Python绘制高颜值豆荚图
- 2026-07-04 13:58:02
Python绘制高颜值豆荚图

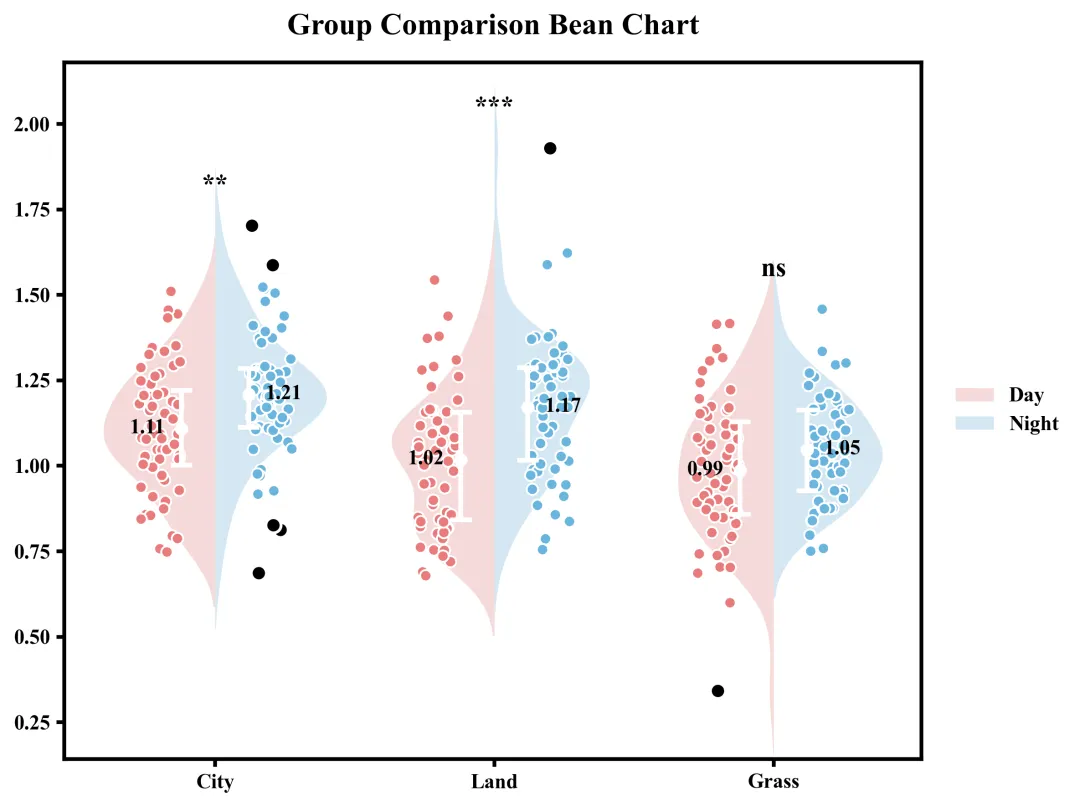
这张豆荚图直观地展示了三个组别在两种条件下的数据分布与统计对比结果。整体来看,所有组别在Night条件下的均值均高于Day条件,其中City的均值由1.11升至1.21,Land由1.02升至1.17,Grass由0.99升至1.05;图中的背景小提琴图和散点描绘了数据的具体分布形态,内部的白色线段和圆点标示了四分位距和均值,而黑色的散点则标识出了各组存在的离群点/异常值。根据图表顶部的显著性检验标注可知,City和Land的左右两种条件之间存在显著差异,而Grass的左右条件之间差异则不具备统计学意义。 
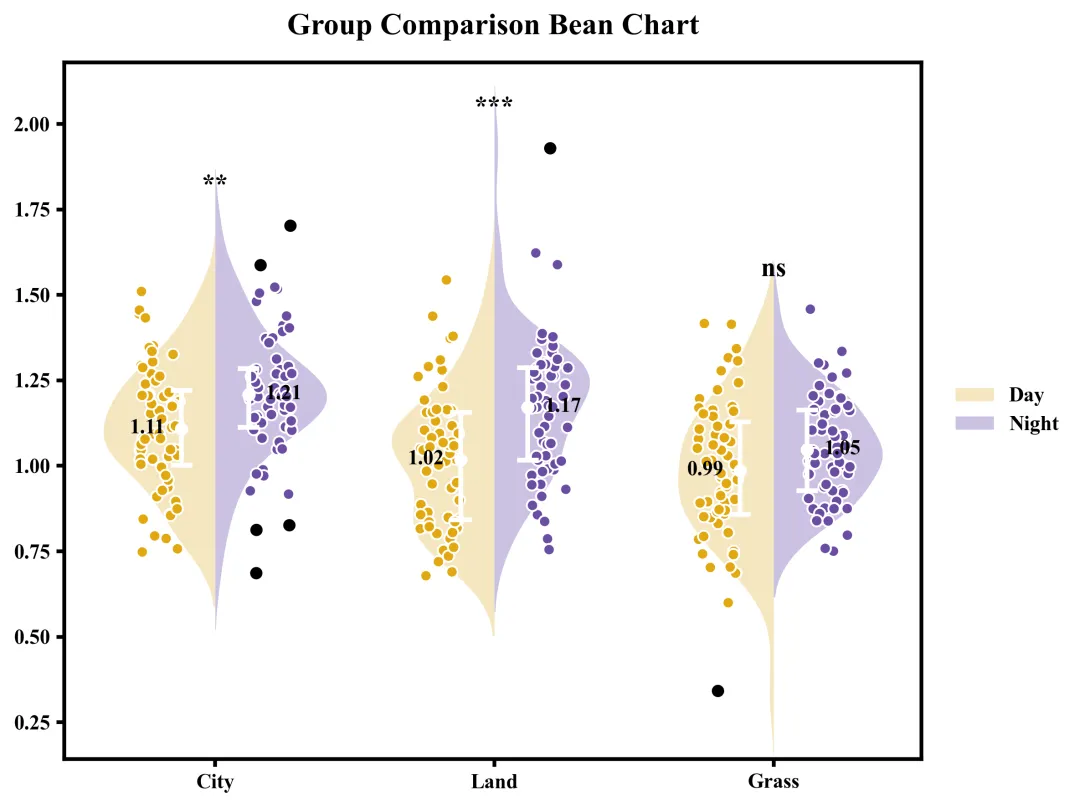
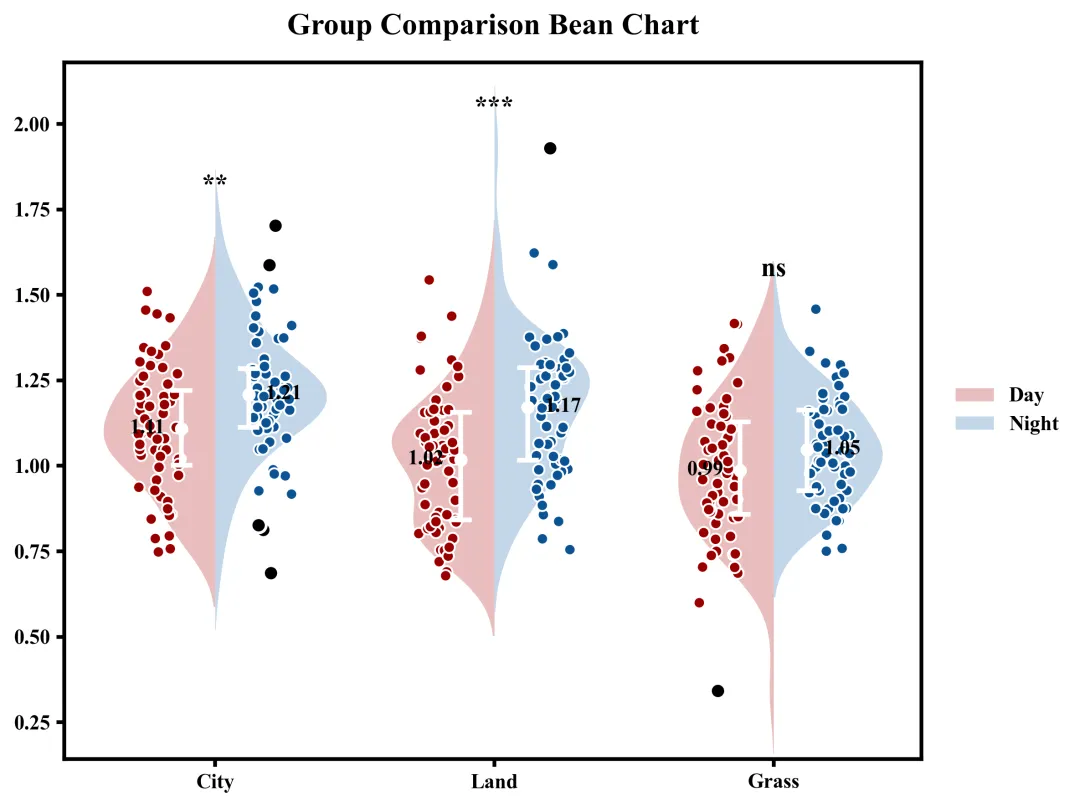
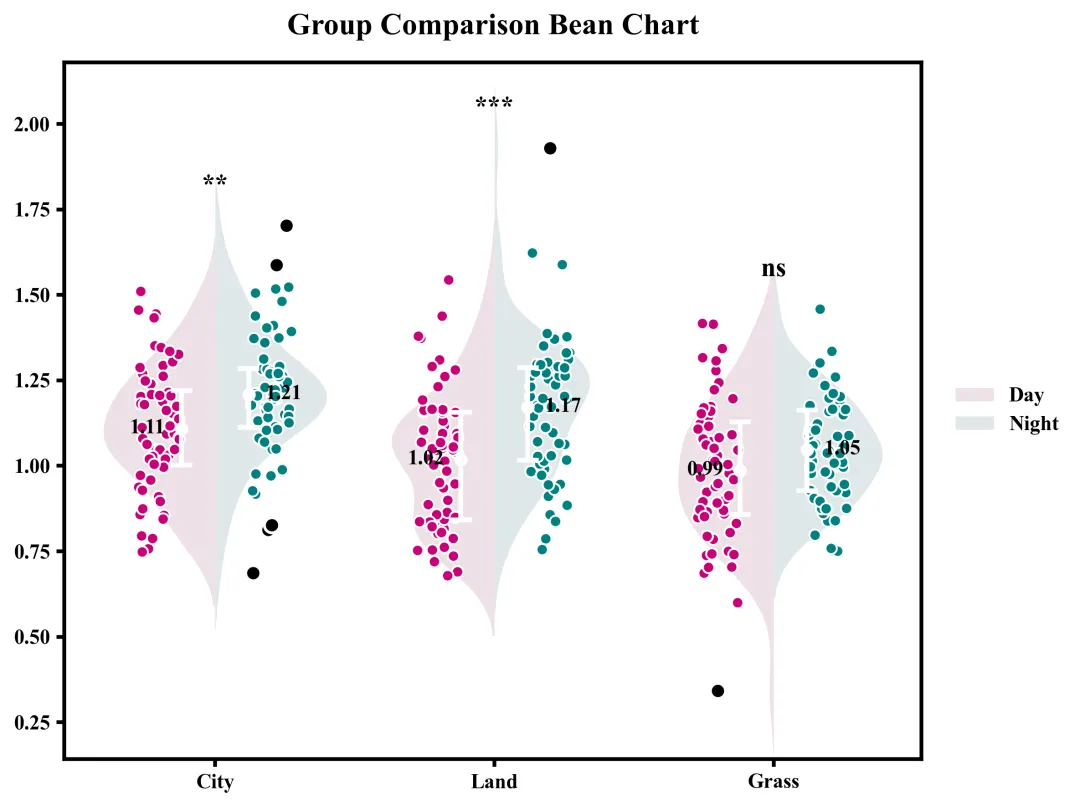
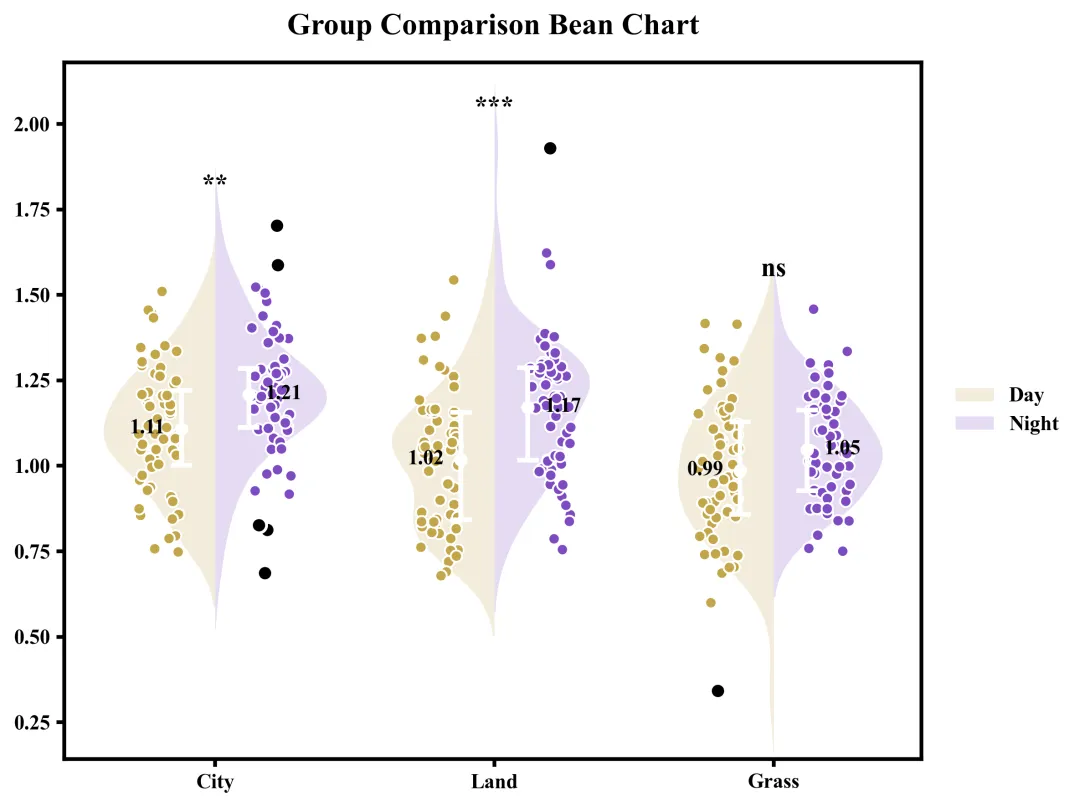
多种配色 



库的导入以及字体设置 

颜色库的设置以及配色方案的选择 

绘图函数:创建画布与绘制基础小提琴图 

绘图函数:散点图部分 

绘图函数:绘制统计线和标注 

绘图函数:执行 T 检验与显著性标注 

绘图函数:图框、标题、刻度设置,图例添加,绘图结果保存 

执行部分,负责数据的读取、预处理及绘图 



期刊图片复现|Python绘制二维偏依赖PDP图 期刊复现|python绘制基于SHAP分析和GAM模型拟合的单特征依赖图 期刊图片复现|python绘制带有渐变颜色shap特征重要性组合图(条形图+蜂巢图) 期刊复现|用Python绘制SHAP特征重要性总览图、依赖图、双特征交互效应SHAP图,解锁XGBoost模型的终极奥秘 期刊图片复现|Python绘制shap重要性蜂巢图+单特征依赖图+交互效应强度气泡图+交互效应依赖图(回归+二分类+分类) 

公众号中的所有所有的免费代码都已经下架了,都并入到付费部分里了,付费合集代码和数据的购买通道已经开通,全部合集100元,后续将会持续更新,决定购买请后台私信我,注意只会分享练习数据和代码文件,不会提供答疑服务,代码文件中已经包含了每行代码的完整注释,购买前请确保真的需要!!!
代码绘制成果展示
代码解释
第一部分
# =========================================================================================# ====================================== 1. 环境设置 =======================================# =========================================================================================import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns
第二部分
# =========================================================================================# ======================================2.颜色库=======================================# =========================================================================================COLOR_SCHEMES = {1: {"violin": {"Day": "#F9C4C4", "Night": "#BCE0F4"}, "scatter": {"Day": "#E87C7C", "Night": "#6AB5DE"}},}scheme_id = 25 #使用的配色方案theme = COLOR_SCHEMES.get(scheme_id, COLOR_SCHEMES[1]) # 获取配色方案palette_violin = theme["violin"] #小提琴图颜色palette_scatter = theme["scatter"] #散点图颜色
第三部分
# =========================================================================================# ======================================4.绘图函数=======================================# =========================================================================================def plot_bean_chart():# 创建画布fig, ax = plt.subplots(figsize=(8, 6), dpi=150)#绘制小提琴图sns.violinplot(data=df, #数据x="Group", #x轴y="Value", #y轴linewidth=0, #边框宽度alpha=0.7, #透明度ax=ax #坐标轴)
第四部分
#绘制散点图sns.stripplot(data=df[~df['Is_Outlier']], #正常值数据x="Group", #x轴alpha=1, #明度size=6, #大小jitter=0.15, #水平方向的随机抖动zorder=1, #层linewidth=1 #轮廓线宽)
第五部分
# 遍历每个唯一的分组for i, groupinenumerate(df['Group'].unique()):#获取当前分组下Left条件的所有统计量left_stats = stats_df[(stats_df['Group'] == group) & (stats_df['Condition'] == 'Day')].iloc[0]#均值、Q1、Q3mean_l, q1_l, q3_l = left_stats['mean'], left_stats['q1'], left_stats['q3']#获取当前分组下Right条件的所有统计量right_stats = stats_df[(stats_df['Group'] == group) & (stats_df['Condition'] == 'Night')].iloc[0]#绘制代表左侧均值的数据点ax.plot(x_left, #xmean_l, #ymarker='o', #形状color='white', #颜色markersize=6, #大小zorder=4) #层#左侧均值文本标注ax.text(x_left - 0.06, #xmean_l, #yf'{mean_l:.2f}', #文本ha='right', #水平va='center', #垂直fontsize=11, # 大小fontweight='bold', #加粗color='black', #颜色zorder=5) #层
第六部分
left_data = df[(df['Group'] == group) & (df['Condition'] == 'Day')]['Value'] #获取当前组别条件的所有具体数值数据right_data = df[(df['Group'] == group) & (df['Condition'] == 'Night')]['Value'] # 取当前组别条件的所有具体数值数据#绘制显著性标记ax.text(i, #xy_pos, #ysig_label, #文本ha='center', #水平va='bottom', #垂直fontsize=14, #大小fontweight='bold', #加粗color='black') #颜色
第七部分
#标题ax.set_title("Group Comparison Bean Chart", #文本fontsize=16, #大小fontweight='bold', #加粗pad=15) #间距#获取图例中所有的文本对象进行属性修改plt.setp(legend.get_texts(),fontweight='bold',fontsize=11)y_global_min = df['Value'].min() #全局最小值y_global_max = df['Value'].max() #全局最大值ax.set_ylim(y_global_min - 0.2, y_global_max + 0.25) #Y轴范围ax.set_ylabel('') #去掉y轴标题ax.set_xlabel('') #去掉x轴标题#设置边框线for spine in ax.spines.values():spine.set_linewidth(2.0) #粗细spine.set_color('black') #颜色#配置刻度线属性ax.tick_params(axis='both', #X轴和Y轴which='major', #主刻度线direction='out', #朝外length=4, #长width=2.0, #粗细labelsize=11) #字体大小
第八部分
# =========================================================================================# ======================================2.颜色库=======================================# =========================================================================================if __name__ == '__main__':data_path = r'data.xlsx' #原始数据路径df = pd.read_excel(data_path) #读取数据df['Is_Outlier'] = False #新建一列用于存储异常值# 遍历不同组别for group in df['Group'].unique():lower = q1 - 1.5 * iqr #下边界upper = q3 + 1.5 * iqr #上边界# 基于先前的分类掩码,进一步把数值小于下界或大于上界的异常值提取出新的布尔掩码outlier_mask = mask & ( (df['Value'] < lower) | (df['Value'] > upper))# 通过DataFrame的loc方法,把新掩码标记为异常值的数据对应所在行的'Is_Outlier'列赋值为Truedf.loc[outlier_mask, 'Is_Outlier'] = True#绘图plot_bean_chart()
如何应用到你自己的数据
1.设置配色方案:
scheme_id = 25 #使用的配色方案2.设置绘图结果的保存地址:
plt.savefig(fr'_chart{scheme_id}.png', dpi=300,bbox_inches='tight')3.设置原始数据的文件路径:
data_path = r'data.xlsx' #原始数据路径推荐
获取方式
本文来自网友投稿或网络内容,如有侵犯您的权益请联系我们删除,联系邮箱:wyl860211@qq.com 。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python 供应链“核弹”级攻击刚刚发生:一个 pip install 就偷走你的所有凭证!
- 从零到一,带你揭开Kali Linux的“神秘”面纱:小白也能上手的渗透测试利器
- Python用户警惕!PyPI有毒包正窃取你的密钥
- 98G Linux+PHP全套学习资源|零基础到运维大神,夸克网盘一键领
- python从基础到AI-机器学习-评估模型的效果
- Python参数传递——位置参数与关键字参数
- Python趣味编程3--满天星
- Python 实战小项目合集|5 个超实用项目,新手也能 1 小时搞定
- Python编辑器怎么选择
- Linux命令每日一清单021:firewalld--动态防火墙管理命令速查表
