目录:
1、什么是正则表达式
2、元字符之通配符与字符集
(1)通配符"."
(2)字符集[]
3、元字符之重复符
(1)重复元字符:{}
(2)重复元字符:*
(3)重复元字符:+
(4)重复元字符:?
Python正则表达式是用于匹配和处理文本的强大利器,它通过特定模式在字符串中搜索、匹配和替换内容。
在Python中,正则表达式由re模块提供支持,包含search()、match()、findall()等方法,可用于数据验证、文本提取、格式转换等场景。
其核心语法包括字符匹配、分组捕获、量词限定等,是处理复杂字符串操作的必备工具。
通配符、万能通配符或通配元字符,匹配1个除了换行符\n以外任何。
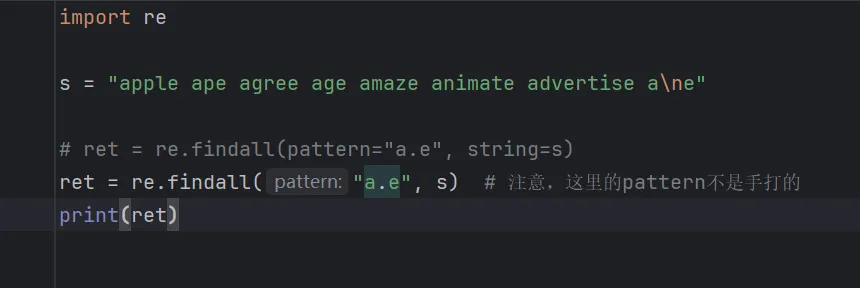
import res = "apple ape agree age amaze animate advertise a\ne"# ret = re.findall(pattern="a.e", string=s)ret = re.findall("a.e", s) # 注意,这里的pattern不是手打的print(ret)
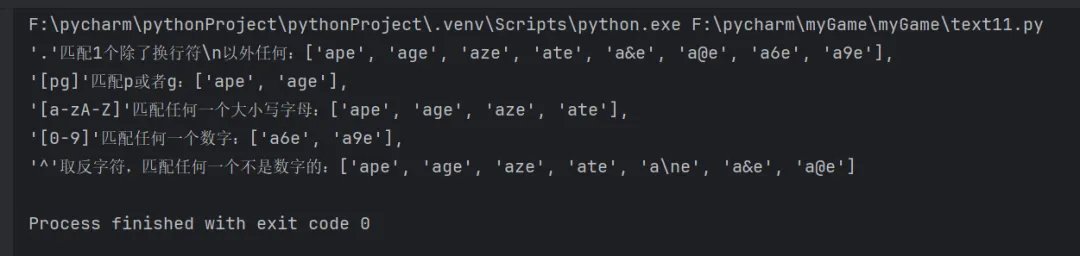
import res = "apple ape agree age amaze animate advertise a\ne a&e a@e a6e a9e"ret1 = re.findall("a.e", s)ret2 = re.findall("a[pg]e", s)ret3 = re.findall("a[a-zA-Z]e", s)ret4 = re.findall("a[0-9]e", s)ret5 = re.findall("a[^0-9]e", s)print(f"'.'匹配1个除了换行符\\n以外任何:{ret1},\n'[pg]'匹配p或者g:{ret2},\n'[a-zA-Z]'匹配任何一个大小写字母:{ret3},\n'[0-9]'匹配任何一个数字:{ret4},\n'^'取反字符,匹配任何一个不是数字的:{ret5}")
{n,,m}:数量范围贪婪符,指定左边原子的数量范围,有{n},{n,},{,m},{n,m}四种写法,其中n与m必须是非负整数。
关键点:重复默认按贪婪匹配,可以通过在重复符右边加一个?取消贪婪匹配,按照非贪婪模式匹配。
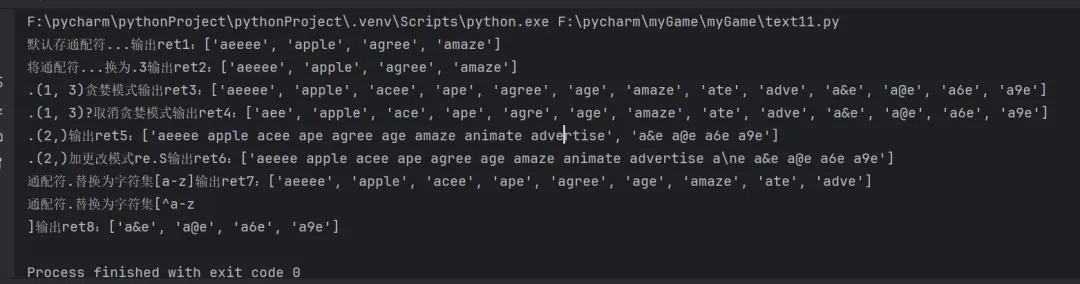
import re# {}:指定左边原子的可以重复的数量范围s = "aeeee apple acee ape agree age amaze animate advertise a\ne a&e a@e a6e a9e"ret1 = re.findall("a...e", s)ret2 = re.findall("a.{3}e", s)# 默认贪婪匹配:按着最大匹配数进行匹配ret3 = re.findall("a.{1,3}e", s) # 优先匹配3个重复# 在重复符后面就跟着一个?,取消贪婪匹配按着最小匹配数进行优先匹配ret4 = re.findall("a.{1,3}?e", s) # 优先匹配1个重复# {2,}:2-无穷大ret5 = re.findall("a.{2,}e", s)# 更改模式re.S,可以匹配任意符号ret6 = re.findall("a.{2,}e", s, re.S)# 将通配符替换为字符集ret7 = re.findall("a[a-z]{1,3}e", s)ret8 = re.findall("a[^a-z\n]{1,3}e", s) # [^a-z\n]表示不匹配a-z字母以及换行符\nprint(f"默认存通配符...输出ret1:{ret1}")print(f"将通配符...换为.{3}输出ret2:{ret2}")print(f".{1,3}贪婪模式输出ret3:{ret3}")print(f".{1,3}?取消贪婪模式输出ret4:{ret4}")print(f".{2,}输出ret5:{ret5}")print(f".{2,}加更改模式re.S输出ret6:{ret6}")print(f"通配符.替换为字符集[a-z]输出ret7:{ret7}")print(f"通配符.替换为字符集[^a-z\n]输出ret8:{ret8}")
import re# *:指定左边原子出现0次或多次,等同{0,}s = "aeeee apple acee ape agree age amaze animate advertise a\ne a&e a@e a6e a9e"ret1 = re.findall("a.{0,}e", s)ret2 = re.findall("a.*e", s) # 默认贪婪匹配ret3 = re.findall("a.*?e", s) # 取消贪婪匹配按着最小匹配数进行优先匹配print(f"{0,}输出ret1:{ret1}")print(f"*输出ret2:{ret2}")print(f"*?输出ret3:{ret3}")
import re# +:指定左边原子出现1次或多次,等同{1,}s = "aeeee apple acee ape agree age amaze animate advertise a\ne a&e a@e a6e a9e"ret1 = re.findall("a.{1,}e", s)ret2 = re.findall("a.+e", s) # 默认贪婪匹配ret3 = re.findall("a.+?e", s) # 取消贪婪匹配按着最小匹配数进行优先匹配print(f"{0,}输出ret1:{ret1}")print(f".+输出ret2:{ret2}")print(f".+?输出ret3:{ret3}")
import re# ?:指定左边原子出现1次或多次,等同{0,1}s = "https://www.baidu.com/, https://www.ooaac.com/, https://www.youdao.com/"ret1 = re.findall("https?://www.*?.com", s) # ? 贪婪匹配{0,1}# ret2 = re.findall("https??://www.*?.com", s) # ??取消贪婪匹配{0,1}print(f"?输出ret1:{ret1}")# print(f"??输出ret2:{ret2}")