实战代码
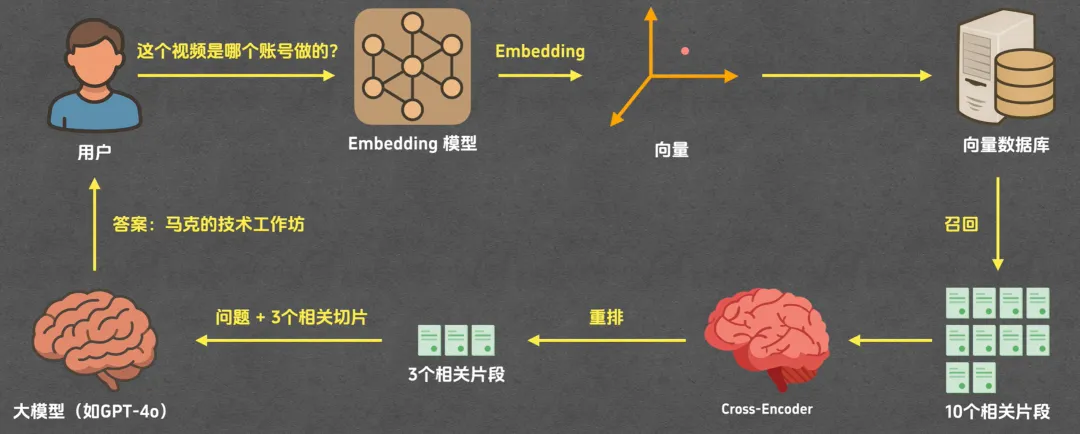
importosfromtypingimportListimportchromadbfromsentence_transformersimportSentenceTransformer, CrossEncoderfromopenaiimportOpenAIembedding_model = SentenceTransformer('shibing624/text2vec-base-chinese')# 文件型向量数据库,默认存储在当前目录下的 chromadb 目录中,可以通过参数指定存储路径# chromadb_client = chromadb.PersistentClient("./chroma.db")chromadb_client = chromadb.EphemeralClient() # 内存型向量数据库# collection是chromadb的概念,相当于一个表,里面存储着向量数据和对应的元数据,可以通过collection来进行增删改查等操作chromadb_collection = chromadb_client.get_or_create_collection(name="default")defsplit_into_chunks(doc_file: str) ->List[str]:"""分片"""withopen("doc.md", "r", encoding="utf-8") asf:content = f.read()return [chunkforchunkincontent.split("\n\n")]defembed_chunk(chunk: str) ->List[float]:"""生成向量"""embedding = embedding_model.encode(chunk)returnembedding.tolist()defsave_embeddings(chunks: List[str], embeddings: List[List[float]]) ->None:"""将所有的片段内容和对应的向量保存到向量数据库中"""# chromadb要求每一条记录都有一个唯一的id,可以使用索引或者其他方式生成唯一id,这里使用索引作为idids = [str(i) foriinrange(len(chunks))]chromadb_collection.add(documents=chunks,embeddings=embeddings,ids=ids, )defretrieve(query: str, top_k: int = 5) ->List[str]:"""召回"""query_embedding = embed_chunk(query)results = chromadb_collection.query(query_embeddings=[query_embedding],n_results=top_k, )returnresults["documents"][0]defrerank(query: str, retrieved_chunks: List[str], top_k: int) ->List[str]:"""重排"""# 创建CrossEncoder模型,使用预训练的中文模型,可以根据需要选择不同的模型cross_encoder = CrossEncoder("cross-encoder/mmarco-mMiniLMv2-L12-H384-v1")pairs = [(query, chunk) forchunkinretrieved_chunks]# CrossEncoder模型会对每一对(query, chunk)进行打分,分数越高表示query和chunk的相关性越高scores = cross_encoder.predict(pairs)# 将召回的片段和分数放到一起chunk_with_score_list = [(chunk, score) forchunk, scoreinzip(retrieved_chunks, scores)]# 根据分数进行排序,分数高的排在前面chunk_with_score_list.sort(key=lambdax: x[1], reverse=True)return [chunkforchunk, _inchunk_with_score_list][:top_k]defgenerate(query: str, retrieved_chunks: List[str]) ->str:"""生成答案"""# 将query和retrieved_chunks拼接成一个prompt,作为输入给语言模型prompt = f"""你是一位知识助手,请根据用户的问题和下列片段生成准确的回答。 用户的问题:{query} 相关片段: {"\n\n".join(retrieved_chunks)} 请基于以上内容作答,不要编造信息。 """print(f"{prompt}\n\n---\n")client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'),base_url="https://api.deepseek.com" )response = client.chat.completions.create(model="deepseek-chat",messages=[ {"role": "user", "content": prompt}, ],temperature=0,stream=False )returnresponse.choices[0].message.contentif__name__ == '__main__':# 分片chunks = split_into_chunks("doc.md")# 索引embeddings = [embed_chunk(chunk) forchunkinchunks]save_embeddings(chunks, embeddings)query = "哆啦A梦使用的3个秘密道具是什么?"# 召回retrieved_chunks = retrieve(query)# 重排ret = rerank(query, retrieved_chunks, 3)# 生成答案answer = generate(query, ret)print("答案:", answer)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
