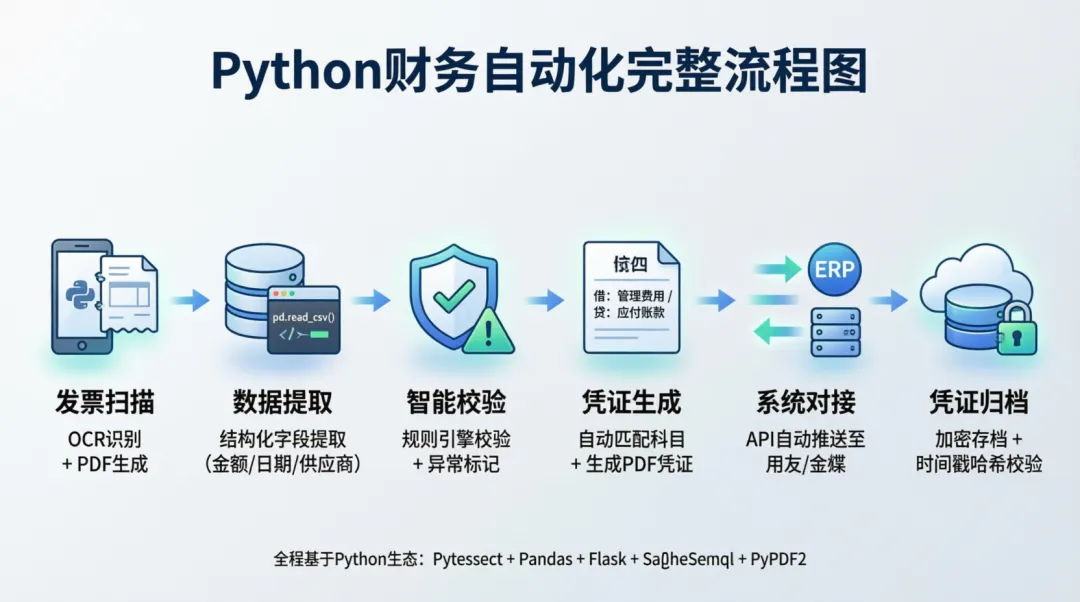
在上一篇文章里,咱们聊了怎么用Python处理单张发票。今天继续往下走,重点说说怎么批量处理一堆发票,然后自动生成财务凭证。这是财务自动化里最实用的一个场景。一、批量发票处理,整体怎么搭
处理多张发票,可不是简单地把“单张处理”重复跑一遍,而是需要一套完整的管理流程。一个成熟的批量处理系统,一般会有这么几个模块:首先是文件收集模块。企业日常会产生大量纸质和电子发票,系统需要能够从不同渠道自动归集这些文件。可以使用Python的watchdog库监控指定文件夹,也可以对接邮件、电子票据平台的接口来拿文件。。
其次是智能识别模块。发票拿到手,得把里面的关键信息提取出来。这就得靠OCR(光学字符识别)技术了。常用的有百度AI、腾讯云OCR,或者开源的Tesseract。识别出来的数据,还得再校验一遍,比如发票代码、金额、税额这些字段对不对。
第三是数据整合模块。就是把识别出来的发票信息和业务系统里的数据对上号。比如把采购发票和采购订单做匹配,把销售发票和销售合同关联起来。这一步会遇到数据对不齐、有异常等情况,需要处理好。
最后是凭证生成模块。前面的步骤都搞定了,就根据提前设定好的会计规则,自动生成记账凭证。具体怎么生成,得看发票类型,比如是采购、销售还是退货,然后再确定借方、贷方科目和金额。
二、核心代码实现思路
接下来咱们看一下批量处理的核心代码结构。先定义一个发票的数据模型:from dataclasses import dataclassfrom typing import Listfrom datetime import datetime@dataclassclass Invoice: invoice_code: str # 发票代码 invoice_no: str # 发票号码 date: datetime # 开票日期 amount: float # 发票金额 tax: float # 税额 supplier: str # 供应商名称 invoice_type: str # 发票类型
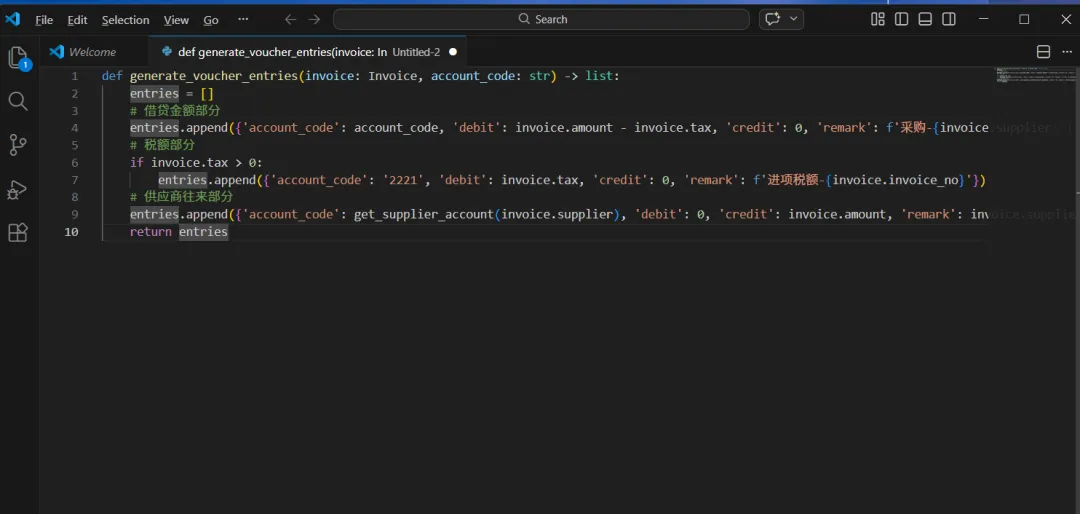
批量处理的主函数,需要加上异常处理和事务回滚的逻辑:def batch_process_invoices(invoices: List[Invoice], rules: dict) -> list: results = [] for invoice in invoices: try: validate_invoice(invoice) # 校验发票 account_code = match_account(invoice, rules) # 匹配会计科目 entries = generate_voucher_entries(invoice, account_code) # 生成凭证分录 results.append({'status': 'success', 'invoice_no': invoice.invoice_no, 'entries': entries}) except Exception as e: results.append({'status': 'failed', 'invoice_no': invoice.invoice_no, 'error': str(e)}) return results

三、凭证生成的关键逻辑
生成凭证,说白了就是把发票信息“翻译”成会计分录。拿采购发票举例,典型的分录是这样的:
借:原材料(或相关科目) 贷:应付账款
税额部分得单独处理:
借:应交税费-进项税额 贷:应付账款
系统会根据发票类型、税率、供应商性质这些因素,自动判断该用哪个科目。一般我们会用配置好的规则引擎来实现:

四、实际用的时候,注意这几个点
在实际项目里搞批量处理,有几个地方要特别留意:数据准确性是首要考量。发票数据直接关系到财务报表,马虎不得。建议在关键环节加个人工复核的步骤。
性能优化不可忽视。如果一次性要处理几千上万张发票,就得考虑并发处理、进度条、日志记录这些了。可以用concurrent.futures来实现并行处理。
异常处理要完善。实际业务中啥情况都可能遇到,比如发票模糊识别不出来、重复扫描、数据格式不对等等,这些都要提前考虑到。
扩展性设计很重要。建议把业务规则、数据字典、科目映射这些东西都做成配置化的,这样后续调整和维护起来就方便多了。
好了,今天咱们就聊到这儿。
如果觉得文章对你有帮助,记得点赞、转发、收藏喔!