第一章:I/O 的本质——一次“语义降维打击”
1.1 从 write() 到 LBA:抽象逐层坍缩
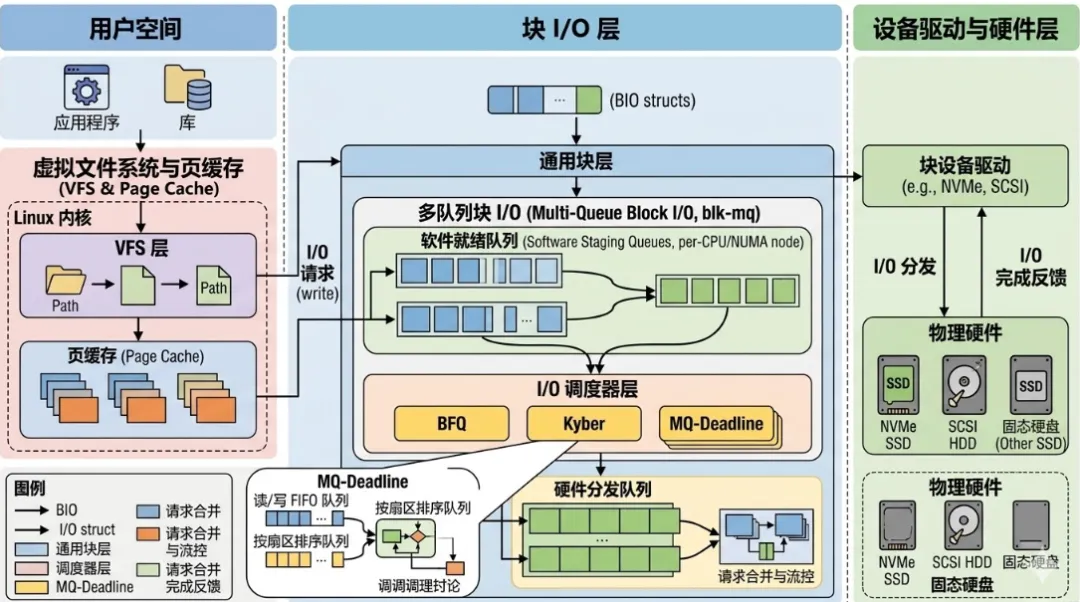
Linux I/O 的核心不是“写数据”,而是一次典型的语义降维过程:用户态 write(fd, buf, len) 表达的是“字节流写入”,但底层设备只接受“块地址 + 长度”的请求。内核的任务就是在多层抽象之间完成映射与优化,其路径严格分层:系统调用负责上下文切换,VFS 负责接口统一,文件系统负责逻辑块到物理块映射,页缓存负责缓冲与合并,块层负责调度与队列化,驱动负责 DMA 与设备交互。这个过程中最关键的设计原则是层间解耦:上层不感知下层实现,从而允许 ext4/xfs、HDD/NVMe 在同一 I/O 框架中共存。
从数据结构角度,这一过程由一条“骨干链路”贯穿:
file → inode → address_space → page/folio → bio → request
这不仅是数据路径,也是控制路径,任何性能问题本质上都可以在这条链路上定位。例如 page cache 命中率低 → 频繁构造 BIO → request 无法合并 → IOPS 飙升,这是一条典型的性能退化路径。
1.2 两条路径决定 80% 性能:Buffered vs Direct
I/O 在文件系统层发生关键分裂:Buffered I/O 与 Direct I/O。Buffered I/O 将写操作转化为 page cache 修改,数据标记为 dirty 后由 writeback 延迟刷盘,本质是“写时缓冲 + 批量提交”,优势在于可以通过页合并与顺序化显著提升吞吐,但 fsync 语义变重;Direct I/O 则绕过 page cache,直接构造 BIO 提交到块层,消除双拷贝并降低延迟,但对齐要求严格且无法利用缓存。
更深一层理解:Buffered I/O 是“内核调度型 I/O”,Direct I/O 是“应用驱动型 I/O”。前者由内核控制节奏,适合通用场景;后者由应用控制,适合数据库与存储引擎。绝大多数“为什么我 I/O 慢”的问题,本质都可以归结为这两条路径选错或使用方式不当。
第二章:系统调用入口——I/O 的调度起点
2.1 write() 调用链与 VFS 分发机制
I/O 从系统调用进入内核,其核心路径为
__x64_sys_write → ksys_write → vfs_write → __vfs_write → file->f_op->write_iter
前半段负责 fd 解析与权限检查,真正的分发发生在 VFS 层。VFS 并不执行 I/O,而是通过 file_operations 中的函数指针实现多态分发,例如 ext4 对应 ext4_file_write_iter,xfs 对应 xfs_file_write_iter。这种设计使得 Linux 可以在不修改上层接口的前提下扩展任意文件系统。
write 并非简单 buffer 写入,而是通过 iov_iter 统一描述数据源,从而支持 writev、splice、sendfile 等复杂 I/O 形态。这种抽象将“数据来源”与“数据处理”解耦,是 Linux I/O 通用化的关键。
2.2 copy_from_user 与零拷贝分界线
用户态数据进入内核必须经过 copy_from_user(),这是安全边界,但也是性能热点。因此 Linux 提供了多种绕过路径:Buffered I/O 中数据只拷贝一次进入 page cache,后续完全在内核流转;Direct I/O 则直接将用户页映射为 BIO;splice/sendfile 则通过页引用实现零拷贝。关键点在于:减少 CPU 参与数据搬运次数,这在高吞吐场景中至关重要。
现代内核通过 folio 优化 page cache 管理,使得大页可以减少页查找与锁开销,从而在高并发 I/O 下获得更好的扩展性。这也是为什么新内核在文件系统性能上持续提升的核心原因之一。
第三章:Page Cache——性能的核心杠杆
3.1 写路径:数据如何“暂存在内存”
Buffered I/O 的核心路径为:generic_perform_write → write_begin → copy → write_end。在这一过程中,内核首先通过 xarray 查找或分配 page,然后将用户数据拷贝进去并标记为 dirty。关键点在于:此时 I/O 尚未发生,所有操作仅限内存。address_space 作为页缓存的管理者,维护着 inode 对应的所有页,其设计使得文件偏移可以高效映射到具体页。
dirty page 的产生标志着数据进入“待持久化队列”,其生命周期为 Clean → Dirty → Writeback → Clean。Linux 通过 dirty_ratio 等参数控制脏页比例,从而避免内存被写缓存占满。
3.2 Writeback:延迟 + 合并 = 吞吐
writeback 子系统负责将 dirty page 刷盘,其核心路径为:
wb_workfn → wb_writeback → writeback_sb_inodes → do_writepages
最终调用文件系统实现(如 ext4_writepages)。其核心思想是:延迟提交 + 批量合并,将大量随机写转化为顺序 I/O,从而显著提升磁盘效率。
fsync 是 writeback 的“强制路径”,它会同步触发数据与元数据落盘,并可能触发日志提交(journal commit),这也是 fsync 延迟高的根本原因。因此,理解 writeback 行为,是优化数据库与日志系统性能的关键。
第四章:Direct I/O——绕过缓存的极致路径
4.1 iomap:现代 Direct I/O 核心框架
Direct I/O 路径为:
ext4_file_write_iter → iomap_dio_rw
其核心在于 iomap 框架。iomap 负责将文件 offset 映射为物理块,并直接构造 BIO。这种设计统一了 ext4/xfs 的实现方式,同时也为 DAX(持久内存直通)提供基础。
本质上,Direct I/O 跳过了 address_space 与 page cache,使 I/O 更“短路径”,但也意味着失去缓存优化能力。
4.2 BIO 构建与性能约束
Direct I/O 通过 bio_add_page 将用户页直接加入 BIO,请求立即进入块层。这要求:
buffer 对齐(通常 4K)
offset 对齐
length 对齐
否则会 fallback 到 Buffered I/O。由于缺乏合并机制,小 I/O 会直接放大为高 IOPS,从而拖垮设备。因此 Direct I/O 的性能高度依赖请求粒度,通常需要配合异步 I/O(如 io_uring)才能发挥优势。
第五章:Block Layer——真正的性能战场
5.1 BIO → Request:进入 blk-mq
所有 I/O 最终进入块层:submit_bio → blk_mq_submit_bio → blk_mq_make_request。在 blk-mq 架构中,BIO 会被映射为 request,并进入 per-CPU software queue,再分发到 hardware queue。这一设计彻底消除了单队列锁竞争,使多核系统可以并行提交 I/O。
5.2 调度与合并:减少 IOPS 的关键
块层通过调度器(mq-deadline、kyber、bfq)对 request 排序与合并,合并策略包括前向与后向合并。目标只有一个:减少 I/O 次数,提高顺序性。对于 NVMe,多队列可以直接映射到硬件 submission queue,实现真正并行;而对于 HDD,调度器则更关注寻道优化。
一句话总结这一层:把“碎 I/O”变成“整 I/O”。
第六章:驱动 + io_uring——新时代 I/O 模型
6.1 驱动执行与完整时序图
当 request 到达驱动后,会调用 queue_rq(如 nvme_queue_rq),驱动构造 DMA 描述符并写入设备队列,随后通过 doorbell 通知设备执行。完成后设备触发中断,内核调用 blk_mq_complete_request → bio_endio 完成闭环。
完整时序图:
User Space │ │ write() ▼syscall ▼VFS ▼Filesystem (ext4/xfs) ├───────────────┐ │ │Buffered I/O Direct I/O │ │Page Cache │ │ │Dirty Page │ │ │Writeback │ └──────┬────────┘ ▼ BIO ▼ blk-mq (queue) ▼ Request ▼ Driver ▼ Device ▼ Interrupt ▼ bio_endio ▼ return
6.2 io_uring:为什么它能“吊打”传统 I/O
传统 I/O 的问题在于:
每次调用都要 syscall
上下文切换成本高
无法高效批量提交
io_uring 通过两个 ring(SQ/CQ)解决这一问题:用户态将请求写入 SQ,内核批量消费并提交,完成后写入 CQ,整个过程可以无 syscall 或少 syscall完成。其优势在于:
本质上,io_uring 不是优化某一层,而是绕过传统调用路径,重构 I/O 提交模型。因此在高并发、小 I/O 场景(如 KV 存储、日志系统)中,性能可以显著优于 write/epoll。
Linux I/O 的本质可以浓缩为三点:
而未来趋势只有一个:
从“系统调用驱动 I/O”走向“共享内存驱动 I/O”(io_uring)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
