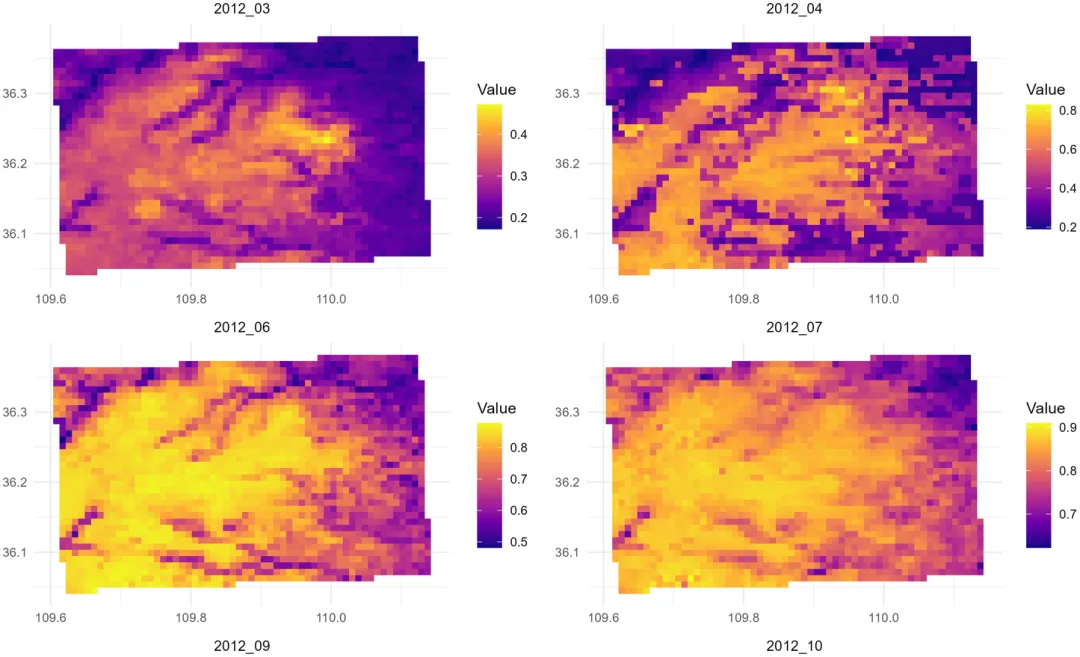
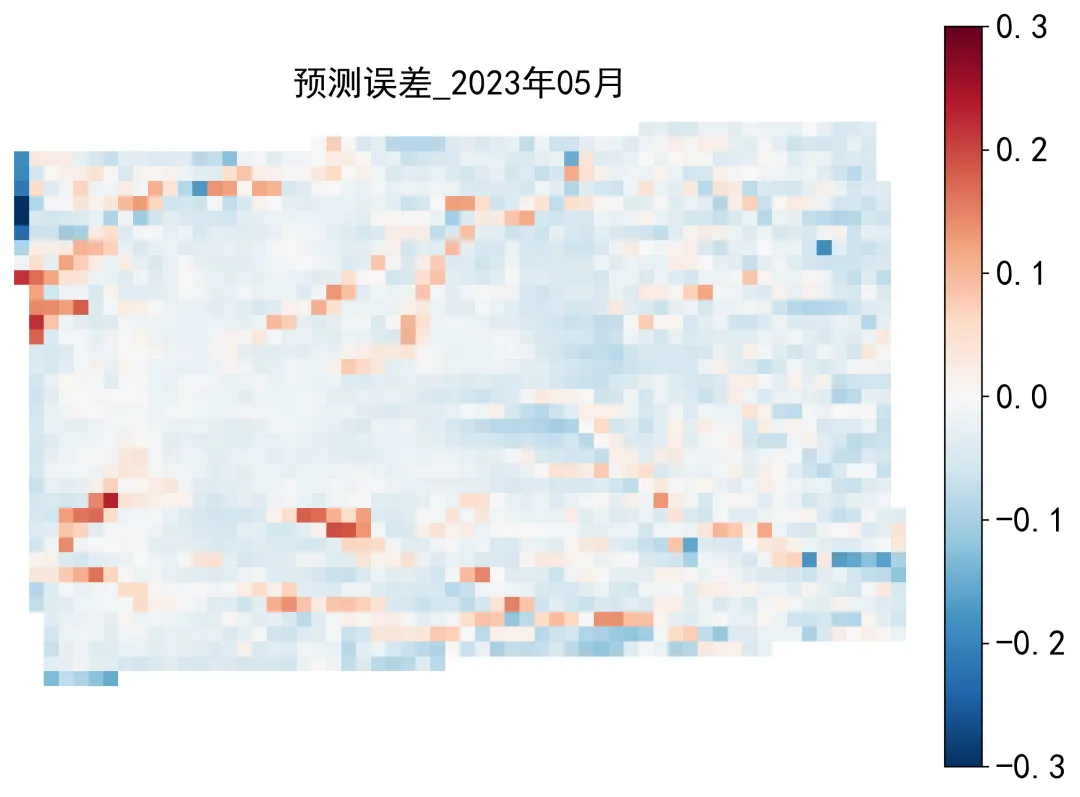
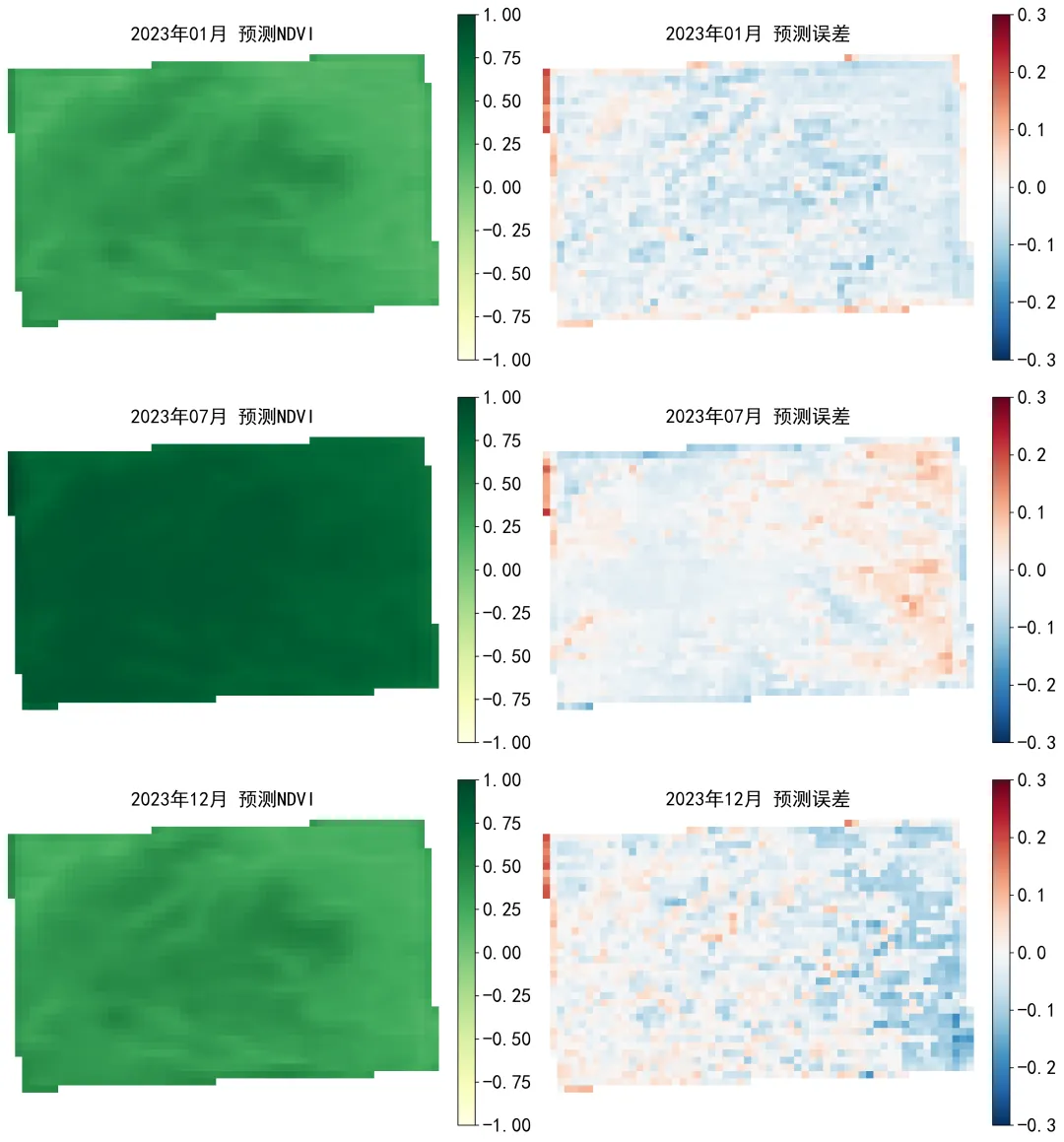
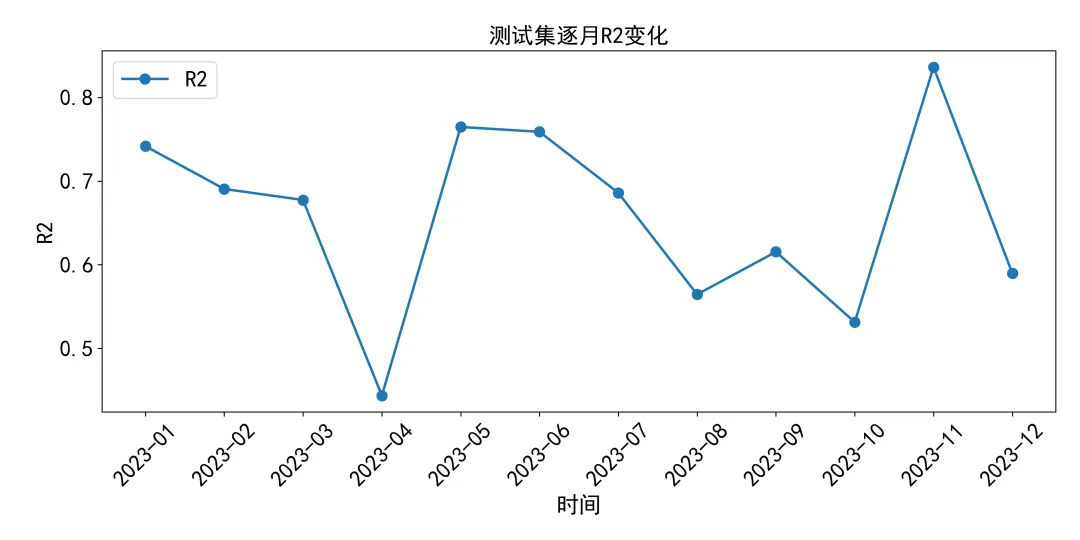
import osimport reimport globimport numpy as npimport pandas as pdimport rasteriofrom tqdm import tqdmfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scoreimport tensorflow as tffrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Input, ConvLSTM2D, BatchNormalization, Conv2D, Dropoutfrom tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau, ModelCheckpointndvi_dir = r"D:\python代码\ConvLSTM\NDVI MONTHLY"out_dir = r"D:\python代码\ConvLSTM\ConvLSTM结果"os.makedirs(out_dir, exist_ok=True)pred_dir = os.path.join(out_dir, "测试集预测NDVI栅格")error_dir = os.path.join(out_dir, "测试集误差栅格")model_dir = os.path.join(out_dir, "训练模型")future_dir = os.path.join(out_dir, "未来12个月NDVI预测")for d in [pred_dir, error_dir, model_dir, future_dir]: os.makedirs(d, exist_ok=True)start_year = 2010end_year = 2023time_steps = 12test_year = 2023future_months = 12epochs = 100batch_size = 2ndvi_min_value = -1.0ndvi_max_value = 1.0def parse_date_from_filename(path): name = os.path.basename(path) m = re.match(r"(\d{4})_(\d{2})\.tif$", name) if m is None: return None return int(m.group(1)), int(m.group(2))def collect_files(folder, start_year, end_year): files = glob.glob(os.path.join(folder, "*.tif")) records = [] for f in files: date = parse_date_from_filename(f) if date is None: continue year, month = date if start_year <= year <= end_year: records.append((year, month, f)) records = sorted(records, key=lambda x: (x[0], x[1])) expected = [(y, m) for y in range(start_year, end_year + 1) for m in range(1, 13)] existing = [(r[0], r[1]) for r in records] missing = [x for x in expected if x not in existing] if missing: pd.DataFrame(missing, columns=["年份", "月份"]).to_csv( os.path.join(out_dir, "缺失月份统计.csv"), index=False, encoding="utf-8-sig" ) return recordsdef read_tif(path): with rasterio.open(path) as src: arr = src.read(1).astype(np.float32) profile = src.profile nodata = src.nodata if nodata is not None: arr[arr == nodata] = np.nan arr[arr < -1.5] = np.nan arr[arr > 1.5] = np.nan return arr, profiledef save_tif(path, arr, profile): profile2 = profile.copy() profile2.update( dtype=rasterio.float32, count=1, compress="lzw", nodata=-9999 ) out = arr.astype(np.float32) out[np.isnan(out)] = -9999 with rasterio.open(path, "w", **profile2) as dst: dst.write(out, 1)def normalize_ndvi(arr): arr = np.clip(arr, ndvi_min_value, ndvi_max_value) return (arr - ndvi_min_value) / (ndvi_max_value - ndvi_min_value)def denormalize_ndvi(arr): return arr * (ndvi_max_value - ndvi_min_value) + ndvi_min_valuerecords = collect_files(ndvi_dir, start_year, end_year)if len(records) == 0: raise ValueError("没有找到符合 2010_01.tif 格式的文件。")arrays = []dates = []profile = Nonefor year, month, path in tqdm(records, desc="读取NDVI数据"): arr, profile = read_tif(path) arrays.append(arr) dates.append((year, month))data = np.array(arrays, dtype=np.float32)T, H, W = data.shapevalid_mask = np.isfinite(np.nanmean(data, axis=0))mean_value = np.nanmean(data)if np.isnan(mean_value): raise ValueError("所有数据都是 NoData,请检查 NDVI 栅格。")data = np.where(np.isfinite(data), data, mean_value)data_norm = normalize_ndvi(data)X_list = []Y_list = []target_dates = []for i in range(time_steps, T): X_list.append(data_norm[i - time_steps:i, :, :]) Y_list.append(data_norm[i, :, :]) target_dates.append(dates[i])X_all = np.array(X_list, dtype=np.float32)Y_all = np.array(Y_list, dtype=np.float32)train_indices = []test_indices = []for idx, (year, month) in enumerate(target_dates): if year < test_year: train_indices.append(idx) else: test_indices.append(idx)X_train = X_all[train_indices][..., np.newaxis]Y_train = Y_all[train_indices][..., np.newaxis]X_test = X_all[test_indices][..., np.newaxis]Y_test = Y_all[test_indices][..., np.newaxis]test_dates = [target_dates[i] for i in test_indices]model = Sequential([ Input(shape=(time_steps, H, W, 1)), ConvLSTM2D( filters=32, kernel_size=(3, 3), padding="same", return_sequences=True, activation="tanh" ), BatchNormalization(), Dropout(0.2), ConvLSTM2D( filters=16, kernel_size=(3, 3), padding="same", return_sequences=False, activation="tanh" ), BatchNormalization(), Dropout(0.2), Conv2D( filters=1, kernel_size=(3, 3), padding="same", activation="sigmoid" )])model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss="mse", metrics=["mae"])best_model_path = os.path.join(model_dir, "最优ConvLSTM模型.keras")callbacks = [ EarlyStopping( monitor="val_loss", patience=15, restore_best_weights=True ), ReduceLROnPlateau( monitor="val_loss", factor=0.5, patience=7, min_lr=1e-6 ), ModelCheckpoint( best_model_path, monitor="val_loss", save_best_only=True )]history = model.fit( X_train, Y_train, epochs=epochs, batch_size=batch_size, validation_split=0.15, callbacks=callbacks, verbose=1)pd.DataFrame(history.history).rename(columns={ "loss": "训练损失", "mae": "训练平均绝对误差", "val_loss": "验证损失", "val_mae": "验证平均绝对误差", "learning_rate": "学习率", "lr": "学习率"}).to_csv( os.path.join(out_dir, "训练过程记录.csv"), index=False, encoding="utf-8-sig")metrics_rows = []all_true = []all_pred = []for i in tqdm(range(len(X_test)), desc="测试集预测"): year, month = test_dates[i] pred_norm = model.predict(X_test[i:i + 1], verbose=0)[0, :, :, 0] true_norm = Y_test[i, :, :, 0] pred = denormalize_ndvi(pred_norm) true = denormalize_ndvi(true_norm) pred[~valid_mask] = np.nan true[~valid_mask] = np.nan error = pred - true abs_error = np.abs(error) save_tif( os.path.join(pred_dir, f"预测NDVI_{year}年{month:02d}月.tif"), pred, profile ) save_tif( os.path.join(error_dir, f"预测误差_{year}年{month:02d}月.tif"), error, profile ) save_tif( os.path.join(error_dir, f"绝对误差_{year}年{month:02d}月.tif"), abs_error, profile ) mask = np.isfinite(true) & np.isfinite(pred) true_flat = true[mask].flatten() pred_flat = pred[mask].flatten() rmse = np.sqrt(mean_squared_error(true_flat, pred_flat)) mae = mean_absolute_error(true_flat, pred_flat) r2 = r2_score(true_flat, pred_flat) metrics_rows.append({ "年份": year, "月份": month, "均方根误差_RMSE": rmse, "平均绝对误差_MAE": mae, "决定系数_R2": r2 }) all_true.append(true_flat) all_pred.append(pred_flat)all_true = np.concatenate(all_true)all_pred = np.concatenate(all_pred)overall_rmse = np.sqrt(mean_squared_error(all_true, all_pred))overall_mae = mean_absolute_error(all_true, all_pred)overall_r2 = r2_score(all_true, all_pred)metrics_df = pd.DataFrame(metrics_rows)overall_row = pd.DataFrame([{ "年份": "总体", "月份": "总体", "均方根误差_RMSE": overall_rmse, "平均绝对误差_MAE": overall_mae, "决定系数_R2": overall_r2}])metrics_df = pd.concat([metrics_df, overall_row], ignore_index=True)metrics_df.to_csv( os.path.join(out_dir, "测试集逐月精度评价.csv"), index=False, encoding="utf-8-sig")residual_mean = np.nanmean(all_pred - all_true)residual_std = np.nanstd(all_pred - all_true)summary_df = pd.DataFrame([{ "时间层数": T, "栅格行数": H, "栅格列数": W, "训练样本数": len(X_train), "测试样本数": len(X_test), "时间窗口长度_月": time_steps, "总体均方根误差_RMSE": overall_rmse, "总体平均绝对误差_MAE": overall_mae, "总体决定系数_R2": overall_r2, "残差均值": residual_mean, "残差标准差": residual_std}])summary_df.to_csv( os.path.join(out_dir, "总体结果汇总.csv"), index=False, encoding="utf-8-sig")history_seq = data_norm[-time_steps:, :, :].copy()future_year = end_year + 1future_predictions = []for step in tqdm(range(future_months), desc="未来12个月预测"): future_month = step + 1 x_input = history_seq[np.newaxis, ..., np.newaxis] pred_norm = model.predict(x_input, verbose=0)[0, :, :, 0] pred = denormalize_ndvi(pred_norm) pred[~valid_mask] = np.nan save_tif( os.path.join(future_dir, f"未来预测NDVI_{future_year}年{future_month:02d}月.tif"), pred, profile ) future_predictions.append(pred) pred_norm_clean = normalize_ndvi(pred) pred_norm_clean = np.where(np.isfinite(pred_norm_clean), pred_norm_clean, mean_value) history_seq = np.concatenate( [history_seq[1:], pred_norm_clean[np.newaxis, :, :]], axis=0 )future_stack = np.array(future_predictions)future_mean = np.nanmean(future_stack, axis=0)future_max = np.nanmax(future_stack, axis=0)future_min = np.nanmin(future_stack, axis=0)future_std = np.nanstd(future_stack, axis=0)future_amp = future_max - future_minsave_tif( os.path.join(future_dir, f"未来{future_year}年平均NDVI.tif"), future_mean, profile)save_tif( os.path.join(future_dir, f"未来{future_year}年最大NDVI.tif"), future_max, profile)save_tif( os.path.join(future_dir, f"未来{future_year}年最小NDVI.tif"), future_min, profile)save_tif( os.path.join(future_dir, f"未来{future_year}年NDVI标准差.tif"), future_std, profile)save_tif( os.path.join(future_dir, f"未来{future_year}年NDVI振幅.tif"), future_amp, profile)future_rows = []for i in range(future_months): arr = future_predictions[i] future_rows.append({ "年份": future_year, "月份": i + 1, "平均NDVI": np.nanmean(arr), "最大NDVI": np.nanmax(arr), "最小NDVI": np.nanmin(arr), "NDVI标准差": np.nanstd(arr) })pd.DataFrame(future_rows).to_csv( os.path.join(future_dir, "未来12个月NDVI统计.csv"), index=False, encoding="utf-8-sig")model.save(os.path.join(model_dir, "最终ConvLSTM模型.keras"))print("全部完成")print("结果文件夹:", out_dir)print("总体RMSE:", overall_rmse)print("总体MAE:", overall_mae)print("总体R2:", overall_r2)





 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
