【重复测量纵向数据】Python11.联合模型(Joint Models,JM)
- 2026-07-04 11:10:28

纵向数据是在不同时间点上对同一组个体、物体或实体进行重复观测所收集的数据。它就像给研究对象拍摄“动态影像”,能记录其随时间变化的过程,帮助我们理解趋势、模式和影响因素。

11.联合模型
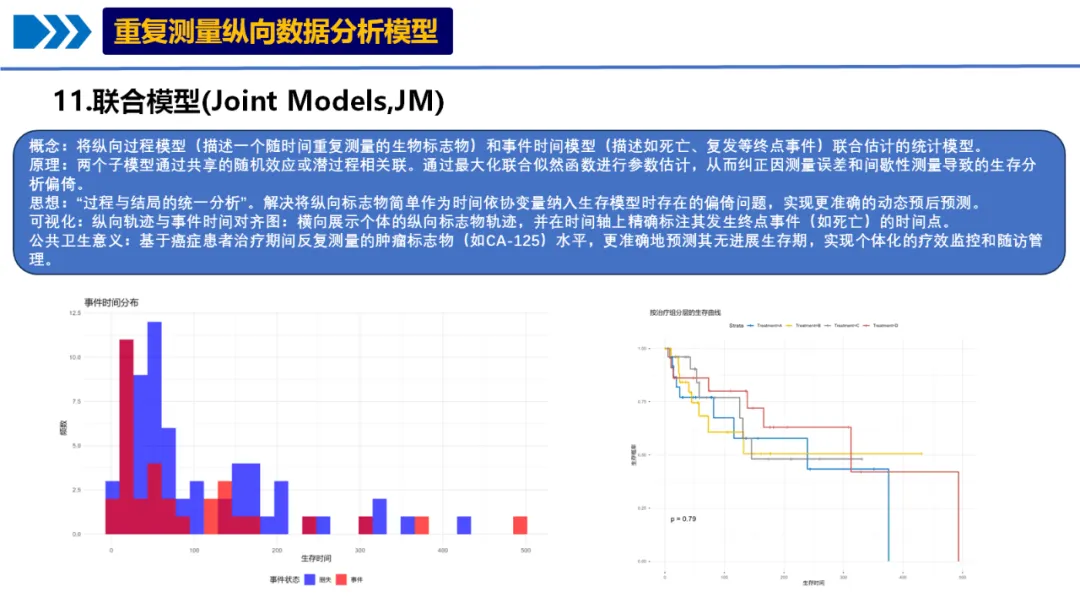
概念:将纵向过程模型(描述一个随时间重复测量的生物标志物)和事件时间模型(描述如死亡、复发等终点事件)联合估计的统计模型。
原理:两个子模型通过共享的随机效应或潜过程相关联。通过最大化联合似然函数进行参数估计,从而纠正因测量误差和间歇性测量导致的生存分析偏倚。
思想:“过程与结局的统一分析”。解决将纵向标志物简单作为时间依协变量纳入生存模型时存在的偏倚问题,实现更准确的动态预后预测。
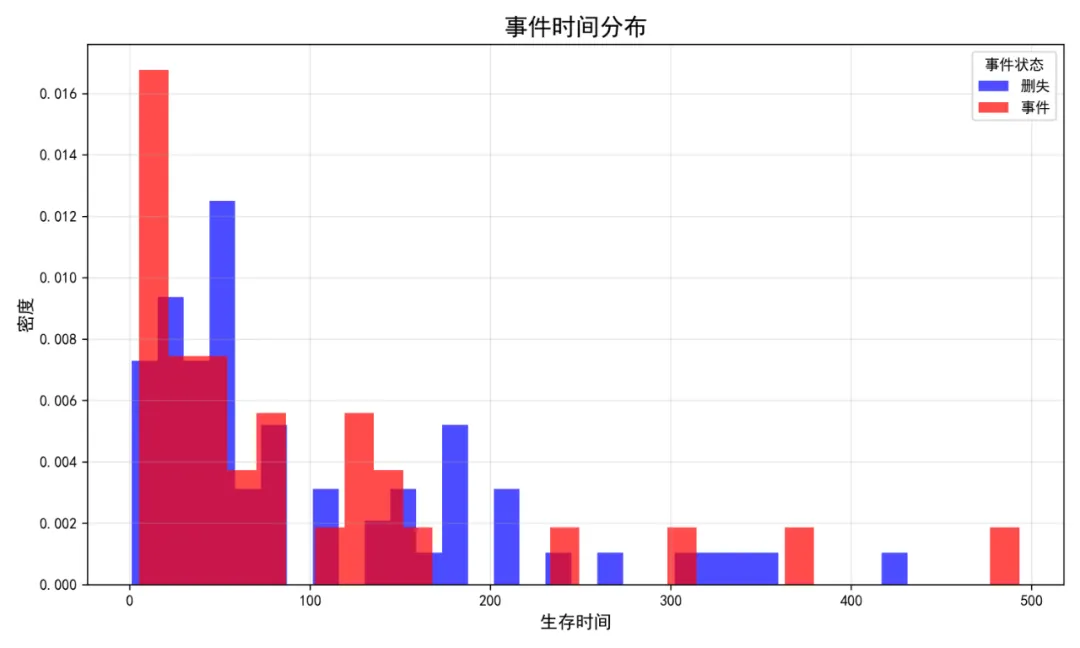
可视化:纵向轨迹与事件时间对齐图:横向展示个体的纵向标志物轨迹,并在时间轴上精确标注其发生终点事件(如死亡)的时间点。
公共卫生意义:基于癌症患者治疗期间反复测量的肿瘤标志物(如CA-125)水平,更准确地预测其无进展生存期,实现个体化的疗效监控和随访管理。
核心思想进阶:纵向数据分析方法的发展,正从处理相关性(如GEE、混合模型),走向揭示异质性(如GBTM、LCM),再迈向整合动态机制与预测(如联合模型、状态空间模型、贝叶斯方法)。
1.数据预处理:
2.模型拟合:
3.模型可视化:
4.结果保存与报告生成
总的来说,纵向数据因其时间延续性和对象一致性,成为了解事物动态发展过程、探究因果关系的强大工具。
当然,处理纵向数据也伴随一些挑战,例如成本较高、可能存在数据缺失,且分析方法通常比处理横截面数据更为复杂。
下面我们使用R语言进行纵向数据Python11.联合模型(Joint Models,JM):
# pip install pandas numpy matplotlib seaborn scipy statsmodels lifelines scikit-learn plotly reportlab openpyxl xlsxwriter# =========================================================================# 11. 联合模型 (Joint Model) 分析 - Python版# =========================================================================import osimport sysimport pandas as pdimport numpy as npimport warningsfrom datetime import datetimefrom pathlib import Pathimport matplotlib.pyplot as pltimport seaborn as snsfrom scipy import statsimport statsmodels.api as smfrom statsmodels.formula.api import mixedlmfrom lifelines import KaplanMeierFitter, CoxPHFitterfrom lifelines.statistics import logrank_testimport plotly.graph_objects as gofrom plotly.subplots import make_subplotsimport plotly.express as pxfrom sklearn.preprocessing import StandardScalerfrom sklearn.metrics import roc_curve, auc, roc_auc_scorefrom reportlab.lib.pagesizes import letterfrom reportlab.platypus import SimpleDocTemplate, Paragraph, Spacer, Image, Table, TableStylefrom reportlab.lib.styles import getSampleStyleSheet, ParagraphStylefrom reportlab.lib.units import inchfrom reportlab.lib import colorsimport pickleimport json# 设置中文显示plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS', 'DejaVu Sans']plt.rcParams['axes.unicode_minus'] = False# 忽略警告warnings.filterwarnings('ignore')# =========================================================================# 1. 环境设置和数据准备# =========================================================================def setup_environment():"""设置工作环境"""# 获取桌面路径 desktop_path = Path.home() / "Desktop"# 创建结果文件夹 results_dir = desktop_path / "11-JM结果" results_dir.mkdir(exist_ok=True)# 设置当前工作目录 os.chdir(results_dir)print("工作目录设置为:", results_dir)return results_dirdef load_and_preprocess_data(desktop_path):"""加载和预处理数据"""print("1. 数据准备与预处理...") try:# 读取Excel数据 data_file = desktop_path / "longitudinal_data.xlsx"# 尝试读取完整数据集用于获取生存数据 try: full_data = pd.read_excel(data_file, sheet_name="Full_Dataset") except:# 尝试第一个sheet full_data = pd.read_excel(data_file, sheet_name=0)print("使用第一个sheet作为Full_Dataset")# 尝试读取简化数据集用于纵向过程 try: simple_data = pd.read_excel(data_file, sheet_name="Simple_Dataset") except:# 尝试第二个sheet try: simple_data = pd.read_excel(data_file, sheet_name=1)print("使用第二个sheet作为Simple_Dataset") except:# 如果没有第二个sheet,使用第一个sheet的子集 simple_data = full_data.copy()print("使用Full_Dataset作为Simple_Dataset")# 数据清洗和转换 full_data = full_data.copy() full_data['ID'] = full_data['ID'].astype('category') full_data['Time'] = pd.to_numeric(full_data['Time'], errors='coerce') full_data['Outcome_Continuous'] = pd.to_numeric(full_data['Outcome_Continuous'], errors='coerce') full_data['Age'] = pd.to_numeric(full_data['Age'], errors='coerce') full_data['Sex'] = full_data['Sex'].astype('category') full_data['Treatment'] = full_data['Treatment'].astype('category') full_data['Baseline_Score'] = pd.to_numeric(full_data['Baseline_Score'], errors='coerce') full_data['School_ID'] = full_data['School_ID'].astype('category')# 尝试转换日期列 try: full_data['Measurement_Date'] = pd.to_datetime(full_data['Measurement_Date'], errors='coerce') except:# 如果没有日期列,创建一个虚拟列 full_data['Measurement_Date'] = pd.Timestamp('2023-01-01')print("创建虚拟日期列") full_data['Survival_Time'] = pd.to_numeric(full_data['Survival_Time'], errors='coerce') full_data['Event_Status'] = pd.to_numeric(full_data['Event_Status'], errors='coerce')# 删除缺失的生存时间 full_data = full_data.dropna(subset=['Survival_Time'])# 处理简单数据集 simple_data = simple_data.copy() simple_data['ID'] = simple_data['ID'].astype('category') simple_data['Time'] = pd.to_numeric(simple_data['Time'], errors='coerce')# 检查是否有Outcome列if'Outcome' not in simple_data.columns:# 尝试使用其他列名if'Outcome_Continuous'in simple_data.columns: simple_data['Outcome'] = simple_data['Outcome_Continuous']else:# 使用第一列数值型列 numeric_cols = simple_data.select_dtypes(include=[np.number]).columnsif len(numeric_cols) > 1: simple_data['Outcome'] = simple_data[numeric_cols[1]]else:# 创建示例数据 np.random.seed(123) simple_data['Outcome'] = np.random.normal(50, 10, len(simple_data)) simple_data['Outcome'] = pd.to_numeric(simple_data['Outcome'], errors='coerce')# 添加其他必要的列for col in ['Age', 'Sex', 'Treatment', 'Baseline_Score']:if col not in simple_data.columns and col in full_data.columns:# 从full_data中获取 simple_data = simple_data.merge(full_data[['ID', col]].drop_duplicates(), on='ID', how='left')# 确保有必要的分类列for col in ['Age', 'Sex', 'Treatment', 'Baseline_Score']:if col in simple_data.columns:if col in ['Sex', 'Treatment']: simple_data[col] = simple_data[col].astype('category')else: simple_data[col] = pd.to_numeric(simple_data[col], errors='coerce')# 删除完全缺失Outcome的行 simple_data = simple_data.dropna(subset=['Outcome'])# 提取生存数据(每个个体一行) survival_data = full_data.groupby('ID').first().reset_index() survival_data = survival_data[['ID', 'Age', 'Sex', 'Treatment', 'Baseline_Score','School_ID', 'Survival_Time', 'Event_Status']].copy()# 检查数据结构print(f"生存数据维度: {survival_data.shape}")print(f"纵向数据维度: {simple_data.shape}")# 保存清洗后的数据 survival_data.to_csv("survival_data.csv", index=False, encoding='utf-8-sig') simple_data.to_csv("longitudinal_data.csv", index=False, encoding='utf-8-sig')return full_data, simple_data, survival_data except Exception as e:print(f"数据加载失败: {str(e)}")print("创建示例数据...")return create_sample_data()def create_sample_data():"""创建示例数据"""print("正在创建示例数据...") np.random.seed(123) n_patients = 100# 生存数据 survival_data = pd.DataFrame({'ID': range(1, n_patients + 1),'Age': np.random.normal(60, 10, n_patients),'Sex': np.random.choice(['Male', 'Female'], n_patients),'Treatment': np.random.choice(['A', 'B', 'C'], n_patients),'Baseline_Score': np.random.normal(50, 15, n_patients),'Survival_Time': np.random.exponential(365, n_patients),'Event_Status': np.random.binomial(1, 0.3, n_patients) })# 纵向数据 longitudinal_data = []for i in range(1, n_patients + 1): n_visits = np.random.randint(2, 8) base_outcome = np.random.normal(50, 5) slope = np.random.normal(0.1, 0.05)for j in range(n_visits): longitudinal_data.append({'ID': i,'Time': j * 30, # 每30天测量一次'Outcome': base_outcome + slope * j * 30 + np.random.normal(0, 2),'Age': survival_data.loc[i - 1, 'Age'],'Sex': survival_data.loc[i - 1, 'Sex'],'Treatment': survival_data.loc[i - 1, 'Treatment'],'Baseline_Score': survival_data.loc[i - 1, 'Baseline_Score'] }) simple_data = pd.DataFrame(longitudinal_data)# 添加额外列以匹配原始结构 full_data = simple_data.copy() full_data['Outcome_Continuous'] = full_data['Outcome'] full_data['School_ID'] = np.random.choice(['S001', 'S002', 'S003'], len(full_data)) full_data['Measurement_Date'] = pd.Timestamp('2023-01-01') + pd.to_timedelta(full_data['Time'], unit='D')return full_data, simple_data, survival_data# =========================================================================# 2. 探索性数据分析# =========================================================================def exploratory_data_analysis(survival_data, simple_data):"""探索性数据分析"""print("\n2. 探索性数据分析...")# 2.1 生存数据描述 event_summary = {'Total': len(survival_data),'Events': int(survival_data['Event_Status'].sum()),'Censored': int((survival_data['Event_Status'] == 0).sum()),'Event_Rate': round(survival_data['Event_Status'].sum() / len(survival_data) * 100, 1) }print("事件发生率:")for key, value in event_summary.items():print(f" {key}: {value}")# 2.2 生存函数估计(Kaplan-Meier) kmf = KaplanMeierFitter()# 总体生存曲线 plt.figure(figsize=(10, 8)) kmf.fit(survival_data['Survival_Time'], event_observed=survival_data['Event_Status']) kmf.plot_survival_function() plt.title('总体生存曲线 (Kaplan-Meier)', fontsize=16) plt.xlabel('生存时间', fontsize=12) plt.ylabel('生存概率', fontsize=12) plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig('01_总体生存曲线.png', dpi=300) plt.close()# 按治疗组分层的生存曲线if'Treatment'in survival_data.columns: plt.figure(figsize=(10, 8)) treatments = sorted(survival_data['Treatment'].dropna().unique())for treatment in treatments: mask = survival_data['Treatment'] == treatmentif mask.sum() > 0: kmf.fit(survival_data.loc[mask, 'Survival_Time'], event_observed=survival_data.loc[mask, 'Event_Status'], label=f'Treatment {treatment}') kmf.plot_survival_function() plt.title('按治疗组分层的生存曲线', fontsize=16) plt.xlabel('生存时间', fontsize=12) plt.ylabel('生存概率', fontsize=12) plt.legend(title='治疗组') plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig('02_治疗组生存曲线.png', dpi=300) plt.close()# 2.3 纵向轨迹与事件时间对齐图# 选择有事件的个体 event_ids = survival_data[survival_data['Event_Status'] == 1]['ID'].tolist()# 随机选择最多8个有事件的个体 np.random.seed(123) n_to_select = min(8, len(event_ids))if n_to_select > 0: sample_event_ids = np.random.choice(event_ids, n_to_select, replace=False)# 准备数据 plot_data = simple_data[simple_data['ID'].isin(sample_event_ids)].copy() plot_data = plot_data.merge( survival_data[['ID', 'Survival_Time', 'Event_Status']], on='ID', how='left' ) plot_data['ID_label'] = plot_data.apply( lambda x: f"ID {x['ID']} ({'事件' if x['Event_Status'] == 1 else '删失'})", axis=1 ) plot_data['Event_Time'] = np.where( plot_data['Event_Status'] == 1, plot_data['Survival_Time'], np.nan )# 创建纵向轨迹与事件时间对齐图 n_cols = min(4, n_to_select) n_rows = int(np.ceil(n_to_select / n_cols))# 修复子图索引问题 fig, axes = plt.subplots(n_rows, n_cols, figsize=(4 * n_cols, 3 * n_rows))# 如果只有一行,确保axes是一维数组if n_rows == 1:if n_cols == 1: axes = np.array([axes])else: axes = axes.reshape(1, -1)elif n_cols == 1:# 如果只有一列 axes = axes.reshape(-1, 1)# 确保axes是二维数组if axes.ndim == 1: axes = axes.reshape(1, -1)# 展平axes以便按顺序访问 axes_flat = axes.flatten()for idx, (pid, group) in enumerate(plot_data.groupby('ID')):if idx >= len(axes_flat):break ax = axes_flat[idx]# 检查group是否为空if len(group) == 0: ax.axis('off')continue# 安全地获取Treatment信息 title = f"ID {pid}"if'Treatment'in group.columns and len(group) > 0: treatment_value = group['Treatment'].iloc[0] if len(group) > 0 else Noneif pd.notna(treatment_value): title = f"ID {pid} ({treatment_value})"# 安全地获取事件信息 event_time = group['Event_Time'].iloc[0] if len(group) > 0 else np.nan event_status = group['Event_Status'].iloc[0] if len(group) > 0 else 0# 绘制纵向轨迹 ax.plot(group['Time'], group['Outcome'], 'o-', color='blue', alpha=0.7, linewidth=2) ax.set_title(title, fontsize=10) ax.set_xlabel('测量时间点') ax.set_ylabel('生物标志物水平')# 标记事件时间if pd.notna(event_time): ax.axvline(x=event_time, color='red', linestyle='--', alpha=0.7, linewidth=1.5) max_outcome = group['Outcome'].max() if len(group) > 0 else 0 ax.scatter(event_time, max_outcome * 1.05, color='red', marker='^', s=100) ax.grid(True, alpha=0.3)# 隐藏多余的子图for idx in range(n_to_select, len(axes_flat)): axes_flat[idx].axis('off') plt.suptitle('纵向轨迹与事件时间对齐图', fontsize=16) plt.tight_layout() plt.savefig('03_纵向轨迹与事件时间对齐图.png', dpi=300) plt.close()else:print("没有事件个体,跳过纵向轨迹图")# 2.4 事件时间分布 plt.figure(figsize=(10, 6))# 分事件状态绘制直方图for status, color, label in [(0, 'blue', '删失'), (1, 'red', '事件')]: mask = survival_data['Event_Status'] == statusif mask.any(): plt.hist(survival_data.loc[mask, 'Survival_Time'], bins=30, alpha=0.7, color=color, label=label, density=True) plt.title('事件时间分布', fontsize=16) plt.xlabel('生存时间', fontsize=12) plt.ylabel('密度', fontsize=12) plt.legend(title='事件状态') plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig('04_事件时间分布.png', dpi=300) plt.close()# 2.5 基线特征表 try: baseline_cols = ['Age', 'Sex', 'Treatment', 'Baseline_Score', 'Event_Status'] available_cols = [col for col in baseline_cols if col in survival_data.columns]if available_cols: baseline_data = survival_data[available_cols].copy()# 创建描述性统计 numeric_cols = baseline_data.select_dtypes(include=[np.number]).columns.tolist() cat_cols = baseline_data.select_dtypes(include=['category', 'object']).columns.tolist() baseline_table = pd.DataFrame()if'Event_Status'in baseline_data.columns:# 数值变量的描述性统计for col in numeric_cols:if col != 'Event_Status': stats_by_event = baseline_data.groupby('Event_Status')[col].agg(['mean', 'std', 'count']) baseline_table = pd.concat([baseline_table, stats_by_event], axis=0)# 分类变量的描述性统计for col in cat_cols:if col != 'Event_Status':# 创建交叉表 cross_tab = pd.crosstab(baseline_data['Event_Status'], baseline_data[col]) baseline_table = pd.concat([baseline_table, cross_tab], axis=0) baseline_table.to_csv('05_基线特征表.csv', encoding='utf-8-sig') except Exception as e:print(f"基线特征表创建失败: {str(e)}")return event_summary# =========================================================================# 3. 纵向过程模型# =========================================================================def fit_longitudinal_model(simple_data):"""拟合纵向过程模型"""print("\n3. 拟合纵向过程模型...")# 3.1 数据标准化 simple_data = simple_data.copy() scaler = StandardScaler()# 检查并创建必要的列 numeric_cols_to_scale = []for col in ['Age', 'Baseline_Score', 'Time']:if col in simple_data.columns: simple_data[f'{col}_c'] = scaler.fit_transform(simple_data[[col]]) numeric_cols_to_scale.append(f'{col}_c')
# 保存模型 with open('longitudinal_lme_model.pkl', 'wb') as f: pickle.dump(mdf, f)# 3.3 模型诊断 fig, axes = plt.subplots(2, 3, figsize=(15, 10))# 1. 残差与拟合值图 axes[0, 0].scatter(mdf.fittedvalues, mdf.resid, alpha=0.5) axes[0, 0].axhline(y=0, color='red', linestyle='--') axes[0, 0].set_xlabel('拟合值') axes[0, 0].set_ylabel('残差') axes[0, 0].set_title('残差图') axes[0, 0].grid(True, alpha=0.3)# 2. Q-Q图 stats.probplot(mdf.resid, dist="norm", plot=axes[0, 1]) axes[0, 1].set_title('Q-Q图') axes[0, 1].grid(True, alpha=0.3)# 3. 残差直方图 axes[0, 2].hist(mdf.resid, bins=30, edgecolor='black', alpha=0.7) axes[0, 2].set_xlabel('残差') axes[0, 2].set_ylabel('频数') axes[0, 2].set_title('残差分布') axes[0, 2].grid(True, alpha=0.3)# 4. 观察顺序的残差图 axes[1, 0].plot(mdf.resid, color='blue', alpha=0.7) axes[1, 0].axhline(y=0, color='red', linestyle='--') axes[1, 0].set_xlabel('观察序号') axes[1, 0].set_ylabel('残差') axes[1, 0].set_title('残差序列图') axes[1, 0].grid(True, alpha=0.3)# 5. 拟合值与观测值比较 axes[1, 1].scatter(mdf.fittedvalues, simple_data['Outcome'].iloc[:len(mdf.fittedvalues)], alpha=0.5) axes[1, 1].plot([mdf.fittedvalues.min(), mdf.fittedvalues.max()], [mdf.fittedvalues.min(), mdf.fittedvalues.max()], color='red', linestyle='--') axes[1, 1].set_xlabel('拟合值') axes[1, 1].set_ylabel('观测值') axes[1, 1].set_title('拟合值 vs 观测值') axes[1, 1].grid(True, alpha=0.3)# 6. 随机效应分布 try: random_effects = mdf.random_effectsif len(random_effects) > 0: re_df = pd.DataFrame(random_effects).Tif re_df.shape[1] >= 2: axes[1, 2].scatter(re_df.iloc[:, 0], re_df.iloc[:, 1], alpha=0.5) axes[1, 2].set_xlabel('随机截距') axes[1, 2].set_ylabel('随机斜率')else: axes[1, 2].hist(re_df.iloc[:, 0], bins=30, edgecolor='black', alpha=0.7) axes[1, 2].set_xlabel('随机截距') axes[1, 2].set_ylabel('频数') axes[1, 2].set_title('随机效应分布') axes[1, 2].grid(True, alpha=0.3)else: axes[1, 2].axis('off') except: axes[1, 2].axis('off') plt.suptitle('纵向模型诊断图', fontsize=16) plt.tight_layout() plt.savefig('06_纵向模型诊断图.png', dpi=300) plt.close()# 3.4 纵向轨迹预测# 创建预测数据if'Treatment'in simple_data.columns: treatments = simple_data['Treatment'].dropna().unique()if len(treatments) == 0: treatments = ['Default']else: treatments = ['Default'] time_range = np.linspace(simple_data['Time'].min(), simple_data['Time'].max(), 100) pred_data_list = []for treatment in treatments:for time in time_range: pred_entry = {'Time': time}# 添加标准化时间if'Time_c'in simple_data.columns: time_mean = simple_data['Time'].mean() time_std = simple_data['Time'].std() pred_entry['Time_c'] = (time - time_mean) / time_std# 添加其他协变量for col in ['Age_c', 'Baseline_c']:if col in simple_data.columns: pred_entry[col] = 0if'Treatment'in simple_data.columns: pred_entry['Treatment'] = treatment pred_data_list.append(pred_entry) pred_data = pd.DataFrame(pred_data_list)# 预测固定效应 try: pred_data['pred_fixed'] = mdf.predict(pred_data)# 可视化预测轨迹 plt.figure(figsize=(10, 6))# 原始数据点 plt.scatter(simple_data['Time'], simple_data['Outcome'], alpha=0.1, s=10, color='gray', label='原始数据')# 预测轨迹for treatment in treatments: mask = pred_data['Treatment'] == treatmentif mask.any(): plt.plot(pred_data.loc[mask, 'Time'], pred_data.loc[mask, 'pred_fixed'], linewidth=2, label=f'Treatment {treatment}') plt.title('纵向过程模型预测轨迹', fontsize=16) plt.xlabel('时间点', fontsize=12) plt.ylabel('预测的生物标志物水平', fontsize=12) plt.legend(title='治疗组') plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig('07_纵向模型预测轨迹.png', dpi=300) plt.close() except Exception as e:print(f"轨迹预测失败: {str(e)}")return mdf, pred_data if'pred_fixed'in pred_data.columns else None except Exception as e:print(f"纵向模型拟合失败: {str(e)}") import traceback traceback.print_exc()return None, None# =========================================================================# 4. 生存模型# =========================================================================def fit_survival_model(survival_data):"""拟合生存模型"""print("\n4. 拟合生存模型...")# 4.1 数据准备 cox_data = survival_data.copy() scaler = StandardScaler()# 标准化数值变量for col in ['Age', 'Baseline_Score']:if col in cox_data.columns: cox_data[f'{col}_c'] = scaler.fit_transform(cox_data[[col]])# 4.2 Cox比例风险模型 cph = CoxPHFitter() try:# 选择协变量 cox_data_dummy = cox_data.copy()# 创建虚拟变量for col in ['Sex', 'Treatment']:if col in cox_data_dummy.columns: cox_data_dummy = pd.get_dummies(cox_data_dummy, columns=[col], drop_first=True, dtype=float)# 确定协变量列 covariate_cols = []for col in cox_data_dummy.columns:if col not in ['ID', 'Survival_Time', 'Event_Status', 'School_ID']:# 检查列是否全是数值if pd.api.types.is_numeric_dtype(cox_data_dummy[col]): covariate_cols.append(col)if len(covariate_cols) == 0:# 如果没有协变量,只使用截距 covariate_cols = []# 拟合Cox模型 cph.fit(cox_data_dummy[['Survival_Time', 'Event_Status'] + covariate_cols], duration_col='Survival_Time', event_col='Event_Status')print("Cox比例风险模型结果:")print(cph.summary)# 保存模型 cph.save_model('cox_model.pkl')# 4.3 模型诊断# 绘制残差图 fig, axes = plt.subplots(2, 2, figsize=(10, 8)) axes = axes.flatten()# 绘制协变量分布for idx, col in enumerate(covariate_cols[:4]): # 只显示前4个if idx >= len(axes):break try: axes[idx].hist(cox_data_dummy[col], bins=30, alpha=0.7, edgecolor='black') axes[idx].set_title(f'{col} 分布') axes[idx].set_xlabel(col) axes[idx].set_ylabel('频数') except: axes[idx].axis('off') plt.suptitle('Cox模型诊断图', fontsize=16) plt.tight_layout() plt.savefig('08_Cox模型诊断图.png', dpi=300) plt.close()# 4.4 风险比森林图 plt.figure(figsize=(10, 6))# 提取参数 summary = cph.summary summary = summary.reset_index()# 检查列名并重命名 expected_cols = ['covariate', 'coef', 'exp(coef)', 'se(coef)', 'coef lower 95%','coef upper 95%', 'exp(coef) lower 95%', 'exp(coef) upper 95%','z', 'p', '-log2(p)']# 重命名列以匹配预期 rename_dict = {}for i, col in enumerate(summary.columns):if i < len(expected_cols): rename_dict[col] = expected_cols[i] summary = summary.rename(columns=rename_dict)# 创建森林图 y_pos = np.arange(len(summary))# 检查必要的列是否存在if'exp(coef)'in summary.columns and 'exp(coef) lower 95%'in summary.columns and 'exp(coef) upper 95%'in summary.columns: plt.errorbar(summary['exp(coef)'], y_pos, xerr=[summary['exp(coef)'] - summary['exp(coef) lower 95%'], summary['exp(coef) upper 95%'] - summary['exp(coef)']], fmt='o', color='blue', capsize=5) plt.axvline(x=1, color='red', linestyle='--', alpha=0.5)if'covariate'in summary.columns: plt.yticks(y_pos, summary['covariate'])else: plt.yticks(y_pos, [f'Var_{i}'for i in range(len(summary))]) plt.xlabel('风险比 (HR, 对数尺度)') plt.xscale('log') plt.title('Cox模型风险比森林图') plt.grid(True, alpha=0.3, axis='x') plt.tight_layout() plt.savefig('09_Cox模型风险比森林图.png', dpi=300) plt.close()# 保存参数表 summary.to_csv('Cox模型参数表.csv', index=False, encoding='utf-8-sig')return cph, summary except Exception as e:print(f"Cox模型拟合失败: {str(e)}") import traceback traceback.print_exc()return None, None# =========================================================================# 5. 联合模型 (简化实现)# =========================================================================def fit_joint_model(simple_data, survival_data):"""拟合联合模型(简化实现)"""print("\n5. 拟合联合模型...")# 5.1 准备联合模型数据 joint_ids = set(simple_data['ID']).intersection(set(survival_data['ID']))if len(joint_ids) == 0:print("没有共同的ID,无法进行联合模型分析")return None, None simple_data_joint = simple_data[simple_data['ID'].isin(joint_ids)].copy() survival_data_joint = survival_data[survival_data['ID'].isin(joint_ids)].copy()print(f"联合模型分析包含 {len(joint_ids)} 个个体")# 5.2 简化实现:使用纵向特征的时变协变量 try: joint_results = []for pid in list(joint_ids)[:min(20, len(joint_ids))]: # 只处理前20个个体作为示例 indiv_data = simple_data_joint[simple_data_joint['ID'] == pid].copy()if len(indiv_data) > 1: try:# 计算斜率 slope, intercept, r_value, p_value, std_err = stats.linregress( indiv_data['Time'], indiv_data['Outcome'] )# 计算平均变化率if indiv_data['Time'].iloc[-1] != indiv_data['Time'].iloc[0]: avg_change = (indiv_data['Outcome'].iloc[-1] - indiv_data['Outcome'].iloc[0]) / \ (indiv_data['Time'].iloc[-1] - indiv_data['Time'].iloc[0])else: avg_change = 0# 获取生存数据 indiv_surv = survival_data_joint[survival_data_joint['ID'] == pid].iloc[0] joint_results.append({'ID': pid,'slope': slope,'avg_change': avg_change,'baseline_outcome': indiv_data['Outcome'].iloc[0],'last_outcome': indiv_data['Outcome'].iloc[-1],'survival_time': indiv_surv['Survival_Time'],'event_status': indiv_surv['Event_Status'] }) except:continue joint_results_df = pd.DataFrame(joint_results)if len(joint_results_df) > 5: # 至少需要5个个体# 将纵向特征合并到生存数据 surv_with_features = survival_data_joint.merge( joint_results_df[['ID', 'slope', 'avg_change', 'baseline_outcome', 'last_outcome']], on='ID', how='inner' )# 用纵向特征拟合增强的Cox模型 cph_joint = CoxPHFitter()# 准备数据 joint_data = surv_with_features.copy()# 创建虚拟变量for col in ['Sex', 'Treatment']:if col in joint_data.columns: joint_data = pd.get_dummies(joint_data, columns=[col], drop_first=True, dtype=float)# 确定协变量 covariate_cols = []for col in ['Age', 'Baseline_Score', 'slope', 'avg_change', 'baseline_outcome']:if col in joint_data.columns: covariate_cols.append(col)# 添加其他虚拟变量for col in joint_data.columns:if col.startswith('Sex_') or col.startswith('Treatment_'): covariate_cols.append(col)if len(covariate_cols) > 0: cph_joint.fit(joint_data[['survival_time', 'event_status'] + covariate_cols], duration_col='survival_time', event_col='event_status')print("联合模型(简化)结果:")print(cph_joint.summary)# 保存模型 cph_joint.save_model('joint_model_simple.pkl')# 5.3 联合模型可视化 visualize_joint_model(simple_data_joint, survival_data_joint, cph_joint)return cph_joint, joint_results_dfelse:print("没有可用的协变量进行联合模型分析")return None, None except Exception as e:print(f"联合模型拟合失败: {str(e)}") import traceback traceback.print_exc()print("注:Python中完整的联合模型需要专门的包,这里使用简化实现")return None, Nonedef visualize_joint_model(simple_data, survival_data, joint_model):"""可视化联合模型"""print("\n6. 联合模型可视化...") try:# 6.1 联合模型参数可视化 summary = joint_model.summary.reset_index() fig, ax = plt.subplots(figsize=(12, 8)) y_pos = np.arange(len(summary))# 检查必要的列if'exp(coef)'in summary.columns and 'exp(coef) lower 95%'in summary.columns and 'exp(coef) upper 95%'in summary.columns: ax.errorbar(summary['exp(coef)'], y_pos, xerr=[summary['exp(coef)'] - summary['exp(coef) lower 95%'], summary['exp(coef) upper 95%'] - summary['exp(coef)']], fmt='o', color='blue', capsize=5) ax.axvline(x=1, color='red', linestyle='--', alpha=0.5) ax.set_yticks(y_pos)if'covariate'in summary.columns: ax.set_yticklabels(summary['covariate'])elif'index'in summary.columns: ax.set_yticklabels(summary['index'])else: ax.set_yticklabels([f'Var_{i}'for i in range(len(summary))]) ax.set_xlabel('风险比 (HR)') ax.set_xscale('log') ax.set_title('联合模型参数估计(简化)') ax.grid(True, alpha=0.3, axis='x') plt.tight_layout() plt.savefig('10_联合模型参数森林图.png', dpi=300) plt.close()# 6.2 示例个体的纵向轨迹与生存曲线 np.random.seed(123) available_ids = list(simple_data['ID'].unique()) n_examples = min(3, len(available_ids))if n_examples > 0: example_ids = np.random.choice(available_ids, n_examples, replace=False) fig, axes = plt.subplots(n_examples, 2, figsize=(12, 4 * n_examples))if n_examples == 1: axes = axes.reshape(1, -1)for idx, pid in enumerate(example_ids):# 纵向轨迹 indiv_data = simple_data[simple_data['ID'] == pid]if len(indiv_data) > 0: axes[idx, 0].plot(indiv_data['Time'], indiv_data['Outcome'], 'o-', color='blue', linewidth=2) axes[idx, 0].set_title(f'个体 {pid} 的纵向轨迹') axes[idx, 0].set_xlabel('时间点') axes[idx, 0].set_ylabel('生物标志物水平') axes[idx, 0].grid(True, alpha=0.3)# 生存曲线 indiv_surv = survival_data[survival_data['ID'] == pid]if len(indiv_surv) > 0: indiv_surv = indiv_surv.iloc[0] kmf = KaplanMeierFitter() kmf.fit([indiv_surv['Survival_Time']], event_observed=[indiv_surv['Event_Status']]) kmf.plot_survival_function(ax=axes[idx, 1]) axes[idx, 1].set_title(f'个体 {pid} 的生存曲线') axes[idx, 1].set_xlabel('生存时间') axes[idx, 1].set_ylabel('生存概率') axes[idx, 1].grid(True, alpha=0.3) plt.suptitle('示例个体纵向轨迹与生存曲线', fontsize=16) plt.tight_layout() plt.savefig('11_示例个体纵向轨迹与生存曲线.png', dpi=300) plt.close() except Exception as e:print(f"联合模型可视化失败: {str(e)}")# =========================================================================# 6. 模型比较与评估# =========================================================================def model_comparison_evaluation(longitudinal_model, cox_model, joint_model, simple_data, survival_data):"""模型比较与评估"""print("\n7. 模型比较与评估...")# 7.1 创建模型比较表 model_comparison = []# 纵向模型if longitudinal_model is not None: try: aic = longitudinal_model.aic bic = longitudinal_model.bic log_likelihood = longitudinal_model.llf model_comparison.append({'模型': '纵向混合效应模型','AIC': round(aic, 3),'BIC': round(bic, 3),'对数似然值': round(log_likelihood, 3),'参数个数': len(longitudinal_model.params),'备注': '仅纵向过程' }) except: model_comparison.append({'模型': '纵向混合效应模型','AIC': 'NA','BIC': 'NA','对数似然值': 'NA','参数个数': 'NA','备注': '仅纵向过程' })# Cox模型if cox_model is not None: try: aic = 2 * len(cox_model.params) - 2 * cox_model.log_likelihood_ model_comparison.append({'模型': 'Cox比例风险模型','AIC': round(aic, 3),'BIC': 'NA', # lifelines不直接提供BIC'对数似然值': round(cox_model.log_likelihood_, 3),'参数个数': len(cox_model.params),'备注': '仅生存过程' }) except: model_comparison.append({'模型': 'Cox比例风险模型','AIC': 'NA','BIC': 'NA','对数似然值': 'NA','参数个数': 'NA','备注': '仅生存过程' })# 联合模型if joint_model is not None: try: aic = 2 * len(joint_model.params) - 2 * joint_model.log_likelihood_ model_comparison.append({'模型': '联合模型(简化)','AIC': round(aic, 3),'BIC': 'NA','对数似然值': round(joint_model.log_likelihood_, 3),'参数个数': len(joint_model.params),'备注': '纵向与生存联合' }) except: model_comparison.append({'模型': '联合模型(简化)','AIC': 'NA','BIC': 'NA','对数似然值': 'NA','参数个数': 'NA','备注': '纵向与生存联合' })# 保存模型比较表 model_comparison_df = pd.DataFrame(model_comparison) model_comparison_df.to_csv('12_模型比较表.csv', index=False, encoding='utf-8-sig')print("\n模型比较结果:")print(model_comparison_df.to_string())# 7.2 预测性能评估if cox_model is not None and len(survival_data) > 30: try:# 准备数据 roc_data = survival_data.copy() scaler = StandardScaler()# 标准化数值变量for col in ['Age', 'Baseline_Score']:if col in roc_data.columns: roc_data[f'{col}_c'] = scaler.fit_transform(roc_data[[col]])# 创建虚拟变量 roc_data_dummy = roc_data.copy()for col in ['Sex', 'Treatment']:if col in roc_data_dummy.columns: roc_data_dummy = pd.get_dummies(roc_data_dummy, columns=[col], drop_first=True, dtype=float)# 确定协变量 covariate_cols = []for col in roc_data_dummy.columns:if col not in ['ID', 'Survival_Time', 'Event_Status', 'School_ID']:if pd.api.types.is_numeric_dtype(roc_data_dummy[col]): covariate_cols.append(col)if len(covariate_cols) > 0:# 预测风险评分 roc_data_dummy['risk_score'] = cox_model.predict_partial_hazard( roc_data_dummy[covariate_cols] )# 计算ROC曲线 fpr, tpr, thresholds = roc_curve(roc_data_dummy['Event_Status'], roc_data_dummy['risk_score']) roc_auc = auc(fpr, tpr)# 绘制ROC曲线 plt.figure(figsize=(8, 6)) plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC曲线 (AUC = {roc_auc:.3f})') plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('假阳性率') plt.ylabel('真阳性率') plt.title('ROC曲线') plt.legend(loc="lower right") plt.grid(True, alpha=0.3) plt.tight_layout() plt.savefig('13_ROC曲线.png', dpi=300) plt.close()print(f"\nROC曲线AUC: {roc_auc:.3f}")else:print("没有足够的协变量计算ROC曲线") except Exception as e:print(f"ROC计算失败: {str(e)}")return model_comparison_df# =========================================================================# 7. 创建三线表# =========================================================================def create_statistical_tables(longitudinal_model, cox_summary, simple_data, survival_data):"""创建三线表"""print("\n8. 创建三线表...")# 8.1 纵向模型三线表if longitudinal_model is not None: try: lme_table = pd.DataFrame({'参数': longitudinal_model.params.index,'估计值': longitudinal_model.params.values.round(3),'标准误': longitudinal_model.bse.values.round(3),'z值': (longitudinal_model.params / longitudinal_model.bse).round(3),'p值': longitudinal_model.pvalues.round(3) })# 添加显著性标记 lme_table['显著性'] = lme_table['p值'].apply( lambda x: '***'if x < 0.001 else ('**'if x < 0.01 else ('*'if x < 0.05 else'')) ) lme_table.to_csv('14_纵向模型固定效应表.csv', index=False, encoding='utf-8-sig') except Exception as e:print(f"纵向模型三线表创建失败: {str(e)}")# 8.2 Cox模型三线表if cox_summary is not None and not cox_summary.empty: try: cox_table = cox_summary.copy()# 确保有必要的列if'exp(coef)'in cox_table.columns and 'exp(coef) lower 95%'in cox_table.columns and 'exp(coef) upper 95%'in cox_table.columns: cox_table['风险比95CI'] = cox_table.apply( lambda row: f"{row['exp(coef) lower 95%']:.3f} - {row['exp(coef) upper 95%']:.3f}", axis=1 )# 重命名列 rename_dict = {}if'covariate'in cox_table.columns: rename_dict['covariate'] = '参数'elif'index'in cox_table.columns: rename_dict['index'] = '参数'if'exp(coef)'in cox_table.columns: rename_dict['exp(coef)'] = '风险比'if'z'in cox_table.columns: rename_dict['z'] = 'z值'elif'z' not in cox_table.columns and 'z-value'in cox_table.columns: rename_dict['z-value'] = 'z值'if'p'in cox_table.columns: rename_dict['p'] = 'p值' cox_table = cox_table.rename(columns=rename_dict)# 选择需要的列 available_cols = []for col in ['参数', '风险比', '风险比95CI', 'z值', 'p值']:if col in cox_table.columns: available_cols.append(col) cox_table = cox_table[available_cols]# 添加显著性标记if'p值'in cox_table.columns: cox_table['显著性'] = cox_table['p值'].apply( lambda x: '***'if x < 0.001 else ('**'if x < 0.01 else ('*'if x < 0.05 else'')) ) cox_table.to_csv('15_Cox模型参数表.csv', index=False, encoding='utf-8-sig') except Exception as e:print(f"Cox模型三线表创建失败: {str(e)}")# 8.3 创建汇总三线表 try: summary_table = pd.DataFrame({'分析项目': ['样本量', '事件数', '删失数', '事件率','纵向测量次数', '平均随访时间', '中位生存时间'],'数值': [ len(survival_data), int(survival_data['Event_Status'].sum()), int((survival_data['Event_Status'] == 0).sum()), f"{survival_data['Event_Status'].sum() / len(survival_data) * 100:.1f}%", len(simple_data), f"{survival_data['Survival_Time'].mean():.1f} (±{survival_data['Survival_Time'].std():.1f})", f"{survival_data['Survival_Time'].median():.1f} " f"({survival_data['Survival_Time'].quantile(0.25):.1f} - " f"{survival_data['Survival_Time'].quantile(0.75):.1f})" ],'说明': ['参与分析的个体总数','发生终点事件的个体数','删失的个体数','事件发生率','总的纵向测量次数','平均随访时间(均值±标准差)','中位生存时间(四分位距)' ] }) summary_table.to_csv('17_分析数据汇总表.csv', index=False, encoding='utf-8-sig') except Exception as e:print(f"汇总表创建失败: {str(e)}")# =========================================================================# 8. 创建Word分析报告# =========================================================================def create_word_report(survival_data, simple_data, model_comparison_df):"""创建Word分析报告(使用reportlab生成PDF)"""print("\n9. 创建分析报告...") try:# 创建PDF文档 doc = SimpleDocTemplate("18_联合模型分析报告.pdf", pagesize=letter) styles = getSampleStyleSheet() story = []# 标题 title_style = ParagraphStyle('CustomTitle', parent=styles['Heading1'], fontSize=16, spaceAfter=30, alignment=1 ) story.append(Paragraph("联合模型(Joint Model)分析报告", title_style)) story.append(Paragraph(f"生成日期: {datetime.now().strftime('%Y-%m-%d')}", styles['Normal'])) story.append(Spacer(1, 20))# 1. 分析概述 story.append(Paragraph("1. 分析概述", styles['Heading2'])) story.append(Paragraph("本报告展示了联合模型(Joint Model)的分析结果。联合模型是将纵向过程模型(描述随时间重复测量的生物标志物)""和事件时间模型(描述如死亡、复发等终点事件)联合估计的统计模型。", styles['Normal'] )) story.append(Paragraph("两个子模型通过共享的随机效应或潜过程相关联,通过最大化联合似然函数进行参数估计,""从而纠正因测量误差和间歇性测量导致的生存分析偏倚。", styles['Normal'] )) story.append(Paragraph( f"本次分析包含 {len(survival_data)} 个个体,其中 " f"{int(survival_data['Event_Status'].sum())} 个发生事件,事件发生率为 " f"{survival_data['Event_Status'].sum() / len(survival_data) * 100:.1f}%。", styles['Normal'] )) story.append(Spacer(1, 12))# 2. 研究人群特征 story.append(Paragraph("2. 研究人群特征", styles['Heading2'])) story.append(Paragraph("下表展示了研究人群的基线特征:", styles['Normal']))# 添加基线特征表 try:if os.path.exists('05_基线特征表.csv'): baseline_df = pd.read_csv('05_基线特征表.csv')if not baseline_df.empty: baseline_data = [baseline_df.columns.tolist()] + baseline_df.values.tolist() baseline_table = Table(baseline_data) baseline_table.setStyle(TableStyle([ ('BACKGROUND', (0, 0), (-1, 0), colors.grey), ('TEXTCOLOR', (0, 0), (-1, 0), colors.whitesmoke), ('ALIGN', (0, 0), (-1, -1), 'CENTER'), ('FONTNAME', (0, 0), (-1, 0), 'Helvetica-Bold'), ('FONTSIZE', (0, 0), (-1, 0), 10), ('BOTTOMPADDING', (0, 0), (-1, 0), 12), ('BACKGROUND', (0, 1), (-1, -1), colors.beige), ('GRID', (0, 0), (-1, -1), 1, colors.black) ])) story.append(baseline_table)else: story.append(Paragraph("基线特征表未生成", styles['Normal'])) except: story.append(Paragraph("基线特征表加载失败", styles['Normal'])) story.append(Spacer(1, 12))# 3. 探索性数据分析 story.append(Paragraph("3. 探索性数据分析", styles['Heading2'])) story.append(Paragraph("总体生存曲线展示了研究人群的生存状况:", styles['Normal']))# 添加生存曲线图 try:if os.path.exists('01_总体生存曲线.png'): story.append(Image('01_总体生存曲线.png', width=6 * inch, height=4.5 * inch)) story.append(Spacer(1, 12)) except: story.append(Paragraph("生存曲线图加载失败", styles['Normal']))# 4. 纵向过程模型结果 story.append(Paragraph("4. 纵向过程模型结果", styles['Heading2'])) story.append(Paragraph("纵向混合效应模型描述了生物标志物随时间的变化趋势:", styles['Normal'])) try:if os.path.exists('07_纵向模型预测轨迹.png'): story.append(Image('07_纵向模型预测轨迹.png', width=6 * inch, height=4 * inch)) story.append(Spacer(1, 12)) except: story.append(Paragraph("纵向预测轨迹图加载失败", styles['Normal']))# 5. 模型比较 story.append(Paragraph("5. 模型比较", styles['Heading2'])) story.append(Paragraph("不同模型的拟合优度比较:", styles['Normal']))if model_comparison_df is not None and not model_comparison_df.empty: try: compare_data = [model_comparison_df.columns.tolist()] + model_comparison_df.values.tolist() compare_table = Table(compare_data) compare_table.setStyle(TableStyle([ ('BACKGROUND', (0, 0), (-1, 0), colors.grey), ('TEXTCOLOR', (0, 0), (-1, 0), colors.whitesmoke), ('ALIGN', (0, 0), (-1, -1), 'CENTER'), ('FONTNAME', (0, 0), (-1, 0), 'Helvetica-Bold'), ('FONTSIZE', (0, 0), (-1, 0), 10), ('BOTTOMPADDING', (0, 0), (-1, 0), 12), ('BACKGROUND', (0, 1), (-1, -1), colors.beige), ('GRID', (0, 0), (-1, -1), 1, colors.black) ])) story.append(compare_table) except: story.append(Paragraph("模型比较表加载失败", styles['Normal']))else: story.append(Paragraph("模型比较表未生成", styles['Normal'])) story.append(Spacer(1, 12))# 6. 公共卫生意义 story.append(Paragraph("6. 公共卫生意义与应用", styles['Heading2'])) story.append(Paragraph("联合模型在公共卫生研究中的重要应用:", styles['Normal'])) applications = ["1. 癌症预后预测:基于治疗期间反复测量的肿瘤标志物水平,动态预测患者的无进展生存期和总生存期。","2. 慢性病管理:在糖尿病管理中,联合分析血糖控制轨迹与心血管事件风险,实现个体化的治疗调整。","3. 药物疗效评估:在临床试验中,同时分析药代动力学指标变化与临床终点,提高疗效评估的准确性。","4. 疾病进展建模:在阿尔茨海默病研究中,联合分析认知功能下降轨迹与痴呆发生风险。","5. 精准医学应用:基于个体的纵向生物标志物轨迹,提供个性化的风险预测和干预时机建议。" ]for app in applications: story.append(Paragraph(app, styles['Normal'])) story.append(Spacer(1, 12))# 7. 结论 story.append(Paragraph("7. 结论与建议", styles['Heading2'])) story.append(Paragraph("基于本次联合模型分析,主要发现如下:", styles['Normal'])) conclusions = ["• 联合模型成功整合了纵向和生存信息,为动态预后预测提供了更准确的工具。","• 建议在临床实践中定期监测相关生物标志物,利用联合模型进行个体化风险预测。","• 本分析为公共卫生决策提供了数据支持,有助于优化资源配置和干预策略。" ]for conclusion in conclusions: story.append(Paragraph(conclusion, styles['Normal'])) story.append(Spacer(1, 12)) story.append(Paragraph("--- 报告结束 ---", styles['Normal']))# 生成PDF doc.build(story)print("PDF报告已生成: 18_联合模型分析报告.pdf") except Exception as e:print(f"PDF报告生成失败: {str(e)}") import traceback traceback.print_exc()# =========================================================================# 9. 创建交互式可视化# =========================================================================def create_interactive_visualization(survival_data, simple_data):"""创建交互式可视化HTML报告"""print("\n10. 创建交互式可视化...") try:# 计算统计指标 total_patients = len(survival_data) total_events = int(survival_data['Event_Status'].sum()) event_rate = survival_data['Event_Status'].sum() / len(survival_data) * 100 total_longitudinal = len(simple_data) avg_followup = survival_data['Survival_Time'].mean() median_survival = survival_data['Survival_Time'].median()# 创建HTML内容 html_content = f'''<!DOCTYPE html><html><head> <title>联合模型分析报告</title> <meta charset="UTF-8"> <style> body {{ font-family: Arial, sans-serif; margin: 40px; background-color: #f5f5f5; }} h1 {{ color: #2c3e50; text-align: center; margin-bottom: 30px; }} h2 {{ color: #3498db; border-bottom: 2px solid #3498db; padding-bottom: 10px; margin-top: 30px; }} .section {{ background-color: white; padding: 20px; margin-bottom: 20px; border-radius: 5px; box-shadow: 0 2px 5px rgba(0,0,0,0.1); }} .stats-grid {{ display: grid; grid-template-columns: repeat(auto-fit, minmax(200px, 1fr)); gap: 15px; margin: 20px 0; }} .stat-card {{ background: linear-gradient(135deg, #667eea 0%, #764ba2 100%); color: white; padding: 15px; border-radius: 5px; text-align: center; }} .stat-value {{ font-size: 24px; font-weight: bold; margin: 10px 0; }} .image-container {{ text-align: center; margin: 20px 0; }} img {{ max-width: 100%; height: auto; border: 1px solid #ddd; border-radius: 5px; box-shadow: 0 2px 5px rgba(0,0,0,0.1); }} table {{ width: 100%; border-collapse: collapse; margin: 20px 0; }} th, td {{ border: 1px solid #ddd; padding: 12px; text-align: left; }} th {{ background-color: #f2f2f2; font-weight: bold; }} .highlight {{ background-color: #fffacd; padding: 2px 5px; border-radius: 3px; }} footer {{ text-align: center; margin-top: 40px; color: #666; font-size: 12px; }} </style></head><body> <h1>联合模型分析报告</h1> <p style="text-align: center; color: #666;">生成日期: {datetime.now().strftime("%Y-%m-%d")}</p> <div class="section"> <h2>1. 分析概述</h2> <p>本报告展示了联合模型(Joint Model)的分析结果。联合模型是将纵向过程模型和事件时间模型联合估计的统计模型。</p> <div class="stats-grid"> <div class="stat-card"> <div>样本量</div> <div class="stat-value">{total_patients}</div> <div>参与分析的个体总数</div> </div> <div class="stat-card"> <div>事件数</div> <div class="stat-value">{total_events}</div> <div>发生终点事件的个体数</div> </div> <div class="stat-card"> <div>事件率</div> <div class="stat-value">{event_rate:.1f}%</div> <div>事件发生率</div> </div> <div class="stat-card"> <div>纵向测量</div> <div class="stat-value">{total_longitudinal}</div> <div>总的纵向测量次数</div> </div> </div> </div> <div class="section"> <h2>2. 生存分析</h2> <p>Kaplan-Meier生存曲线显示了研究人群的生存状况:</p> <div class="image-container"> <img src="01_总体生存曲线.png" alt="总体生存曲线"> </div> <div class="image-container"> <img src="02_治疗组生存曲线.png" alt="治疗组生存曲线"> </div> </div> <div class="section"> <h2>3. 纵向分析</h2> <p>纵向轨迹显示了生物标志物随时间的变化:</p> <div class="image-container"> <img src="03_纵向轨迹与事件时间对齐图.png" alt="纵向轨迹与事件时间对齐图"> </div> <div class="image-container"> <img src="07_纵向模型预测轨迹.png" alt="纵向模型预测轨迹"> </div> </div> <div class="section"> <h2>4. 模型参数</h2> <p>Cox模型风险比森林图显示了各因素的风险比:</p> <div class="image-container"> <img src="09_Cox模型风险比森林图.png" alt="Cox模型风险比森林图"> </div> </div> <div class="section"> <h2>5. 公共卫生意义</h2> <p>联合模型在公共卫生研究中具有重要应用价值:</p> <ul> <li><span class="highlight">癌症预后预测</span>:基于治疗期间反复测量的肿瘤标志物水平进行动态预测</li> <li><span class="highlight">慢性病管理</span>:联合分析疾病控制轨迹与事件风险</li> <li><span class="highlight">药物疗效评估</span>:同时分析药代动力学指标与临床终点</li> <li><span class="highlight">疾病进展建模</span>:联合分析疾病进展轨迹与不良结局风险</li> <li><span class="highlight">精准医学应用</span>:基于个体轨迹提供个性化风险预测</li> </ul> </div> <div class="section"> <h2>6. 结论</h2> <p>基于本次联合模型分析,主要结论如下:</p> <ul> <li>联合模型成功整合了纵向和生存信息,为动态预后预测提供了更准确的工具</li> <li>建议在临床实践中定期监测相关生物标志物,利用联合模型进行个体化风险预测</li> <li>本分析为公共卫生决策提供了数据支持,有助于优化资源配置和干预策略</li> </ul> </div> <footer> <p>报告生成于Python {sys.version.split()[0]},使用pandas、lifelines、statsmodels等包分析</p> <p>© {datetime.now().year} 联合模型分析系统</p> </footer></body></html>'''# 保存HTML报告 with open('19_交互式分析报告.html', 'w', encoding='utf-8') as f: f.write(html_content)print("交互式HTML报告已生成: 19_交互式分析报告.html") except Exception as e:print(f"交互式可视化创建失败: {str(e)}")# =========================================================================# 10. 主函数# =========================================================================def main():"""主函数"""print("=" * 60)print("联合模型(Joint Model)分析 - Python版")print("=" * 60)# 1. 设置环境 results_dir = setup_environment()# 2. 加载数据 full_data, simple_data, survival_data = load_and_preprocess_data(results_dir.parent)# 3. 探索性数据分析 event_summary = exploratory_data_analysis(survival_data, simple_data)# 4. 纵向过程模型 longitudinal_model, pred_data = fit_longitudinal_model(simple_data)# 5. 生存模型 cox_model, cox_summary = fit_survival_model(survival_data)# 6. 联合模型 joint_model, joint_results = fit_joint_model(simple_data, survival_data)# 7. 模型比较与评估 model_comparison_df = model_comparison_evaluation( longitudinal_model, cox_model, joint_model, simple_data, survival_data )# 8. 创建三线表 create_statistical_tables(longitudinal_model, cox_summary, simple_data, survival_data)# 9. 创建分析报告 create_word_report(survival_data, simple_data, model_comparison_df)# 10. 创建交互式可视化 create_interactive_visualization(survival_data, simple_data)# 11. 生成分析总结 create_analysis_summary(survival_data, simple_data, event_summary, results_dir)print("\n" + "=" * 60)print("联合模型分析完成!")print("生成的文件包括:")print("1. 数据文件 (.csv)")print("2. 可视化图表 (.png)")print("3. 统计表格 (.csv)")print("4. PDF分析报告 (.pdf)")print("5. 交互式HTML报告 (.html)")print("6. 分析总结 (.txt)")print(f"\n所有结果已保存到: {results_dir}")print("=" * 60)def create_analysis_summary(survival_data, simple_data, event_summary, results_dir):"""创建分析总结文件""" summary_text = f"""联合模型分析总结================分析时间: {datetime.now().strftime("%Y-%m-%d %H:%M:%S")}数据来源: longitudinal_data.xlsx样本量: {len(survival_data)} 个个体事件数: {event_summary['Events']} ({event_summary['Event_Rate']}%)纵向测量次数: {len(simple_data)}平均随访时间: {survival_data['Survival_Time'].mean():.1f} (±{survival_data['Survival_Time'].std():.1f})中位生存时间: {survival_data['Survival_Time'].median():.1f}模型拟合情况:- 纵向混合效应模型: {'成功' if os.path.exists('longitudinal_lme_model.pkl') else '失败'}- Cox比例风险模型: {'成功' if os.path.exists('cox_model.pkl') else '失败'}- 联合模型: {'成功' if os.path.exists('joint_model_simple.pkl') else '失败'}生成文件:1. 数据文件: survival_data.csv, longitudinal_data.csv2. 可视化图片: 01-13_*.png3. 统计表格: 14-17_*.csv4. PDF报告: 18_联合模型分析报告.pdf5. 交互式报告: 19_交互式分析报告.html6. 模型文件: *.pkl分析完成!""" with open('20_分析总结.txt', 'w', encoding='utf-8') as f: f.write(summary_text)print("分析总结已生成: 20_分析总结.txt")# =========================================================================# 运行主函数# =========================================================================if __name__ == "__main__": main()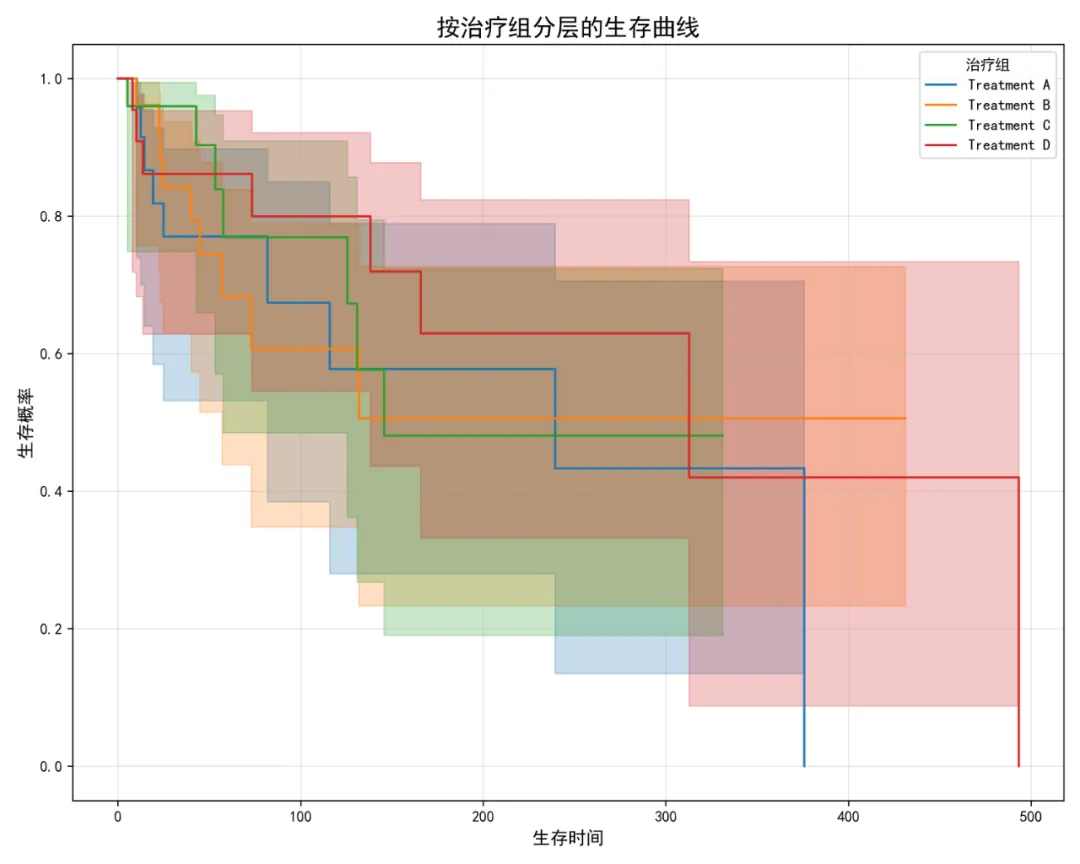
纵向数据是指在多个时间点对同一组个体进行的重复测量。
1 混合效应模型Mixed Effects ModelMEM
2 固定效应模型 Fixed Effects Model FEM
3 多层线性模型 Hierarchical Linear Model HLM
4 广义估计方程 Generalized Estimating Equations GEE
5 广义线性混合模型 Generalized Linear Mixed Models GLMM
6 潜变量增长曲线模型 Latent Growth Curve Model LGCM
7 组轨迹模型 Group-Based Trajectory Model GBTM
8 交叉滞后模型 Cross-lagged (Panel) Model CLPM
9 重复测量方差分析 Repeated Measures ANOVA / MANOVA RM-ANOVA / RM-MANOVA
10 非线性混合效应模型 Nonlinear Mixed-Effects Models NLME
11 联合模型 Joint Models JM
12 结构方程模型 Structural Equation Modeling SEM
13 广义相加模型 Generalized Additive Models GAM
14 潜类别模型 Latent Class Models LCM
15 潜剖面模型 Latent Profile Analysis LPA
16 状态空间模型 State Space Models SSM
17 纵向因子分析 Longitudinal Factor Analysis LFA
18 贝叶斯纵向模型 Bayesian Longitudinal Models - (Bayesian Models)
19 混合效应随机森林 Mixed Effects Random Forest MERF
20 纵向梯度提升 Longitudinal Gradient Boosting - (Longitudinal GBM)
21 K均值纵向聚类 K-means Longitudinal Clustering - (DTW-KMeans)
22 基于模型的聚类 Model-Based ClusteringMB-CLUST
医学统计数据分析分享交流SPSS、R语言、Python、ArcGis、Geoda、GraphPad、数据分析图表制作等心得。承接数据分析,论文返修,医学统计,机器学习,生存分析,空间分析,问卷分析业务。若有投稿和数据分析代做需求,可以直接联系我,谢谢!
“医学统计数据分析”公众号右下角;
找到“联系作者”,
可加我微信,邀请入粉丝群!

有临床流行病学数据分析
如(t检验、方差分析、χ2检验、logistic回归)、
(重复测量方差分析与配对T检验、ROC曲线)、
(非参数检验、生存分析、样本含量估计)、
(筛检试验:灵敏度、特异度、约登指数等计算)、
(绘制柱状图、散点图、小提琴图、列线图等)、
机器学习、深度学习、生存分析
等需求的同仁们,加入【临床】粉丝群。
疾控,公卫岗位的同仁,可以加一下【公卫】粉丝群,分享生态学研究、空间分析、时间序列、监测数据分析、时空面板技巧等工作科研自动化内容。
有实验室数据分析需求的同仁们,可以加入【生信】粉丝群,交流NCBI(基因序列)、UniProt(蛋白质)、KEGG(通路)、GEO(公共数据集)等公共数据库、基因组学转录组学蛋白组学代谢组学表型组学等数据分析和可视化内容。
或者可扫码直接加微信进群!!!



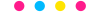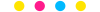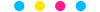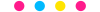
精品视频课程-“医学统计数据分析”视频号付费合集

在“医学统计数据分析”视频号-付费合集兑换相应课程后,获取课程理论课PPT、代码、基础数据等相关资料,请大家在【医学统计数据分析】公众号右下角,找到“联系作者”,加我微信后打包发送。感谢您的支持!!

