欢迎再次回到机器学习入门工作流 !今天的内容将围绕“数据点绘制”和“函数拟合”两项任务展开,系统阐述包括基本定义、Python内置函数、Python库的概念以及本研究所用库的类型等Python编程基础,并通过导入公开数据集开展统计分析与函数拟合,全程代码可直接运行【建议优选google colab,次之Jupyter notebook或者Pycharm,如果都没有,手头的豆包千问试试吧 】~
】~
本节学习目录
- 数据集处理 (Dataset manipulation)
1.变量
在Python及多数编程语言中,变量被定义为数据值的存储单元,各变量具有唯一标识符。本节我们通过示例演示Python变量的基本用法,以变量a与b为例,我们为其赋予任意数值。(注意!!计算逻辑与数学逻辑存在本质差异:符号 = 并非数学意义上的等号,而是赋值操作符,用于将右侧数值赋予左侧变量)在示例中,我们把数值1赋予变量a(a→1),方便后续引用计算结果。
运算符用于变量与数值之间的运算。示例中,我们定义了变量addition为a与b的和;定义变量exponentiation为二者的幂运算结果,即a^b。
# 定义变量a = 1b = 2# 加减乘除、幂运算addition = a + b # 加法exponentiation = addition ** b # 幂运算 和的b次方
运行结果:
addition → 3exponentiation → 9
比较运算符==用于判定两个数值是否相等,其运行结果为布尔型数据,取值为真(True)或假(False),相关内容将在下一节详细阐述。
2. 数据类型
Python支持多种数据类型,我们这里重点介绍以下五类:
- 布尔值 (bool):只有True/False 两种结果
- 整数 (int):正/负整数,如8、-678
- 浮点数 (float):小数,如3.14159、-6.5
- 字符串 (str):文本,用引号包裹,如"hello"
- 列表 (list):有序集合,如[1,2,3,4]
2.1 查看数据类型
可通过type()函数查看数据类型:
type(3) # inttype(0.5) # float
如前所述,3是整数,0.5是浮点数。
2.2 浮点数精度问题
如前所述,浮点数可以是有限或无限小数形式的有理数或无理数。受限于计算机的存储与运算能力,其内部可保存的小数位数存在上限,因此我们执行的任何数学运算均不可避免地存在一定近似。
需要注意的是,判断计算机是否采用浮点数与近似计算至关重要。以数值0.3为例,Python等编程语言均以二进制分数存储浮点数,而绝大多数十进制小数无法被精确表示,仅能以近似值存储与运算,因而会出现微小误差,这种现象被称为浮点误差。尽管输出[使用print()函数]浮点数时Python会输出其十进制近似值,使误差难以察觉,但在数值运算中该偏差会明显体现。例如输入0.1时,计算机实际采用其二进制近似值参与计算,而非精确的1/10,因此0.1+0.1+0.1的结果并不严格等于0.3。这类情况在计算中必须予以考虑,此类误差曾导致1996年阿丽亚娜5号重型运载火箭自毁事故。
0.1 + 0.1 + 0.1 == 0.3 # 结果:False
2.3 字符串与列表
print()函数用于在终端输出各类对象,涵盖字符串、数值及多种数据类型变量。代码单元可通过Ctrl+Enter执行,Shift+Enter执行后跳转至下一单元。文本内容,即字符串,需使用单引号(‘’)或双引号(“”)包裹。# 定义字符串'this is a string'# 运行结果→ 'this is a string'
字符串可包含数字,但不遵循数学运算规则,字符串间加法实则拼接操作,比如我们将字符串‘12’、‘34’和‘A’相加,得到的结果如下:'12' + '34' + 'A' # 结果→ '1234A'
列表也是一种重要的数据结构,它能够在单一变量中存储多个元素。列表中元素具备有序性,且创建后支持修改操作。每个元素均分配唯一索引,其中首个元素索引为[0],第二个元素索引为[1],其余元素索引依次递增。如我们在列表["element1",2,3.14]中选取索引为[1]的元素,即列表中的第二个元素。
my_list = ["element1", 2, 3.14]my_list[1] # 取第2个元素 → 2
3. 函数
函数就是可重复使用的一段代码块,仅在调用时执行。Python内置很多现成函数,如print()、sum()、pow() 等,也可自定义函数。
3.1 常用内置函数
print("Hello World!") # 打印输出 → Hello World!sum([1,2]) # 求和 → 3pow(3,2) # 幂运算 → 9
3.2 自定义函数
除系统内置函数外,用户也可以通过def自定义函数,并依托代码缩进区分独立的函数代码块。为了更好地阐释函数的运行机制,需要明确区分参数与参数值:
- 参数:函数声明时定义的变量,位于括号内;
- 参数值:函数调用时传入的实际数值。
而return的作用是指定函数的返回结果。如下面的第一个例子中,arg1和arg2称为参数,传入的实际数值4和2称作参数值。而变量result的作用域限定于function_add函数内部,此类变量定义为局部变量。在自定义函数的实际书写过程中,要注意相应的缩进和对齐格式。
# 定义加法函数, def function_add(arg1, arg2): result = arg1 + arg2 return resultfunction_add(4, 2) # 调用 → 6
# 同时返回加、乘两个结果def function_addmult(arg1, arg2): result1 = arg1 + arg2 result2 = arg1 * arg2 return result1, result2function_addmult(4,2) # → (6, 8)
4. 库
在开展数据处理工作前,需要先导入模块(modules),即由第三方开发的功能程序集,这些模块化的程序集称之为“库”。本节将导入两款常用的数据管理库:
- Pandas:提供表格生成函数,支持执行多样化数据处理操作;
- Seaborn:支持调用各类常规统计函数,并可通过简洁语法实现大规模数据的图形化可视化,不过 Seaborn库的使用,还需同步导入Matplotlib图形库。
Pandas与Seaborn均以数据框(DataFrame)结构处理数据,即带行、列标签的二维表格形式。库模块的导入可通过import命令执行,as命令用于为导入的模块指定自定义缩写名称。import pandas as pdimport seaborn as sns
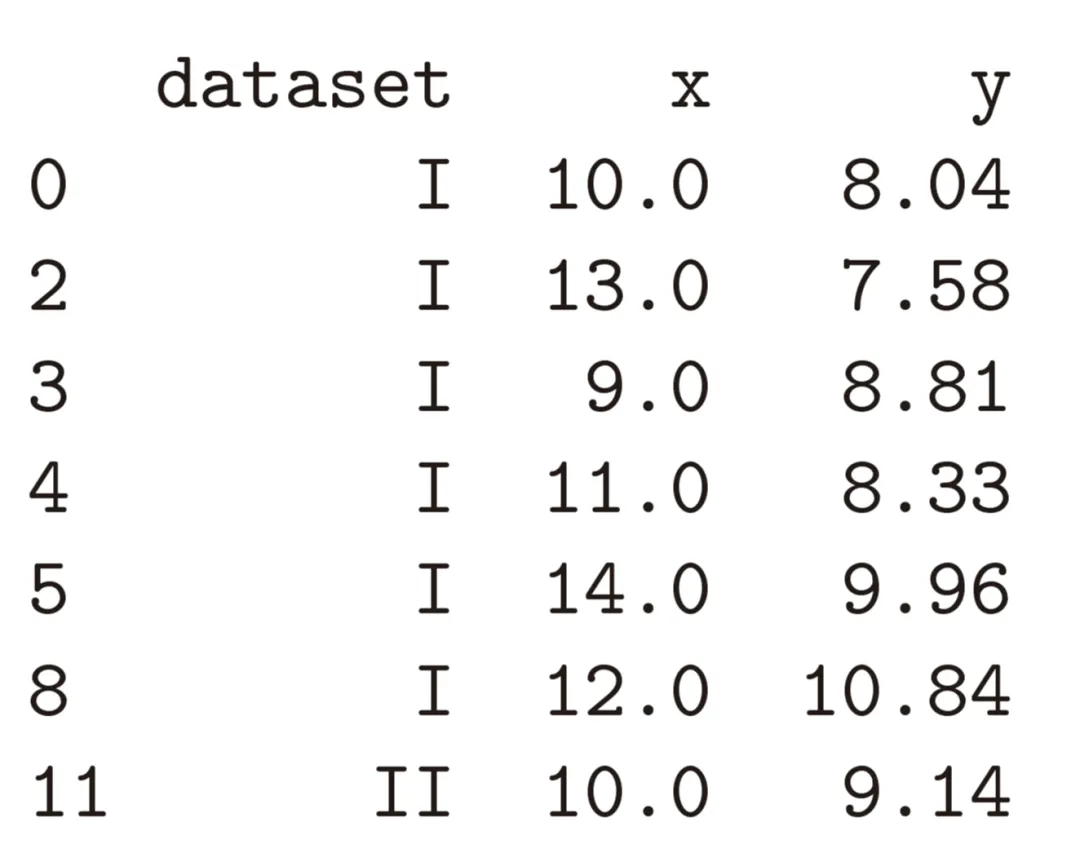
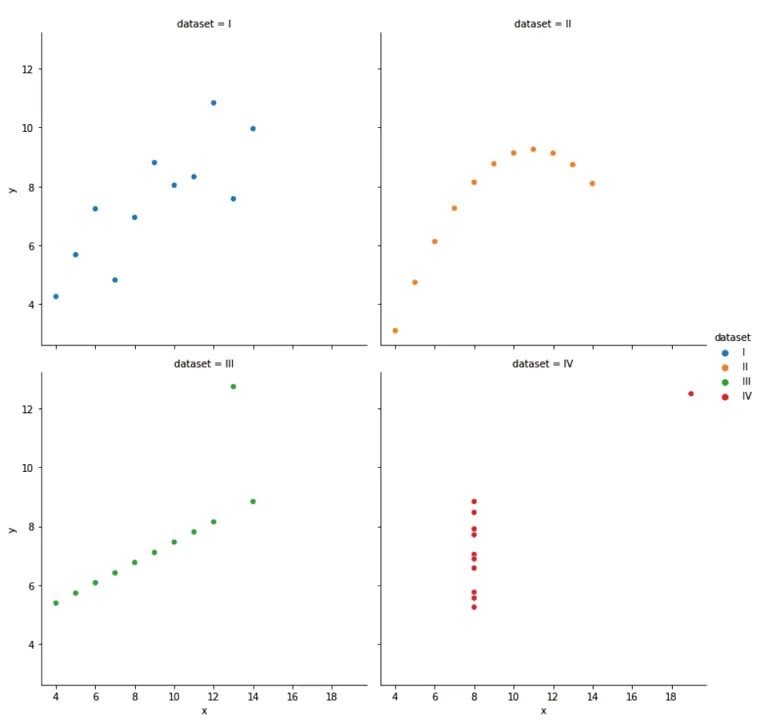
在线笔记本环境相关模块已在远程服务器完成预装(也可在自己的Python环境下自己安装,命令:!pip installSeaborn),在导入Seaborn模块时,Matplotlib库会被自动加载。本研究使用Seaborn内置经典数据集安斯库姆四重奏(Anscombe Quartet),该数据集在统计学中具有重要意义。安斯库姆四重奏(Anscombe's quartet)是统计学家弗朗西斯・安斯库姆提出的一组由四个数据集构成的经典数据集,用来说明统计分析中数据可视化的重要性。这四个数据集都包含11个数据点,每个数据点都由两个变量组成,分别为X和Y。它们的统计学特征,如平均数、方差、相关系数等,高度一致。但当将这四个数据集可视化后,却发现它们的分布情况大不相同。Anscombe Quartet数据集在Seaborn数据库中可直接调用加载。df = sns.load_dataset('anscombe')
数据集加载完成后,为查看所处理的数据内容,可将数据以表格(即数据框)形式输出。通过该方式可以看到,数据集中dataset列将数据划分为Ⅰ、Ⅱ、Ⅲ、Ⅳ四组,各组分布特征存在差异,可分别开展统计分析。如上表,该数据表共包含4列。第一列为索引(index),仅用于对数据点进行编号;其余各列为当前数据集所对应的特征字段。在编程中,任何数值、函数或数据框均可统称为对象(object),且每个对象均隶属于特定的类(class)。数据框本身即为一种类,原因在于所有数据框均支持相同类型的操作行为。简言之,对Python对象使用type()函数,其本质是获取该对象所属的类信息。
type(df) # 输出结果 → pandas.core.frame.DataFrame
数据框(df)常用操作如下:
- 数值排序:
df.sort_values (by='列名', ascending=True/False) - 单列提取:
df['列名'],返回序列(Series) - 布尔筛选:
df[df['列名']>条件],df[df['列名']==条件]
Pandas中的一些内置函数可以帮助我们查看数据框的某些特征,例如columns函数可以输出数据表中所有现有列的列名,我们也可以使用T函数转置表格的行和列。df.columns # 查看列名 → Index(['dataset', 'x', 'y'])df.T # 行列转置
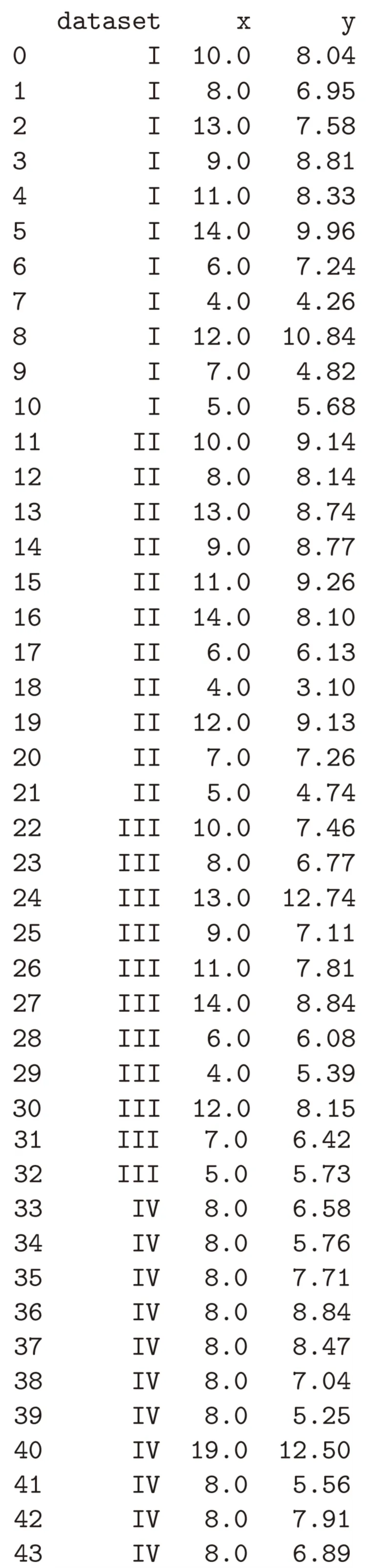
如若需要按照指定条件对表格中的数值进行排序,则可使用sort_values()函数。这里需要注意的是,我们必须指定对哪一列中的数据进行排序,并通过ascending(升序)或descending(降序)等参数设置数据的排序方式。与其他函数一样,该函数也可根据需求自定义其他参数。例如,ascending参数的默认值为True(升序);如有需要,可将其修改为False(降序)。下面的例子中,我们将对x列的数据执行升序排序:
# 按x列升序排序df.sort_values(by='x', ascending=True)
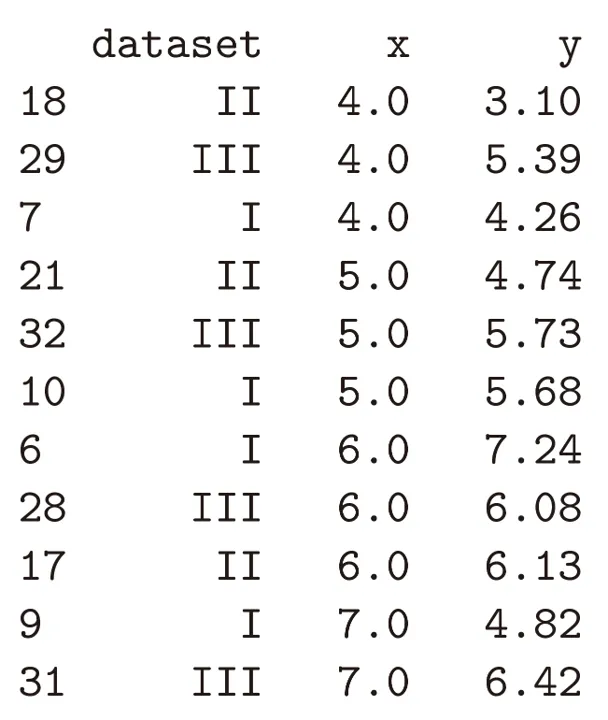
借助Pandas模块,我们还可以按照指定条件对数据集中的数据进行筛选操作,如下面的例子:我们可以选取单独一列,并生成仅包含索引与所选列的数据表。这类数据表被称为序列(Series)。我们还可以结合上述两种操作,通过loc方法同时选取一定范围的行与指定的列。我们还可以对列中的数值使用比较运算符或布尔运算符。例如,以下代码创建了一个序列(Series),用于显示x列中哪些行的数值大于8。这种操作也被称为布尔掩码(boolean mask)。那么,按照这样操作所创建的序列可作为原始数据集的筛选器使用。df['x'] > 8 #Boolean mask
以上述数据集为原始数据集,再做一次筛选,则能生成一个新的数据框,其中仅保留原始数据框中x列数值大于8的行。为了更加便捷,我们通常也会根据数据类型对数据进行筛选。比如在当前数据集中,不同数据已预先通过一列标记为I、II、III、IV四种类型。Pandas支持将条件表达式作为索引来完成数据筛选。在下面的案例中,筛选条件为:dataset列的取值等于I、II、III或IV。(注意,这里的条件表达式本质上相当于先做了一次布尔筛选)# 按dataset分组筛选df_I = df[df['dataset']=='I']df_II = df[df['dataset']=='II']df_III = df[df['dataset']=='III']df_IV = df[df['dataset']=='IV']
我们再来定义一个能够并排显示多个表格的函数。为实现这一功能,我们首先需要从IPython.display中导入display_html。在函数内部,我们先定义一个新变量html_str并将其初始化为空字符串;再将数据框(df)调整为HTML表格格式,把生成的表格内容赋值给html_str;最后通过样式参数table style="display:inline"实现多表格并排展示。from IPython.display import display_htmldef display_side_by_side(*args): html_str = '' for df in args: html_str += df.to_html() display_html(html_str.replace('table','table style="display:inline"'), raw=True)# 调用display_side_by_side(df_I, df_II, df_III, df_IV)
注意:这段代码中的+=运算符,表示将另一个数值与变量当前值相加,并将计算后的新值赋给该变量。6. 数据可视化
数据可视化是机器学习的核心环节,Seaborn支持散点图、折线图、直方图等多种可视化形式。本节将介绍如何基于当前数据集绘制几种基础图表。绘制这些图表时,我们可以直接使用模块内置的函数,与前面的操作方式一致。
6.1 散点图
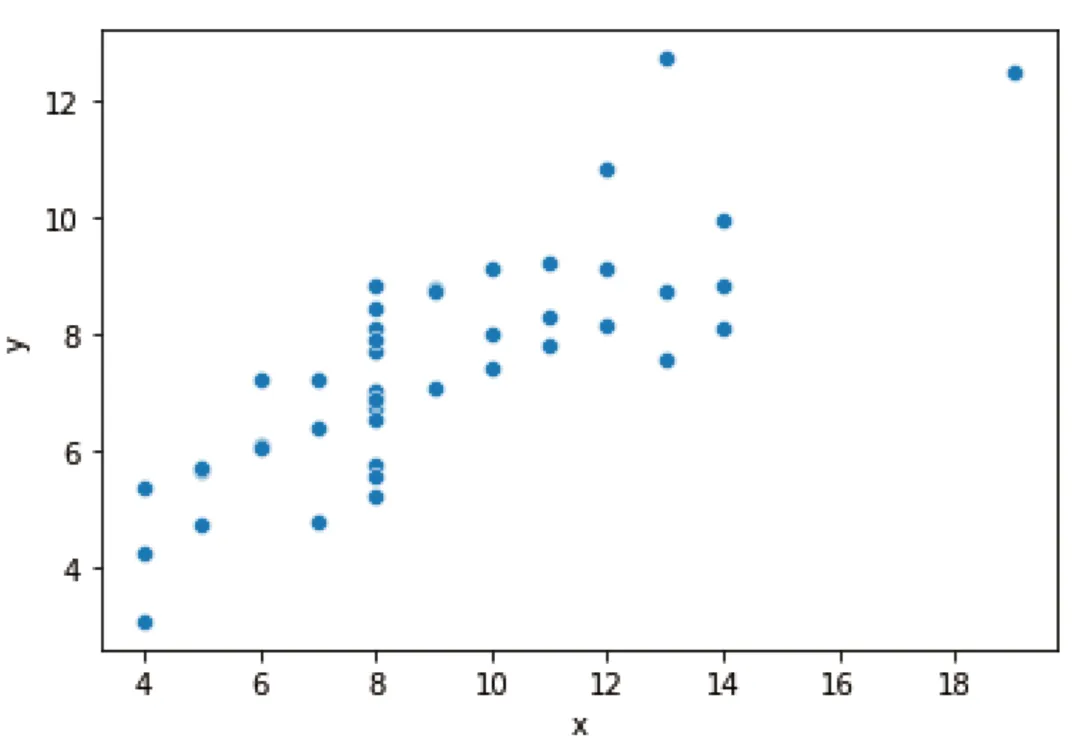
如在散点图绘制中,scatterplot函数会创建一个默认尺寸的图形,并接收需要绘制的参数。如下代码展示了如何绘制数据框中x列与y列的数值。
# 基础散点图sns.scatterplot(x="x", y="y", data=df)# 按分组上色、改形状、改大小sns.scatterplot(x="x", y="y", hue="dataset", style="dataset", size="dataset", data=df)
我们还可以对图表的颜色、尺寸、坐标轴标签及图表标题等多种属性进行调整。例如,Seaborn库中自带的参数hue,可对变量进行分组,并以不同颜色显示数据点。更多操作细节,可查阅Seaborn官方文档。plot=sns.scatterplot(x="x", y="y", data=df[df['dataset']=='I'])
我们也可将图表保存为一个变量。通过这种方式,后续能够继续修改它的部分属性,例如坐标轴的取值范围等,示例如下:plot=sns.scatterplot(x="x", y="y", data=df[df['dataset']=='I'])plot.set(xlim=(0, 20), xlabel='common xlabel', ylim=(0, 20), ylabel='common␣↪ylabel', title='some title')
我们还可以创建包含多个子图的图表。在绘制多子图图表时,需要通过设置参数col对变量进行分组,并为每个分组单独生成子图。同时借助参数col_wrap,设置图表中子图的展示行数。在下面的例子中,我们使用relplot而非scatterplot,因为只有relplot支持参数col。
sns.relplot(x="x", y="y", col="dataset", col_wrap=2, hue="dataset", data=df)
7. 线性回归
数据分析中的一个常规步骤是执行线性回归。我们将使用Seaborn自带的工具来完成这一操作。
7.1 线性拟合
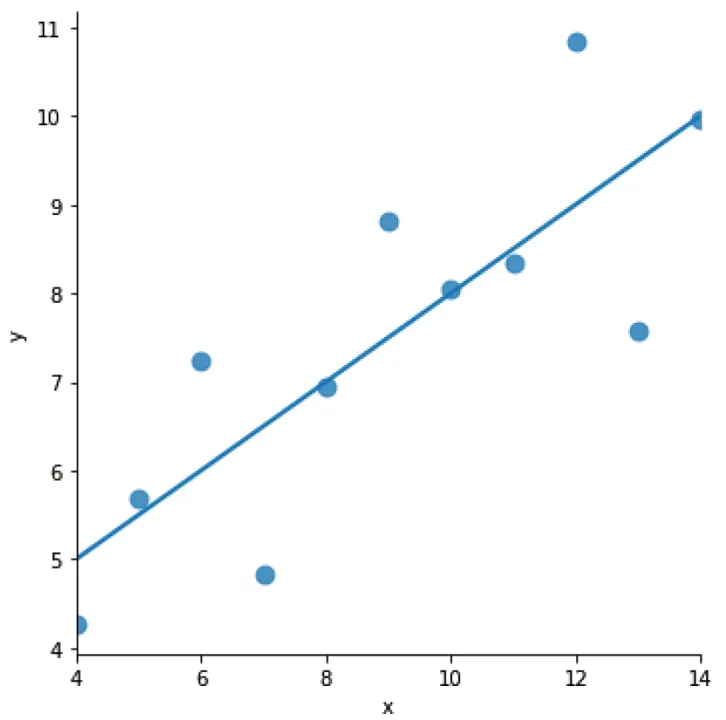
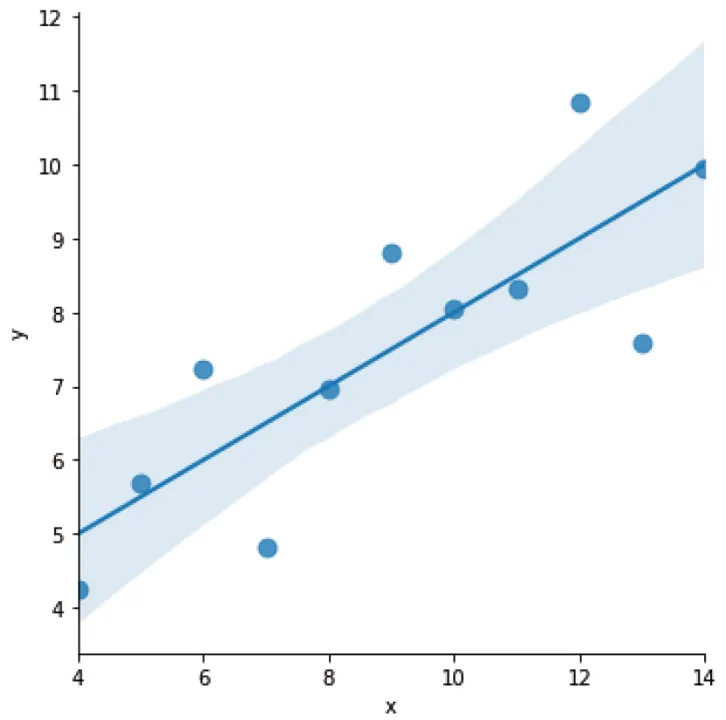
首先以区域 I 的数据为例,lmplot命令可实现回归分析;若未指定回归类型,默认输出线性回归结果。其中,参数scatter_kws用于设置图表中点的大小;参数ci=None用于关闭置信区间显示(Seaborn默认会展示置信区间双曲线)。我们将展示两种情况:包含置信区间与不包含置信区间的效果。
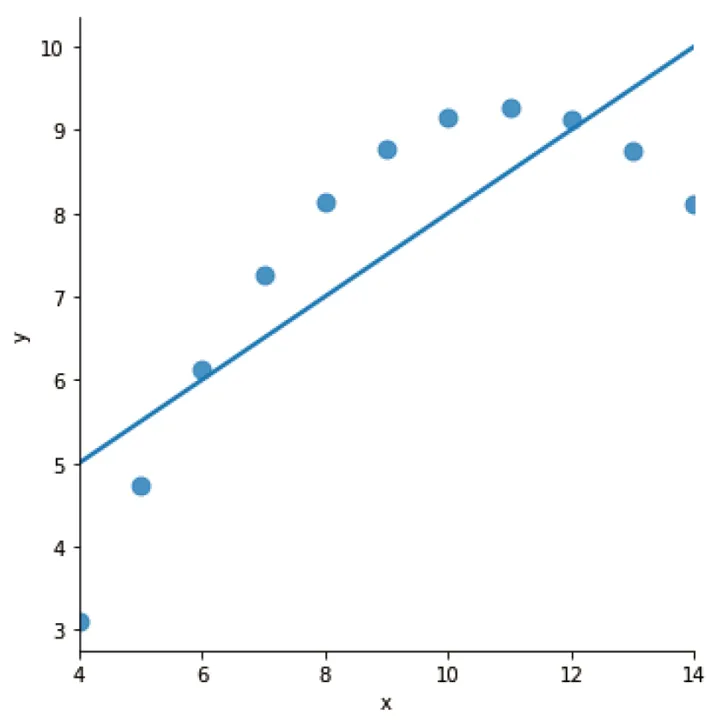
# 数据集I做线性回归sns.lmplot(x="x", y="y", data=df[df['dataset']=='I'], ci=None, scatter_kws={"s":80})
sns.lmplot(x="x", y="y", data=df[df['dataset']=='I'], scatter_kws={"s": 80})
7.2 多项式拟合(抛物线)
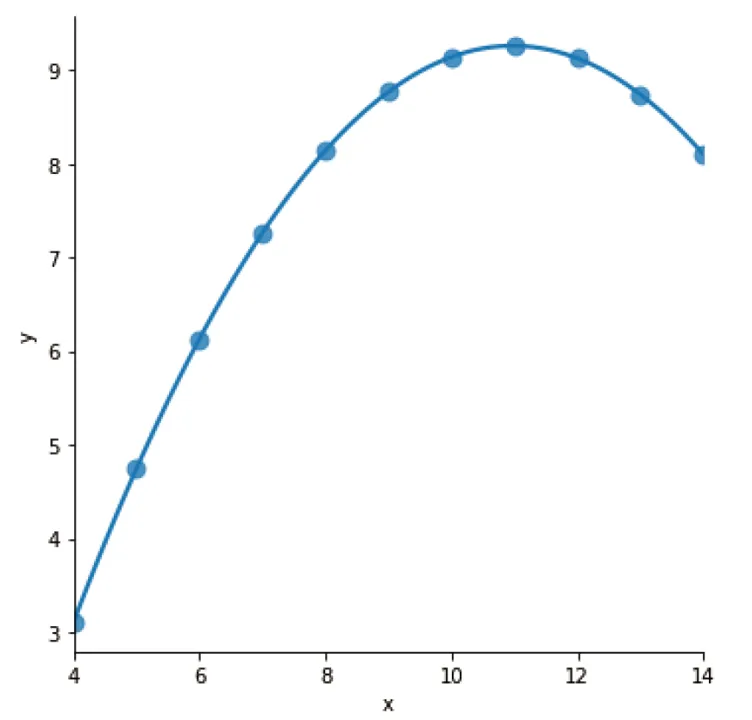
接着,我们对区域 II 的数据执行同样的操作:
sns.lmplot(x="x", y="y", data=df[df['dataset']=='II'], order=2, ci=None, scatter_kws={"s":80})
结果发现区域 II 的数据并不适合线性,反而更接近抛物线,因而改用二次多项式拟合,通过设置参数order即可实现。
c=sns.lmplot(x="x", y="y", data=df[df['dataset']=='II'], order=2, ci=None, ␣↪scatter_kws={"s": 80});
7.3 残差
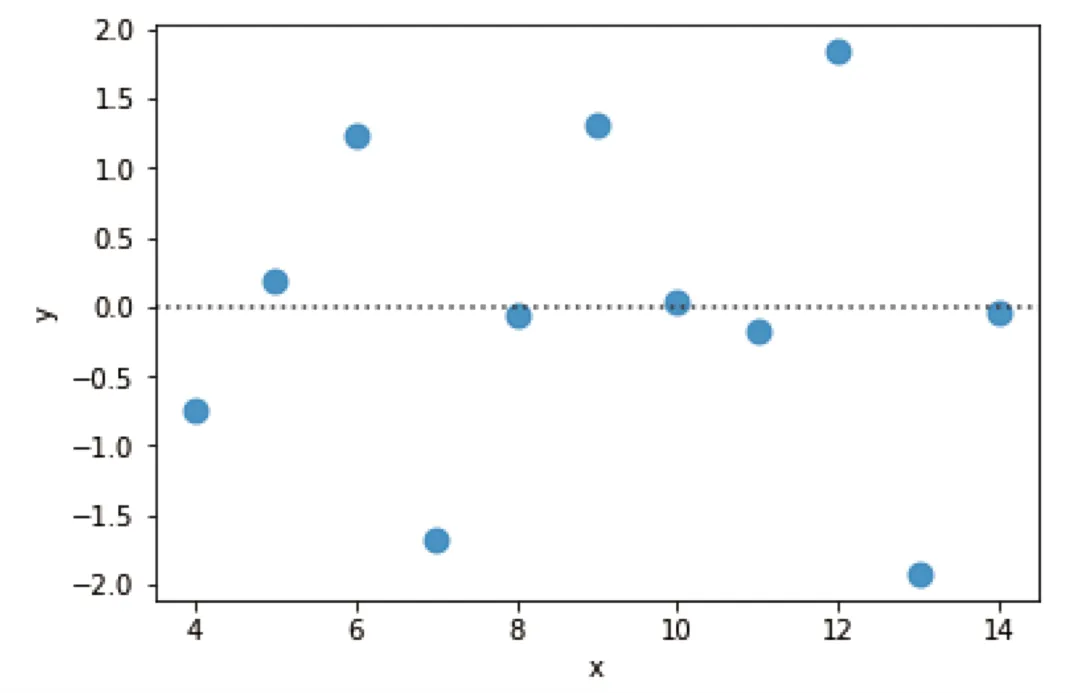
- 执行residplot命令,可以绘制残差图,通过绘制残差图可以判断我们是否选对了回归模型。例如,若线性模型适用于当前数据(区域 I 数据),残差图中的点应当随机分布在横轴周围。
# 残差图sns.residplot(x="x", y="y", data=df[df['dataset']=='I'], scatter_kws={"s":80})
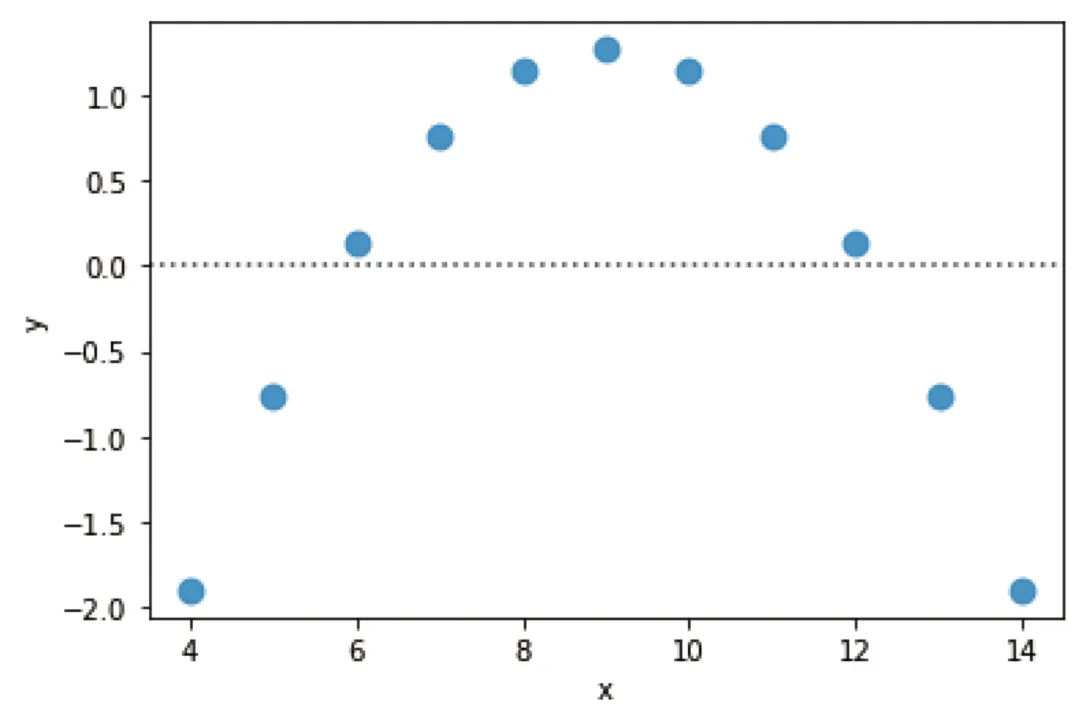
而当我们对区域 II 数据进行同样的操作,结果观察到残差图中的数据点呈现出明显的抛物线趋势。这表明线性回归并不适用于该组数据。sns.residplot(x="x", y="y", data=df[df['dataset']=='II'], scatter_kws={"s": 80})
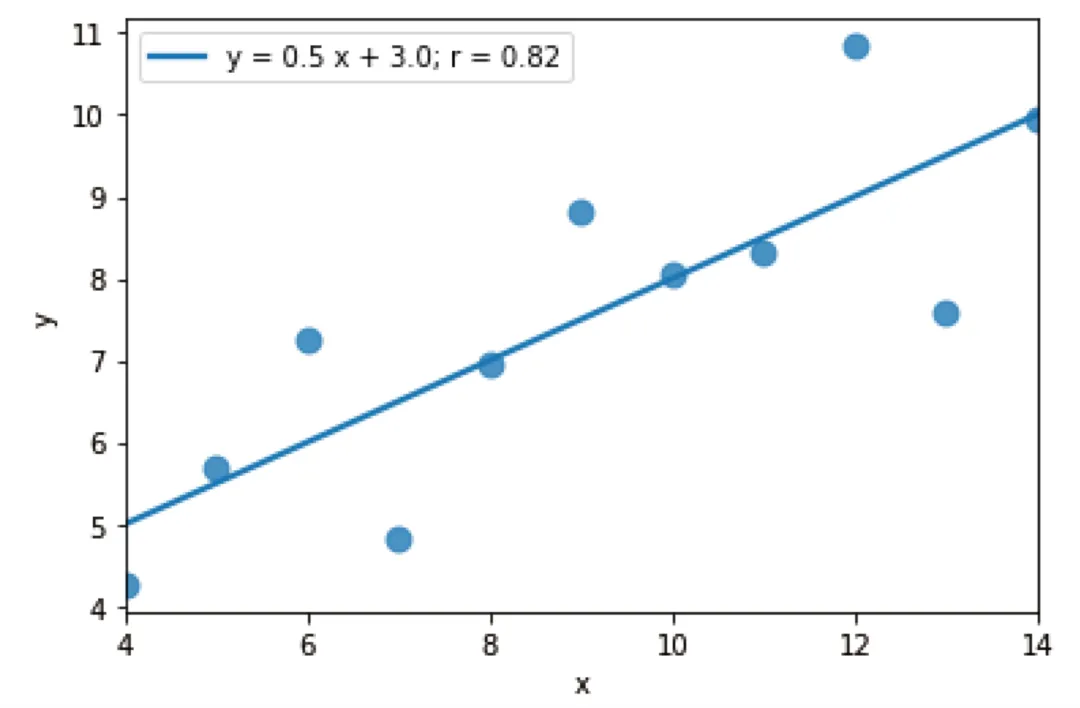
如上所见,区域 I 的数据确实符合线性趋势。若我们想要获取这条趋势线的方程,则可以使用Scipy库来精确算出斜率、截距、R² 等指标::只需再次对区域 I 的数据绘制线性回归图,并添加plot.legend()函数即可。若我们不为该函数设定任何参数,图例的内容将自动生成。from scipy import stats# 线性回归计算slope, intercept, r_value, p_value, std_err = stats.linregress(df[df['dataset']=='I'].x, df[df['dataset']=='I'].y)# 输出结果print(f"斜率: {slope:.1f}")print(f"截距: {intercept:.1f}")print(f"R²: {r_value**2:.2f}")
斜率: 0.5截距: 3.0R²: 0.82p值: 0.002170标准误: 0.117906
小结
学完这篇Python入门,你应该已经掌握了:
这套流程是化学领域机器学习最最基础的workflow,后续我们将继续用它处理一些真实的化学数据!


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
