Python绘制SHAP+蜂巢图(附数据和代码)
- 2026-07-04 08:15:01

©[悠悠智汇笔记] 版权所有
🙏请尊重劳动成果,守护每一份劳动心血;⚖️未经授权,不得以为任何方式转载、摘编或抄袭。🔄转载合作请后台联系授权,侵权必究。
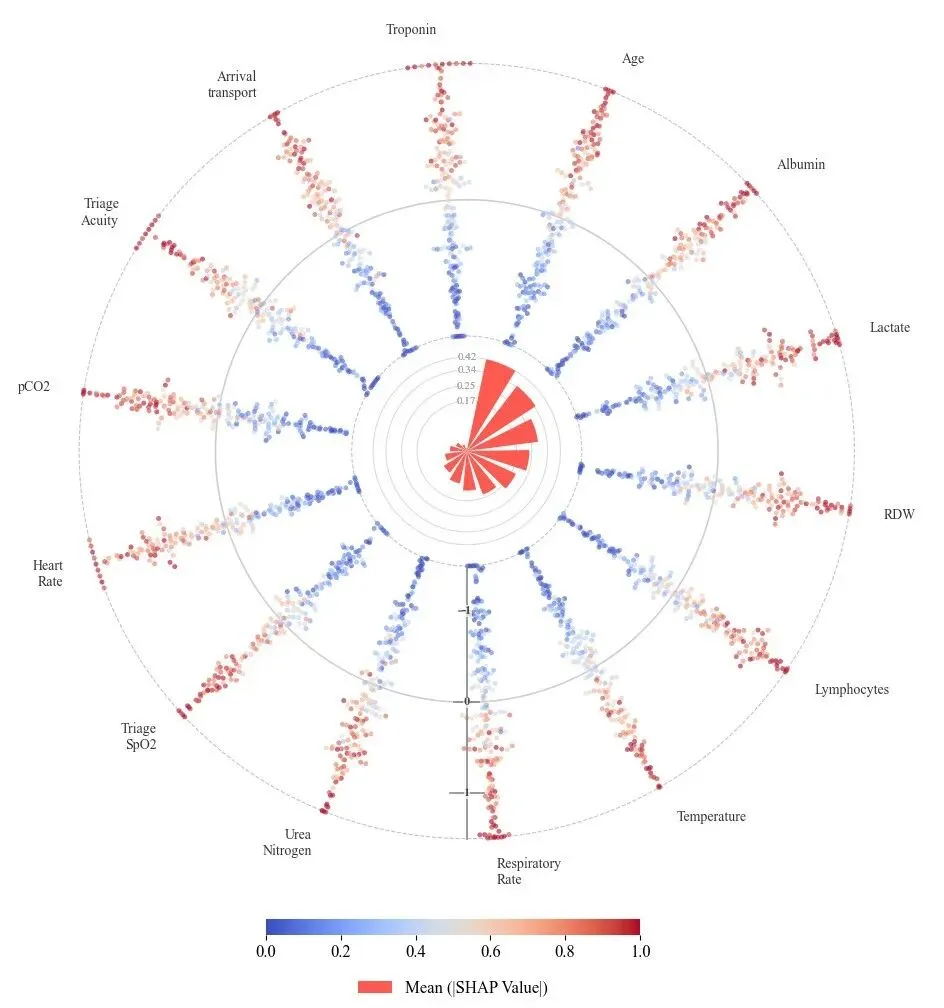
本期分享的图,内圈的红色玫瑰图代表特征对模型的平均贡献度;外圈蜂群散点则展示了特征值(由蓝至红)对预测结果的具体影响(正向或负向)。
外红内蓝正相关:特征值越高,预测值越高(如:年龄越大,患病风险越高)。
外蓝内红负相关:特征值越高,预测值越低(如:锻炼时间越长,患病风险越低)。
红蓝交织非线性/复杂关系:该特征对结果的影响不单调,可能存在复杂的交互效应。
01

数据预处理

这一步是绘图的基础。为了让不同量纲的特征能在同一个颜色条下展示,将特征值缩放到 [0,1] 区间。这里使用了 5% 到 95% 的分位数来排除离群点的干扰。
1 2 3 4 5 6 7 8 9 10 def normalize_feature_values(values): values = np.asarray(values, dtype=float) if len(values) == 0: return values # 使用分位数平滑极端值 vmin, vmax = np.percentile(values, [5, 95]) if vmax <= vmin: vmin, vmax = np.min(values), np.max(values) if vmax <= vmin: return np.zeros_like(values) return np.clip((values - vmin) / (vmax - vmin), 0, 1)
02

蜂群算法

当多个数据点具有相同的 SHAP 值时,它们会重叠。下面函数计算每个点在极坐标角度方向上的“偏移量”,使得点群像蜂群一样向两侧散开,增加可视化密度感。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def exact_beeswarm(values, nbins=45, spread=0.25): # 将数值分配到不同的桶(bins)中 bins = np.linspace(np.min(values), np.max(values), nbins) inds = np.digitize(values, bins) offsets = np.zeros_like(values, dtype=float) for i in range(1, nbins + 1): mask = inds == i count = np.sum(mask) if count > 0: # 计算对称偏移:从中心向两边排布 t = np.arange(count) - (count - 1) / 2.0 width_factor = spread * (1.0 if count > 12 else count / 12.0) offsets[mask] = (t / (count if count > 10 else 10)) * width_factor return offsets
03

非线性高度缩放

这一步是为了让重要性差异更明显。
1 2 3 4 5 6 def scale_rose_heights(values, gamma=0.75): x = np.asarray(values, dtype=float) x_min, x_max = np.min(x), np.max(x) if x_max <= x_min: return np.ones_like(x) * 0.5 # 归一化后进行幂律转换,提升视觉表现力 return np.power((x - x_min) / (x_max - x_min), gamma)
04

极坐标系初始化

这一步建立画布,并将坐标轴转换为极坐标。这一步绘制了代表重要性刻度的灰度圆环,并设置了 12 点钟方向为起始点
1 2 3 4 5 6 7 8 9 10 11 # 在绘图函数内部的关键片段fig = plt.figure(figsize=(11, 11), facecolor="white")ax = fig.add_subplot(111, polar=True)ax.set_theta_zero_location("N") # 顶部对齐ax.set_theta_direction(-1) # 顺时针方向# 绘制辅助背景环ticks = [0.0, 0.17, 0.25, 0.34, 0.42]for t in ticks: r_ring = bar_bottom + scale_rose_heights([t, 0.0, 0.42], gamma=0.7)[0] * bar_max_h ax.plot(np.linspace(0, 2 * np.pi, 200), np.full(200, r_ring), color="#888888", alpha=0.3)
05

玫瑰图与蜂群散点

这一步是绘图的核心步骤。也是最复杂的一步。首先在内圈绘制红色条形图(代表平均绝对 SHAP 值),然后在指定半径区域绘制散点。
1 2 3 4 5 6 7 8 9 10 11 12 # 循环绘制每个特征for i, name in enumerate(sorted_names): # 1. 绘制内圈条形图 (Mean SHAP) ax.bar(angles[i], rose_h[i], width=angle_step * 0.75, bottom=0.45, color="#ff5a52") # 2. 绘制外圈蜂群散点 (Individual SHAP samples) s_vals = np.clip(d["shap"].values, -limit, limit) v_vals = normalize_feature_values(d["feature"].values) r_pos = base_r + (s_vals / limit) * spread_r # 半径代表SHAP正负影响 t_offs = exact_beeswarm(s_vals, spread=angle_step * 0.48) # 角度偏移 ax.scatter(angles[i] + t_offs, r_pos, c=plt.get_cmap("coolwarm")(v_vals), s=13)
06

样式设计

最后一步是处理文本旋转和颜色条。为了防止标签重叠,代码根据标签所在的角度动态调整水平对齐方式(ha),并添加图例。
1 2 3 4 5 6 7 8 9 10 11 12 for i, angle in enumerate(angles): deg = np.rad2deg(angle) % 360 # 根据角度自动决定标签靠左还是靠右,防止文字遮挡图像 ha = "left" if 0 < deg < 180 else "right" if np.isclose(deg, 0, atol=1) or np.isclose(deg, 180, atol=1): ha = "center" ax.text(angle, 5.4, short_feature_name(sorted_names[i]), ha=ha, va="center")# 添加底部的特征值颜色映射条sm = plt.cm.ScalarMappable(cmap="coolwarm", norm=plt.Normalize(vmin=0, vmax=1))cax = fig.add_axes([0.33, 0.15, 0.34, 0.015])fig.colorbar(sm, cax=cax, orientation="horizontal", label="Feature Value")
🌿 今日的分享就到这里啦~如果这些内容有为你带来帮助,欢迎轻点右下角的【👍赞】和【👀在看】,也欢迎分享给更多需要的人,感恩~
THE
END


数据和代码怎么获取?
点击关注后,后台回复关键词:
2026_map_015可直接获取完整的示例数据和代码
如有帮助,您的点赞、评论、转发是我持续创作的动力~


随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 油价暴涨92号迈入9元时代:Python量化实战,能源板块数据获取与技术指标分析
- Linux 环境下让动态的 ttyUSB* 设备使用固定端口
- 手把手玩转Linux初始化系统systemd,包会!
- Linux发行版之母——Debian
- Linux 进程终止指南:理解 kill 与 kill -9 的核心区别与正确用法
- 2.2 Linux启动流程-2
- 在Linux中安装.bundle文件包指南
- 紧急预警!多款AI工具框架引用的Python库LiteLLM被投毒,你的密码、密钥可能已泄露
- Python 算法大全:这个项目把面试要考的算法都写了一遍
- 去年二级Python选择题押的挺准的,今年也是!
