 导语:设想这样一个场景:你手头有一份 1000 人的抽奖名单,但因为系统故障,里面有很多重复的名字。老板让你十分钟内把**“实际参与抽奖的独立人数”**整理出来。 如果你用列表配合
导语:设想这样一个场景:你手头有一份 1000 人的抽奖名单,但因为系统故障,里面有很多重复的名字。老板让你十分钟内把**“实际参与抽奖的独立人数”**整理出来。 如果你用列表配合 for 循环挨个比对,不仅代码写得长,运行还慢。
这时候,就轮到 Python 数据结构家族里最低调,但在关键时刻最能打的“去重神器”出场了——它就是集合(Set)。今天,我们就来解锁集合的超能力!
一、 什么是集合(Set)?
💡 核心概念:集合 = 天生自带“去重”光环的容器
集合和我们在初中数学里学过的集合概念一模一样。它有两个最核心的特点:
绝对唯一:集合里绝对不允许出现重复的元素。任何重复的数据丢进去,都会被瞬间“吞”掉,只保留一份。
无序排布:集合里的元素是没有顺序的(所以你不能像列表那样用 [0]、[1] 这种下标去强行抓取它)。
二、 如何“召唤”一个集合?
创建集合通常有两种姿势,让我们来看看这台“去重碎纸机”是怎么工作的。
姿势 1:使用大括号 {}虽然字典也用大括号,但字典是 key: value 成对出现的,而集合里面只是一堆单独的数据。
# 故意放入重复的 4 和 2s1 = {1, 2, 3, 4, 4, 2}print(s1)
运行结果:
{1, 2, 3, 4}(看!多余的 4 和 2 瞬间人间蒸发,只留下独苗。)
姿势 2:使用 set() 魔法函数这是最常用的招式,你可以把一个充满重复数据的列表,直接扔进 set() 里进行“洗礼”。
# 这是一个有重复元素的列表my_list = [10, 20, 20, 30]s2 = set(my_list)print(s2)
运行结果:
{10, 20, 30}
三、 集合的“特异功能”:高阶数学运算
如果集合只会去重,那它还不够强大。集合最牛的地方在于,它完美支持数学里的集合运算!只需一行代码,就能解决极其复杂的业务逻辑。
假设我们有两个兴趣小组的名单:
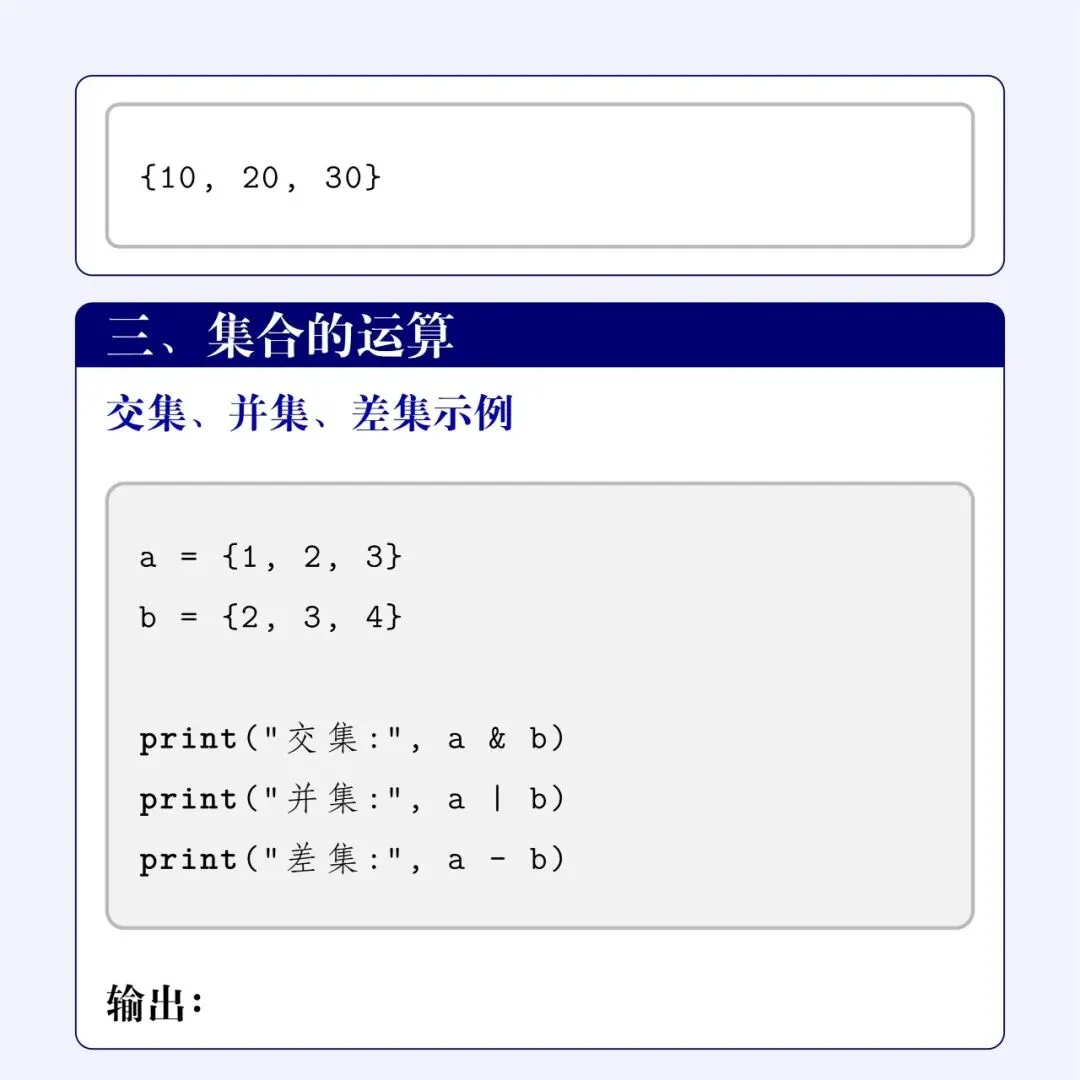
a = {1, 2, 3} # 喜欢打篮球的同学编号b = {2, 3, 4} # 喜欢踢足球的同学编号
1. 找共同好友:交集(Intersection)想知道谁既喜欢篮球又喜欢足球?用 & 符号!
print("交集:", a & b)# 或者使用:a.intersection(b)
输出:交集: {2, 3}
2. 找所有人:并集(Union)想知道两个兴趣小组一共有哪些人(去重后)?用 |(管道符)!
print("并集:", a | b)# 或者使用:a.union(b)
输出:并集: {1, 2, 3, 4}
3. 找特立独行的人:差集(Difference)想知道谁只喜欢打篮球,不喜欢踢足球?用减号 -!
print("差集:", a - b)# 或者使用:a.difference(b)
输出:差集: {1}(解释:从 a 中踢掉那些同时也在 b 里的元素)
四、 集合的黄金应用场景
学了这么多,集合在实际开发中到底能干嘛?
🧹 极速数据去重:处理爬虫抓取的海量数据、清洗用户注册邮箱、合并多份成绩单。
📊 统计唯一种类:一篇文章用了多少个不同的汉字?把它转成 set,然后 len() 一下秒出结果。
🏷️ 标签与权限管理:判断用户是否拥有某项权限(交集),或者给商品打上互不重复的推荐标签(并集)。
⚙️ 复杂数据建模:与之前学的字典(Dict)强强联手,构建更高效的检索系统。
五、 本讲核心心法总结
🛡️ 唯一性:集合天生过滤重复项,是数据清洗的最佳搭档。
🛠️ 操作符:牢记 &(交)、|(并)、-(差)三大神器,代码量省 90%。
⚡ 高效率:集合在底层的查找速度极快,性能远超列表。
核心口诀:集合 = 唯一元素 + 极速运算 + 业务逻辑
我为你整理了一套《Python零基础保姆级教程》,这不只是干巴巴的理论,而是包含:
✅ 完整版 Python 零基础到精通完整代码
✅ 完整注释讲解,一键运行
👇 获取方式:
想要解锁 [Python保姆级教程] 的同学,可以点击下方赞赏支持博主,并在后台留言




 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
