第一章:CMA 的语义重构——“连续性”只是结果而非前提
1.1 CMA 的设计哲学:从预留到延迟构造
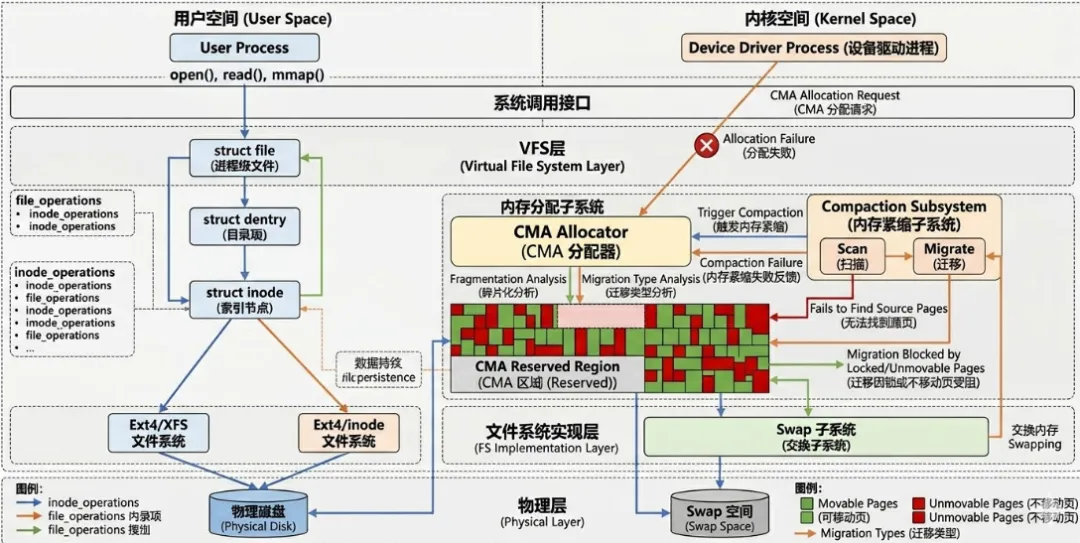
CMA(Contiguous Memory Allocator)经常被误解为“预留一块连续物理内存供设备使用”,但这种理解停留在 boot-time 视角,忽略了 runtime 的动态行为。实际上,CMA 的核心思想并不是静态连续,而是“在需要时构造连续性”。在内核启动阶段,CMA 区域通过 memblock 被标记出来,但这些页并不会永久闲置,而是被放入伙伴系统(buddy allocator),并以 MIGRATE_CMA 类型参与正常分配,这意味着这些页在绝大多数时间是被系统复用的。换言之,CMA 并不保证物理连续性始终存在,而是保证“理论上可以恢复连续性”。这种设计本质上是一种“延迟构造(deferred construction)”,依赖于后续的 compaction 和 migration 来兑现承诺。
这种语义带来一个重要推论:CMA 的成功与否,不取决于当前 free 内存数量,而取决于“这些页是否仍然具备可迁移性”。也就是说,CMA 的连续性不是静态属性,而是一种动态可恢复能力。一旦这种能力丧失(例如被不可迁移页污染),即使 meminfo 中显示有大量 CmaFree,也无法完成分配。因此,从系统设计角度看,CMA 实际上是一个“以迁移能力为前提的连续性合成机制”,而不是简单的内存池。
1.2 pageblock 粒度:连续性的最小约束单位
Linux 内存管理并不是逐页(4KB)维护迁移属性,而是以 pageblock(通常为 2MB,对应一个 hugepage 大小)为单位维护 migratetype。这一点极其关键,因为 CMA 的连续性也是在 pageblock 粒度上成立的。每个 pageblock 都有一个 migratetype 标志,例如 MIGRATE_MOVABLE、MIGRATE_UNMOVABLE、MIGRATE_CMA 等,这些类型决定了该区域在 compaction 和 fallback 时的行为。当 CMA 分配请求到来时,内核并不是简单地找连续页,而是尝试找到一组 pageblock,使得这些 pageblock 可以被完全清空并重新组合。
问题在于,一旦某个 pageblock 中混入一个不可迁移页(例如 slab 对象或 pinned page),整个 pageblock 在逻辑上就无法再用于构造连续空间。这种“以块为单位的失败放大效应”是 CMA 失败的核心机制之一。换句话说,连续性并不是被“打碎”,而是被“污染”:一个 pageblock 的污染会导致整个块失效,从而在宏观上表现为高阶页分配失败。因此,理解 CMA 的关键不是“页是否连续”,而是“pageblock 是否纯净且可迁移”。
第二章:CMA 分配路径的真实执行逻辑
2.1 alloc_contig_range:连续性的重建流程
CMA 分配的核心函数是 alloc_contig_range(),它并不是传统意义上的分配函数,而是一个“构造函数”。其执行流程可以抽象为:首先标记目标 pageblock 为 isolate 状态,防止新的分配进入;然后遍历该范围内的所有页,将可迁移页迁移到其他区域;接着对不可回收页执行 reclaim 尝试;最后检查该范围是否全部变为 free,如果是,则将其从 buddy 中摘除并返回给调用者。整个过程本质上是一个“清场 + 验证”的过程,而不是直接从 free list 获取。
这个过程的复杂性在于它依赖多个子系统协同:migration 依赖 LRU 管理和 reverse mapping,reclaim 依赖 shrinker 和回收策略,而 isolate 依赖 pageblock 的一致性。如果任何一个环节失败,整个分配都会失败。因此,CMA 分配的成功概率实际上是多个概率的乘积,而不是单一条件判断。这也是为什么在高负载系统中,CMA 分配成功率会呈指数级下降。
2.2 三类失败路径:不可迁移、不可回收、不可收敛
从执行路径上看,CMA 失败可以归结为三类:第一类是不可迁移页阻塞,例如 GUP(get_user_pages)固定的页、内核栈、page table 等,这些页没有 migration path,直接导致 pageblock 无法清空;第二类是不可回收页,例如 slab 中的活跃对象或写回中的 page cache,这些页理论上可以释放,但在当前时间点无法回收;第三类是 compaction 无法收敛,即系统中存在足够的 free 页,但由于分布不连续,迁移过程无法将其聚合成高阶块。
这三类失败路径的本质差异在于:第一类是“绝对不可行”,第二类是“时序不可行”,第三类是“算法不可行”。在实际系统中,这三种情况往往叠加出现,形成复杂的 failure pattern。例如,一个 pageblock 可能既包含 pinned page,又包含 writeback page,同时系统还处于高碎片状态,此时 compaction 即使运行多次也无法成功。因此,单纯增加内存或触发 reclaim 并不能解决问题,必须从迁移类型和 pageblock 纯度角度入手。
第三章:碎片化的本质——从空间分布到语义污染
3.1 外部碎片的误区:连续性不是“空闲的排列”
传统上,外部碎片被定义为“空闲内存被分散在不同位置,无法形成大块连续空间”。但在 Linux 的实现中,这种定义是不完整的,因为连续性不仅要求“空闲”,还要求“可清空”。换句话说,即使某个区域当前是占用状态,只要其中的页可以迁移或回收,它仍然可以参与连续性构造。因此,碎片化的真正含义不是“分散”,而是“无法被重组”。
这种重新定义带来一个关键洞察:碎片化是一个“语义问题”,而不是纯粹的空间问题。两个系统可能拥有相同的 free 内存分布,但如果其中一个系统的 pageblock 被 UNMOVABLE 污染,它就无法完成高阶分配。因此,在分析 CMA 失败时,单纯查看 buddyinfo 或 free 内存是远远不够的,必须结合 pagetypeinfo 来判断 pageblock 的迁移属性。
3.2 pageblock 污染模型:失败的放大机制
pageblock 污染可以形式化为一个简单模型:设一个 pageblock 包含 N 个页,只要其中存在一个不可迁移页,该 block 即不可用于连续分配。这个模型意味着污染具有“1→∞”的放大效应,即一个页可以使整个 2MB 区域失效。在系统运行过程中,这种污染会不断累积,导致可用的纯净 pageblock 数量逐渐减少,最终使 compaction 无法找到足够的目标区域。
污染的来源主要包括:slab 分配(尤其是 dentry、inode 等长期驻留对象)、内核结构体(task_struct)、用户空间 pin(如 RDMA、GPU 映射)以及文件系统元数据。这些对象的共同特征是生命周期长、不可迁移或难以回收。一旦它们落入 CMA 区域,就会形成“永久污染”,除非系统重启或通过特殊手段回收。因此,CMA 失败往往不是瞬时事件,而是长期演化的结果。
第四章:迁移类型与 fallback 机制的结构性冲突
4.1 migratetype 体系:逻辑隔离与物理共享
Linux 通过 migratetype 实现不同类型分配的隔离,例如 UNMOVABLE、RECLAIMABLE、MOVABLE 和 CMA。理论上,这种隔离可以减少碎片化,因为不同类型的页不会混合在同一个 pageblock 中。然而,在实际实现中,这种隔离并不是绝对的,因为 buddy allocator 支持 fallback 机制,即当某种类型的 free list 不足时,可以从其他类型借用页。
这种设计在提高内存利用率的同时,也引入了结构性风险:隔离被打破,污染开始跨类型传播。特别是当 UNMOVABLE 分配 fallback 到 CMA 区域时,会直接破坏 CMA 的可迁移性假设。由于 UNMOVABLE 页无法迁移,这种污染是不可逆的,从而导致 CMA 区域逐渐退化为普通内存。
4.2 fallback 的长期效应:CMA 的“腐化过程”
fallback 并不会立即导致问题,但其长期累积效应是灾难性的。在系统运行初期,CMA 区域通常是干净的,可以成功完成分配;随着时间推移,fallback 逐渐将 UNMOVABLE 页注入 CMA 区域,这些页无法被 compaction 移走,从而形成污染点。随着污染点数量增加,可用的连续 pageblock 数量呈指数级下降,最终导致分配失败。
这种过程可以类比为“腐化”:CMA 区域从一个高纯度、可迁移的内存池,逐渐变成一个混合用途的普通区域。更糟糕的是,这一过程是不可逆的,因为内核没有机制将 pageblock 重新“净化”。因此,一旦系统运行足够长时间,CMA 失败几乎是必然事件,除非采取额外的隔离或限制措施。
第五章:compaction 的算法边界与失败模式
5.1 双指针算法:free scanner 与 migrate scanner
compaction 的核心是一个双指针算法:free scanner 从高地址向低地址扫描,寻找空闲页;migrate scanner 从低地址向高地址扫描,寻找可迁移页。通过不断将可迁移页移动到低地址区域,释放高地址的连续空间,从而形成高阶页。这一算法在理论上可以在任意碎片状态下收敛,但前提是存在足够的可迁移页。
问题在于,在实际系统中,这一前提往往不成立。由于 pageblock 污染的存在,很多页无法参与迁移,导致 migrate scanner 无法找到足够的候选页。同时,free scanner 也可能因为高阶页被拆分而无法找到足够大的空闲区域。这种双重限制使得 compaction 的收敛性大幅下降。
5.2 失败模式:partial success 与 livelock
compaction 的返回状态包括 COMPACT_SUCCESS、COMPACT_PARTIAL 和 COMPACT_FAILED,其中 PARTIAL 表示虽然有部分进展,但未达到目标。在 CMA 场景中,大多数失败都表现为 PARTIAL,即系统不断进行迁移,但始终无法形成足够大的连续块。这种状态在高负载下可能演化为 livelock,即 CPU 大量消耗在 compaction 上,但分配仍然失败。
这种现象的根本原因在于:compaction 是一个局部优化算法,而 CMA 需要全局连续性。局部迁移可能改善某些区域的连续性,但同时也可能破坏其他区域,从而导致整体无法收敛。因此,在污染严重的系统中,compaction 的收益会逐渐降低,最终变得几乎无效。
第六章:长时间运行系统的不可逆退化
6.1 时间维度:从随机分布到结构性失效
在系统初始阶段,内存分布相对均匀,pageblock 污染较少,compaction 可以有效工作。但随着时间推移,各种长期对象逐渐占据内存,例如 slab 缓存、文件系统元数据、用户态 pin 等,这些对象会随机分布在各个 pageblock 中,从而逐步增加污染密度。当污染密度超过某个阈值时,系统将无法再找到足够数量的纯净 pageblock。
这一过程可以视为一种“相变”:从一个可重组的系统,转变为一个不可重组的系统。一旦进入这一状态,CMA 分配几乎必然失败,即使系统仍有大量空闲内存。因此,CMA 问题本质上是一个时间演化问题,而不是瞬时资源不足问题。
6.2 与 THP 的统一解释框架
Transparent Huge Page(THP)分配失败与 CMA 具有相同的根本原因:都依赖 compaction 来构造高阶连续页。当 pageblock 被污染后,THP 也会失败。这表明,高阶分配问题可以用统一的框架解释:即“pageblock 纯度决定连续性可构造性”。在这一框架下,CMA 和 THP 只是不同的应用场景,而其底层机制完全一致。
这种统一视角有助于我们理解为什么某些优化(如提高 compaction 频率)对两者都有帮助,同时也解释了为什么这些优化无法从根本上解决问题,因为它们并没有改变 pageblock 污染的事实。
第七章:watermark 与分配策略的隐性约束
7.1 watermark:容量约束而非结构约束
zone watermark(min/low/high)控制的是内存分配的触发条件,而不是连续性。当 free 内存低于 min 时,内核会触发 reclaim 和 compaction,但这些机制只保证“有足够的 free 页”,并不保证这些页是连续的。因此,即使 watermark 满足,CMA 分配仍可能失败。
此外,watermark 还会限制 alloc_contig_range 的行为,因为该函数在清空 pageblock 时也需要消耗 free 页,如果系统处于低水位状态,内核可能拒绝进一步分配,从而导致分配提前失败。这种“容量与结构的错位”是 CMA 问题的另一个关键因素。
7.2 PCP 与局部缓存:隐藏的碎片来源
per-cpu page list(PCP)用于提高分配性能,但它会缓存大量 order-0 页,这些页不会立即返回到 buddy system,因此无法参与 compaction。这意味着,即使系统中存在大量 free 页,它们也可能被分散在各个 CPU 的本地缓存中,从而无法合并为高阶页。
这种机制在高并发系统中尤为明显,因为每个 CPU 都会持有一定数量的页,导致全局视角下的碎片化加剧。因此,在分析 CMA 失败时,必须考虑 PCP 的影响,否则可能误判系统的实际可用内存结构。
第八章:CMA 失败的诊断方法论
8.1 多维观测:buddyinfo、pagetypeinfo 与 trace
诊断 CMA 失败需要从多个维度入手。首先,通过 /proc/buddyinfo 查看高阶页分布,如果高阶页数量为零,则说明存在严重碎片化;其次,通过 /proc/pagetypeinfo 查看各 migratetype 的分布,重点关注 CMA 区域是否被 UNMOVABLE 污染;最后,通过 tracepoint(如 compaction events)观察 compaction 的执行情况,判断是否存在反复失败或 livelock。
这些工具提供的是不同层面的信息:buddyinfo 反映空间结构,pagetypeinfo 反映语义结构,trace 反映动态行为。只有将三者结合,才能准确定位问题根因。
8.2 根因归类:不可迁移、不可回收与不可收敛
在收集数据后,可以将问题归类为三种类型:如果 pagetypeinfo 显示大量 UNMOVABLE 页占据 CMA 区域,则属于不可迁移问题;如果 compaction 日志显示大量 writeback 或 reclaim 失败,则属于不可回收问题;如果系统反复执行 compaction 但无明显进展,则属于不可收敛问题。不同类型的问题需要不同的解决策略,因此准确分类至关重要。
这种方法论的核心在于:将复杂的现象分解为基本机制,从而避免盲目调优。例如,单纯增加内存或提高 compaction 参数,往往只能缓解症状,而无法解决根因。
第九章:工程化对策与系统设计原则
9.1 从“避免污染”到“控制退化”
解决 CMA 问题的关键在于控制 pageblock 污染。首先,可以通过增加 CMA 区域大小和使用 ZONE_MOVABLE 来减少 fallback 的概率,从而保护 CMA 区域的纯度;其次,可以限制 UNMOVABLE 分配,例如优化 slab 使用或减少长期 pin;再次,可以在系统初始化阶段提前分配 CMA,避免在碎片化环境中进行分配。
这些措施的共同目标是:延缓系统从“可重组状态”向“不可重组状态”的退化过程。虽然无法完全避免退化,但可以显著延长系统的稳定运行时间。
9.2 结论:连续性是一种能力,而不是资源
从根本上看,CMA 问题揭示了一个重要原则:连续性并不是一种资源,而是一种能力。这种能力依赖于 pageblock 的纯度、迁移机制的有效性以及系统整体的内存结构。一旦这种能力丧失,即使拥有再多的内存,也无法满足高阶分配需求。
因此,系统设计的重点不应是“增加内存”,而应是“维护可重组性”。这包括合理的内存隔离策略、对 fallback 的控制以及对长期对象的管理。只有在这一框架下,才能真正理解并解决 CMA 分配失败的问题。