egrep实战技巧|Linux日志过滤封神,运维必看
- 2026-07-04 02:11:28
在我们的日常Linux运维,最耗时的操作应该就是日志过滤了。查错误、找异常、抽取数据,很多人还在反复敲基础grep,效率极低;而熟练掌握egrep的人,一条命令或许就能搞定别人半小时的活。egrep = grep -E,它支持扩展正则(ere),不用疯狂写反斜杠转义,复杂匹配更简洁、更高效。
今天我们不谈理论,直接聚焦运维日常高频实战场景,每个技巧都配可直接复制的命令。
一、为什么优先用egrep
普通grep(基础正则),写+、|、?、()、{}这些符号,必须加\转义,又乱又容易错,比如:
普通grep多关键词匹配:grep 'error\|fail' /var/log/messagesegrep多关键词匹配:egrep 'error|fail' /var/log/messages

egrep核心优势:不用转义、语法简洁、匹配效率更高。在日常日志过滤、文本搜索,优先用egrep。
二、egrep的实战应用
1. 多关键词过滤
场景:在应用日志中同时找error、fail,不用多次执行grep,一条搞定。
egrep 'error|failure|timeout|exception' /var/log/messagesegrep -i 'error|fail' app.log #-i参数忽略大小写
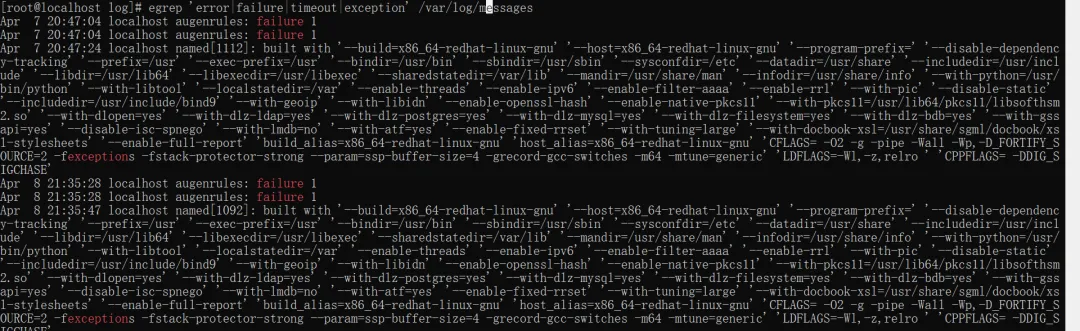

补充:加-i忽略大小写(比如匹配Error、ERROR)
2. 只提取匹配内容,不显示整行
场景:从日志中提取user_id、手机号、IP等关键信息,不显示冗余日志内容。
#提取user_id(数字格式)egrep -o 'user_id=[0-9]+' app.log#提取手机号(简单校验)egrep -o '1[3-9][0-9]{9}' app.log#提取IP地址egrep -o '([0-9]{1,3}\.){3}[0-9]{1,3}' access.log


关键参数:-o(only-matching),只输出匹配到的内容,避免日志刷屏。
3. 查看匹配行内容上下文
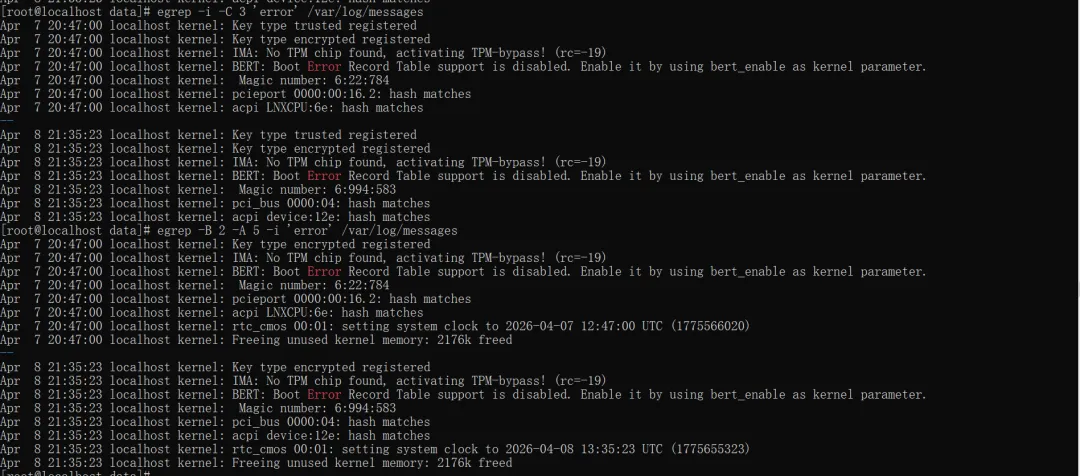
场景:找到错误日志后,需要看前后几行,定位错误原因,和grep的参数类似,也是-ABC三个参数。-B(before)前几行,-A(after)后几行,-C(context)前后几行。
#查看error前后各3行(最常用)egrep -i -C 3 'error' /var/log/messages#查看fatal前2行、后5行(精准定位)egrep -B 2 -A 5 -i 'error' /var/log/messages
4. 反向过滤
场景:日志中太多debug、info信息,只想看错误日志,过滤掉无用内容。
#过滤掉debug和info日志,只看异常egrep -v 'debug|info' boot.log# 过滤空行和注释行(清理配置文件)egrep -v '^$|^[[:space:]]*#' nginx.conf

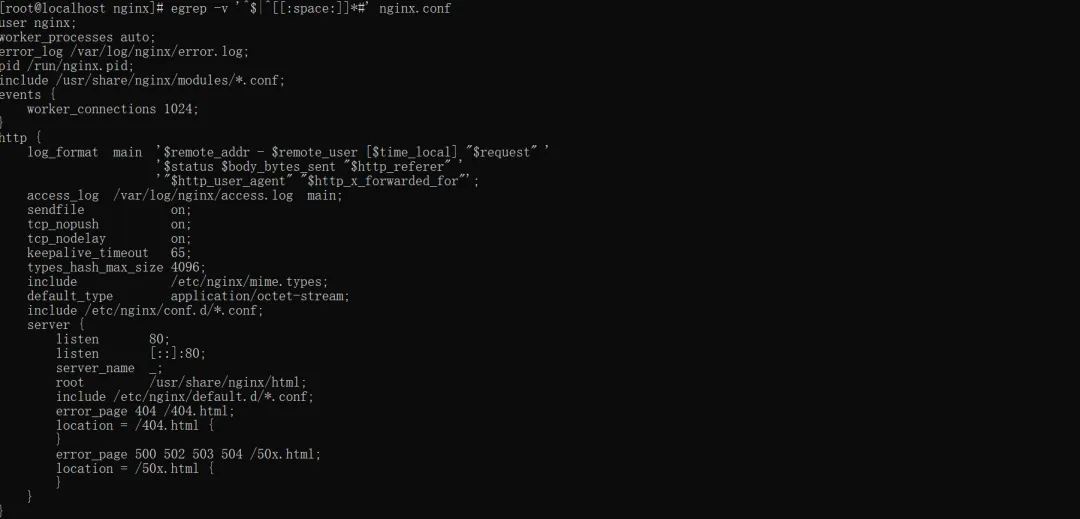
关键参数:-v(invert-match),反向匹配,显示不满足条件的行。
5. 全词匹配(避免匹配子串)
场景:搜索error,不想匹配errorLog等包含error的子串,只匹配完整单词。
egrep -i -w 'error' messages
关键参数:-w(word-regexp),只匹配完整单词,避免误匹配。
6. 显示行号
场景:找到错误后,需要知道错误在日志的第几行,方便后续定位代码或配置。
egrep -i -n 'error' messages
关键参数:-n(line-number),显示匹配行的行号。
三、实战高频组合命令
1. 递归搜索整个目录
场景:在程序目录下,所有文件中搜索jdbc配置,不用逐个文件打开。
egrep -r 'jdbc' /data
补充:只显示匹配到的文件名(不显示内容),方便批量处理
egrep -rl 'fail' /var/log/
2. 统计匹配行数
场景:统计日志中fail出现的次数,判断异常严重程度。
egrep -c 'fail' messages
关键参数:-c(count),统计匹配到的行数(注意:一行多个error只算1行)。
3. 提取IP并统计访问TOP10
场景:分析访问日志,找出访问量最高的10个IP,排查异常访问。
egrep -o '([0-9]{1,3}\.){3}[0-9]{1,3}' access.log | sort | uniq -c | sort -nr | head -10
思路:提取IP → 排序 → 去重计数 → 按数量倒序 → 取前10名。
4. 过滤接口异常日志
场景:排查日志接口的异常,只看该接口的error日志,且显示上下文。
egrep -C 5 -i 'fail|error' message 
四、注意事项
egrep不用转义特殊符号:在扩展正则表达式 (ere) 中, + 、 | 、 ? 、 () 、 {} 等元字符具有特殊含义,可直接使用。若在前面加 \` 转义,则会将其解释为普通字符。例如, egrep 'a+' file 匹配连续的“a”;而 egrep 'a+' file` 则匹配字面字符串 “a+”。。
关键词含特殊符号需转义:如果搜索的关键词本身有.、*、[]等(比如搜索192.168.1.1),需要加\转义:egrep '192\.168\.1\.1' access.log。
大批量日志优先加-F:如果只是单纯匹配固定字符串(不使用正则),加-F参数,速度会快很多:egrep -F 'user/login' log.log。
egrep不支持零宽断言:如果需要用(?=)、(?<=)等高级正则,改用grep -P(比如提取带前缀的手机号:grep -P '(?<=phone=)1[3-9][0-9]{9}' app.log)。
五、总结
实战中只需要记住这几个核心场景对应的命令,日常够用:
多关键词 → egrep 'a|b|c' 文件名;
提内容 → 加 -o;
看上下文 → 加 -C/-B/-A;
过滤干扰 → 加 -v;
递归搜目录 → 加 -r;
统计数量 → 加 -c;
egrep的核心是简化正则写法、提升过滤效率,日常运维中,多用几次就能学会了。如果觉得有用,记得点赞加关注。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 这个Python代码习惯,80%的新手都没注意
- Python应用培训招生简章
- 《Python 编程快速上手》阅读理解:浅学基础语法,补齐工作必备的 基础认知
- Python 常见配置文件写法全解,这篇超全攻略必看!
- 5 分钟极速入门:用 Python 和 ChromaDB 体验向量数据库的魅力
- 别死磕算法了!2026 年 Python+AI 入门,就盯这 3 个落地方向
- VS Code 与 Python 虚拟环境实用技巧:从多项目管理到离线部署
- CAE Python 实战 2026年4月14日
- python-递归函数(全排列算法)
- python入门之测试代码(一)
