import pyttsx3def text_to_audio(text, output_file="output"): # 初始化语音引擎 engine = pyttsx3.init() # ========== 可调节参数 ========== engine.setProperty('rate', 180) # 语速,越小越慢 engine.setProperty('volume', 0.9) # 音量 0~1 # ================================ final_file = f"{output_file}.mp3" #查看语音 voice = engine.getProperty("voices") for i in voice: print(i) #选择一个可用的声音,voices[0].id or voices[1].id根据你的输出决定 #engine.setProperty('voice', voices[0].id) try: engine.save_to_file(text, final_file) engine.runAndWait() print(f"音频生成成功:{final_file}") except Exception as e: print(e) if __name__ == "__main__": #print("=== 文字转朗读音频mp3格式===") text = "你好啊,我是一个机器人,我会说话,你来听听?"#input("请输入要朗读的文字:") text_to_audio(text, output_file=text)
voice = engine.getProperty("voices")for i in voice: print(i)
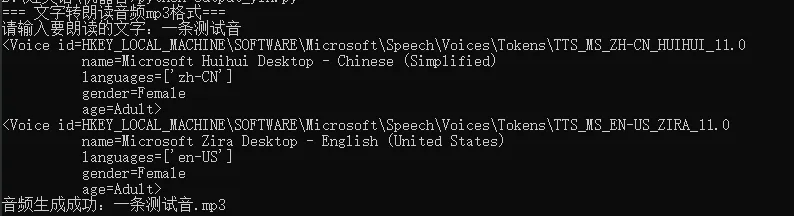
终端输出的voice有两个,一个女音(中文),男音(英文)选择一个可用的声音,voices[0].id or voices[1].id
根据你的输出决定
engine.setProperty('voice', voices[0].id)
print("=== 文字转朗读音频mp3格式===")text = input("请输入要朗读的文字:") text_to_audio(text, output_file=text)

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
