Python绝学,大道至简——高效编写数据分析脚本的五种秘笈
- 2026-07-03 03:38:52


江湖风波恶,“码林”行路难。
时值岁末寒风凛,江湖传言:生物信息阁中,数据如江湖暗流,非精妙算法不得破局。然诸君执笔成码,常因招式粗疏,致脚本繁冗如乱麻,既失其效,又损其韵。今有武林秘典《码林五绝》现世,此乃前贤于数据洪流中淬炼之精要:
一曰"列表推导",如掌降龙,凌厉刚猛,无坚不摧;二曰"函数匿名",似太极阴阳相融,以柔克刚;三曰"map迭代",纵千里数据亦可瞬息擒拿;四曰"apply应用",若剑招起落皆有章法;五曰"函数装饰",同金钟罩护体周全。习得此五绝者,执笔如持龙泉,代码似行云流水,破数据迷阵如探囊取物。
(利剑境:宝剑锋利,凌厉刚猛,无坚不摧,依赖外物与招式,入此境者,可与群雄争锋)
列表推导式(List Comprehension)是 Python 中一种简洁高效的语法结构,用于从可迭代对象(如列表、元组、集合等)生成新列表。其核心思想是将遍历、条件筛选和元素处理整合到一行代码中,从而提升代码可读性和执行效率。
(一)基本语法
1 [表达式for变量in可迭代对象if条件]
2 [表达式1if条件else表达式2for变量in可迭代对象]
表达式:生成新列表元素的计算逻辑(如 x**2)。
表达式1:if 条件下执行新列表元素的计算逻辑。
表达式2:else语句下执行新列表元素的计算逻辑。
变量:迭代变量(如 x)。
可迭代对象:源数据(如 range(10))。
条件:可选筛选条件(如 x % 2 == 0)。
(二)优势1.简洁性:将多行循环+条件+操作压缩为单行。2.性能优化:底层实现更高效,通常比 map()/filter() 更快。3.可读性:语法直观,符合 Python 的“明确优于隐晦”原则。(三)实操
1. 数值转换(平方数列表)
1# 传统方式(4行)
2squares = []
3for i inrange(10):
4squares.append(i**2)
5
6# 列表推导式(1行)
7squares = [i**2for i inrange(10)]
输出:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]。
2. 数据过滤(保留偶数)
1 # 传统方式(3行)
2 nums = [12, 7, 18, 5, 9, 22]
3 evens = []
4 for x in nums:
5 if x % 2 == 0:
6 evens.append(x)
7
8 # 列表推导式(1行)
9 evens = [x for x in nums if x % 2 == 0]
输出:[12, 18, 22]。
3. 嵌套循环(矩阵转置)
1 # 传统方式(5行)
2 matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
3 transposed = []
4 for i inrange(len(matrix)):
5 rowi = []
6 for row in matrix:
7 rowi.append(row[i])
8 transposed.append(rowi)
9
10 # 列表推导式(1行)
11 transposed = [[row[i] for row in matrix] for i inrange(len(matrix))]
输出:[[1, 4, 7], [2, 5, 8], [3, 6, 9]]。
4.提取指定路径下的分组名和样本名
在test文件夹下随机创建文件夹,如图所示:
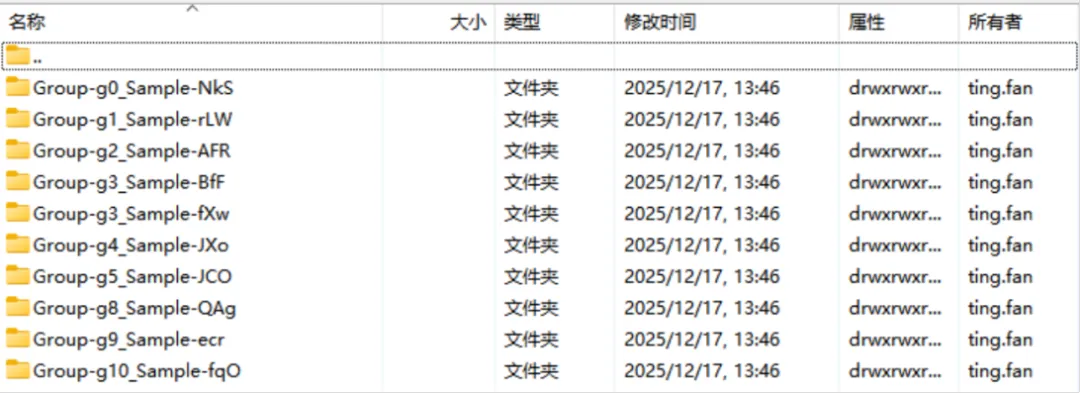
其中,文件夹名由组名和样本名组成,如“Group-g0_Sample-NkS”中,组名为g0,样本名为NkS。因此最终的目标为提取test目录下所有的组名(g0,g1,g2, ...)和样本名(NkS,rLW,AFR, ...)
生成随机文件夹:
1 # 导入模块
2 import os
3 import random
4 # 生成英文26个字母列表
5 alphabet = [chr(i) for i inrange(97, 123)]
6 Alphabet = [al.upper() for al in alphabet]
7 all_lis = alphabet + Alphabet
8 # 设置随机种子,保证结果可复现
9 random.seed(221)
10 # 创建文件夹
11 for i inrange(10):
12 os.makedirs(f'test/Group-g{random.randint(0,10)}_Sample-{all_lis[random.randint(0,51)]}{all_lis[random.randint(0,51)]}{all_lis[random.randint(0,51)]}')
输出:Group-g3_Sample-BfF, Group-g3_Sample-mcF, Group-g4_Sample-Ofq, Group-g5_Sample-JCO, Group-g6_Sample-gAY, Group-g6_Sample-lHX, Group-g6_Sample-Vdo, Group-g8_Sample-zfW, Group-g9_Sample-WcN, Group-g10_Sample-Zpf。
提取分组名和样本名:
1 import os
2 groups,samples = set(),set()
3
4 # 传统方式(5行)
5 for folder in os.listdir(folder_path):
6 if"_"in folder:
7 group, sample = folder.split("_")
8 groups.add(group.split("-")[1])
9 samples.add(sample.split("-")[1])
10
11 # 列表推导式(1行)
12 k = [[group_lis.add(row[0].split('-')[1]),sample_lis.add(row[1].split('-')[1])] for row in [folder_name.split("_") for folder_name in os.listdir(f'test')]]
输出:{'g5', 'g6', 'g8', 'g10', 'g9', 'g4', 'g3'} {'Zpf', 'JCO', 'WcN', 'BfF', 'mcF', 'zfW', 'gAY', 'lHX', 'Ofq', 'Vdo'}。
(四)注意事项
避免嵌套过深:超过三层嵌套时建议拆分为多步骤处理。
无副作用操作:推导式中应避免修改外部状态。
大数据场景:处理海量数据时优先使用生成器表达式(惰性求值)。
列表推导式是 Python 中处理数据的利器,通过合理运用可显著提升代码效率和可维护性。
(软剑境:追求极致变化与速度,剑出无畏,道成无悔,入此境者,阴阳相融,刚柔并济)
匿名函数(Lambda)是Python中一种无需显式定义的函数,通过关键字lambda创建。
(一)基础语法
1 lambda参数1, 参数2, ... : 表达式
1. 参数:可多个,用逗号分隔。
2. 表达式:单行计算逻辑,结果自动返回。
(二)优势
1. 与高阶函数配合:常用于map()、filter()等内置函数。
2. 临时功能定义:无需命名,避免函数名冲突。
3. 模块化编程:作为参数传递,增强代码复用性。
4. 简洁性:仅包含单行表达式,无需函数名。
5. 即时定义:在需要时直接定义,适合临时使用。
6. 自动返回:表达式结果自动返回,无需return。
(三)实操
1. 数值计算(平方数生成)
1 # 传统方式(3行)
2 def square(x):
3 return x**2
4 numbers = [1, 2, 3, 4]
5 squares = list(map(square, numbers))
6
7 # Lambda方式(1行)
8 squares = list(map(lambda x: x**2, numbers))
输出:[1, 4, 9, 16]。
2. 数据过滤(保留偶数)
1 # 传统方式(3行)
2 def is_even(x):
3 return x % 2 == 0
4 nums = [1, 2, 3, 4, 5]
5 evens = list(filter(is_even, nums))
6
7 # Lambda方式(1行)
8 evens = list(filter(lambda x: x % 2 == 0, nums))
输出:[2, 4]。
3. 排序(按长度排序字符串)
1 # 传统方式(3行)
2 def get_length(s):
3 returnlen(s)
4 words = ["apple", "banana", "pear"]
5 sorted_words = sorted(words, key=get_length)
6
7 # Lambda方式(1行)
8 sorted_words = sorted(words, key=lambda s: len(s))
输出:['pear', 'apple', 'banana']。
(四)注意事项
单行限制:Lambda仅支持单行表达式,复杂逻辑需用常规函数。
参数类型:支持任意类型参数,但避免过多参数(1-2个最佳)。
性能优化:Lambda在高阶函数中比常规函数更高效,但不适合复杂计算。
匿名函数是Python中处理简单逻辑的利器,通过合理运用可显著提升代码简洁性和执行效率。
(重剑境:重剑无锋,大巧不工。入此境者,举轻若重,举重若轻,轻重自如,返璞归真)
map() 是 Python 中一个强大的内置函数,用于将一个函数应用到可迭代对象(如列表、元组)的每个元素上,并返回一个迭代器(惰性求值)。其核心功能是将函数与数据流结合,实现数据处理的函数式编程风格。
(一)基础语法
1 map(function, iterable, ...)
function:要应用的函数,接受一个或多个参数。
iterable:一个或多个可迭代对象(如列表、元组、字符串)。
返回值:一个迭代器,包含函数处理后的结果。
(二)优势
1. 惰性求值:map() 返回迭代器,实际计算在迭代时触发,节省内存。
2. 多输入支持:可同时处理多个可迭代对象,函数需接受相应数量的参数。
3. 兼容性:支持内置函数(如 str.upper)和自定义函数。
(三)实操
1. 平方运算(单输入处理)
1 # 计算列表元素的平方
2 numbers = [1, 2, 3, 4, 5]
3 squares = map(lambda x: x**2, numbers)
4 print(list(squares))
输出:[1, 4, 9, 16, 25]。
使用 lambda 表达式定义匿名函数,可简化函数的定义。
2. 求和运算(多输入处理)
1 # 向量加法
2 vec1 = [1, 2, 3]
3 vec2 = [4, 5, 6]
4 result = map(lambda x, y: x + y, vec1, vec2)
5 print(list(result))
输出: [5, 7, 9]。
当输入两个数据时(vec1,vec2),此处的函数需接受两个参数(x,y),map() 会自动将两个数据中,相同索引位置的元素一一对应,但需要注意的是,传入的两个数据必须具有相同的维度。
3. 调用python内置函数
1 # 将字符串列表转换为大写
2 words = ["hello", "world"]
3 upper_words = map(str.upper, words)
4 print(list(upper_words))
输出:['HELLO', 'WORLD']。
直接使用内置函数 str.upper。
4. 应用自定义函数
# 自定义函数示例
1 # 自定义函数示例
2 def add_prefix(text, prefix):
3 returnf"{prefix}_{text}"
4
5 texts = ["apple", "banana", "cherry"]
6 prefixed_texts = map(add_prefix, texts, ["fruit"] * 3)
7 print(list(prefixed_texts))
输出:['fruit_apple', 'fruit_banana', 'fruit_cherry']。
通过 map() 实现多参数函数的批量处理。
(四)注意事项
类型转换:map() 返回迭代器,需用 list()、tuple() 等转换为具体类型。
性能优化:处理大数据集时,map() 通常比显式循环快2.3倍。
替代方案:map() 与列表推导式功能类似,但 map() 更适合函数式编程场景。
(木剑境:运用之妙,存乎一心,木剑非剑,是为心剑。入此境者,发乎本能,不拘外物,草木竹石均可为剑)
data.apply() 是 Pandas 库中用于批量处理数据的核心函数,支持对 Series 和 DataFrame 对象应用自定义函数或 lambda 表达式。
(一)基础语法
1 data.apply(func, axis=0, raw=False, result_type=None, args=(), **kwargs)
· func:要应用的函数或 lambda 表达式。
· axis:处理方向(0/1 或 'index'/'columns')。
· raw:数据传递方式(Series/ndarray)。
· result_type:结果格式控制(仅 axis=1 时生效)。
(二)优势
1. 数据类型支持:适用于 Series(单列数据)和 DataFrame(多列数据)。
2. 灵活轴向处理:通过 axis 参数控制函数作用于行(axis=1)或列(axis=0)。
3. 高效执行:底层实现优化,通常比显式循环更快。
(三)实操
1. Series 单列操作(字符串处理)
1 import pandas as pd
2 # 创建 Series 数据
3 names = pd.Series(['Alice', 'Bob', 'Charlie'])
4 # 使用 apply() 转换为大写
5 upper_names = names.apply(lambda x: x.upper())
输出:['ALICE', 'BOB', 'CHARLIE']。
2. DataFrame 多列关联处理(条件筛选)
1 # 创建 DataFrame 数据
2 df = pd.DataFrame({
3 '学历': ['本科', '硕士', '博士'],
4 '年龄': [22, 29, 30]
5 })
6 # 自定义函数判断条件
7 def is_eligible(row):
8 return'匹配'if row['学历'] in ['硕士', '博士'] and row['年龄'] > 28else'不匹配'
9 # 使用 apply() 应用函数
10 df['结果'] = df.apply(is_eligible, axis=1)
输出:
学历 年龄 结果
0 本科 22 不匹配
1 硕士 29 匹配
2 博士 30 匹配
```。
3. DataFrame 行向量化操作(统计计算)
1 # 创建 DataFrame 数据
2 df = pd.DataFrame({
3 'A': [1, 2, 3],
4 'B': [4, 5, 6]
5 })
6 # 使用 apply() 计算每行的和
7 row_sums = df.apply(lambda row: row.sum(), axis=1)
输出:[5, 7, 9]。
(四)注意事项
数据类型选择:Series 用法更简单,DataFrame 需指定 axis=1 处理行。
性能优化:raw=True 可提升 ndarray 处理效率,但需注意数据类型转换。
结果格式控制:result_type 参数可控制返回值的 Series/DataFrame 格式。
data.apply() 是 Pandas 数据处理的基石,通过灵活的函数应用实现高效的数据转换和分析。
(无剑境:万事万物皆可为剑,入此境者,上下一心,内外一体,是以无招胜有招,无剑胜有剑)
函数装饰器是Python中一种高级特性,通过在函数调用前后添加额外逻辑实现功能扩展。
(一)基础语法
1 @decorator
2 def func():
3 pass
等价于:
1 func = decorator(func)
(二)优势
语法简洁:使用@decorator语法糖,无需修改原函数代码。
功能增强:支持日志记录、性能监控、权限控制等场景。
底层实现:装饰器本质是高阶函数,接收函数对象返回新函数。
(三)实操
1. 日志记录装饰器
1 import functools
2 # 定义装饰器
3 def logger(func):
4 @functools.wraps(func)
5 def wrapper(*args, **kwargs):
6 print(f"开始执行{func.__name__}")
7 result = func(*args, **kwargs)
8 print(f"结束执行{func.__name__}")
9 return result
10 return wrapper
11
12 # 应用装饰器
13 @logger
14 def add(a, b):
15 return a + b
输出:
开始执行 add
结束执行 add
2. 性能计时装饰器
1 import time
2 # 定义装饰器
3 def timer(func):
4 @functools.wraps(func)
5 def wrapper(*args, **kwargs):
6 start = time.time()
7 result = func(*args, **kwargs)
8 end = time.time()
9 print(f"{func.__name__}耗时{end - start:.4f}秒")
10 return result
11 return wrapper
12
13 # 应用装饰器
14 @timer
15 def slow_task():
16 time.sleep(2)
输出:
slow_task 耗时 2.0001秒
3. 权限控制装饰器
1 # 定义装饰器
2 def admin_required(func):
3 @functools.wraps(func)
4 def wrapper(*args, **kwargs):
5 user = kwargs.get('user')
6 if user != 'admin':
7 raise PermissionError("权限不足")
8 return func(*args, **kwargs)
9 return wrapper
10
11 # 应用装饰器
12 @admin_required
13 def delete_user(user):
14 print(f"删除用户{user}")
输出:
PermissionError: 权限不足
(四)注意事项
functools.wraps:保留原函数元数据(如__name__)。
参数传递:装饰器需支持*args和**kwargs处理任意参数。
嵌套装饰器:多个装饰器时从内到外依次执行。
函数装饰器是Python中代码复用和功能扩展的利器,通过合理运用可显著提升代码可维护性和扩展性。
江湖路远,大道独行,数据如潮,暗流汹涌,诸君且持此秘笈,共赴这没有硝烟的码林之战!
了解及咨询更多质谱多组学技术可以联系欧易生物对应区域销售工程师,或者拨打小欧科服电话17317724501(微信同号)为您解疑答惑哦~
欧易生物简介
Oebiotech
欧易生物是一家致力于为生命科学研究提供多组学技术的研究服务机构,产品涵盖单细胞及时空多组学、基因组学、转录组学、表观组学、蛋白组学、代谢组学、生物信息学以及临床诊断产品开发,秉承以生物科技 成就他人 造福大众」的企业使命,用技术改变生活,用科技造福人类。

欧易生物先后与中国海洋大学、中国科学院遗传与发育生物学研究所等机构建立了紧密的产学研合作,与日立诊断产品有限公司共建联合研发实验室,与华东师范大学合作建立院士专家工作站,并陆续荣获国家级专精特新“小巨人”、上海市科技小巨人企业、上海市专利试点企业、上海市企业技术中心、闵行区研发机构、闵行区科技小巨人企业等资质。还获得知识产权管理体系认证企业资质,总授权发明专利53项、在审发明专利54项、授权软件著作权213项(含欧易生物及旗下子公司,截止至2025年12月)。至今已累计助力客户发表6000+高水平研究论文,累计影响因子40000+;发文期刊包括Nature、Cell、Science等知名期刊。

内容整理:饭团
原创声明:本文由欧易生物(OEBIOTECH)学术团队报道,本文著作权归文章作者所有。欢迎个人转发及分享,未经作者的允许禁止转载。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 开篇|告别办公内耗!Python办公自动化,让你从重复劳动中“解放”自己
- Linux | Docker容器间网络通信
- Linux命令每日一清单027:diff--文件比较命令速查表
- MLIR从Python DSL编译到Dialect的完整流程
- 24天学会Python
- 学习Python,这几张图就够了
- 学会Python,实现财富自由
- Python高阶函数reduce——累积计算的艺术
- 告别重复劳动:用 AI 零基础编写 Python 脚本,保姆级教程实录——整理表格
- 3500 行 Python,竟然跑起了一个 24/7 的 AI Agent 系统:724-office
