封面
上篇结尾写的是"4.5 倍差距还在,光靠 AI 消耗 token 做不到"。这篇是后续:让 AI 先用 Python 把架构跑通,再翻译成 Verilog, 吞吐量就上来了。
1先回顾一下上次卡在哪
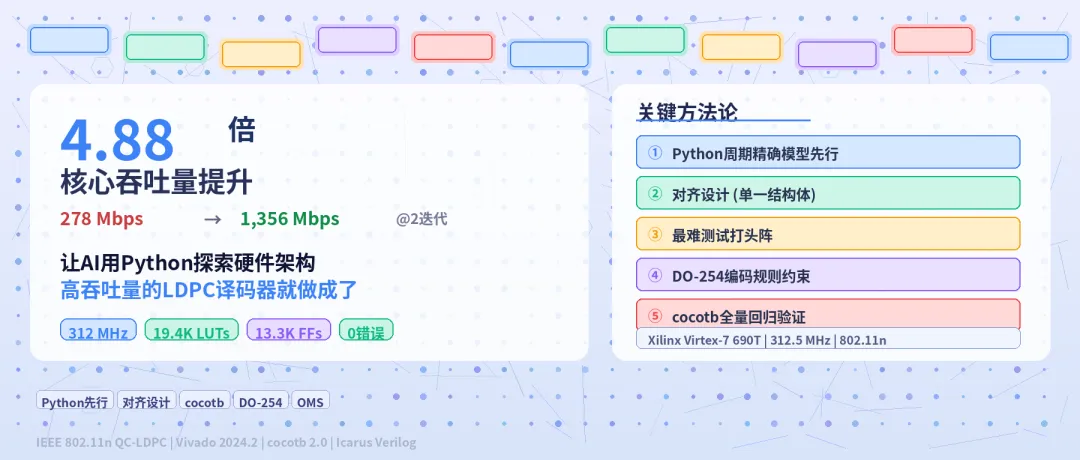
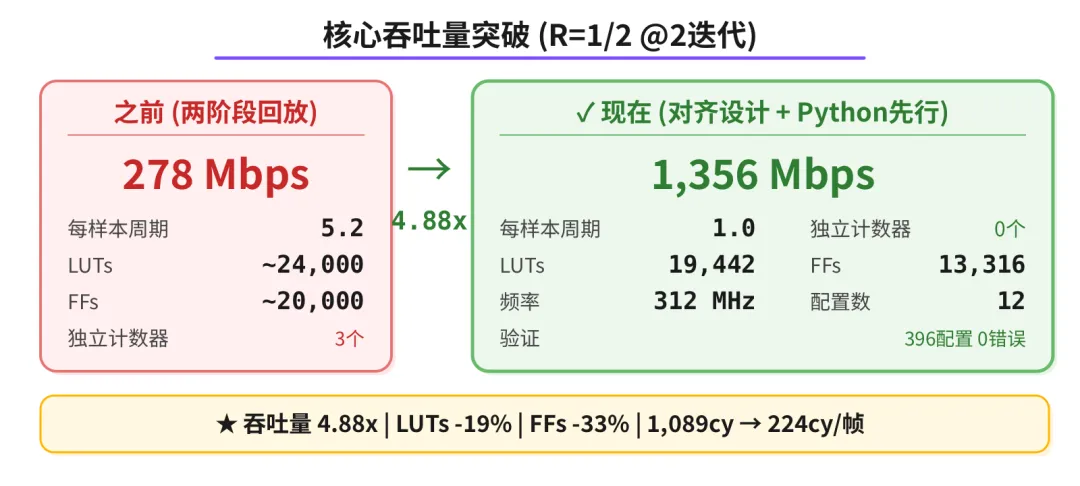
上篇文章(《用 AI 在 FPGA 上自主实现一个 LDPC 译码器的全记录》)里,迭代了 23 个版本,时序收敛了,面积压下来了,但吞吐量始终上不去 - 278 Mbps (R=1/2 @2 迭代,1,089 周期/帧), 离目标差了 4.5 倍。
根本原因很清楚:AI 写了一个两阶段回放架构(正向累积 + 反向回放), 每个样本需要 5.2 个周期。目标架构是延迟线 + 连续流水线,每个样本约 1 个周期。架构不对,优化到死也没用。
之后四轮尝试(v20-v23)切换到流式流水线,全部失败。v20 用了 3 个独立计数器,改一个错两个;v22 猜了延迟深度,差了 6 个周期;v23 做了 17 个模块 41 个单元测试全过,但集成以后差一拍,定位不到。
上次结论是:架构规划省不了,迭代代替不了思考。
核心吞吐量突破: 从278到1,356 Mbps
这次的故事,从"想清楚了"开始。
2想清楚了什么?
v20-v23 失败的时候,我一直觉得是 AI 写 Verilog 的水平不够。后来花了两天仔细研究目标架构,才意识到问题出在哪。
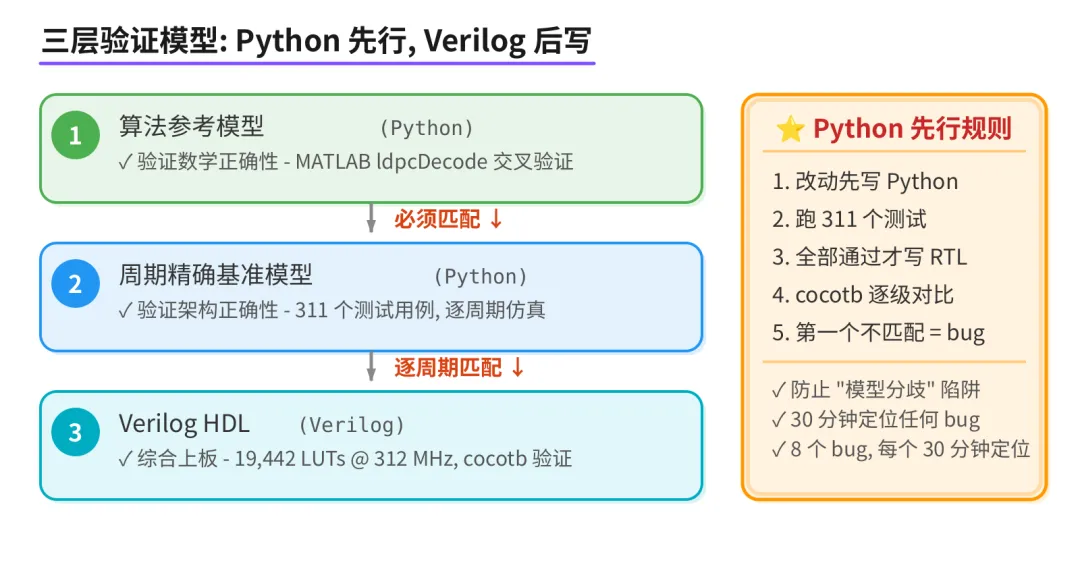
应该先有架构的行为模型,然后再写 Verilog,所以问题是设计流程反了。
之前的做法:先写 Verilog 模块,再跑仿真看结果对不对,不对就让 AI 分析时序调延迟。尽管每个模块单独测试通过了,但集成起来以后结果不对,AI 反复调整时序总是对不齐。17 个模块,5 条以上的独立延迟链,改一条就要重新对齐其他四条。
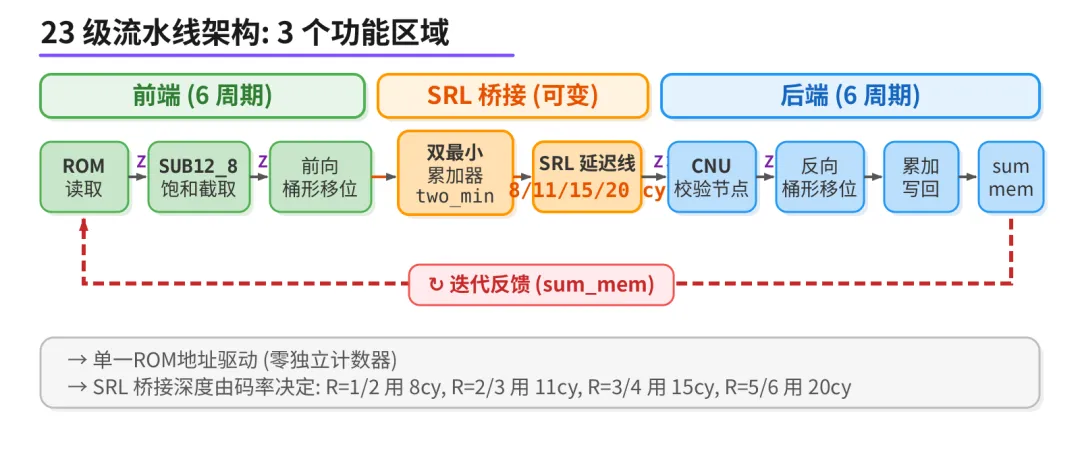
流式 LDPC 流水线的正确做法是"单一地址驱动": H 矩阵的所有非零元素按行主序存在 ROM 里,FSM 只做一件事 - 每拍递增 ROM 地址,读出一个条目,送进流水线。行边界、迭代边界、列地址,全部从 ROM 数据里提取,不需要额外的行计数器或列计数器。整条流水线只有这一个计数器。
想通这一点以后,定了三条规则:
3规则一:先写 Python, 再写 Verilog
三层验证模型
这一次不直接写 RTL 了。先用 Python 写一个周期精确的流水线模型。注意,不是算法模型,是每个变量对应一个寄存器级、每个 tick 对应一个时钟上升沿的精确模型。
所有的流水线改动,先在 Python 上改,跑完全部功能测试,全过了才转换成 Verilog。
测试用例全部通过后才允许写 Verilog
这有多大区别?Python 改一行代码,2 秒钟跑完全部测试。Vivado 仿真同样的改动,至少几分钟。更重要的是,Python 模型可以 dump 每一级流水线的中间状态,跟 Verilog 仿真逐周期对比 - 第一个不匹配的流水级就是 bug。
✅ Tip
之前 v22 版本 AI 会估算延迟深度+9 周期,实测是+15 周期,差了 6 周期,导致 5.2%的残余误码率。这次的做法:用 Python 构建带时序信息的仿真模型,然后让 Verilog 去匹配 Python。猜延迟这种事,再也不干了。
上次四轮失败,每轮卡几天。这次 Python 模型一两天搞定,后面翻译成 Verilog 就会很快,包括 debug 也会变得容易。
4规则二:一个结构体走到底
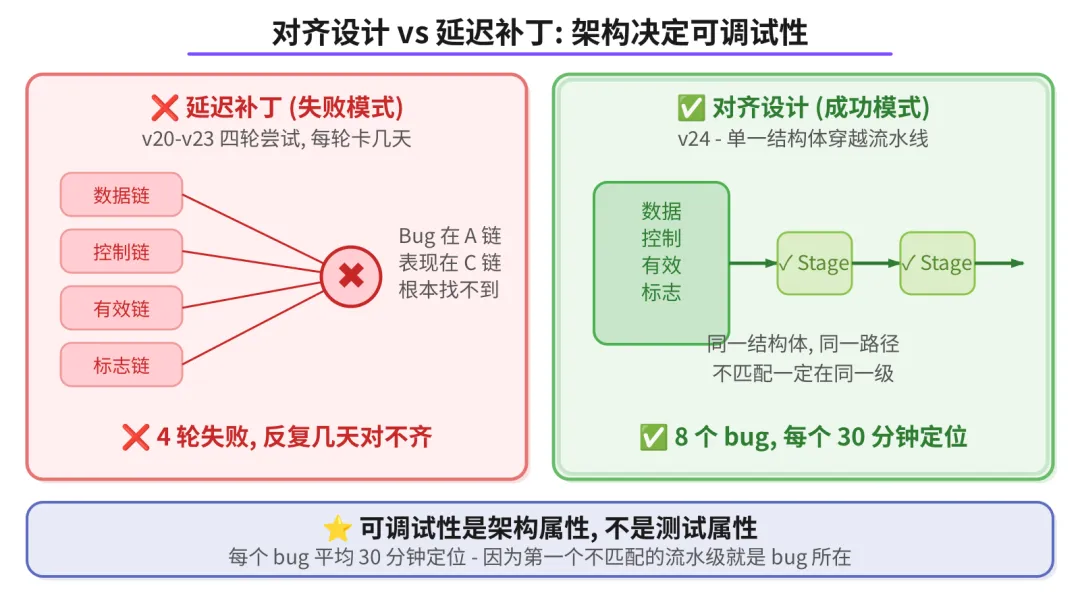
对齐设计 vs 延迟补丁
这是代价最大的教训。
v20 到 v23, 数据走一条延迟链,控制信号走另一条,valid 标志走第三条,各种标志走第四条。四条链各自有延迟,理论上在 CNU 节点汇合。
问题是:bug 在 A 链,表现在 C 链。你去调 C 链,D 链又错了。反复几天,还是对不齐。
这次换了个思路:把所有信号打包成一个 entry 结构体(数据、列号、旋转值、迭代标志、active 标志、行起止标志), 全部走同一条流水线。
entry{data, col, rot, fiter, active, fir, lir, sign, llr_orig} → sub12_8(entry) → barrel(entry) → bridge(entry) → CNU(entry) → write(entry)
你不需要任何延迟补丁。如果 CNU 收到的数据不对,bug 要么在 CNU 本身,要么在上一级。不可能在五个模块之外的某条延迟链里。
效果:8 个 bug, 每个平均 30 分钟定位。跟之前每轮卡几天比,这才是真正的突破。
可调试性是架构属性,不是测试属性。测试覆盖率再高,也救不了一个不可调试的架构。
5规则三:用最难的测试打头阵
验证金字塔
全零码字测试看起来全绿,但它隐藏了37.5%的 bug。
这三类 bug, 全零测试完全检测不到:
第 7 和第 8 个 bug, 在全零测试下隐藏了好几天。换成 16-QAM 随机编码测试向量以后,立刻暴露。
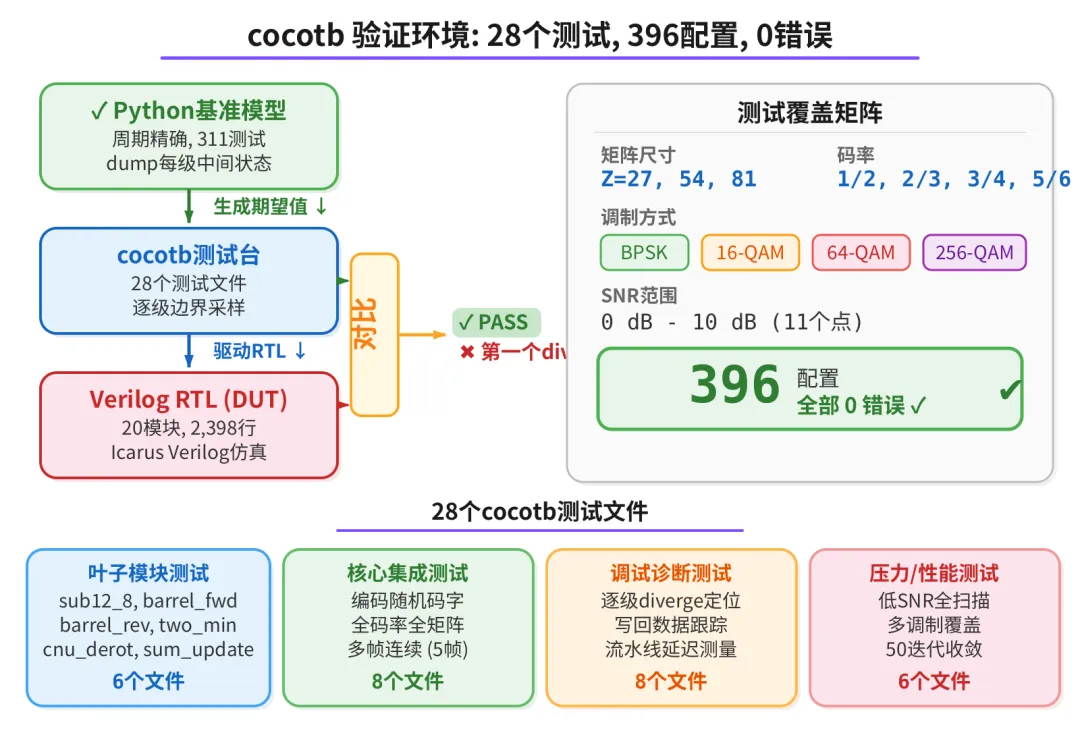
最后用 cocotb 跑了396 个配置(3 种矩阵尺寸 x 4 种码率 x 3 种调制 x 11 个 SNR), 全部 0 错误。
6代码质量:DO-254 规则 + cocotb 验证
吞吐量上来了,但代码质量怎么保证?靠两样东西:DO-254 编码规则约束代码结构,cocotb做端到端验证。
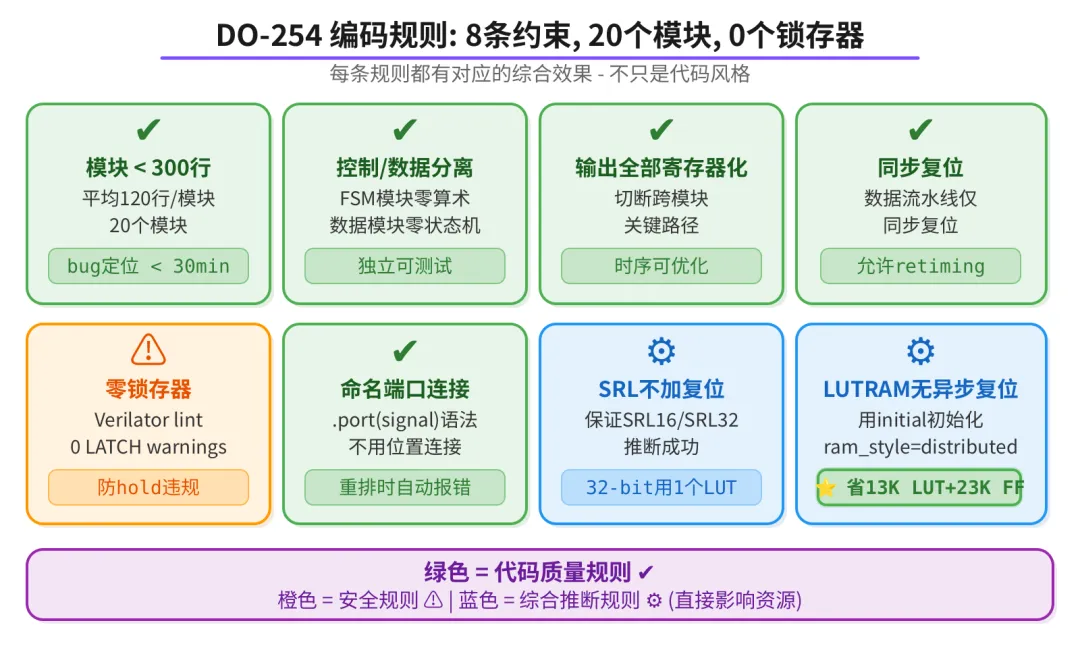
DO-254编码规则
DO-254 编码规则不是建议,是硬约束。AI 生成的每一行 Verilog 都必须满足:
最终20 个模块,平均 120 行。最大的 core.v 有 583 行,但它纯粹是结构化布线,只做实例化和连接,零内联逻辑。
❗ Important
这些规则不只是代码风格。模块<300 行直接决定了 bug 能在 30 分钟内定位;输出寄存器化方便分模块做时序优化和 Debug 定位问题;LUTRAM 不加异步复位省了13K LUT + 23K FF。编码规范直接影响综合结果。
cocotb验证环境
cocotb 验证环境是最后的质量关卡。不是跑一两个测试就完事,而是:
- ▶28 个测试文件
- ▶逐级基准对比 Python 基准模型 dump 每个流水级的中间状态,cocotb 在 RTL 的相同边界逐周期逐 bit 对比
- ▶4 种调制 BPSK、16-QAM、64-QAM、256-QAM 编码随机码字
- ▶全参数扫描 3 种矩阵尺寸 x 4 种码率 x 11 个 SNR = 396 配置
- ▶多帧连续
每次 RTL 改动(24 步优化中的每一步), 都要跑完整套 cocotb 测试。改一个模块,全量回归。没有"这次应该没问题"。
完整配置全部通过,0 bit 错误
DO-254 规则约束 AI 不要写"能跑但不能综合"的代码;cocotb 验证确保改完以后没有功能回退。两者缺一,代码质量都撑不住。
7从 278 到 1,356 Mbps
24 步优化,从 34K LUTs 压到 19.4K LUTs:
吞吐量演进
| | | |
|---|
| 278 Mbps | 1,356 Mbps | 4.88倍 |
| | 2,434 Mbps | |
| | | |
| | | |
| | 13,316 | |
| | | |
| | 12 | |
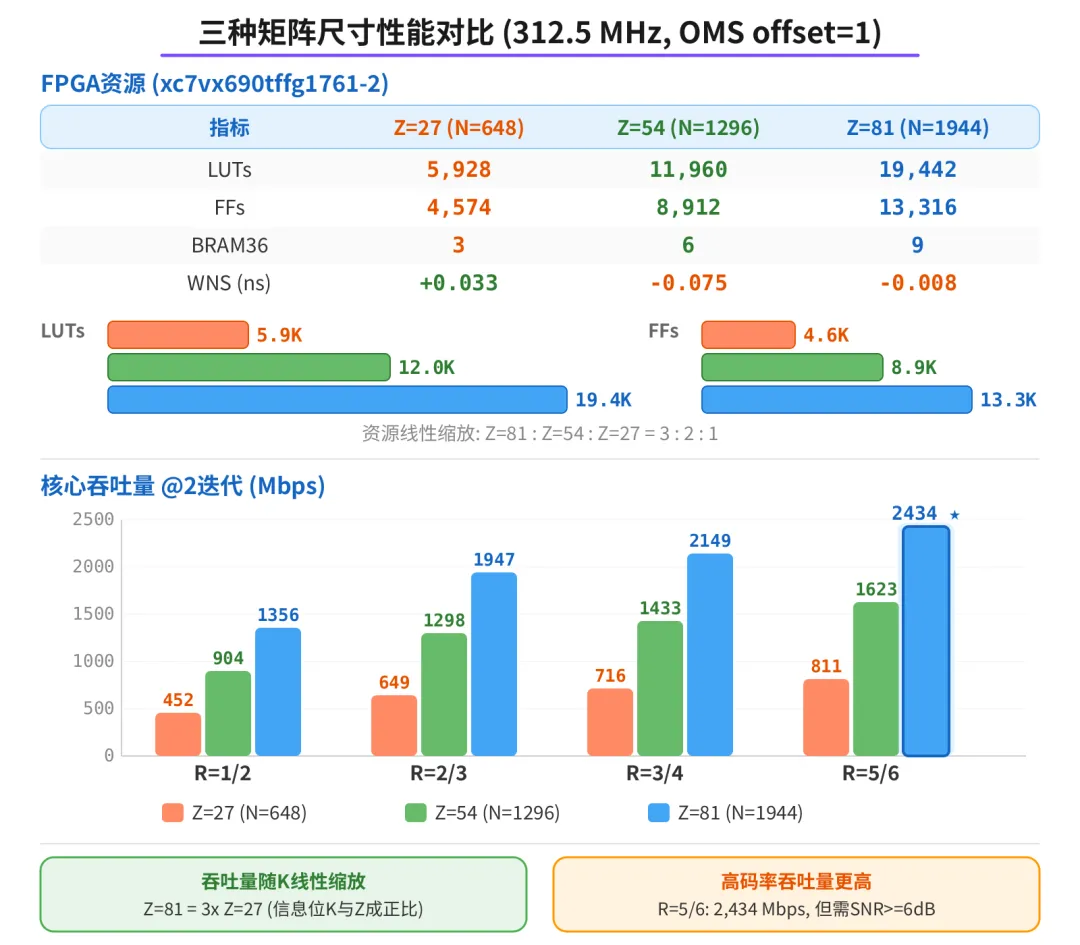
三种矩阵尺寸性能对比
核心译码器各码率吞吐量 (Z=81, 312.5 MHz):
4.88x / 核心吞吐量提升 (R=1/2 @2 迭代,从 278 到 1,356 Mbps)
以上是核心译码器吞吐量(从 start 到 done), 不含 I/O 开销。核心每帧只需 224 周期 @2 迭代(R=1/2), 但当前 16-bit AXI 接口加载一帧需要 984 周期,输入接口反而成为瓶颈。用 128-bit 宽总线(加载降到 120 周期)或双缓冲 LLR 存储器就能消除这个瓶颈,让核心吞吐量成为真实系统吞吐量。
ℹ Note
吞吐量依赖于收敛所需的迭代次数。R=1/2 在 SNR>=2dB 时 2 次迭代就收敛(0 错误), R=5/6 需要 SNR>=6dB。更高码率或更低 SNR 需要更多迭代,吞吐量相应降低。
8一个有意思的 bug
Z=81(最大矩阵)全部通过,Z=27(最小矩阵) R=5/6 在高 SNR 下总有 2-7 个 bit 错误。
原因:FSM 发出 done 信号以后,流水线里还有~28 个来自下一迭代的数据在运行。这些数据流到终点,把正确的解码结果覆盖了。Z=81 的时候累加器值很大(~2000), 覆盖写入的符号位碰巧一样,看不出来。Z=27 的值小(~100), 就翻转了几个 bit。
修复:一个 AND 门。
wire best_wr_en = wb_en & is_processing;
is_processing 在 FSM 进入 IDLE 时拉低,此后所有写入都被屏蔽。流水线内部的工作存储器继续写没关系,但对外可见的输出存储器必须在 done 之后冻结。
ℹ Note
教训:永远用最小的配置测试。大配置下隐藏的 bug, 在小配置下会暴露 - 因为裕量更小。
9上次说"AI 做不到", 这次做到了?
上篇结论是:"架构规划省不了,迭代代替不了思考。一个有经验的架构师花一周时间画清楚流水线依赖关系,就能避免后面几个月的 token 浪费。"
这个判断现在看依然对,但需要修正一点:那个"想清楚的人"可以用 AI 作为工具来实现。关键是先想清楚三件事:
- 1.目标架构到底用了什么机制
- 2.用 Python 模型验证架构,而不是直接写 Verilog 试错
- 3.对齐设计,不要延迟补丁
有了这三条,再加上 DO-254 编码规则约束代码质量、cocotb 做全量回归验证,AI 做完了剩下所有的事:24 步优化,8 个 bug 定位,396 配置 0 错误,三种矩阵尺寸的综合实现。
流水线架构
上次用了几百万 token, 吞吐量纹丝不动。这次方法论对了,用更少的 token 量,核心吞吐量从 278 提到1,356 Mbps (R=1/2 @2 迭代), 4.88 倍, 资源还更少了。
上次的结论是"想清楚了再动手"。这次的结论是:想清楚以后,AI 确实能做到。


 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
