在Linux操作中,大家应该经常碰到这些困惑:下载的文件不知道能不能打开、修改后缀后仍无法使用、批量文件不会分类等,其实一个file命令就能全部解决。
虽然file对许多人员来说比较陌生,但这个瑞士军刀能够精准识别文件真实类型,不依赖文件名后缀,是linux系统运维人员都必备的基础工具。今天我就用最简洁的内容,讲清它的核心用法和实战技巧。
一、file作用
file命令通过分析文件头部特征,识别文件真实类型,不依赖后缀名。不管文件有没有后缀、后缀是否正确,都能精准判断,解决“文件打不开”“类型不明”的痛点。
适用场景:下载未知文件、排查文件异常、批量分类文件、系统运维排查。(几乎所有Linux发行版自带,无需额外安装;若未安装,使用yum安装)
二、基础用法
file的语法结构:file [选项] 文件名/路径
以下3种主要用法:
1. 识别单个文件
file test.txt #输出UTF-8 Unicode textfile 12.sh # Bourne-Again shell script, UTF-8 Unicode text executable
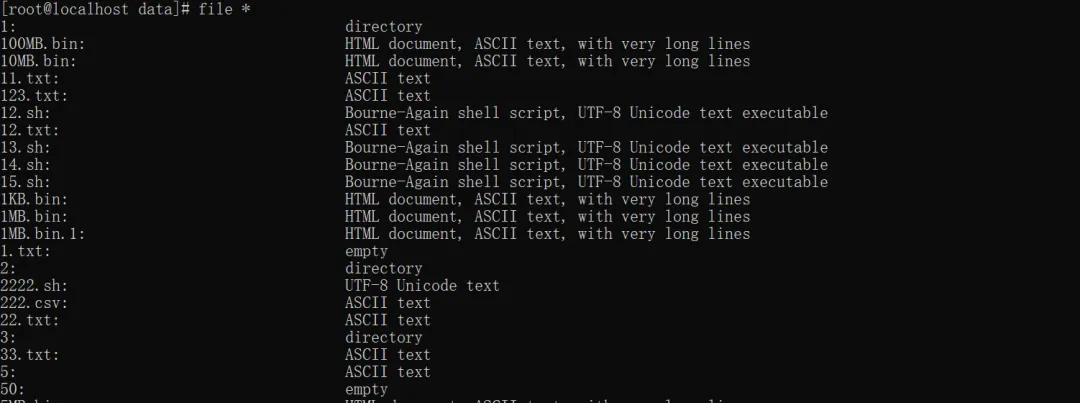
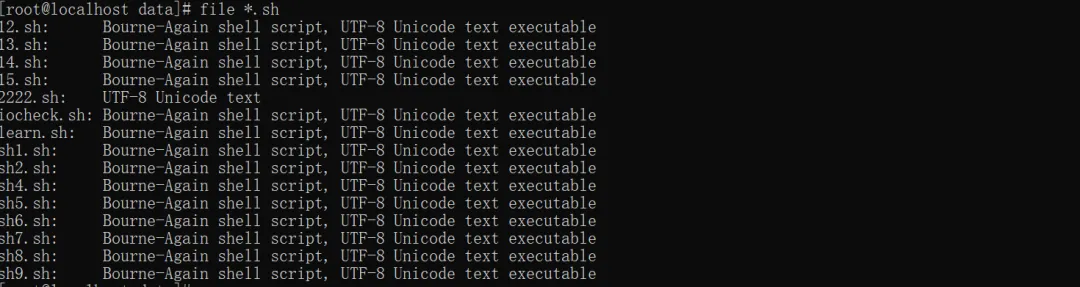
2. 批量识别文件
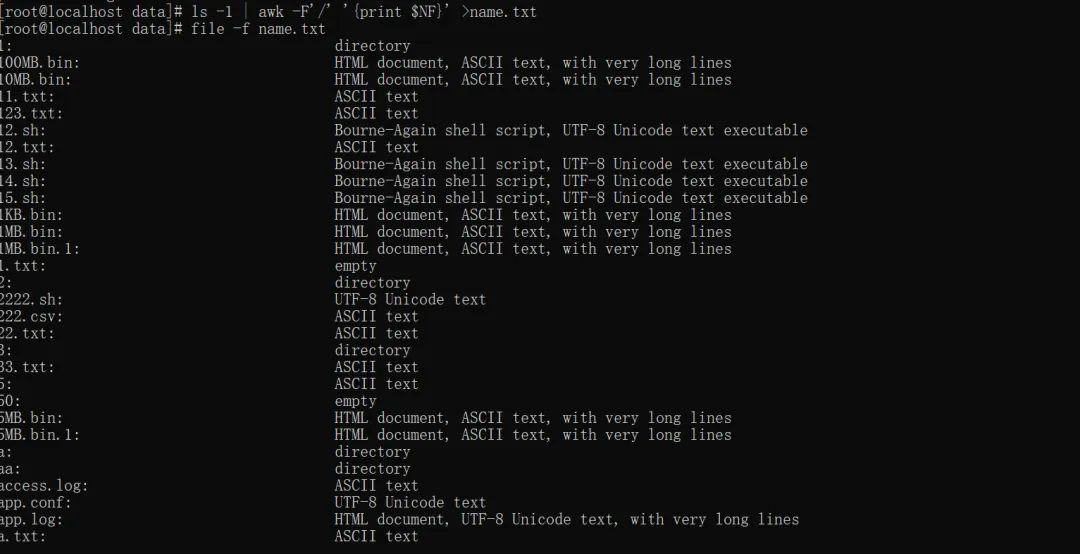
file * #识别当前目录下的所有文件file *.sh #识别当前目录下指定类型的文件file 123 #隐藏图片后缀,可以查看图片的类型 ls -1 | awk -F'/' '{print $NF}' >name.txt #从文件列表批量识别
3. 简洁输出
file -b ceshi.csv #只显示文件类型,不显示文件命名
三、高级技巧
掌握这5个技巧,能够有效提供运维效率
1. 跟随符号链接识别(-L)
file -L python3 #穿透软链接,显示可执行文件类型
2. 查看压缩包内部(-z)
3. 查看MIME类型(--mime-type)
# 输出标准MIME类型,适配开发场景file --mime-type 123.jpg # 输出:123.jpg: image/jpeg
4. 处理特殊文件(-s)
# 识别设备文件、套接字等特殊文件file -s /dev/sda1 # 识别硬盘设备文件类型
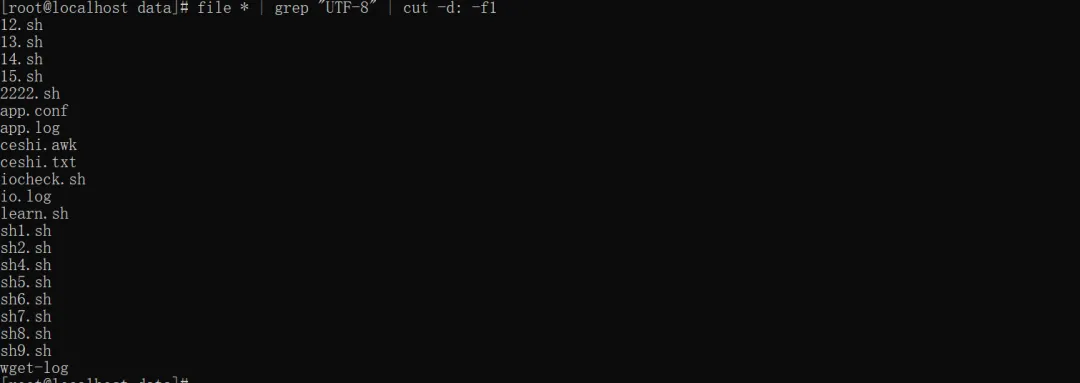
5. 结合其他命令批量操作
# 1.筛选所有UTF-8文本文件file * | grep "UTF-8" | cut -d: -f1# 2.批量给可执行文件加权限file * | grep "executable" | cut -d: -f1 | xargs chmod +x
find . -type f -name "*.log" -exec file {} \;#用于批量识别当前目录下所有log文件的类型
四、避坑指南
权限不足:切换至root用户操作
识别缓慢:大文件用head -c 1000 文件名 | file -,只读取头部
识别异常:用hexdump -C 文件名 | head进一步验证
特殊文件系统(proc/sys):无需纠结类型,重点关注文件用途
五、核心用法速查表
参数 | 作用 | 示例 |
无参数 | 识别文件类型(带文件名) | file test.txt |
-b | 简洁输出,只显类型,不显示文件名 | file -b test.txt |
-L | 跟随软链接识别 | file -L python3 |
-z | 查看压缩包内部 | file -z backup.tar.gz |
--mime-type | 输出MIME类型 | file --mime-type test.jpg |
总结:file命令不用死记复杂参数,掌握“识别单个文件、批量识别、简洁输出”3个基础用法,再结合实战技巧,就能解决80%的文件类型相关问题。
#运维#linux运维#linux实战#file文件格式识别








 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
