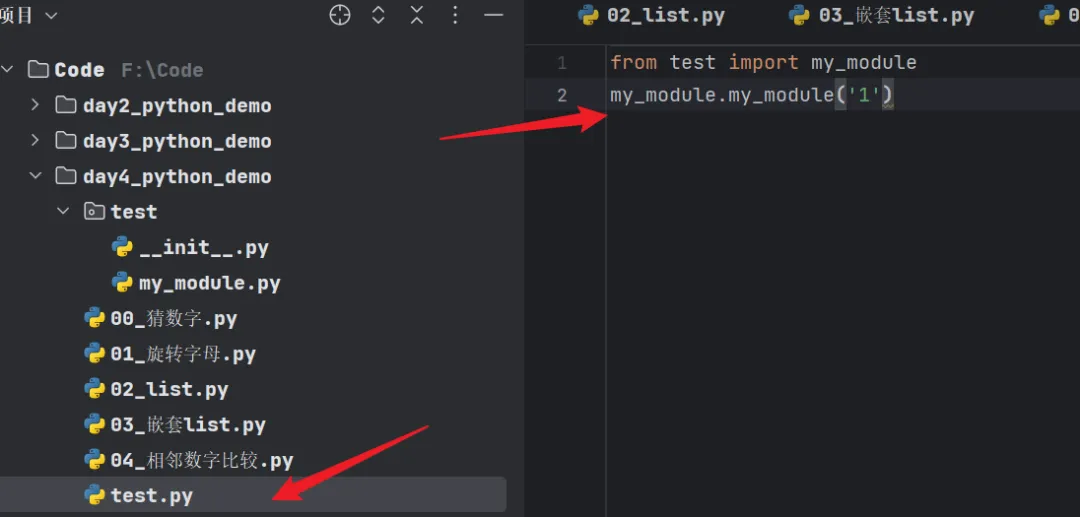
运行结果
以上就是Python的基础语法知识,掌握了这些基础知识,Python中绝大部分代码我们都是可以看得懂的,还有一部分进阶的python基础(类与对象),下一次更新。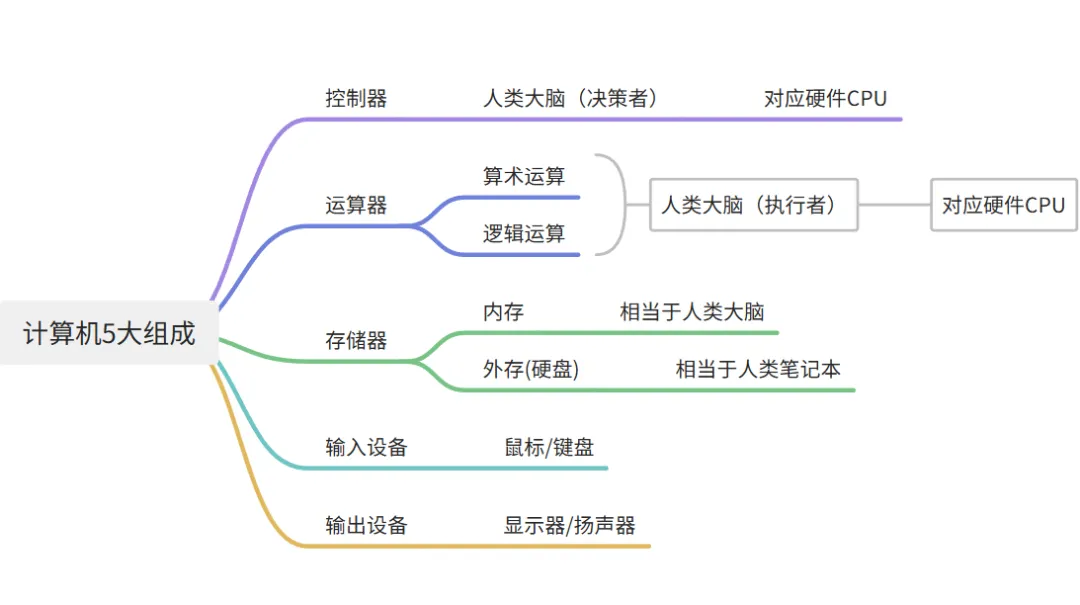



















 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
