
Go 的正则比 Python 慢 25 倍。
这不是一个段子,而是实测数据。同一台机器,同一个 pattern (a+)+b,同一个输入
,Python 的执行时间是 443 ns,而 Golang 需要 11,292 ns。Golang 被按在地上摩擦。
最近 r/golang 有个帖子就因为这组数据炸了锅。评论区吵得很热闹,有人说换第三方库,有人说用 strings.Contains,甚至还有人直接说:Go team 是不是写不好正则?
我决定自己跑一遍。
先看 Go 内部的对比。输入是 1001 个字符(1000 个 a + 末尾一个 b),三种匹配方式:
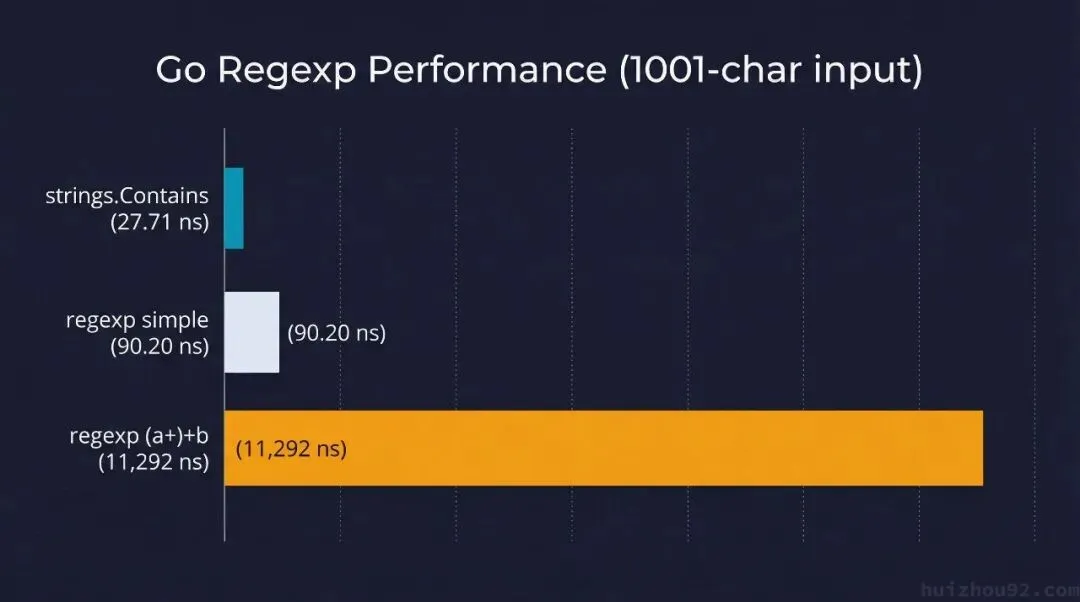
// Go 1.23.4, Intel Xeon Platinum, linux/amd64
strings.Contains(s, "b") 27.71 ns/op ← 字符串查找,基准线
regexp `b` 90.20 ns/op ← 简单正则,慢 3.3x
regexp `(a+)+b` 11,292 ns/op ← 复杂正则,慢 408x
再看 Python,同一台机器,同一个复杂 pattern:
// Python 3.12
Complex regex (a+)+b: 443.6 ns/op ← 比 Go 的 regexp 模式 快 25 倍
数字摆在这里,Go 确实慢。但这组 benchmark 有个前提:输入末尾有 ,匹配成功。回溯引擎找到一条路就停了,所以快。
换句话说,这是最好的情况。
那么最差的情况是什么样?往下看。
两种引擎,两条路
所有的正则引擎可以分为两类。
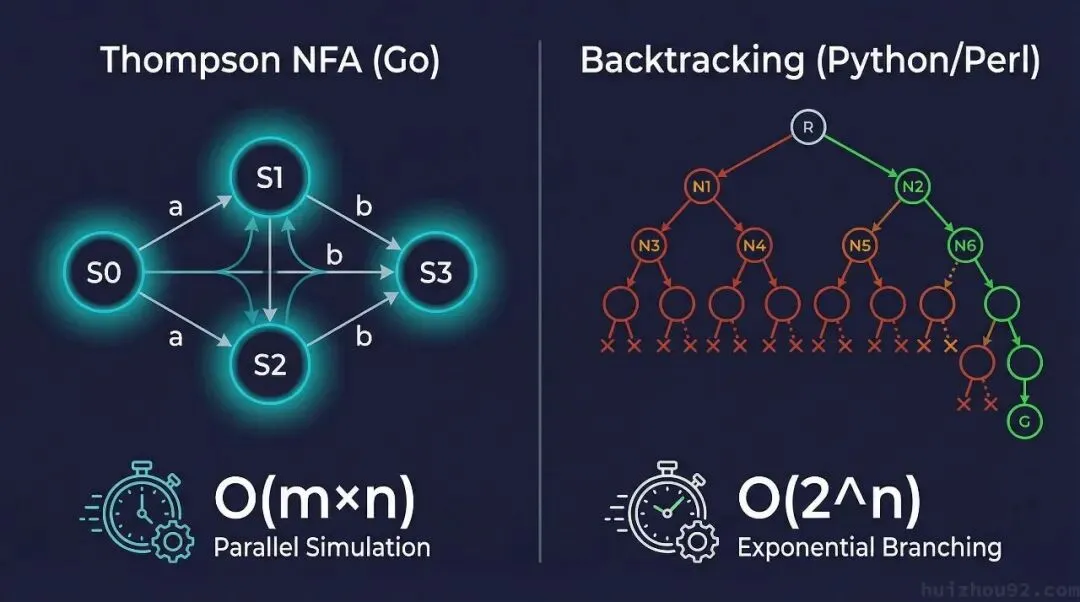
Thompson NFA(Go 用的)——Ken Thompson 1968 年提出。不挑一条路走,而是同时模拟所有可能的状态。时间复杂度严格为 O(m×n),m 是 pattern 长度,n 是输入长度。线性时间,没有例外。
回溯算法(Python、Perl、Java、Ruby、PCRE 等使用的)——它的原理是先试一条路,失败了回头换下一条,直到匹配或穷尽。平均情况很快,但是最坏情况为 O(2ⁿ),指数级爆炸。
Go 选了前者。慢是真的慢,但是它的慢,换来了什么呢?往下看就知道。
换个输入试试
上面的 benchmark 有个前提:Python 用的是有匹配的输入(1000 个 a + b)。回溯引擎找到匹配就停,所以快。
换成无匹配的输入——纯 a 字符串,强迫引擎穷举所有路径——结果完全不同:
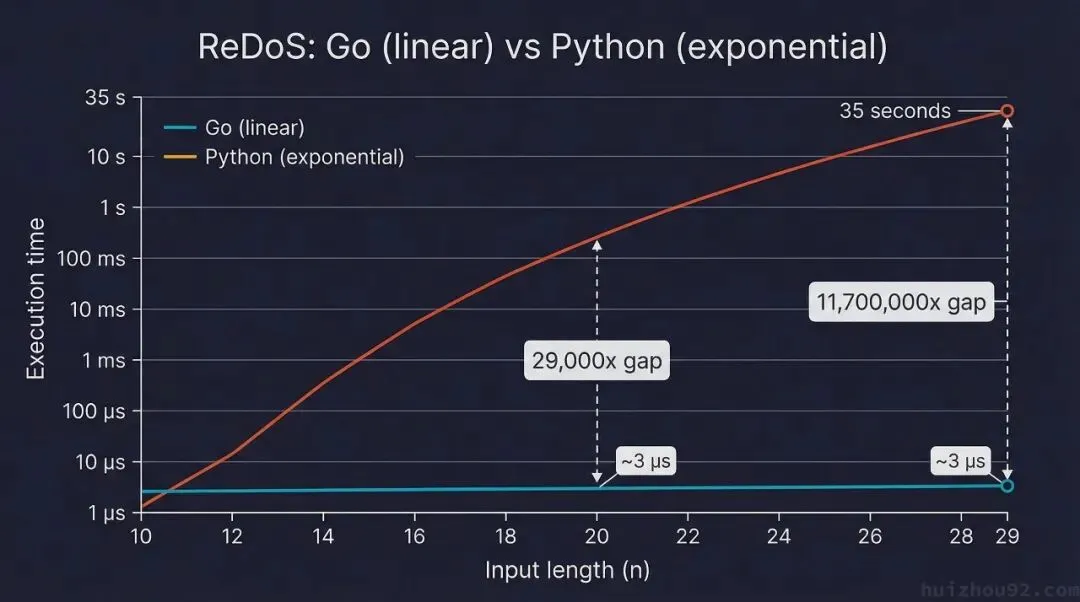
// pattern: (a+)+b,input: 纯 "a"×n,无匹配 → 最坏情况
// 同一台机器,Python 3.12 实测
输入长度 n | Go 耗时 | Python 耗时 | 差距
10 | 1.9 µs | 96 µs | 50x
20 | 2.3 µs | 67,698 µs | 29,000x
25 | 2.9 µs | 2,169,774 µs | 750,000x
29 | 3.0 µs |35,110,024 µs | 11,700,000x
看最后一行:29 个字符,Go 用了 3 微秒,Python 用了 35 秒。1170 万倍的差距。
每多一个字符,Python 耗时翻倍——标准的 O(2ⁿ)。这就是 ReDoS(Regular Expression Denial of Service)。
2019 年 Cloudflare 就踩了这个坑。WAF 里一条有回溯漏洞的正则遇上恶意输入,全球 CPU 打满,流量跌了 80%,宕机 27 分钟。
"A leader in our Solutions Engineering group told me we had lost 80% of our traffic."
— Cloudflare 事故复盘, July 2, 2019
回头看那个"Python 比 Go 快 25 倍"的数字——那是顺风局的成绩。生产环境里,你的正则引擎没法选择只处理"好输入"。
Go 跑 (a+)+b 不管输入是什么,永远 3 微秒左右。这是 Thompson NFA 的数学保证。
Go 内部其实有三个引擎
Go 的 regexp 包不只一个执行引擎,有三个,运行时自动选择。看 src/regexp/exec.go:
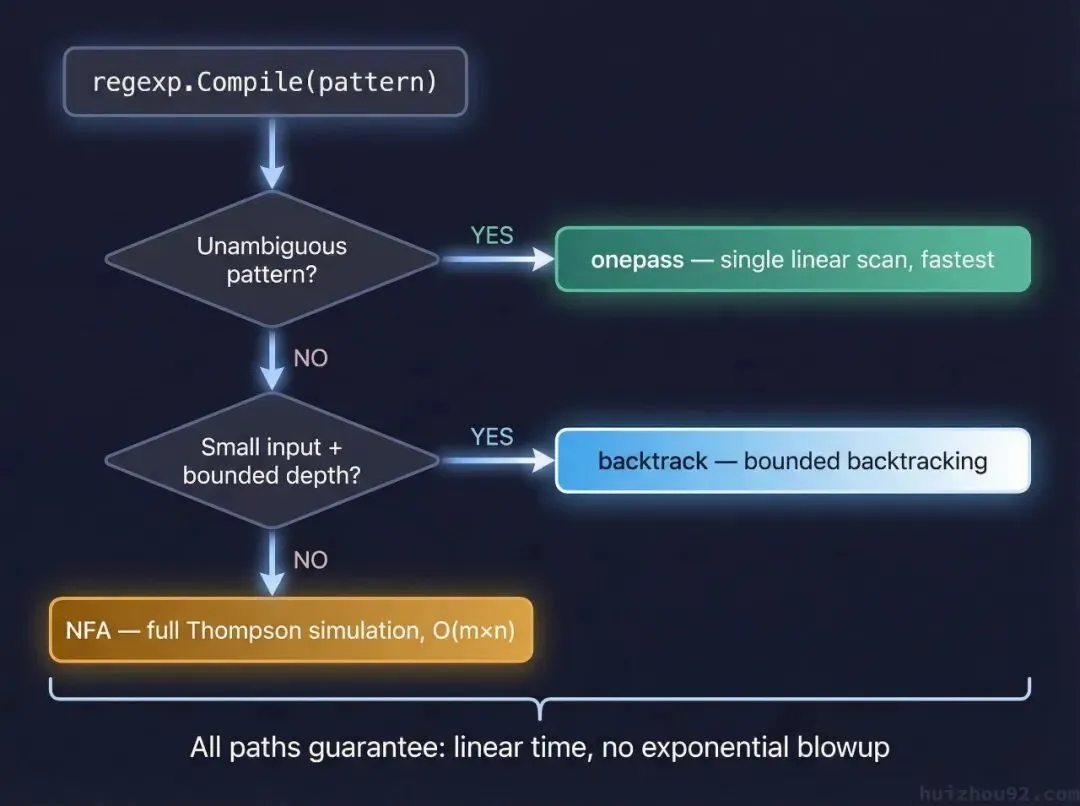
onepass——最快路径。无歧义的简单 pattern,单趟扫描,不回头。
backtrack——中等路径。pattern 稍复杂,但输入在安全范围内,有深度限制的回溯。
NFA(Thompson 全模拟)——兜底路径。复杂 pattern 或无法证明安全的情况下,走这条路。O(mn) 不会更差。
实测里 a+b(走 onepass)和 (a+)+b(走 NFA)在 100 字符输入下几乎一样快——1212 ns vs 1228 ns。你可能觉得三引擎模式没什么用。
不是这样。三引擎模式的价值不在于让快的更快,而在于在最坏情况下有保底。不管 pattern 多复杂,兜底的 NFA 永远是 O(mn),耗时随输入长度线性增长,不会指数爆炸。这是安全设计,不是速度优化。
Russ Cox 在 2007 年就说清楚了
2007 年,Russ Cox 写了一篇文章:
"Perl 匹配一个 29 个字符的字符串需要 60 多秒,而 Thompson NFA 只需要 20 微秒。"
— Russ Cox, Regular Expression Matching Can Be Simple And Fast
他的观点很直接:Thompson 算法 1968 年就解决了这个问题,但大多数语言实现都忘了。现代引擎选回溯,是历史惯性,不是理性选择。
这篇文章定下了 Go regexp 的基调:safe by default。
RE2 也是他做的——Go 标准库 regexp 的加速版,同样基于 NFA,加了 lazy DFA 优化,快很多,仍然保持线性时间。
实际工程怎么选
现在知道原因了,工程实践中要怎么办呢?
- 1. 固定字符串不要用正则:
// ❌ 没必要
matched, _ := regexp.MatchString(`^https://`, url)
// ✅ 更快,更清晰
matched := strings.HasPrefix(url, "https://")
实测:邮件格式验证,regexp 跑 312 ns,手写字符串逻辑跑 7.4 ns,差 42 倍,两者都零分配。能用 strings 就用 strings。
- 2. 最常见的性能问题是每次重新编译:
// ❌ 每次调用都重新编译 pattern
// 实测:1171 ns/op,1717 B/op,19 次内存分配
func IsValid(s string) bool {
matched, _ := regexp.MatchString(`^\d{4}-\d{2}-\d{2}$`, s)
return matched
}
// ✅ 包级变量,只编译一次
// 实测:808 ns/op,0 B/op,0 次内存分配
var dateRe = regexp.MustCompile(`^\d{4}-\d{2}-\d{2}$`)
func IsValid(s string) bool {
return dateRe.MatchString(s)
}
差距不只是速度。每次编译触发 19 次堆分配,高频路径上这是 GC 压力的来源。
- 3. 真的碰到性能瓶颈,考虑
go-re2:
go get github.com/wasilibs/go-re2
RE2 的 Go 实现,接口和标准库几乎一样,复杂 pattern 下快 5–10x,仍保持线性时间。适合高吞吐的日志解析、路由匹配。
- 4. 但是,处理用户输入的正则,用标准库。别把 PCRE 语义暴露给不受信任的输入。
| 场景 | 推荐方案 |
|---|
| 固定字符串匹配 | strings.Contains / bytes.Index |
| 用户提供的 pattern | 标准库 regexp(永远安全) |
| 高频调用、已是瓶颈 | go-re2(需 profiler 确认) |
| 需要 PCRE 语法(反向引用等) | regexp2(但要理解 ReDoS 风险) |
| 其他情况 | 标准库,编译一次,别想太多 |
总结
Go regexp 比字符串操作慢 3–408x,看 pattern 复杂度。Python 有匹配时比 Go 快 25x,没匹配时比 Go 慢 1170 万倍。原因就一个:Go 用 Thompson NFA,拿平均速度换最坏情况的上界。
实际用的时候,编译一次、复用就够了。真有瓶颈,上 go-re2。处理用户输入,别碰 PCRE。
Go 标准库还有不少这种"看起来慢其实是故意的"设计。你碰到过哪些?留言聊聊。
参考资料
- • Russ Cox — Regular Expression Matching Can Be Simple And Fast
- • Go 源码 — src/regexp/exec.go
- • GitHub Issue — regexp: investigate further performance improvements #26623
- • Cloudflare — Details of the Cloudflare outage on July 2, 2019
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
