Python实战:DrissionPage 一键查询商品历史价格
- 2026-07-03 16:58:42
本文作者:丁晨璐,河南大学高级金融学院
本文编辑:赵语涵
技术总编:兰博文
Stata and Python 数据分析
爬虫俱乐部Stata数据处理与实证研究实战、Python基础编程与文本分析进阶课程可在小鹅通平台查看,欢迎大家多多支持订阅!如需了解详情,可以通过课程链接(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或课程二维码进行访问哦~


当我们在京东、天猫等电商平台购物时,常常会担心一个问题:现在买是不是最便宜的时候?
很多商品的价格都会随着促销活动不断变化,如果没有参考历史价格,很容易在“价格高点”买入。为了避免买贵,不少人都会借助价格查询工具,比如喵喵折,来查看商品的历史价格走势,从而判断当前价格是否值得入手。
不过,如果我们想批量查询多个商品的历史价格,手动一个一个输入商品链接显然效率很低。
那么,今天小编就带大家利用Python的DrissionPage自动化工具,实现一个一键采集喵喵折商品历史价格的小脚本,只需输入商品链接,程序就可以自动查询并获取对应的历史价格数据,大大提高数据采集效率。

自动登录

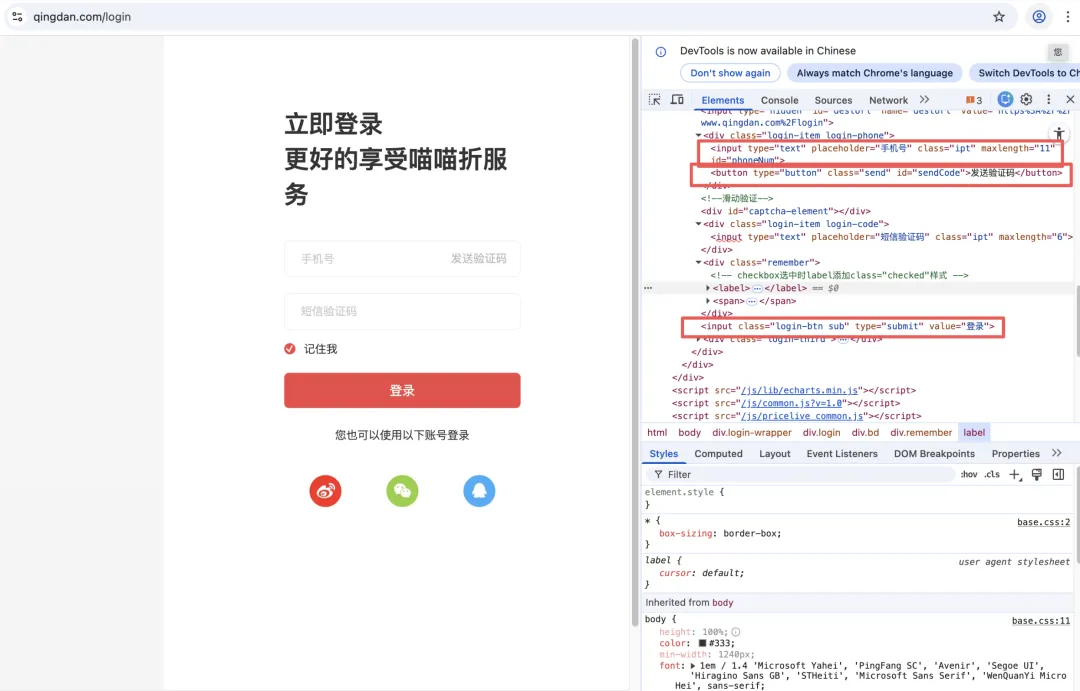
我们先打开喵喵折网站的登录页面,并且左键打开检查:
可以看到喵喵折网站强制要求使用“手机号 + 短信验证码”的形式,并且在输入手机号之后,还需要通过阿里云滑块来拼图验证,才能发送验证码,因此在首次登陆时我们可以让DrissionPage帮我们填手机号、点击发送验证码,然后程序暂停,等我们看手机并且手动把验证码输入至控制台,首次登录成功后,保存cookie文件,之后就可以自动登录啦。
通过观察右侧的代码结构,我们可以精准提取出以下元素的特征:
手机号输入框 id 为 'phoneNum',发送验证码按钮 id 为 'sendCode',最下方的红色登录按钮 value 为 '登录'。
我们可以用这三个属性精准定位这几个关键元素,然后配合 DrissionPage 对其进行输入数据和点击操作。
代码实现:
#导入所有需要用到的包import jsonimport timeimport csvimport matplotlib.pyplot as pltfrom DrissionPage import ChromiumPage, ChromiumOptions# 配置Mac下的Chrome路径和自动分配端口co = ChromiumOptions()co.set_browser_path('/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')co.auto_port()# 启动浏览器page = ChromiumPage(addr_or_opts=co)# 跳转到登录页面page.get('https://www.qingdan.com/login')# 定位手机号输入框并输入手机号 (改成你自己的手机号)page.ele('#phoneNum').input('150xxxxxxxxx')# 点击发送验证码按钮page.ele('#sendCode').click()# 暂停程序,等你手动过滑块,并在控制台敲入手机短信验证码sms_code = input('请手动完成滑块,并在这里输入收到的6位短信验证码: ')# 定位验证码输入框并输入page.ele('@placeholder=短信验证码').input(sms_code)# 定位并点击红色的登录按钮page.ele('@value=登录').click()# 强制等5秒,给网页充足的时间跳转到首页time.sleep(5)# 获取登录后的所有cookie并转为字典格式cookies = page.cookies().as_dict()# 将cookie写入本地json文件with open('miaomiaozhe_cookies.json', 'w', encoding='utf-8') as f:json.dump(cookies, f, ensure_ascii=False, indent=4)print('登录完成,Cookie保存成功')

对于程序来说,这一步其实就是模拟浏览器打开目标页面并完成页面跳转。在使用DrissionPage时,我们可以通过page.get() 方法直接访问目标网址,当页面加载完成后,程序就可以继续对页面中的元素进行定位和数据提取。
代码实现:
# 重新配置并启动浏览器co = ChromiumOptions()co.set_browser_path('/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')co.auto_port()page = ChromiumPage(addr_or_opts=co)# 首先访问网站首页page.get('https://www.qingdan.com/')# 读取cookie文件withopen('miaomiaozhe_cookies.json', 'r', encoding='utf-8') as f:cookies_dict = json.load(f)page.set.cookies(cookies_dict)# 刷新页面page.refresh()# 跳转查价页面page.get('https://www.qingdan.com/pricehistory')page.wait.load_start()print("免密登录成功,已经顺利进入查价页面")

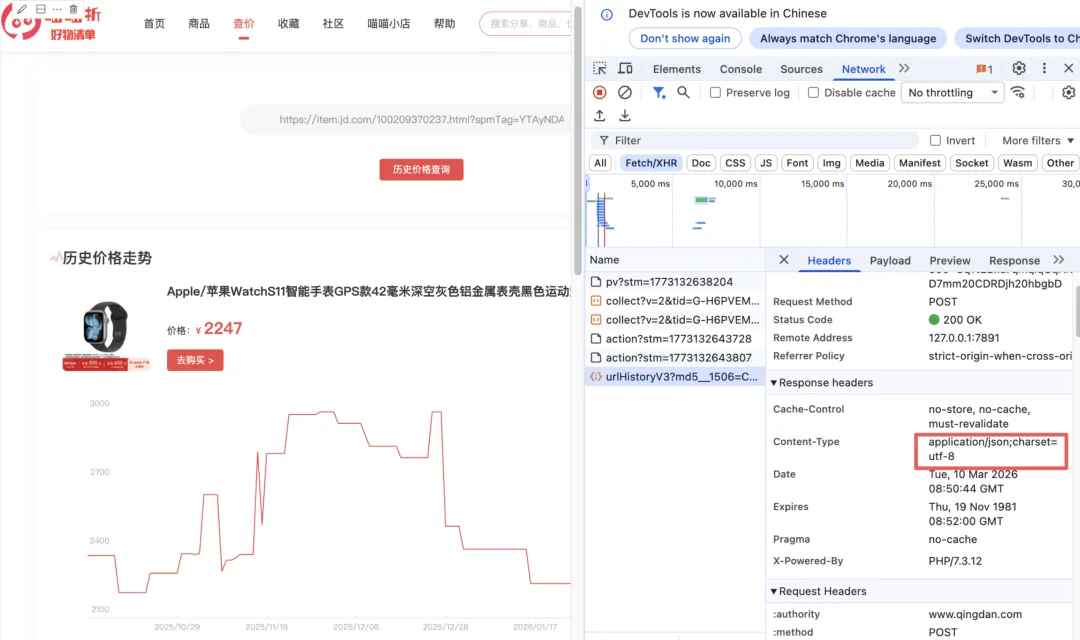
通过对网页查价过程的分析发现,页面的历史价格折线图实际上是由后台传回的JSON数据包动态渲染而成的。因此我们不需要去费力解析复杂的网页元素,而是可以直接利用监听功能来“截胡”这部分底层数据。实现起来也很简单,只需要在用代码模拟输入链接并点击“历史价格查询”按钮之前,提前开启针对该网站的网络监听。一旦程序捕获到后台返回的纯净字典格式数据包,我们就可以直接将里面的历史价格提取出来,完美避开了复杂的网页结构和各种反爬限制。最后我们将解析到的数据写入到csv文件中保存下来。
代码实现:
# 准备要查询的商品链接(可替换)item_url = 'https://item.jd.com/100209370237.html?spmTag=YTAyNDAuYjAwMjQ5My5jMDAwMDQwMjcuMSUyM3NrdV9jYXJk'# 找到页面输入框并把新链接填进去page.ele('@placeholder^请输入商品链接').input(item_url)# 开启监听器page.listen.start('qingdan.com')# 定位并点击红色的“历史价格查询”按钮page.ele('text=历史价格查询').click()print(f"已开始查询新商品,正在拦截后台传回的数据包...")# 等待并抓取数据包for i in range(5):packet = page.listen.wait(timeout=3)if packet and 'application/json' in packet.response.headers.get('Content-Type', ''):# 将数据包转为Python字典data = packet.response.body# 提取带有日期的价格列表price_list = data['data']['pcinfo']['info']# 将提取出的列表写入CSV文件filename = '新商品历史价格.csv'with open(filename, 'w', encoding='utf-8', newline='') as fp:# 定义两列表头:dt(日期) 和 pr(价格)writer = csv.DictWriter(fp, fieldnames=['dt', 'pr'])writer.writeheader()# 遍历价格列表,写进表格for item in price_list:row_dict = {}row_dict['dt'] = item['dt']row_dict['pr'] = item['pr']writer.writerow(row_dict)break # 写入完成,跳出循环# 停止监听page.listen.stop()
结果如图:
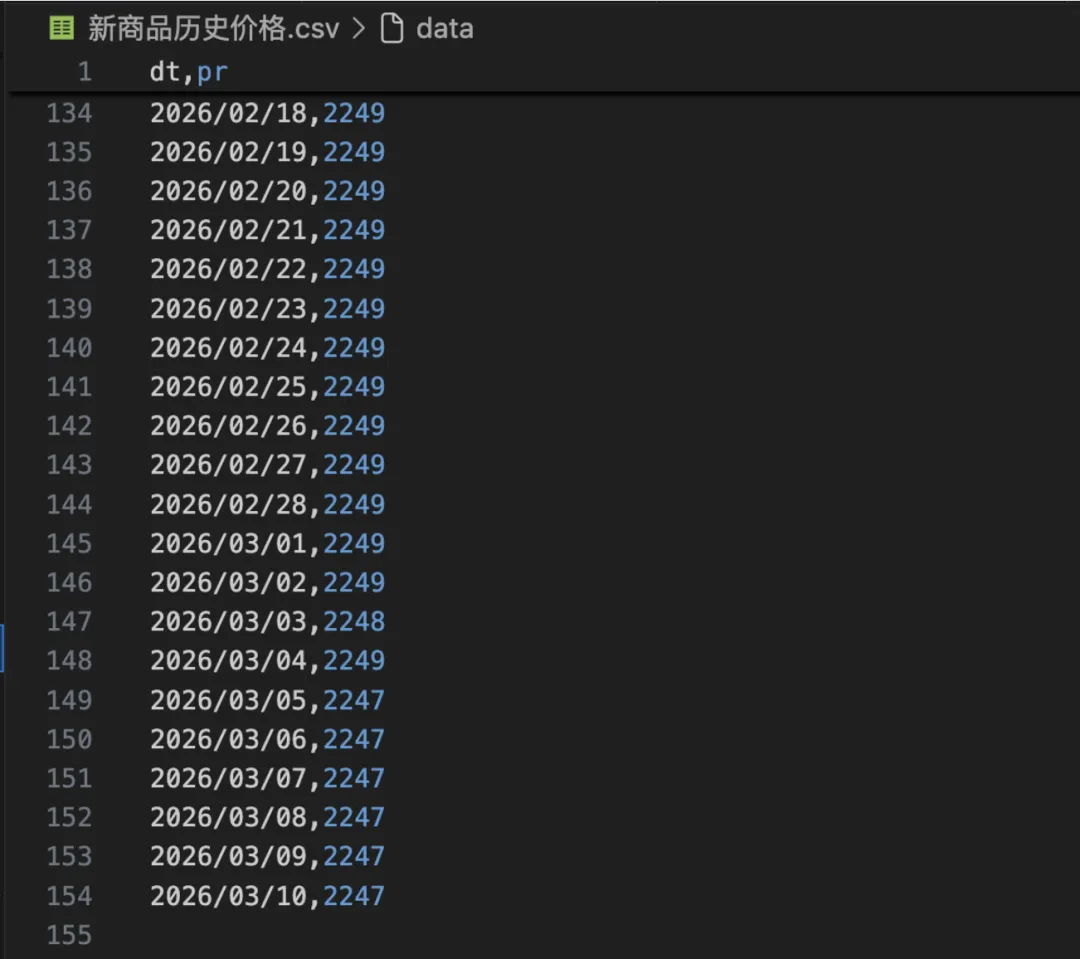

在成功拦截并保存了原始的历史价格数据后,我们可以将其转化为直观的折线图。
代码实现:
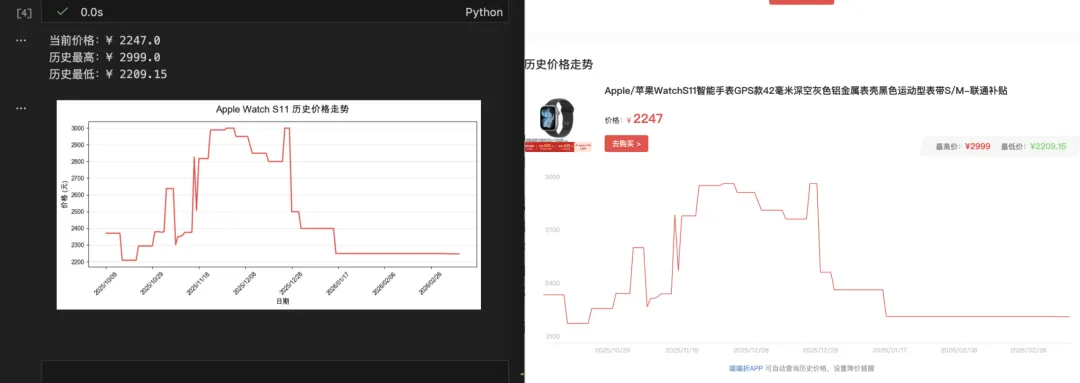
# 从CSV文件中读取日期和价格dates = []prices = []with open('新商品历史价格.csv', 'r', encoding='utf-8') as f:reader = csv.DictReader(f)for row in reader:dates.append(row['dt'])# CSV里读出来的都是字符串,我们要把它转换成浮点数才能比大小和画图prices.append(float(row['pr']))# 找出当前价格、最高价以及最低价current_price = prices[-1] # 列表里的最后一个就是当前价格max_price = max(prices) # 最高价min_price = min(prices) # 最低价print(f"当前价格:¥ {current_price}")print(f"历史最高:¥ {max_price}")print(f"历史最低:¥ {min_price}")# 设置画图字体plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = False# 设置画布大小plt.figure(figsize=(10, 5))# 画折线:传入横坐标(日期)、纵坐标(价格),设置成与喵喵折网站相同的折线颜色并且加粗plt.plot(dates, prices, color='#f54343', linewidth=2)# 添加标题和坐标轴名称plt.title('Apple Watch S11 历史价格走势', fontsize=16, pad=15)plt.xlabel('日期', fontsize=12)plt.ylabel('价格 (元)', fontsize=12)# 每隔20天显示一次横坐标标签,并且倾斜45度plt.xticks(dates[::20], rotation=45)# 加上浅色的横向网格线plt.grid(axis='y', linestyle='--', alpha=0.5)# 自动调整排版并显示图表plt.tight_layout()plt.show()
结果如图,和网站基本一致:

到这里,我们的自动化查价代码就彻底大功告成了!希望这套实用的爬虫思路,不仅能帮你精准看穿各种电商大促“先涨后降”的套路,做到理性消费,更能为你今后探索更多数据自动化采集项目打开一扇新的大门。
声明:代码仅供学习使用,请勿用做任何商业行为!
重磅福利!为了更好地服务各位同学的研究,爬虫俱乐部将在小鹅通平台上持续提供金融研究所需要的各类指标,包括上市公司十大股东、股价崩盘、投资效率、融资约束、企业避税、分析师跟踪、净资产收益率、资产回报率、国际四大审计、托宾Q值、第一大股东持股比例、账面市值比、沪深A股上市公司研究常用控制变量等一系列深加工数据,基于各交易所信息披露的数据利用Stata在实现数据实时更新的同时还将不断上线更多的数据指标。我们以最前沿的数据处理技术、最好的服务质量、最大的诚意望能助力大家的研究工作!相关数据链接,请大家访问:(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或扫描二维码:
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐 Stata中codebook命令介绍及应用
Stata绘制热力图 自动化报告生成:sum2docx与reg2docx深度应用指南 Python库:【Tableau】气候数据可视化 Stata | 从字节串到Unicode:Stata ustrfrom使用手册
Seminar|CEO言行不一,审计师如何“明察秋毫”?——一项关于诚信、审计与公司治理的深度研究
《赌神》 里的发哥能赢赌场?蒙特卡洛模拟:现实里“赌神”赢不了这5.26%”
Python | 别让Emoji毁了你的模型!Python机器学习中的Emoji “神翻译”指南 Stata爬虫——我的数据去哪里了?
python爬虫 | 获取港股基本信息
Stata入门:tempvar命令与tempfile命令详解
Python绘图:用matplotlib库绘制好看的折线图
Seminar | 注意力独特性与企业绩效:增长行动的中介作用
Stata | 从sum2docx到reg2docx——基于《中国工业经济》期刊文章的结果输出 Seminar | 邻避效应:内在动机与企业污染治理
Stata爬取豆瓣读书,一键获取你的读书清单
Seminar | 自动化对企业报告质量的影响
识别处理重复值duplicates命令
Pandas 数据筛选的多种方法
Python交互可视化实战:构建动态数据仪表盘 Stata查看变量信息的三个常用命令 我用 Mermaid 画了《甄嬛传》角色关系图,结果…… 关于我们 微信公众号“Stata and Python数据分析”分享实用的Stata、Python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
我们团队一直为广大用户提供数据采集和分析的服务工作,如果您有这方面的需求,请发邮件到statatraining@163.com。
此外,欢迎大家踊跃投稿,介绍一些关于Stata和Python的数据处理和分析技巧。
投稿邮箱:statatraining@163.com投稿要求:1)必须原创,禁止抄袭;2)必须准确,详细,有例子,有截图;注意事项:1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。 2)邮件请注明投稿,邮件名称为“投稿+推文名称”。3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python ctypes进阶:从qsort到EnumWindows的回调机制全解析
- Linux终端效率神器:10个必会的快捷键技巧
- Python Tkinter之复杂表单处理与校验
- Python操作MySQL数据库:网络安全视角下的增删改查全攻略
- python入门之文件操作
- 少儿编程——Python篇
- 催款催到崩溃?1个Python脚本,1分钟发完100封催款邮件!
- 悬臂梁变形分析研究(Python代码实现)
- Linux远程连接与网络配置的一些记录
- “Python Blood Could Hold the Secret To Healthy Weight Loss” 看完标题你的第一反应是什么?
