1 前言
在前一章节,我们主要介绍了MMU,并探索了ARM的一些寄存器,那么下面我们是可以根据代码来看Linux内存是如何管理的,又是如何工作的。 在此之前,我们需要做的还是一样先了解一些概念,方便我们去看代码,当然笔者会尽量减少代码,以更多的概念与脉络梳理来写该篇文章。因为AI的大模型对于代码的理解可能远远超过我个人,如果各位读者有兴趣知道笔者是如何用AI去读内核代码的也欢迎留言,笔者届时可以专门写一文来介绍。紧跟时代背景去做事情。2 物理内存的管理概念
物理内存管理上,主要是软件抽象以及相应的分布是我们需要知道的基础概念。Flat Memory:物理内存地址连续,这个也是Linux最初使用的内存模型。当内存有空洞的时候也是可以使用该模型,只是strcut page* mem_map数组的大小与物理地址正相关,内存会有空洞造成浪费。
Discontiguous Memory:物理内存存在空洞,随着SparseMemory的提出,这种内存模型被弃用了。
Sparse Memory:物理内存存在空洞,并且支持内存热插拔,以section为单位进行管理的。
内存所用的模型可以查看Include/asm-generic/memory_model.h,由内存配置defconfig(如CONFIG_SPARSEMEM_VMEMMAP)可以进行配置。目前kernel基本是采用Sparse Memory。
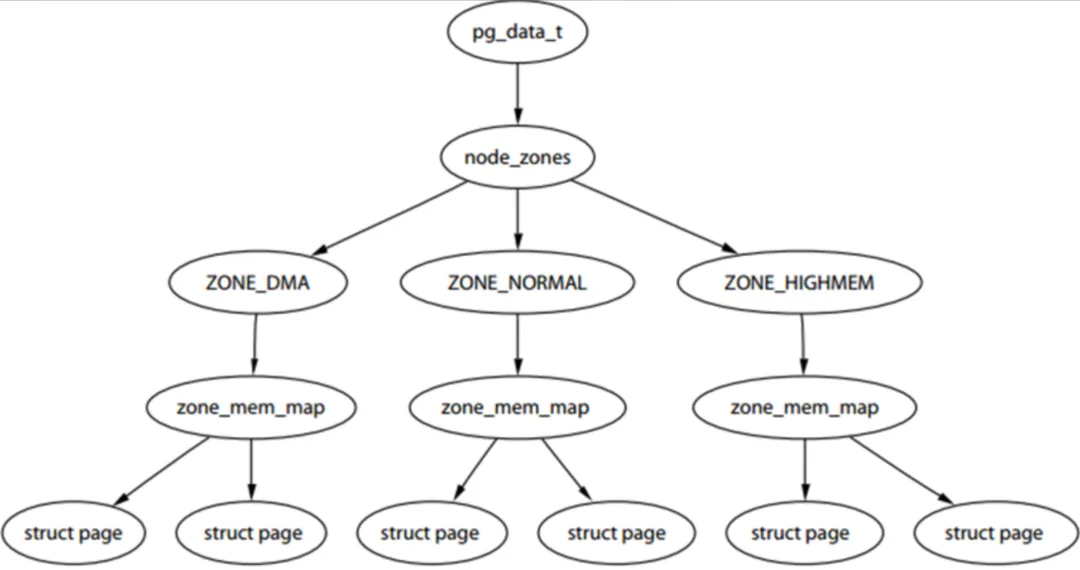
在物理内存中,内存是按照页(逻辑上)来管理的,内核用一个page的结构体来描述一页的物理内存,而一页的物理内存又是由其所在的区域(zone)决定,zone的分布又是由node决定的,因此可以知道物理内存的三级结构:Node、Zone、 Page。
Node(存储节点):CPU被划分为多个节点,内存则被分簇,在每个CPU对应一个本地物理内存,即一个CPU-node对应一个内存簇的bank,那我们认为这个就是一个内存节点,这种多Node的系统一般只有服务器才会有,一般嵌入式只有一个。
Zone(管理区):每个物理内存节点node被划分多个内存管理区域,用于表示不同范围的内存,内存可以使用不同的映射方式映射物理内存
Page(页面)内存被细分为多个页面帧,页面是最基础的页面分配的单位。
简化一点,我们以结构体代表该结构体:
内存被划分为节点,内存的每个节点都是有pg_data_t来描述的,该结构体在include/linux/mmzone.h。然后节点又被划分为内存管理区域,通过struct zone_struct来描述,被定义为zone_t,一般低端范围的16MB被标为ZONE_DMA,可以被直接映射到内核的普通内存域为ZONE_NORMAL,超出内核段的物理地址域为ZONE_HIGHMEM,也统称为高端内存,是系统预留的可用内存空间,不能被内核直接映射,最后就是页帧了(Page Frame),最小的系统内存单位,堆内存中的每个页都会创建一个strcut page的一个实例。
基本上大家了解到了物理内存管理的最小单位是Page。大体内核对于物理内存的管理是这样的。
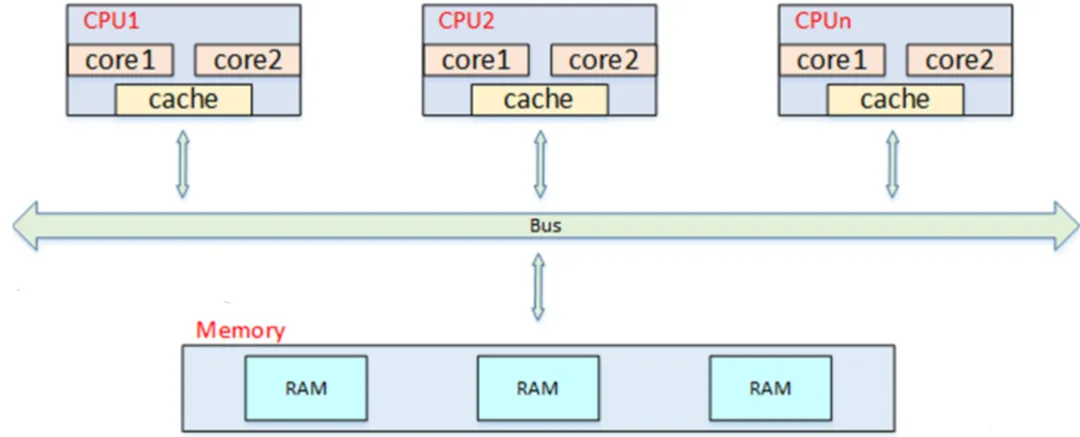
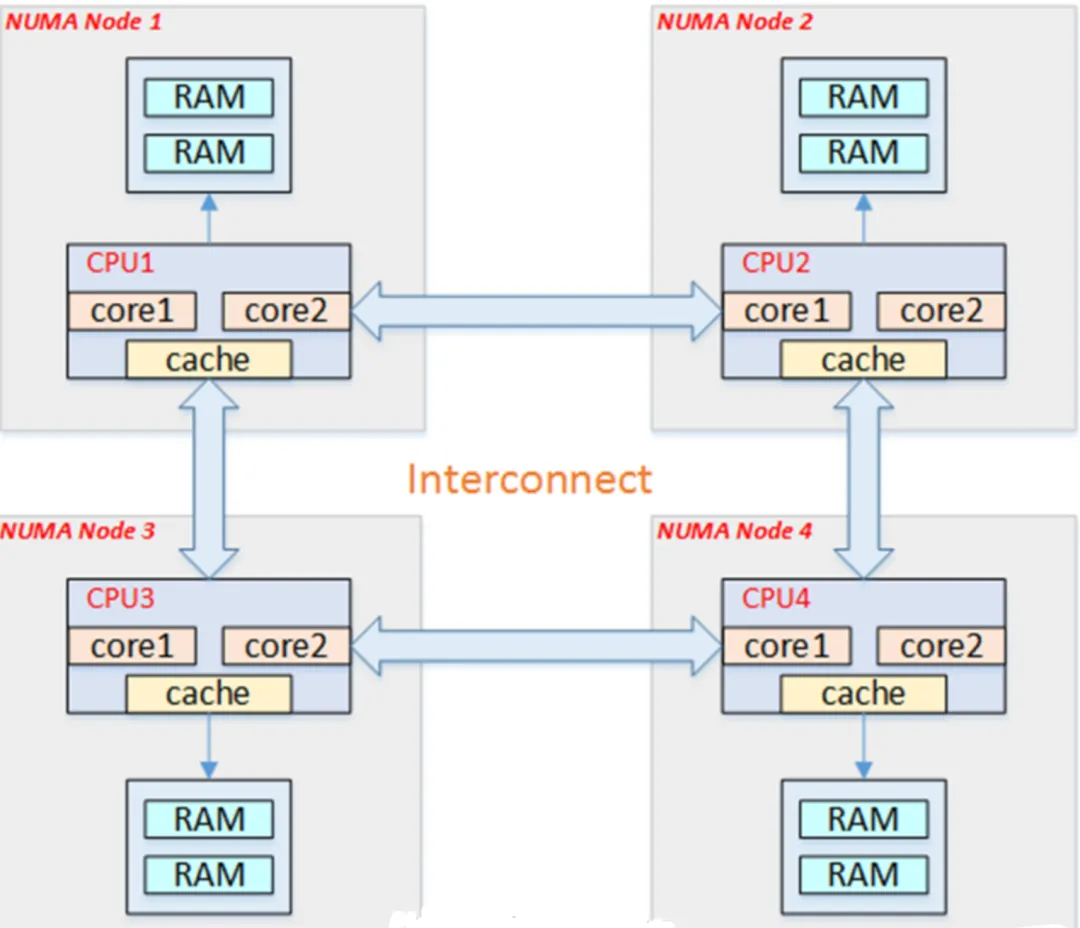
在ARM的架构中,基本采用均匀存储器存取(Uniform-Memory-Access,简称UMA)模型UMA,所有处理器对内存的访问都是一致的。 上图可以看出当处理器的核变多后,我们的内存带宽将反而成为瓶颈。 当然人们肯定是已经想到了这个问题,因此又提出一个非均匀存储器存取(Nonuniform-Memory-Access,简称NUMA)模型,即处理器被划分成多个节点,每个节点被分配本地存储器空间,所有节点中的处理器都可以访问全部的系统物理存储器,但是访问本节点内的存储器所需要的时间,比访问某些远程节点的存储器所花时间少的多,随着芯片封装技术的能力增加,这个模型被用于更多CPU了。此时内存被分割成多个区域(BANK,也称“簇”),依据簇与处理器的“距离”不同,访问不同簇的代码也会不同。大体如下:这样各个cup就有内存直接处理。当然也不说是这个方案就是完美的,当你的核要访问另一个核,那么势必会增加指令的流水线,主要还是要看应用的场景,目前在嵌入式行业中,我们大体都是用UMA的模型哈。
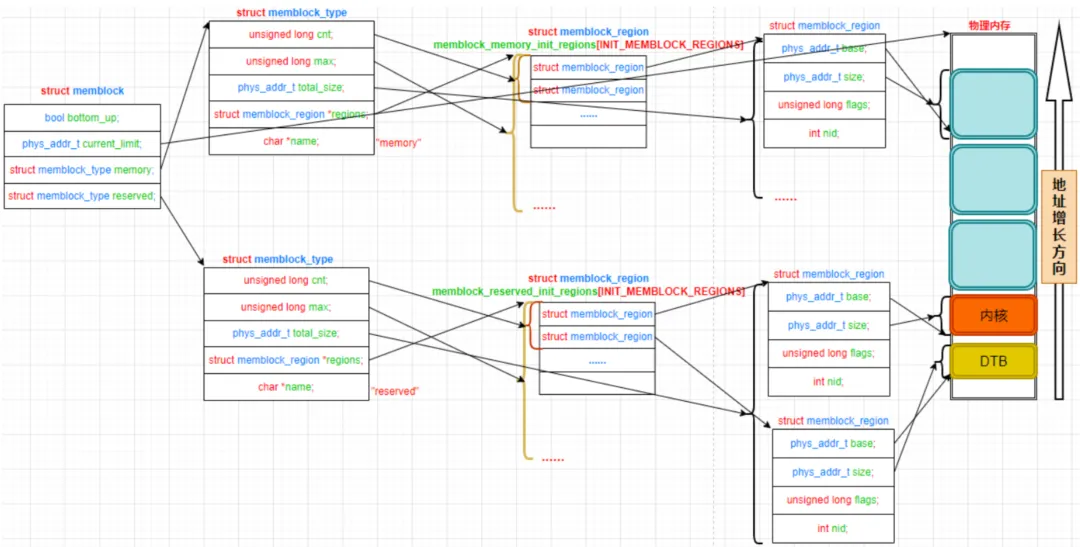
物理内存管理在Linux的不同阶段采用的内存管理方式也是不同的,主要分为memblock与buddy两种。在此,是否有一个疑问,难道buddy系统不能完全管理物理内存吗?其原因在于Linux的前级可能还存在更加前级的系统,比如Uboot。那么在uboot中需要Linux预留一部分的内存等,此时应该如何处理呢?一般用到的就是memblock。它会扣留了一部分内存,直到剩下的可以被我们使用的内存才会轮到buddy系统管理。
memblock其前任为bootmem,不过bootmem已经退休,目前全部都由memblock来完成。而memblock顾名思义,就是内存被分为一块一块的,内核以memblock_region的结构体表示一块,它的base和size字段分别表示块的起始地址和大小。memblock_type分为memory(可用内存)与reserved(被预留的内存)。
memblock与buddy系统的交接在mem_init中完成,主要标记位after_bootmem变量被置为1,会释放highmem与lowmem到buddy系统中去。后续在分析代码的时候会看到。
3 物理内存的管理
我们可以直接来分析一下内核启动阶段的页表创建过程,显然,在内核启动初期时没有开启MMU的,在这之前必须先把页表映射做好(这里创建的页表是个临时页表,在后面会被真正的页表替换),开启MMU后,内核才能在运行虚拟地址的时候不会崩溃,主要标记点为swapper_pg_dir,在其完成后才有相应的映射。后续在分析代码的时候,也会看到。记住一些关键点,有助于我们快速记住关键信息点。
3.1 内核的内存分布情况
一般我们看到的内存在ARM32与ARM64表现是有所不同的,我们可以尝试进行一些分析,笔者这边主要是要分析ARM64,ARM32也有设备,但基本都是公司在用,实在不方便透露,狗头保命。[ 0.000000] Memory: 412628K/430080K available (5120K kernel code, 756K rwdata, 1956K rodata, 5120K init, 292K bss, 17452K reserved, 0K cma-reserved, 0K highmem)[ 0.000000] Virtual kernel memory layout:[ 0.000000] vector : 0xffff0000 - 0xffff1000 ( 4 kB)[ 0.000000] fixmap : 0xffc00000 - 0xfff00000 (3072 kB)[ 0.000000] vmalloc : 0x9b800000 - 0xff800000 (1600 MB)[ 0.000000] lowmem : 0x80000000 - 0x9b000000 ( 432 MB)[ 0.000000] pkmap : 0x7fe00000 - 0x80000000 ( 2 MB)[ 0.000000] modules : 0x7f000000 - 0x7fe00000 ( 14 MB)[ 0.000000] .text : 0x80008000 - 0x80600000 (6112 kB)[ 0.000000] .init : 0x80800000 - 0x80d00000 (5120 kB)[ 0.000000] .data : 0x80d00000 - 0x80dbd2c4 ( 757 kB)[ 0.000000] .bss : 0x80dbd2c4 - 0x80e062d0 ( 293 kB)
以上打印主要在mem_init()的函数来实现。把上面的日志放到千问中,你可以很快得到相应的信息:
总物理内存: 430080K (约 420 MB)可用内存 (Available): 412628K (约 403 MB)这意味着内核启动时就占用了约 17MB (430080 - 412628)。保留内存 (Reserved): 17452K (约 17 MB)这部分内存被硬件(如视频编解码器、显示缓冲区等)直接占用,内核无法使用。Lowmem (低端内存): 0x80000000 - 0x9b000000 (432 MB)所有的 420MB 物理内存都位于 Lowmem 区域。Highmem: 0K highmem。系统没有启用高端内存。这意味着所有内存都可以被内核直接映射,不需要复杂的映射机制,这对性能有利,但也意味着内核数据结构(如 struct page)会占用一部分 Lowmem。Vmalloc 空间: 1600 MB内核自身占用:Kernel Code (.text): 6112 KB (~6 MB)Init (.init): 5120 KB (~5 MB) -> 注意:内核启动完成后,这部分内存通常会被释放回收。Data (.data + .bss): ~1 MBRWData/ROData: ~2.7 MB
大大增加了我们分析内核分布的效率。言归正传,这里的虚拟内存1.6GB的映射空间,其中有一部分用于直接映射物理内存地址,这个区域被称为线性映射区(Normal Memory)。这里是直接将420MB可以线性映射了,不用太多的纠结,这一部分内存会被线性映射到【3GB:3GB+760MB】的虚拟地址上,虚拟地址与物理地址相差PAGE_OFFSET即3GB。在config生成的数据中可以看到CONFIG_PAGE_OFFSET 0x80000000。这样你就能瞬间找到物理内存与虚拟内存的差值了。
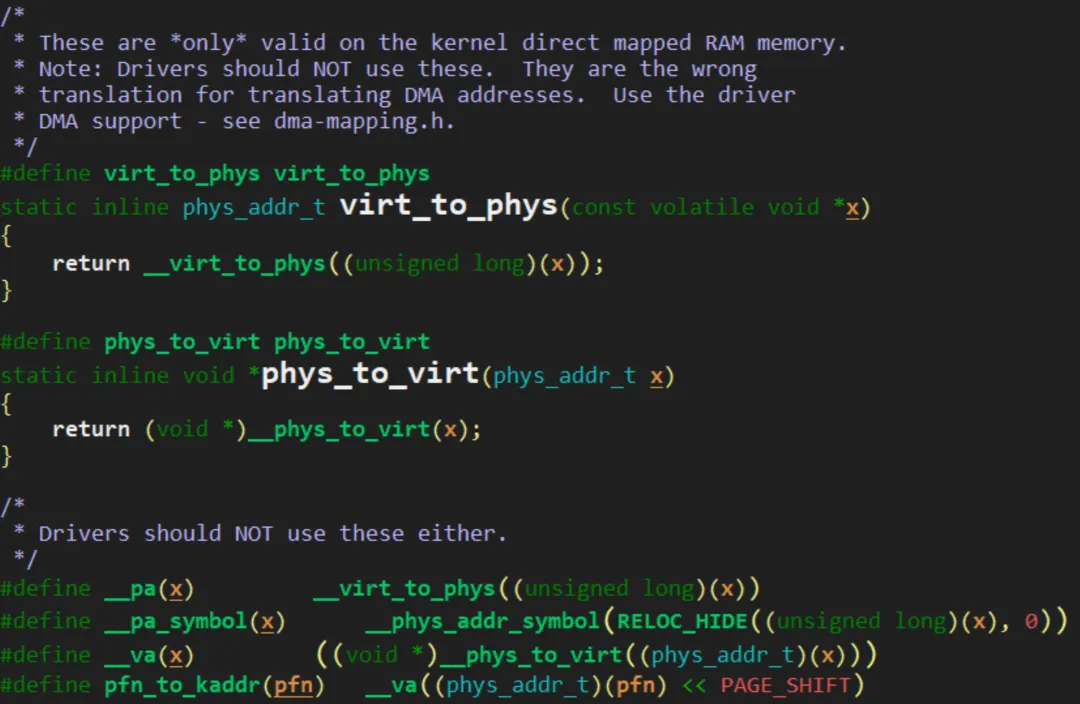
经常在使用的虚拟地址与实际地址转化的函数__pa和__va.
可以知道
__phys_to_virt() 根据物理地址计算线性映射的虚拟地址
__virt_to_phys_nodebug()根据线性映射的虚拟地址计算物理地址
__is_lm_address()用于判断虚拟点至是否为线性映射的虚拟地址
还有一些内核是以设备树来划分的,比如:
在init中的main.c中start_kernel(void)->setup_arch(&command_line)位置在arch/arm/kernel/setup.c->setup_machine_fdt(atags_vaddr); 位置在arch/arm/kernel/devtree.c
->early_init_dt_scan_nodes();位置在driver/of/fdt.c
其主要实现在
/* Setup memory, calling early_init_dt_add_memory_arch */ of_scan_flat_dt(early_init_dt_scan_memory, NULL);
但笔者对照F1S200C这里的设备树这里并没有看到memory的相关信息,不清楚它这里是如何划分的。但sram是看到是由drivers/soc/sunc/sunxi_sram.c来实现的。但这里笔者也没有继续跟踪下去了,主要是这个芯片有点慢,不太适合我们去分析ARM64位,当然后面笔者会继续把这个相应的坑给填了。 草稿写了,就是没整理好。
草稿写了,就是没整理好。
在ARM64的内核中已经取消了相应的虚拟内存分布的打印,因此如果需要打开这个打印需要在arch/arm64/mm/init.c重新添加这些打印。笔者这里的环境换成了ARM64位的RK3576鲁班猫V3,主要是代码比较完整,方便笔者写文章,后续笔者会选择RK3566的板子,尝试自己移植内核将其升级到6.4,主要好奇其多媒体的业务是如何工作的,我看过奔跑吧linux一书,其在上面改了代码,但我编译无法通过,于是尝试着自己去修改相关的代码:
if (PAGE_SIZE >= 16384 && get_num_physpages() <= 128) {extern int sysctl_overcommit_memory;/* * On a machine this small we won't get anywhere without * overcommit, so turn it on by default. */ sysctl_overcommit_memory = OVERCOMMIT_ALWAYS;}+/* Print virtual memory layout information */+pr_notice("Virtual Memory Layout:\n");+pr_notice(" TEXT: 0x%016lx..0x%016lx\n", (unsigned long)_stext, (unsigned long)_etext);+pr_notice(" DATA: 0x%016lx..0x%016lx\n", (unsigned long)_sdata, (unsigned long)_edata);+/* Note: _sbss and _ebss may not be available in all kernel versions */+pr_notice(" INIT: 0x%016lx..0x%016lx\n", (unsigned long)__init_begin, (unsigned long)__init_end);+pr_notice(" MEMORY: 0x%016lx..0x%016lx\n", (unsigned long)PAGE_OFFSET, (unsigned long)high_memory);+#ifdef CONFIG_COMPAT+ pr_notice(" COMPAT: 0x%016lx..0x%016lx\n", 0UL, (unsigned long)TASK_SIZE_32);+#endif+pr_notice(" TASK_SIZE: 0x%016lx\n", (unsigned long)TASK_SIZE);
但并未有打印出相关的打印,这块不知道有没有友友们来说明一下。后续待笔者自己研究一下哈。
但没关系,在ARM64的日志其实已经换成了:
[ 2.765526] Memory: 3956320K/4175872K available (22784K kernel code, 3776K rwdata, 7780K rodata, 7616K init, 719K bss, 203168K reserved, 16384K cma-reserved)[ 2.765649] SLUB: HWalign=64, Order=0-3, MinObjects=0, CPUs=8, Nodes=1
这样的打印,这里可以知道鲁班猫提供的Memory,这里主要讲一下init,主要是7616K,其这个主要包含.init.text,init.data与初始页表。那么它是如何来的呢?
代码段、init段、数据段都是在arch/arm64/kernel/vmlinux.ld.S中可以看到其是如何构造的。比如init段:
__init_begin = .;__inittext_begin = .;.......__initdata_end = .;__init_end = .;
这段就是init段的代码,其大致为:
[ 开始地址 ] | +-- __init_begin | +-- 初始化代码 (INIT_TEXT) -> 启动后释放 | +-- 退出代码 (.exit.text) | +-- 替代指令表 (.altinstructions) | +-- 初始页表 (init_idmap_pg_dir) -> 启动后释放 | +-- 初始化数据 (.init.data) -> 启动后释放 | +-- 退出数据 (.exit.data) | +-- 重定位信息 (.rela, .relr) | +-- __init_end / __initdata_end |[ 结束地址 ]
大家完全可以把相关的代码放到千问中直接询问。
3.2 MMU的实操
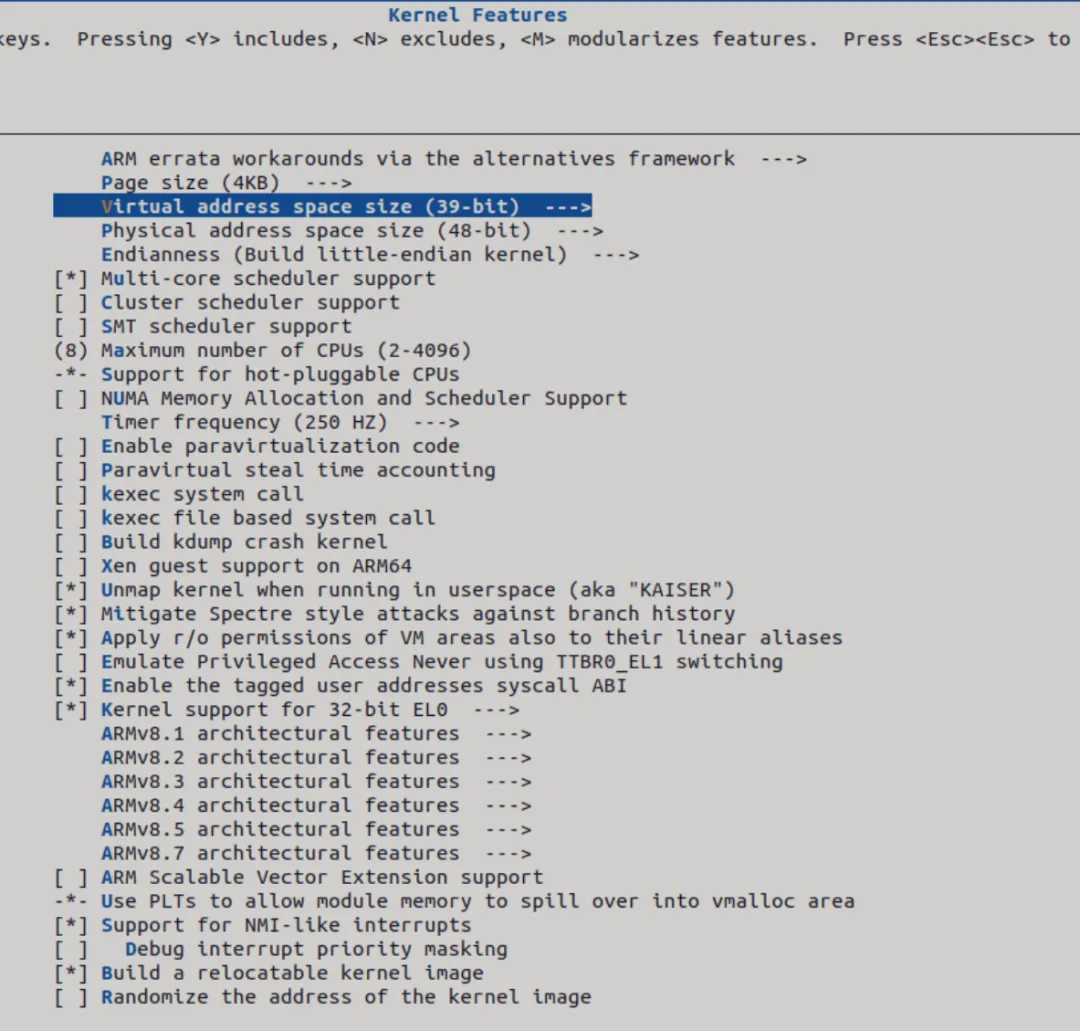
在上一章,我们有说到有关MMU,里面介绍了相应的页表项,那么在鲁班猫3中是如何的呢?在AARCH64架构中会有L0~L3页表项的描述符格式完全不一样,其中L0~L2一般可以分为3类,即无效类页表项、块类页表项、页表类页表项。 在ARMV8-A架构的处理器是通过ARM64_VA_BITS宏来设置虚拟地址的宽度
可以看到鲁班猫是39位的最大虚拟地址,物理地址宽度为48位,PageSize是4K
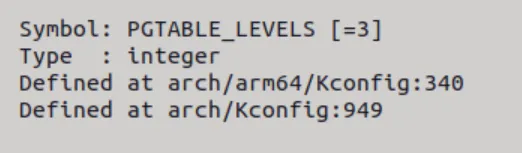
再来看一下PGTABLE_LEVELS
可以看到其是进行了3级映射。
可以看到对应PAGE_SHIFT为12。这里比较要注意的是CONFIG的选项和32位系统差别还是很大的。
总结其使用ARM64_VA_BITS_39,ARM64_4K_PAGE,默认使用3级页表。
3.2.1 分页模式简介与鲁班猫的分页分析
ARM64中的Linux的分页模式分别为页全局目录(Page Global Directory,PGD)、页上级目录(Page Upper Directory,PUD)、页中间目录(Page Middle Directory,PMD)、页表(Pega Table,PT)
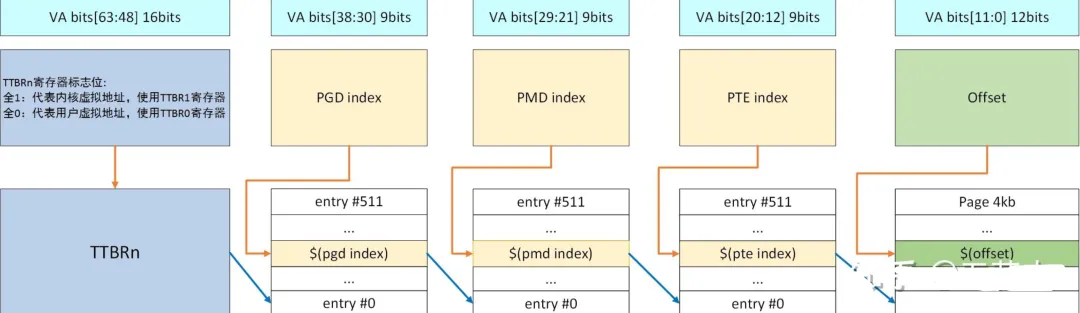
这样ARM64在MMU的虚拟地址中就可以这样表示
|63---------------------4847----3938-----3029----2120----1211-----------------||------------------------|--PGD--|--PUD--|--PMD--|--PT----|--页面内偏移量--|
在Documentation/arm64/memory.rst中就有如下描述:
Translation table lookup with 4KB pages:: +--------+--------+--------+--------+--------+--------+--------+--------+ |63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0| +--------+--------+--------+--------+--------+--------+--------+--------+ | | | | | | | | | | | v | | | | | [11:0] in-page offset | | | | +-> [20:12] L3 index | | | +-----------> [29:21] L2 index | | +---------------------> [38:30] L1 index | +-------------------------------> [47:39] L0 index +-------------------------------------------------> [63] TTBR0/1Translation table lookup with 64KB pages:: +--------+--------+--------+--------+--------+--------+--------+--------+ |63 56|55 48|47 40|39 32|31 24|23 16|15 8|7 0| +--------+--------+--------+--------+--------+--------+--------+--------+ | | | | | | | | | v | | | | [15:0] in-page offset | | | +----------> [28:16] L3 index | | +--------------------------> [41:29] L2 index | +-------------------------------> [47:42] L1 index (48-bit) | [51:42] L1 index (52-bit) +-------------------------------------------------> [63] TTBR0/1
因此在鲁班猫上当CONFIG_PGTABLE_LEVELS为3级页表时,没有PUD。只有PGD->PMD->PTE这三级页表。为什么这么说,大家可以看arch/arm64/include/asm/pgtable-hwdef.h中有定义,只有大于3的时候才会有PUD的定义使能。
代码如下:
/* PAGE_SHIFT determines the page size */#define PAGE_SHIFT CONFIG_ARM64_PAGE_SHIFT#define PAGE_SIZE (_AC(1, UL) << PAGE_SHIFT)#define PAGE_MASK (~(PAGE_SIZE-1))#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)#define PGDIR_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(4 - CONFIG_PGTABLE_LEVELS)//表示PGD页表在虚拟地址中的起始偏移量#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)//表示PGD页表项所能映射的区域大小#define PGDIR_MASK (~(PGDIR_SIZE-1)) //用于屏蔽虚拟地址中的PMD PTE索引的字段的#define PTRS_PER_PGD (1 << (VA_BITS - PGDIR_SHIFT)) //表示PGD页表中页表项的个数
把配置(ARM64_VA_BITS_39,ARM64_4K_PAGE, PGTABLE_LEVELS=3)代入计算,我们把结果汇总成一个表格,这个表格也就是代码中来的。
| | |
| | |
| | |
| ARM64_HW_PGTABLE_LEVEL_SHIFT(0) | |
| ARM64_HW_PGTABLE_LEVEL_SHIFT(1) | |
| ARM64_HW_PGTABLE_LEVEL_SHIFT(2) | |
| ARM64_HW_PGTABLE_LEVEL_SHIFT(3) | |
| PGDIR_SHIFT ((12-3)*(4-(4-3))+3 | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
| | |
因而大致可以画出
而PTE又在这里有许多属性,如以下代码,在asm/pgtable-hwdef.h中对PTE的定义是X86的,而在pgtable-prot.h中是ARM64的。
include <asm/memory.h>#include<asm/pgtable-hwdef.h>#include<linux/const.h>/* * Software defined PTE bits definition. */#define PTE_WRITE (PTE_DBM) /* same as DBM (51) *///表示该页面为脏页#define PTE_SWP_EXCLUSIVE (_AT(pteval_t, 1) << 2) /* only for swp ptes */#define PTE_DIRTY (_AT(pteval_t, 1) << 55)//表示该页面是脏的#define PTE_SPECIAL (_AT(pteval_t, 1) << 56)#define PTE_DEVMAP (_AT(pteval_t, 1) << 57)#define PTE_PROT_NONE (_AT(pteval_t, 1) << 58) /* only when !PTE_VALID */
而在同级的pgtabel.h中:
/* * The following only work if pte_present(). Undefined behaviour otherwise. */#define pte_present(pte) (!!(pte_val(pte) & (PTE_VALID | PTE_PROT_NONE)))//判断该页是否在内存中#define pte_young(pte) (!!(pte_val(pte) & PTE_AF))//判断该页是否被访问过#define pte_write(pte) (!!(pte_val(pte) & PTE_WRITE))//判断该页是否具有可写属性#define pte_hw_dirty(pte) (pte_write(pte) && !(pte_val(pte) & PTE_RDONLY))//判断判断该页是否被硬件设置为脏页#define pte_sw_dirty(pte) (!!(pte_val(pte) & PTE_DIRTY))//判断该页是否被软件设置为脏页#define pte_dirty(pte) (pte_sw_dirty(pte) || pte_hw_dirty(pte))//判断该页是否被写入过
这样还有许多的函数,这些都在pgtabel.h中
函数 | 说明 |
clear_pte_bit | 清除页表项的标志位 |
set_pte_bit | 设置页表项的标志位 |
pte_wrprotect | 设置写保护 |
pte_mkwrite | 使能可写属性 |
基本这些函数会被arch/arm64/mm中的pageattr.c调度到用于更改页面的属性。到后面去看mm/memory.c中的一些实现就能看到调度set_pte_at进行页面属性的硬件配置。这里先不一一讲解了,后续还会碰到。
3.3 Linux内核内存初始化与恒等映射
Linux的内核初始化主要是在arch/arm64kernel/head.S中汇编实现的,这个文件是在系统上复位后,经过启动引导程序(Bootloader)或者BIOS的初始化,最终会跳转到Linux内核的入口函数(stext汇编函数)。在ARMv8中是支持虚拟化中拓展的EL2和安全模式EL3,这些等级主要是用于切换Linux内核的运行模式的。而在head.S中主要描述内核关于入口的约定。/* * Kernel startup entry point. * --------------------------- * * The requirements are: * MMU = off, D-cache = off, I-cache = on or off, * x0 = physical address to the FDT blob. * * Note that the callee-saved registers are used for storing variables * that are useful before the MMU is enabled. The allocations are described * in the entry routines. */
关闭所有的DMA设备,将X0指向设备树入口X1,X2,X3全部置为0,CPU需要屏蔽所有的中断,并且处于EL2或者非安全模式的EL1下,MMU关闭,数据高速缓存全部关闭。 主要是数据高速缓存会保留Uboot中一些数据。总体来说这些要求就是为了交接的时候,数据不会出错。 b primary_entry // branch to kernel start, magic
主要任务是在开启 MMU(内存管理单元)和跳转到 C 语言入口之前,完成最底层的硬件初始化和环境准备。其中的ARMv8的寄存器此时:
x20: 保存 CPU 的启动模式(Boot Mode)。
x21: 保存设备树(FDT/DTB)的物理地址指针(这是 Bootloader 传递给内核的参数)。
x22: 保存设备树在 ID 映射中的虚拟地址。
x23: 保存物理地址的错位值或 KASLR(内核地址空间布局随机化)的偏移量。
x24: 用于线性映射的 KASLR 种子。
x25: 保存支持的虚拟地址(VA)位宽。
x28: 在创建 ID 映射时用作临时寄存器。
SYM_CODE_START(primary_entry) bl preserve_boot_args// 保存 Bootloader 传递过来的参数(如设备树指针),确保它们不会在后续操作中被覆盖。 bl init_kernel_el // w0=cpu_boot_mode ARMv8 支持不同的异常级别(EL0-EL3)。此函数确保 CPU 处于正确的异常级别(通常是 EL1)来运行内核。 mov x20, x0 //将init_kernel_el 返回的 CPU 启动模式保存到 x20 寄存器中 bl create_idmap /创建“恒等映射”(Identity Map)。此时 MMU 尚未开启,CPU 使用的是物理地址。为了让开启 MMU 后能继续执行代码,必须建立一套虚拟地址等于物理地址的页表/* * The following calls CPU setup code, see arch/arm64/mm/proc.S for * details. * On return, the CPU will be ready for the MMU to be turned on and * the TCR will have been set. */#if VA_BITS > 48 mrs_s x0, SYS_ID_AA64MMFR2_EL1 tst x0, #0xf << ID_AA64MMFR2_EL1_VARange_SHIFT mov x0, #VA_BITS mov x25, #VA_BITS_MIN csel x25, x25, x0, eq mov x0, x25#endif bl __cpu_setup // initialise processor b __primary_switchSYM_CODE_END(primary_entry)
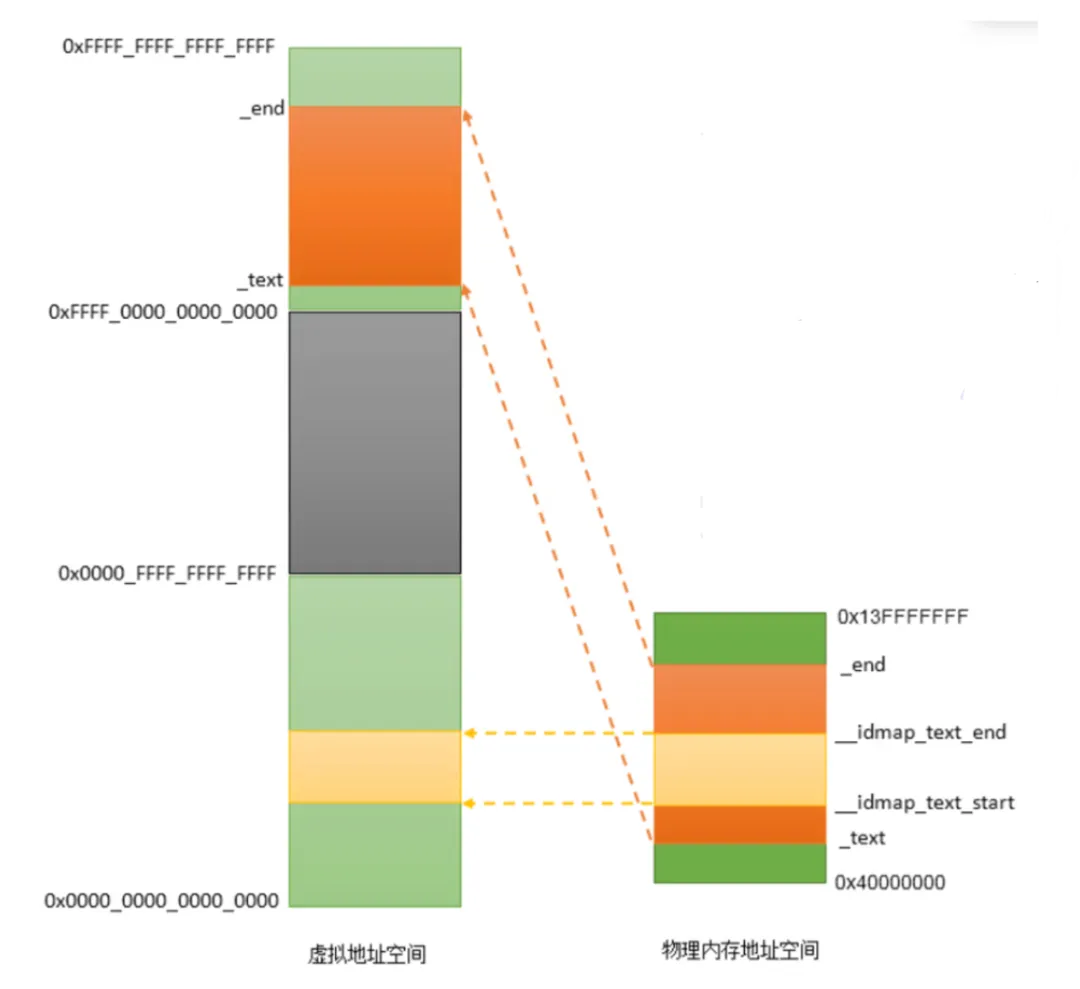
在这里我们需要重点分析create_idmap,它跟我们的内存息息相关。此时可以直接跳转到arch/arm64/mm/mmu.c:
static void __initcreate_idmap(void){ u64 start = __pa_symbol(__idmap_text_start);//获取__idmap_text_start的物理地址 u64 size = __pa_symbol(__idmap_text_end) - start;//需要恒等映射的代码段范围 pgd_t *pgd = idmap_pg_dir;//这是用于恒等映射的顶级页表(PGD)的基地址 u64 pgd_phys;/* check if we need an additional level of translation *//*如果当前的配置(如 4KB 页面,39位 VA)导致顶级页表(PGD)不足以直接覆盖所需的地址范围, 代码会动态分配一个新的页表级。*/if (VA_BITS < 48 && idmap_t0sz < (64 - VA_BITS_MIN)) { pgd_phys = early_pgtable_alloc(PAGE_SHIFT);//early_pgtable_alloc一个早期的内存分配器,用于在 C 环境初始化之前分配页表内存。 set_pgd(&idmap_pg_dir[start >> VA_BITS], __pgd(pgd_phys | P4D_TYPE_TABLE)); pgd = __va(pgd_phys); } __create_pgd_mapping(pgd, start, start, size, PAGE_KERNEL_ROX, early_pgtable_alloc, 0);//创建核心恒等映射pgd:页表根目录 start, start:第一个 start 是虚拟地址,第二个 start 是物理地址。两者相同,因此称为“恒等映射”。size:映射区域的大小。PAGE_KERNEL_ROX:设置内存属性为“内核只读可执行”。这是为了安全,因为这段代码在开启 MMU 后只需要被执行,不需要被修改。//__create_pgd_mapping:这是一个通用的页表构建函数,它会遍历页表层级,分配必要的中间页表页,并填入最终的映射条目。 /*处理 KPTI 特殊情况 这是一个针对安全特性的补丁: KPTI:即“内核页表隔离”,用于防御 Meltdown 漏洞。它会在用户态(EL0)时卸载内核页表。 __idmap_kpti_flag:这是一个同步标志,用于在切换页表时协调 CPU 状态。 特殊映射:由于这个标志需要在恒等映射环境下被修改(用于同步),因此必须给它单独建立一个可读写(PAGE_KERNEL)的恒等映射。如果不这样做,当切换到恒等映射页表时,CPU 将无法更新这个标志,导致死锁或崩溃。 */if (IS_ENABLED(CONFIG_UNMAP_KERNEL_AT_EL0)) {extern u32 __idmap_kpti_flag; u64 pa = __pa_symbol(&__idmap_kpti_flag);/* * The KPTI G-to-nG conversion code needs a read-write mapping * of its synchronization flag in the ID map. */ __create_pgd_mapping(pgd, pa, pa, sizeof(u32), PAGE_KERNEL, early_pgtable_alloc, 0); }}
其中__idmap_text_start可以在vmlinux.ld.S找到。
__create_pgd_mapping函数的层层调用就不说了。大致上可以画出以下图:
其主要目的是在__enable_mmu启动之前,能够平滑过渡。
OK,基本此时我们已经可以看到内存的工作情况了,在完成恒等映射后,平滑过渡掉这段没有MMU的时代,后面的操作就非常符合基础的运行状态了。
一般来讲,在设备树中可以进行相应的memblock的获取,其主要函数为early_init_dt_add_memory_arch()。其主要指向memblock_add()这个函数进行工作的。大体可以看到这个:这里的memblock的子系统,笔者准备写一个代码即在uboot中抓取相关的数据,然后在Linux中能够保护起来后,再将保护起来的内存释放到正常的内存中的一个实际案例。这样可以清晰的理解memblock的作用。非常感谢你能看到这里,你的关注、点赞与评论是我写文章的巨大动力!请点点关注,感恩每一位读者。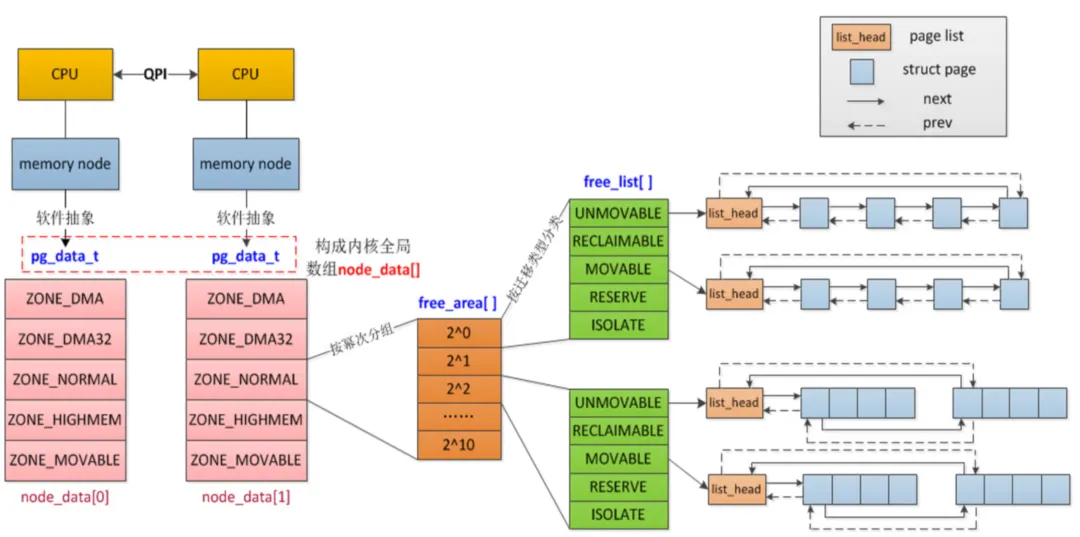


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
