相关性分析(基于Python)5—— 皮尔逊相关系数的定义与标准化
- 2026-07-03 14:10:31
1总体相关系数 vs. 样本相关系数
在统计推断的框架下,通常假设观测到的数据(样本)是从一个更大、无法完全观测的总体中随机抽取的。我们最终目的是通过样本的性质去推断总体的性质。
总体皮尔逊相关系数()
总体的皮尔逊相关系数,通常用希腊字母 (rho) 表示,是描述总体中两个随机变量 和 之间真实线性关系强度的参数。它是一个理论值,在绝大多数现实情况下是未知的。
它的定义是基于随机变量的数学期望、方差和协方差这些理论概念:
其中, 和 是总体的均值, 和 是总体的标准差。
样本皮尔逊相关系数()
样本的皮尔逊相关系数,通常用英文字母 表示,是利用有限的 个样本数据点 计算出来的统计量(Statistic)。
它的定义是基于样本的均值、方差和协方差这些可计算的量:
注意到分子分母中的无偏估计因子 可以相互抵消,因此样本相关系数的计算公式可以简化为:
这里的 和 是样本均值。
和 的关系是统计推断中“样本”与“总体”关系的经典体现,具体而言,如果我们从同一个总体中抽取另一组样本,计算出的 值很可能会发生变化,故 是一个随机变量,具有概率分布,且这样的分布被称为抽样分布(Sampling Distribution);同时 是未知参数 的一个点估计(Point Estimate),我们希望这个估计具有无偏(Unbiased)和/或一致(Consistent)的特性。
注意:在统计推论中,样本相关系数 是对总体相关系数 的一个有偏估计(Biased Estimator),且在大多数情况下,样本相关系数的绝对值 会系统性地略高于总体相关系数的绝对值 。不过,当样本量 趋向于无穷大时, 会收敛于 ,因此它是一个一致估计。
为了直观地感受样本相关系数 的随机性,我们将设定一个固定的总体相关系数 ,然后从这个总体中反复、多次地抽取小样本,并计算每一次的样本相关系数 。最后,我们将所有计算出的 值绘制成一个直方图,以展示 的抽样分布。
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 1. 定义总体的真实参数# 假设我们研究的总体中,两个变量的真实相关系数 rho = 0.6population_rho = 0.6population_mean = [0, 0]population_cov = [[1.0, population_rho], [population_rho, 1.0]]# 2. 设定抽样实验的参数sample_size = 30# 每次抽取的样本量num_experiments = 5000# 重复实验的次数# 3. 进行模拟抽样# 创建一个数组来存储每次实验计算出的样本相关系数 rsample_correlations_r = np.zeros(num_experiments)for i in range(num_experiments):# 从总体中抽取一个样本 sample = np.random.multivariate_normal(population_mean, population_cov, size=sample_size) x_sample = sample[:, 0] y_sample = sample[:, 1]# 计算并存储样本相关系数 r# np.corrcoef 返回一个相关矩阵,我们需要的是非对角线元素 r = np.corrcoef(x_sample, y_sample)[0, 1] sample_correlations_r[i] = r# 4. 可视化 r 的抽样分布fig, ax = plt.subplots(figsize=(10, 6))# 绘制直方图ax.hist(sample_correlations_r, bins=40, density=True, alpha=0.7, color='#377eb8', edgecolor='white', label=f'样本相关系数 r 的抽样分布\n(基于 {num_experiments} 次实验)')# 绘制理论上的正态分布拟合曲线(这是一个近似)mean_r = np.mean(sample_correlations_r)std_r = np.std(sample_correlations_r)x_grid = np.linspace(np.min(sample_correlations_r), np.max(sample_correlations_r), 200)pdf = stats.norm.pdf(x_grid, loc=mean_r, scale=std_r)ax.plot(x_grid, pdf, 'k--', linewidth=2, label='正态分布近似')# 添加真实的总体 rho 和样本 r 的均值作为参考线ax.axvline(population_rho, color='red', linestyle='-', linewidth=2, label=f'真实的总体相关系数 $\\rho$ = {population_rho}')ax.axvline(mean_r, color='black', linestyle='--', linewidth=2, label=f'样本相关系数的均值 E[r] = {mean_r:.3f}')ax.set_title(f'样本相关系数 $r$ 的抽样分布 (当总体 $\\rho={population_rho}$, 样本量 $n={sample_size}$)', fontsize=15)ax.set_xlabel('样本相关系数 $r$ 的值', fontsize=12)ax.set_ylabel('概率密度', fontsize=12)ax.legend()ax.grid(True, linestyle=':', alpha=0.6)plt.tight_layout()plt.show()执行结果如下:
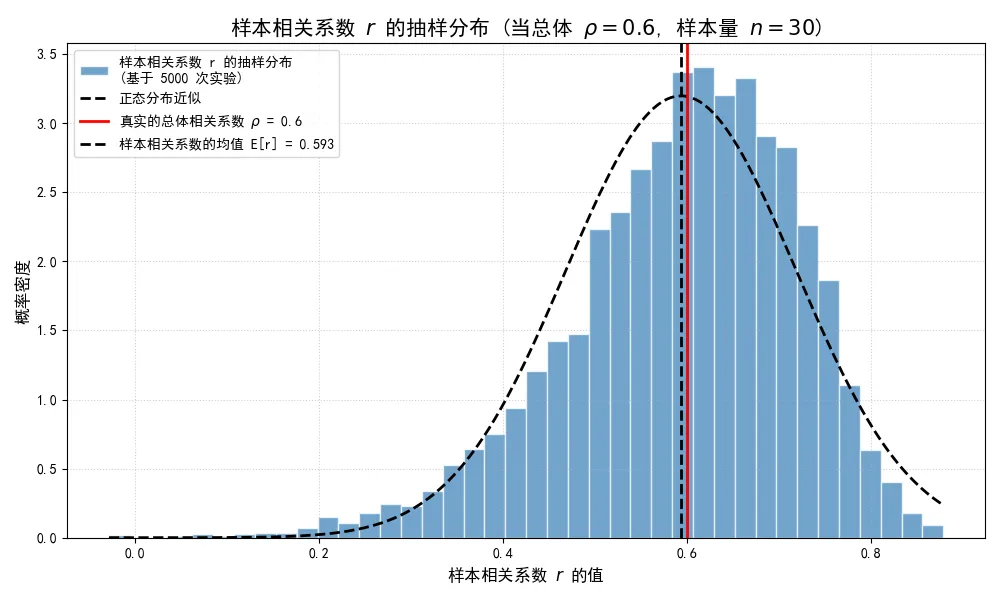
由图中可以看出,尽管每一次抽样都来自同一个总体(),但我们得到的样本相关系数 却分布在一个相当宽的范围内,从0.2到0.8甚至更高。这直观地证明了 是一个随机变量;且这些 值大致呈现出一种钟形分布,但仔细观察会发现它并不完全对称,而是稍微向左偏斜;黑色的虚线(样本均值)非常接近红色的实线(总体真值),但通常会略小于它,这展示了 作为估计量的轻微偏差。
这个模拟实验揭示了一个核心的统计问题:当我们从数据中计算出一个样本相关系数,比如 ,我们如何确定这个值在多大程度上反映了真实的 ,又在多大程度上仅仅是由于抽样运气好造成的?
要回答这个问题,我们必须深入研究 的抽样分布的数学性质。
2标准化 I:通过 Z-Score 进行数值标准化
在深入探讨 的复杂抽样分布之前,我们先回顾一下皮尔逊相关系数最基础的标准化过程,Z-Score标准化是一种将任意分布的原始数据转换成均值为0、标准差为1的标准分布的过程。对于每一个数据点 ,其Z-Score为:
其中 是样本均值, 是样本标准差 。
现在,我们把样本相关系数的简化公式写出来:
我们可以对这个公式进行一个巧妙的代数变形,将标准差的定义代入其中:
上述公式表明:样本皮尔逊相关系数,是两个变量经过Z-Score标准化后,其对应数据点乘积的平均值(使用 作为分母)。
这个定义提供了一种非常稳健的计算方法(先对数据进行标准化,可以避免大数值导致的浮点数精度问题),同时如果一个样本在 上是一个离群的高值( 是一个大的正数),它在 上也倾向于是离群的高值( 也是大的正数),那么它们的乘积 就会是一个很大的正数,对总和做出巨大贡献,从而推高相关系数。
我们通过一段代码来可视化Z-Score标准化后的数据是如何决定相关系数的。
import numpy as npimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 生成一些示例数据np.random.seed(1)x_raw = np.random.normal(50, 10, 100)y_raw = 0.7 * x_raw + np.random.normal(0, 5, 100)# 方法1:使用传统公式计算 r# 为了演示,我们手动计算x_mean = np.mean(x_raw)y_mean = np.mean(y_raw)numerator = np.sum((x_raw - x_mean) * (y_raw - y_mean))denominator = np.sqrt(np.sum((x_raw - x_mean)**2) * np.sum((y_raw - y_mean)**2))r_formula = numerator / denominator# 方法2:通过 Z-Score 标准化计算 rx_std = np.std(x_raw, ddof=1) # ddof=1 使用 n-1 作为分母y_std = np.std(y_raw, ddof=1)z_x = (x_raw - x_mean) / x_stdz_y = (y_raw - y_mean) / y_stdn = len(x_raw)r_zscore = np.sum(z_x * z_y) / (n - 1)# 创建图表fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))# 图1:原始数据散点图ax1.scatter(x_raw, y_raw, alpha=0.7)ax1.set_title(f'原始数据散点图\n公式计算 r = {r_formula:.4f}', fontsize=14)ax1.set_xlabel('原始变量 X')ax1.set_ylabel('原始变量 Y')ax1.grid(True, linestyle=':')# 图2:Z-Score 标准化后的数据散ax2.scatter(z_x, z_y, alpha=0.7, color='orange')ax2.axhline(0, color='black', lw=1)ax2.axvline(0, color='black', lw=1)# 用颜色区分四个象限的贡献positive_contribution = z_x * z_y > 0negative_contribution = z_x * z_y <= 0ax2.scatter(z_x[positive_contribution], z_y[positive_contribution], color='#d73027', label='正贡献点 ($z_x z_y > 0$)')ax2.scatter(z_x[negative_contribution], z_y[negative_contribution], color='#4575b4', label='负贡献点 ($z_x z_y < 0$)')ax2.set_title(r'$Z$-$Score$标准化后' + f'\n$r = \\frac{{1}}{{{n-1}}}\\sum z_x z_y = {r_zscore:.4f}$', fontsize=14)ax2.set_xlabel('标准化的 X ($z_x$)')ax2.set_ylabel('标准化的 Y ($z_y$)')ax2.set_aspect('equal')ax2.grid(True, linestyle=':')ax2.legend()plt.tight_layout()plt.show()print(f"两种方法计算的相关系数是否一致: {np.isclose(r_formula, r_zscore)}")执行结果如下:
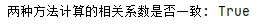
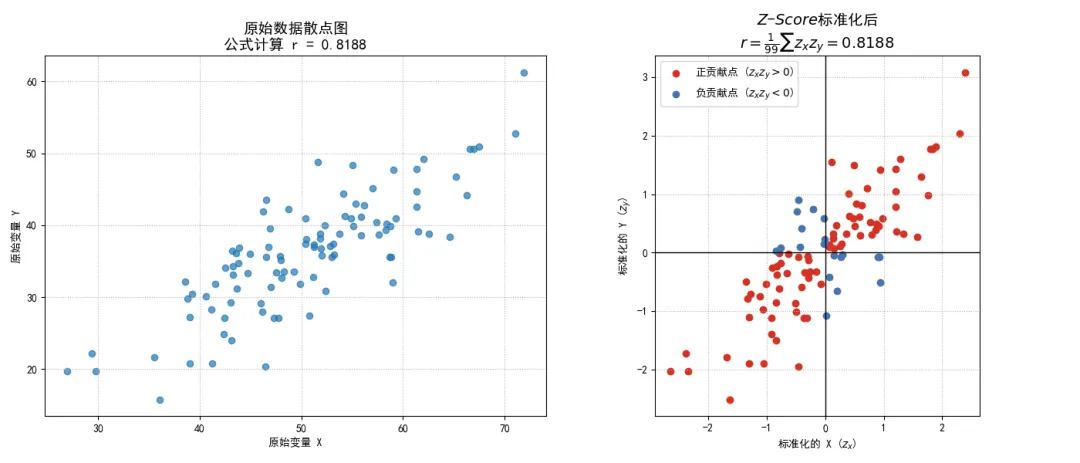
图表清晰地展示了两种方法计算出的相关系数 完全相等,且在右侧的Z-Score标准化空间中,坐标原点代表了数据的平均水平,落在第一和第三象限的点(红色),它们的 和 同号,乘积为正,对相关系数做出了正向贡献; 落在第二和第四象限的点(蓝色),它们的 和 异号,乘积为负,对相关系数做出了负向贡献;最终的相关系数,就是所有这些正负贡献的加权平均。
这种通过Z-Score标准化的定义,是我们后续理解更复杂的统计量(如t统计量)的基础。
然而,数值上的标准化并不能解决统计推断的核心难题:样本相关系数 的抽样分布本身是一个形状怪异、依赖于未知参数 的非标准分布。直接在这个分布上进行概率计算(如构建置信区间、进行假设检验)是极其困难的。
3标准化 II:Fisher Z变换与分布的正态化
在上述讨论中,我们通过模拟实验观察到,样本相关系数 的抽样分布是一个形状依赖于总体参数 的偏态分布。且当总体 接近0时,抽样分布近似对称,有点像正态分布;当总体 接近或时,由于 的取值范围被限制在 ,抽样分布会受到边界效应的挤压,呈现出强烈的偏态。
例如,如果 ,那么抽样得到的 值更容易低于0.9,而很难高于0.9,因为它的上升空间只剩下0.1,而下降空间有1.9。
这种非正态性以及分布形状对未知参数 的依赖,使得直接基于 进行统计推断(变得异常复杂。
为了克服这个难题,罗纳德·费雪(Ronald Fisher)提出了一个巧妙的非线性变换——Fisher Z变换(Fisher's Z-transformation)。这个变换能够将 的抽样分布,转化为一个近似正态的、且方差不依赖于未知参数 的新分布。
Fisher Z变换的数学定义与性质
Fisher Z变换的定义式如下:
其中 是自然对数, 是反双曲正切函数。这个函数将取值于 区间的 ,映射到了整个实数轴 上。
当样本 来自于一个二维正态分布时,经过变换后的新随机变量 的抽样分布具有以下性质:
一是 的分布比 的分布更接近于正态分布,尤其是在小样本和 接近边界的情况下;
二是 的期望近似等于对总体参数 进行相同变换后的值 。
三是 的方差几乎不依赖于未知的总体参数 ,它近似为一个只与样本量 有关的常数。
我们将编写一段代码,对比在不同总体 值(包括接近边界的极端情况)下,原始样本相关系数 的抽样分布和经过Fisher Z变换后 的抽样分布。
import numpy as npimport matplotlib.pyplot as pltimport scipy.stats as statsplt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 设定总体参数和实验参数population_rhos = [0.0, 0.5, 0.9] # 三种不同的总体相关系数sample_size = 20# 使用一个小样本量以凸显问题num_experiments = 10000# 创建 3x2 的子图布局fig, axes = plt.subplots(3, 2, figsize=(12, 15))fig.suptitle(f'Fisher Z变换对r抽样分布的正态化效果 (样本量 n={sample_size})', fontsize=18)for i, rho in enumerate(population_rhos):# 生成大量的样本相关系数 r cov_matrix = [[1.0, rho], [rho, 1.0]] sample_correlations_r = np.zeros(num_experiments)for j in range(num_experiments): sample = np.random.multivariate_normal([0, 0], cov_matrix, size=sample_size) sample_correlations_r[j] = np.corrcoef(sample[:, 0], sample[:, 1])[0, 1]# 对 r 进行 Fisher Z 变换# 为了避免 r=1 或 r=-1 导致 log(0) 的问题,进行微小的数值截断 sample_correlations_r = np.clip(sample_correlations_r, -0.99999, 0.99999) z_transformed_r = np.arctanh(sample_correlations_r)# --- 绘制 r 的分布 --- ax_r = axes[i, 0] ax_r.hist(sample_correlations_r, bins=50, density=True, alpha=0.7, label='r 的经验分布') ax_r.set_title(f'原始 r 的抽样分布 (当 $\\rho = {rho}$)') ax_r.set_xlabel('样本相关系数 r')if i == 0: ax_r.set_ylabel('概率密度')# 使用 Q-Q 图检验正态性 stats.probplot(sample_correlations_r, dist="norm", plot=plt.figure().add_subplot(111)) qq_ax = plt.gca() qq_line = qq_ax.get_lines()[1] # 获取理论线 qq_r_squared = np.corrcoef(qq_ax.get_lines()[0].get_ydata(), qq_ax.get_lines()[0].get_xdata())[0,1]**2 ax_r.text(0.05, 0.95, f'Q-Q R² = {qq_r_squared:.3f}', transform=ax_r.transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5)) plt.close()# --- 绘制 z_r 的分布 --- ax_z = axes[i, 1] ax_z.hist(z_transformed_r, bins=50, density=True, alpha=0.7, color='green', label='z_r 的经验分布') ax_z.set_title(f'Fisher Z变换后 $z_r$ 的分布 (当 $\\rho = {rho}$)') ax_z.set_xlabel('变换后的值 $z_r = \\text{arctanh}(r)$')# 绘制理论上的正态分布 z_rho = np.arctanh(rho) std_z = 1 / np.sqrt(sample_size - 3) x_grid = np.linspace(z_rho - 4*std_z, z_rho + 4*std_z, 200) pdf = stats.norm.pdf(x_grid, loc=z_rho, scale=std_z) ax_z.plot(x_grid, pdf, 'k--', label='理论正态分布\n$N(z_\\rho, \\frac{1}{n-3})$') ax_z.legend(loc='upper right')# 使用 Q-Q 图检验正态性 stats.probplot(z_transformed_r, dist="norm", plot=plt.figure().add_subplot(111)) qq_ax = plt.gca() qq_line = qq_ax.get_lines()[1] qq_r_squared = np.corrcoef(qq_ax.get_lines()[0].get_ydata(), qq_ax.get_lines()[0].get_xdata())[0,1]**2 ax_z.text(0.05, 0.95, f'Q-Q R² = {qq_r_squared:.3f}', transform=ax_z.transAxes, verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.5)) plt.close()plt.tight_layout(rect=[0, 0, 1, 0.96])plt.show()执行结果如下:
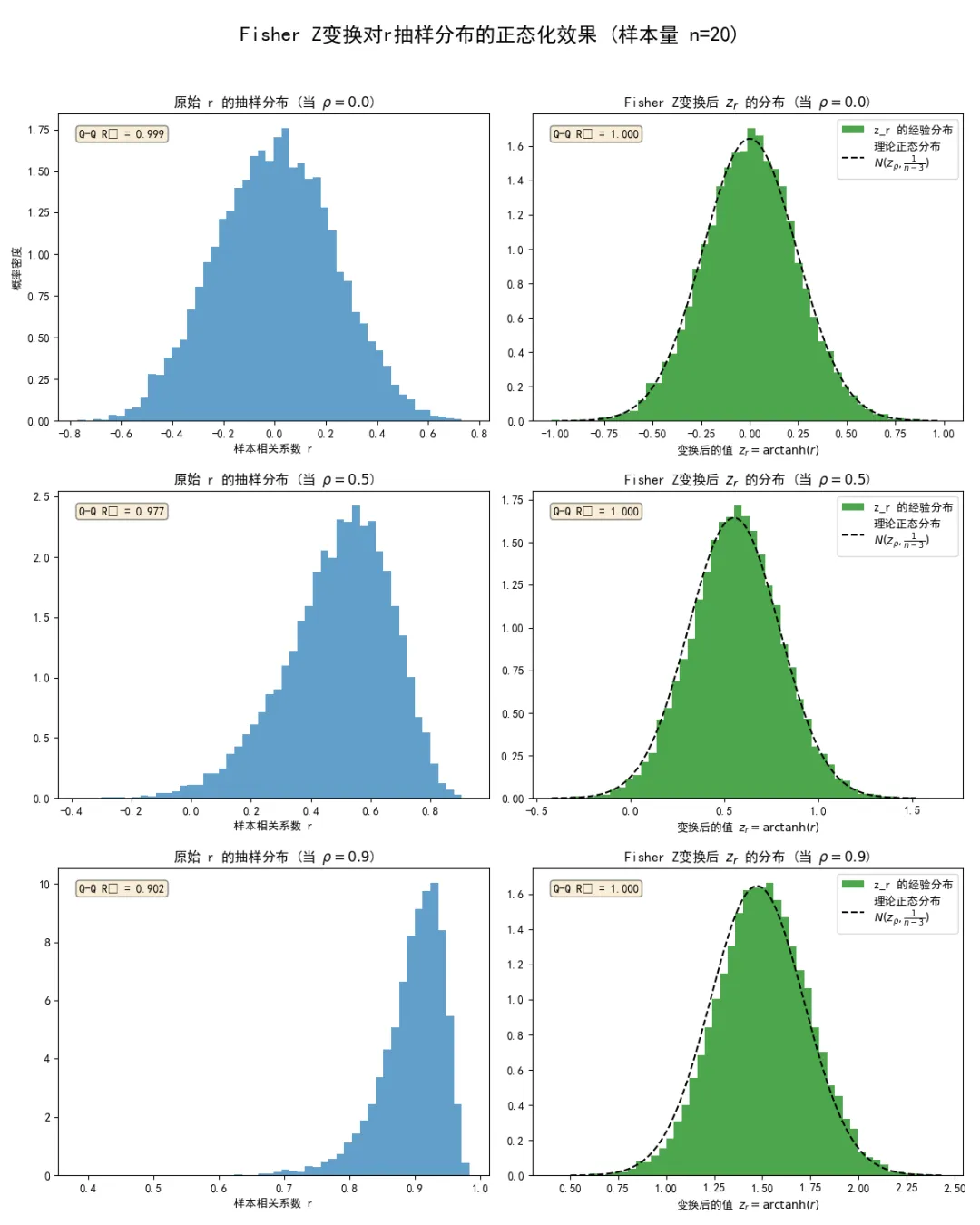
由图可知,当 时(第一行),原始的 分布(左侧)本身就比较对称,Q-Q图的R²值较高,表明其与正态分布拟合得不错。经过Z变换后(右侧),分布依然保持了很好的正态性;当 时(第二行),原始的 分布开始出现明显的左偏,Q-Q图的值下降。而经过Z变换后分布变得更加对称,Q-Q图的R²值显著提升,且与黑色的理论正态曲线拟合得非常好;当 时(第三行),这是最极端的情况。原始的 分布由于受到右侧边界的强烈挤压,呈现出极端的左偏形态,Q-Q图的值很低,完全不符合正态分布。
然而,Fisher Z变换将这个严重偏态的分布,成功地转化为了一个近似对称、钟形的正态分布,Q-Q图的值大幅回升。
Fisher Z变换的反函数
在利用Z变换进行统计推断(例如计算置信区间)后,我们得到的结果是在Z空间中的。为了将其解释回原始的相关性空间,我们需要使用Z变换的反函数。
如果 ,我们要求解出 。
这个反函数即双曲正切函数
(注:将分子分母同时乘以 即可得到 )
因此,Fisher Z变换的反函数就是双曲正切函数 。
在实际计算中,我们几乎总是在Z空间完成所有的统计计算,只在最后一步展示结果时,才使用 函数将Z空间的端点值转换回相关系数 的空间。
4标准化的应用场景
至此,我们通过Z-Score,我们将相关系数的计算与数据的尺度解耦,将其定义为标准化变量的乘积均值,通过Fisher Z变换,我们将相关系数的复杂抽样分布,近似转化为了一个简单的、与未知参数无关的正态分布,完成了对皮尔逊相关系数的两种标准化,其中分布的标准化,是后续所有相关性推断统计的基石。它为我们解决了以下几个核心问题:
一是为总体相关系数 构建置信区间。我们可以在Z空间中,围绕 构建一个正态置信区间 ,其中标准误 ;然后,我们再用反函数 将这个区间的两个端点转换回 的空间,得到的就是 的置信区间。
二是检验相关性是否显著不为0(即 )。 虽然这个问题有更直接的t检验方法,但也可以通过Z变换来解决。在原假设下,。我们可以构造Z统计量 ,并与标准正态分布的临界值进行比较。
三是比较两个独立的样本相关系数是否相等(即 )。这个问题无法简单的用t检验解决的问题。但有了Z变换,问题迎刃而解。我们分别计算两个样本的 和 。根据方差的可加性,它们的差值 的方差为 。 我们可以构造Z统计量 ,它近似服从标准正态分布。
本节总结
在本节中,我们严格区分了作为未知参数的总体相关系数 和作为随机变量的样本相关系数 。通过模拟实验,我们直观地展示了 存在抽样分布,并且这个分布是偏态的、依赖于未知参数 的,这为统计推断带来了巨大的困难。
进一步开展了数值标准化。我们证明了 在代数上等价于对原始数据进行Z-Score标准化后,其乘积的均值。这个定义深化了我们对相关系数内在逻辑的理解。
引入了分布标准化。介绍了Fisher Z变换的数学定义 及其反函数 。通过一个系统性的模拟实验,我们证明了这个变换能够将 的偏态分布转化为一个近似于 的正态分布,并且其方差与未知的 无关。

