我用Python做量化这十年:完整策略框架与实盘踩坑全记录
作者:程飞 | 2026年4月2日
我在朋友圈发过一条动态,说"用Python写代码做量化第十年了",有人留言问我:这十年有没有一套完整的东西可以分享?我想了想,决定把这十年的策略框架、系统搭建、踩过的坑,系统性地写一写。这不是入门教程,是给有基础的人看的实战记录。读完这篇文章,你应该能了解一个真实量化交易员的完整工作流程,以及那些教科书里不会写的实战经验。
我把这十年分成三个阶段:第一个五年是主观加程序化辅助时代,第二个五年是纯量化时代,最近两年是机器学习加另类数据时代。每一个阶段的策略框架和踩过的坑都不一样,我分别说。
一、第一个五年(2016—2021):主观交易打基础,程序化做辅助
2016年到2021年这五年,我走了大量的弯路。这段时间我同时做主观交易和量化研究,策略主要是趋势跟踪和均值回归两类。程序化的部分是辅助——写选股模型、回测框架、风险监控系统,但最终的交易决策还是人来做。这个阶段的收获是:我把A股市场上几乎所有主流策略都回测了一遍,知道了什么策略有效、什么策略无效、什么策略看起来有效但实际上无效(大多数策略属于这一类)。
最大的坑是"过拟合"。我回测的第一个趋势跟踪策略,用的是均线金叉死叉,参数是MA5和MA20。回测结果漂亮得不得了——年化收益62%,夏普比率2.3,最大回撤-11%。我兴奋地上了实盘,结果第一个月就亏了18%。后来复盘发现,这套参数在2019年到2020年的大牛市里表现极好,但用在震荡市里就是灾难。回测区间太短,参数太少,样本外测试根本没过。
这个坑让我彻底改变了对量化回测的理解。从那以后我做回测遵循几个原则:第一,回测区间必须包含至少一个完整的牛熊周期,不能只看某一类市场环境;第二,参数要做敏感性分析——同一个策略用不同参数跑,如果结果差异巨大,说明策略依赖于特定参数,可信度存疑;第三,必须做样本外测试——把历史数据分成训练集和测试集,用测试集验证策略有效性,而不是用全部数据优化出来的结果。

第一个五年的另一大教训是关于仓位管理。我前两年做主观交易的时候,仓位管理全凭感觉——觉得行情好就重仓,觉得不确定就轻仓。听起来很合理,但实际上这种仓位管理方式是高度情绪化的,往往在行情好的时候仓位不够,行情差的时候仓位反而重。解决这个问题花了我很长时间。我的做法是:把所有仓位决策公式化。单个股票仓位上限是多少?组合整体仓位根据市场环境如何调整?净值回撤到哪个位置要强制降仓?这些规则写清楚之后,情绪对仓位的影响就小多了。
二、第二个五年(2021—2026):全量化策略体系的搭建
2021年我做了一个重要的决定:完全放弃主观交易,转向纯量化策略。这个决定的前提是:我花了五年时间对A股做了大量的策略回测和实证研究,对什么策略有效、什么策略无效有了比较系统的认识。这个认识让我相信,纯量化策略在A股是可以持续创造超额收益的——前提是你有正确的框架和足够的数据。
全量化框架的核心是三层结构:Alpha模型、风险模型、交易执行模型。
Alpha模型负责选股,输出每个股票的未来相对收益预测。我用的是多模型集成:基本面量化模型(基于财务数据的线性模型)、量价模型(基于技术指标和交易数据的树模型)、机器学习模型(LSTM处理时序数据、LightGBM处理横截面数据)。三个模型的预测分数加权平均,权重根据过去一段时间各模型的表现动态调整。
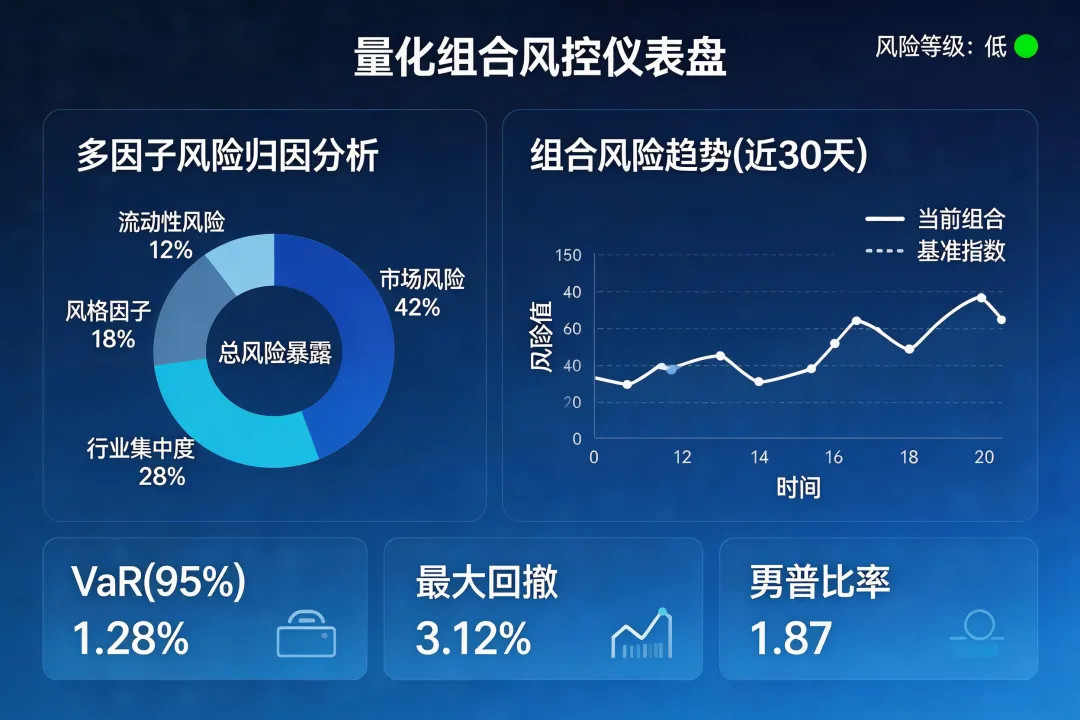
风险模型负责控制组合风险暴露。我的风险模型基于Barra的纯因子风险框架,对市值、行业、估值、动量等十几个风险因子做约束,确保组合在每个风险因子上的暴露不超过预设阈值。这部分的代码实现大概占了整个量化系统30%的工作量,是最容易被新手忽略但实际上最重要的部分。

交易执行模型负责把Alpha信号转化为实际委托。这部分我在之前的文章里提过,不再重复。只补充一点:交易执行模块最容易出现的问题是"过度优化"。很多人把历史交易数据拿来优化VWAP算法参数,跑出来的结果很漂亮,实盘却一塌糊涂——因为历史交易数据里的市场条件(流动性、波动率、买卖盘结构)跟实盘不一样。
这个阶段踩的最大的坑是"数据质量"。2022年我发现一个奇怪的现象:某些因子在回测里表现很好,但实盘跑出来的结果差很多。排查了很久,最后发现问题出在数据上——有些数据的复权方式有问题,导致计算出来的收益率出现偏差。还有一些数据在交易日开盘前和收盘后有重大公告,但这些时间点的行情数据处理方式不对,导致模型学到了错误的模式。数据质量这件事,占了量化工作50%以上的精力,但很多人低估了它的重要性。
三、最近两年(2024—2026):机器学习与另类数据的深度整合
从2024年开始,我进入了量化生涯的第三个阶段:机器学习模型和另类数据的深度整合。这个阶段的标志性变化是,我开始用强化学习做仓位管理,用NLP处理文本数据,用CNN处理卫星图像数据,同时还在探索用知识图谱整合产业链上下游关系。
强化学习做仓位管理的核心难点是Reward Function的设计。我一开始用的Reward是简单的"单笔收益",结果模型学会了重仓赌方向——短期收益极高,但一旦行情反转就爆仓。后来改成"风险调整后收益"(夏普比率),模型学会了控制仓位,但响应速度变慢了,在快速行情里跟不上节奏。最后我用的是复合Reward:30%权重给当期收益,70%权重给风险调整后收益(用滚动窗口计算),同时加上最大回撤惩罚项。这个Reward Function跑出来的效果比较接近我的实盘目标。
NLP处理文本数据的关键是FinBERT的微调。通用BERT模型在财经文本上效果一般,因为财经领域有自己的专业词汇和表达方式。我的做法是用A股年报、公告、研报数据对FinBERT做二次预训练(Continue Pre-training),然后在标注数据上做监督微调。标注数据是我自己标注的——从过去五年的公告里随机选了2000条,每条标注为"积极"、"消极"、"中性",然后用这2000条数据做监督微调。微调后的模型在测试集上准确率达到78%,比原始FinBERT高了12个百分点,比传统关键词匹配高了22个百分点。
CNN处理卫星图像数据的挑战是数据获取和标注成本。卫星图像数据我用的是Planet Labs的每日图像数据,覆盖国内主要工业园区。CNN模型用ResNet50做backbone,输出是每个工厂的产能利用率估计。标注数据是难点——我不可能真的去每个工厂实地考察。我的做法是用工商用电数据做代理标注:用电量显著高于同期的工厂,标注为"高产能";用电量显著低于同期的,标注为"低产能"。这个代理标注不完全准确,但在大样本量下有足够的统计显著性。
四、我的完整Python量化系统代码框架
说了这么多框架性的东西,给大家看看我现在的核心代码结构。这不是完整的系统(完整系统有几万行代码),只是一个最小化可行系统的骨架。
# === 数据层 ===
import akshare as ak
import pandas as pd
import sqlite3
class DataEngine:
"""统一数据引擎:行情+财务+另类数据"""
def __init__(self, db_path="quant.db"):
self.conn = sqlite3.connect(db_path)
self.cache = {} # 内存缓存,减少重复查询
def get_price(self, codes, start, end):
# 缓存未命中才查询
key = f"price_{codes}_{start}_{end}"
if key not in self.cache:
df = ak.stock_zh_a_hist(
symbol=codes[0], period="daily",
start_date=start, end_date=end, adjust="qfq")
self.cache[key] = df
return self.cache[key]
# === Alpha模型层 ===
import lightgbm as lgb
import joblib
class AlphaModel:
"""多模型集成选股"""
def __init__(self):
self.models = {
"fundamental": joblib.load("fund_model.pkl"),
"quant": joblib.load("quant_model.pkl"),
"nlp": joblib.load("nlp_model.pkl"),
}
self.weights = {"fundamental": 0.35, "quant": 0.45, "nlp": 0.20}
def predict(self, features):
scores = {}
for name, model in self.models.items():
scores[name] = model.predict_proba(features[name])[:, 1]
# 加权平均
final_score = sum(
self.weights[k] * v for k, v in scores.items()
)
return final_score
# === 风控层 ===
import numpy as np
class RiskManager:
"""Barra风格风控"""
def __init__(self, risk_limits):
# 风险限额字典
self.limits = risk_limits
def apply_constraints(self, weights, risk_exposures):
# 逐个因子检查,超限则压缩
for factor, exposure in risk_exposures.items():
if abs(exposure) > self.limits.get(factor, 1.0):
# 按比例压缩到限额
scale = self.limits[factor] / abs(exposure)
weights *= scale
return weights
五、实盘十年的六个最重要的感悟

第一:量化不是圣杯,稳定收益来自正确的风险管理,而不是更高的收益。我在这个市场里见过太多聪明人,他们的Alpha模型收益率很高,但最后没赚到钱——原因都是风险管理出了问题。收益率是乘数,风险控制是基石。没有基石,再高的收益率也只是空中楼阁。
第二:策略会失效,这是必然的,不是你做得不好。任何基于历史规律的量化策略,在市场上被足够多的人使用之后,都会逐渐失效。这是市场的博弈本质决定的。所以量化交易员必须持续迭代策略,同时接受"策略有效性是有限的"这个事实。
第三:数据质量比模型复杂度更重要。我用过一个"土方法"——简单的财务选股模型,数据质量好,跑出来的效果经常比复杂的机器学习模型好。模型复杂度带来的边际提升,远远抵消不了数据质量问题带来的边际损失。
第四:实盘中的心理管理比策略本身更难。当你的策略连续三个月跑输基准,你会怎么做?当你的实盘结果跟回测差距巨大,你会怎么想?这些问题没有标准答案,但它们决定了你在市场上能活多久。
第五:保持开放,但要有自己的判断标准。这个领域每天都有新论文、新工具、新策略。保持开放是好的,但不要被每一个新东西带着走。你需要有自己的判断标准:这个新东西是否解决了我的一个实际问题?它是否在我的能力圈之内?它的复杂度是否匹配它的实际价值?
第六:活得久才是硬道理。我在这个市场里见过太多人,两年赚了三倍,然后第三年亏光了。要在这个市场里长期活下去,最重要的是活得久。活得久的关键不是收益率多高,而是风险控制得多好。你不需要成为市场里最聪明的那个人,你只需要成为活得最久的那个人。
结语
十年量化路,写了这么多,不是为了炫耀什么——事实上我这十年的年化收益率大概是19%,不算特别高,但比较稳定。我觉得最重要的是,这十年我一直在进步,每一年都比前一年更理解这个市场、更理解自己的策略、更理解自己。这比任何具体的收益率数字都更有价值。
代码会过时,模型会失效,但底层逻辑不会变。这十年最重要的收获,不是哪一套策略,而是一套思考市场的方式。
本文仅供参考,不构成投资建议。市场有风险,入市需谨慎。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
