第一章:从用户态快路径到内核慢路径
1.1 Mutex 失败后的路径切换
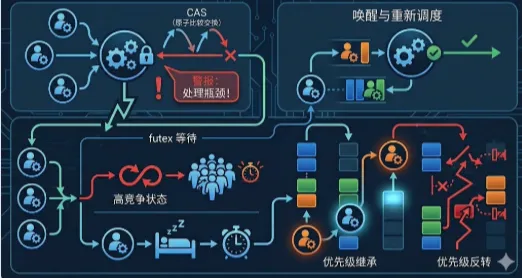
在绝大多数工程师的直觉里,pthread_mutex_lock() 的开销似乎只是一次 CAS 原子操作,因此往往把锁性能问题简单理解为“原子指令太多”。但真正的性能分水岭并不在 fast path,而在 CAS 失败后的 slow path 切换频率。无竞争场景下,线程仅通过用户态原子交换即可完成 owner 设置,耗时通常仅几十纳秒,cache 命中时甚至更低;一旦竞争出现,glibc 会先执行短暂 adaptive spin,随后迅速跌入 futex(FUTEX_WAIT),进入内核等待队列。此时成本模型立刻变化:原本单纯的 CPU 指令流水,变成 syscall、哈希桶加锁、等待队列挂接、调度休眠、IPI 唤醒、runqueue 插入以及 cache 热数据失效的组合路径。很多系统里临界区本身只有 100~300ns,但 slow path 一次就可能增加数微秒,这意味着锁本身不是瓶颈,锁失败后的调度路径才是系统延迟被指数级放大的根源。
1.2 为什么极短临界区也会引发灾难性抖动
很多人误以为“临界区短就一定安全”,这是 mutex 优化里最常见的误判。极短临界区在高线程密度下反而更容易出现灾难性抖动,因为锁持有时间虽短,但 owner 一旦在 unlock 前被调度器抢占,所有 waiter 都会被放大到一个完整调度周期。典型场景如日志 ringbuffer、连接跟踪表、对象池 freelist,这些共享路径本来只需几百纳秒,但当 owner preemption 出现后,等待线程延迟从 ns 直接跨越到 ms。更隐蔽的是虚拟化环境中的 vCPU 抢占:guest 内线程持锁期间若宿主机调度 host vCPU 让出 CPU,那么 guest 里的所有 waiter 会错误地表现为“锁竞争严重”,实际根因却是宿主调度延迟。因此真正优化 mutex,不能只盯临界区代码,而要联合观察 sched_switch、owner runtime、wake latency 与 vCPU steal time,确认慢的到底是锁,还是锁背后的调度链路。
第二章:Futex 哈希桶热点与伪共享陷阱
2.1 Futex 哈希桶冲突如何制造隐藏串行化
futex 被广泛认为是高性能同步原语,核心原因在于无竞争不进内核。但进入慢路径后,所有 futex 地址都会映射到内核哈希桶。理论上桶数量足够时冲突概率可控,但真实业务里大量短生命周期对象、数组式 mutex、连接池槽位锁,常常让地址低位高度集中,最终映射到少数热点桶。此时多个逻辑无关的锁会共享同一个 bucket spinlock,形成内核层面的隐藏串行化。应用层看起来是“不同锁互不相关”,而 perf 却显示大量时间耗在 futex_wait_queue_me 或 bucket spin 上。尤其高并发会话表、线程池任务队列、分片缓存系统中,这类热点桶会直接拖垮吞吐,使锁竞争看起来远超真实共享程度。
2.2 伪共享比真实锁竞争更难排查
另一个更隐蔽的问题是伪共享。很多锁对象虽逻辑独立,但被连续分配在同一 cacheline 内,例如结构体数组中的多个 mutex 字段。不同 CPU 分别操作不同锁时,仍会因 MESI 协议导致 cacheline 在核间频繁 bouncing。此时即使没有 futex wait,性能也会持续恶化,表现为 CAS latency 上升、LLC miss 增加、snoop traffic 激增。和真实竞争不同,伪共享在代码层面几乎不可见,必须通过 perf c2c、cacheline 对齐分析或结构体 padding 才能定位。工程上常见优化包括 64B 对齐锁对象、按 NUMA 节点分片分配、冷热字段拆分等,否则你优化了 futex 路径,却仍会被 cache coherence 吞掉收益。
第三章:唤醒惊群与调度风暴
3.1 唤醒一个线程,为什么可能抖动一群 CPU
futex 的 FUTEX_WAKE 从语义上看只是把等待队列中的一个或多个线程设置为 runnable,但在线程池、数据库 worker、网络收包线程这类高并发场景里,unlock 往往并不意味着竞争结束,而是新一轮竞争开始。一个典型链路是:owner 解锁 → waiter 被唤醒 → 线程插入 runqueue → IPI 通知目标 CPU → 目标 CPU 发生调度点 → waiter 恢复执行 → 再次争抢共享资源。如果此时被唤醒的线程不止一个,就会形成局部惊群。很多业务里明明只释放了一个资源,却唤醒多个候选线程,最终只有一个线程真正拿到锁,其余线程重新进入睡眠,造成大量无效上下文切换。更糟糕的是,多个线程被唤醒后会同步访问 owner 刚释放的 cacheline,造成瞬时 cacheline 抖动与 LLC refill,尾延迟迅速上升。
[Owner unlock] | v[FUTEX_WAKE] | v[多个 waiter 进入 runnable] | v[IPI 通知多个 CPU] | v[重新调度 + cacheline 抢占] | v[仅1个线程成功拿锁] | v[其余线程再次 FUTEX_WAIT]
3.2 惊群在高核服务器上的放大机制
在 64 核、96 核甚至双路 NUMA 服务器上,惊群的代价会进一步放大。原因不是线程数量线性增加,而是调度域、NUMA 域和 LLC 域共同参与了锁恢复链路。一个 waiter 若被调度到远端 socket,不仅需要重新抢锁,还要跨节点拉取锁变量及临界区相关数据,单次恢复执行就可能增加数百纳秒到数微秒。数据库 buffer pool、消息队列 broker、共享索引更新路径最容易出现这种问题:白天业务高峰时吞吐仍然正常,但 P99.9 延迟突然恶化,本质就是 unlock 引发的小规模 CPU 广播。工程上应尽量采用 worker 分片、per-core queue、MCS 队列锁风格设计,把唤醒控制在局部 CPU 域内,而不是让一个全局 mutex 成为整机同步点。
第四章:优先级反转的真实代价
4.1 为什么低优先级线程能拖死高优任务
优先级反转不是抽象理论,而是系统抖动里极其常见的真实根因。其核心模型是:高优线程 H 等待低优线程 L 持有的锁,而中优线程 M 不断抢占 CPU,使 L 无法运行,自然也无法释放锁。此时 H 看起来是“卡在 mutex 上”,但真正的问题是调度优先级破坏了资源释放顺序。很多实时链路,如工业网关控制线程、音视频同步时钟线程、网络设备 keepalive 线程,都可能因为一个低优后台线程持锁而发生 deadline miss。没有 PI 时,这种问题的症状极具迷惑性:perf 看见的是 mutex hotspot,业务看到的是周期超时,真正根因却藏在 scheduler 的抢占路径里。
4.2 普通服务器中的软优先级反转
即使不使用 SCHED_FIFO/SCHED_RR,普通服务器同样存在“软优先级反转”。例如 RPC 主线程等待日志落盘状态锁,而锁 owner 是低权重 cgroup 内的后台 flush 线程;与此同时一批中等优先级业务线程持续跑满 CPU。由于 cgroup quota、容器 CPU limit、虚拟机 steal time 的存在,低优 owner 可能长时间拿不到时间片,最终让高价值请求线程尾延迟暴涨。这类问题在云环境非常高频,尤其是微服务网关、配置中心和状态同步线程。解决思路不只是“减少锁”,更关键是避免高优路径依赖低权重后台线程持有的共享状态。
[高优线程 H 等锁] | v[低优线程 L 持锁] | v[中优线程 M 持续抢占 CPU] | v[L 无法运行] | v[H 长时间阻塞 -> 延迟抖动]
第五章:PI Futex 与 rt_mutex 链式传播
5.1 PI 的本质是资源依赖链传播
PI futex 的核心并不是简单“提升 owner 优先级”,而是基于 rt_mutex 动态维护完整资源依赖链。当线程 A 等待线程 B 的锁,而 B 又在等待线程 C 的另一个锁时,系统必须把 A 的高优先级沿链路一直传递到 C,否则最底层 owner 仍可能被其他线程抢占。这意味着每次 wait、wake、timeout、owner 迁移时,内核都要更新红黑树、重排 waiter 队列并重新计算继承优先级。依赖链越长,PI bookkeeping 成本越高。
5.2 性能陷阱:链太长时比业务还重
很多团队看到“PI 能解决优先级反转”后,习惯性把它用于普通服务锁,这是非常危险的。PI 适合实时 deadline 场景,但对数据库元数据锁、复杂对象树锁、嵌套配置锁这类多层依赖结构,PI 的传播链可能非常长。一次加锁失败触发的不只是 futex wait,而是整条 owner 链优先级重算,甚至涉及多个 CPU runqueue 调整。此时锁管理成本可能比临界区业务本身还高,最终吞吐明显下降。因此 PI 必须用于强实时关键路径,而不是作为通用“高级锁”滥用。
[A 高优等待 B] | v[B 等待 C] | v[C 实际 owner] | v[A 优先级 -> B -> C 链式继承]
第六章:NUMA 与锁迁移成本
6.1 锁真正慢的常常不是 futex,而是跨节点 cacheline
NUMA 服务器里,全局锁最容易成为跨 socket cacheline 漂移热点。即使没有明显 futex wait,只要 owner 在不同 NUMA 节点频繁迁移,锁变量所在 cacheline 就会不断跨 UPI/QPI 链路转移。一次远端 hop 的成本可达本地 LLC 的数倍,若叠加 CAS retry、自旋失败和 futex 慢路径,锁延迟会从百纳秒直接进入微秒级。很多数据库 buffer header lock、全局统计计数器、连接池空闲链表锁都属于此类问题。
6.2 降低 NUMA 锁抖动的工程方法
真正有效的方法不是盲目替换 lock-free,而是从数据所有权入手:按 NUMA 节点拆分 freelist、连接表、任务队列和统计信息,让线程优先访问本地资源;同时通过绑核和内存本地化分配减少 owner 漂移。对于不可避免的全局状态,应使用批量汇总而非实时更新,避免高频全局 mutex 成为双路服务器的 cache ping-pong 中心。
[CPU0 owner] | v[unlock] | v[CPU1 waiter 抢锁] | v[cacheline 跨 socket 漂移] | v[远端访问延迟上升]
第七章:性能优化的落地方法论
7.1 从 wait graph 而不是热点函数入手
锁优化最怕“只看热点函数”。pthread_mutex_lock 时间占比高,并不代表问题就在 lock API 本身。真正要分析的是完整 wait graph:谁持锁、谁等待、owner 是否被抢占、waiter 是否跨 NUMA 唤醒、wake 后是否再次失败。建议联合 perf lock、perf sched、ftrace 和 eBPF 构建等待链路,重点观察 CAS fail、slow path 比例、wake latency 和 runqueue backlog。只有把锁、调度、NUMA 和 cacheline 串起来,才能真正找到尾延迟源头。
7.2 最终目标不是无锁,是可预测延迟
很多人喜欢把“无锁”作为终点,但在线上系统里更重要的是可预测性。一个设计良好的 mutex,若 owner 稳定、本地 NUMA 命中高、waiter 局部化,往往比复杂 lock-free 结构更容易控制尾延迟。系统优化的最终目标不是消灭所有锁,而是让锁竞争范围收敛、唤醒链路最短、优先级继承仅用于关键路径、NUMA 漂移最小化。只有这样,P99 和 P999 才能真正稳定。