Python实战:使用PuLP库解决线性规划问题
- 2026-06-30 17:17:25
本文作者:赵语涵 中南财经政法大学统计与数学学院
本文编辑:梁莹
技术总编:兰博文
Stata and Python 数据分析
爬虫俱乐部Stata数据处理与实证研究实战、Python基础编程与文本分析进阶课程可在小鹅通平台查看,欢迎大家多多支持订阅!如需了解详情,可以通过课程链接(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或课程二维码进行访问哦~



线性规划为此提供了一种统一的建模语言。通过明确目标函数与约束条件,可以在给定条件下求得全局最优解。本文以一个“三阶段决策问题”为例,依次构建选址、投资与生产模型,展示如何使用 Python 中的 PuLP 库,将复杂运营决策转化为可求解的线性规划问题。


本案例刻画的是一个典型的中长期运营决策流程:先进行工厂选址,再决定是否进行产能投资,最后在既定产能条件下安排生产与配送。这种决策具有明确的先后依赖关系,因此在数据层面需要进行分阶段组织。
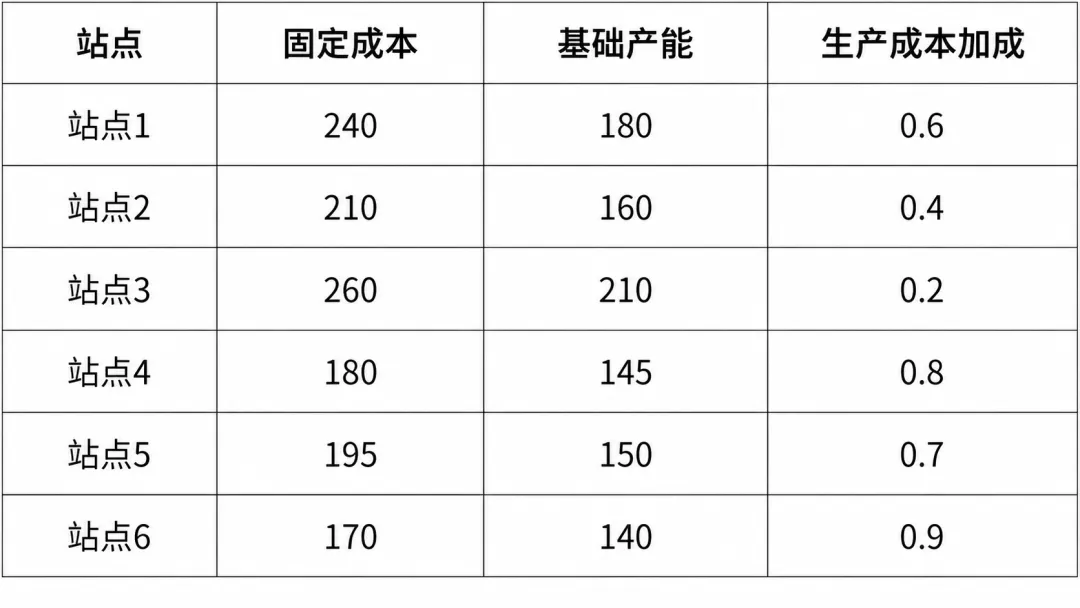
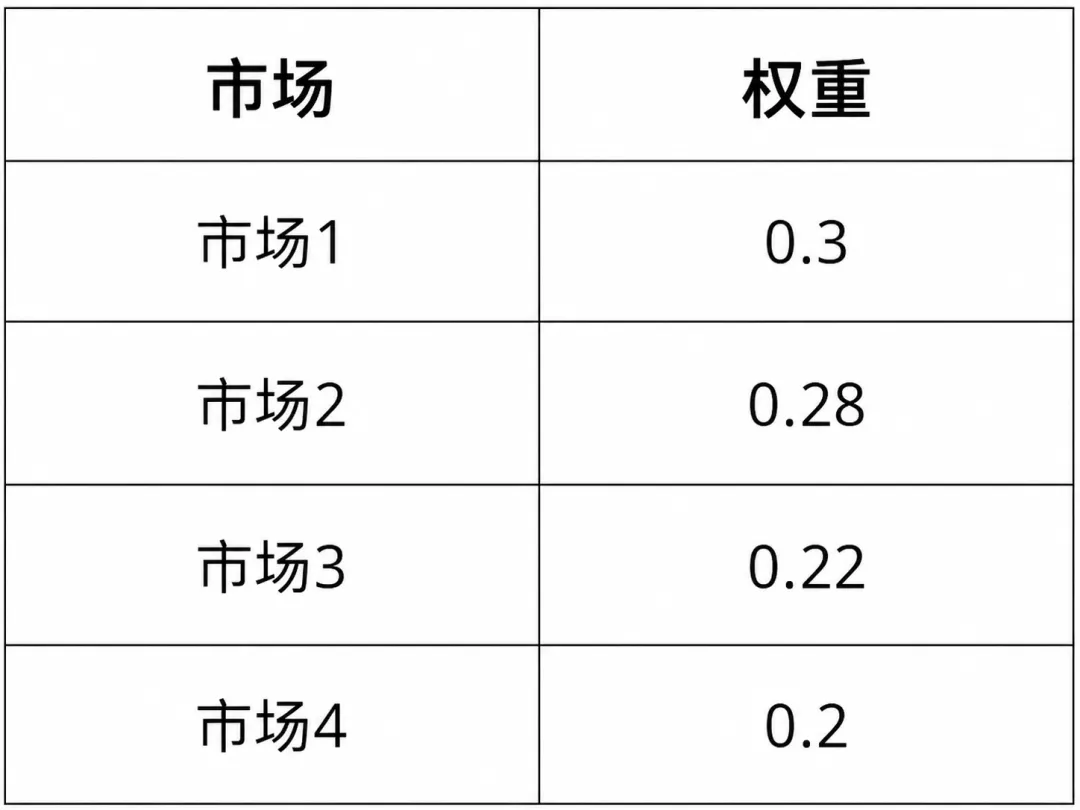
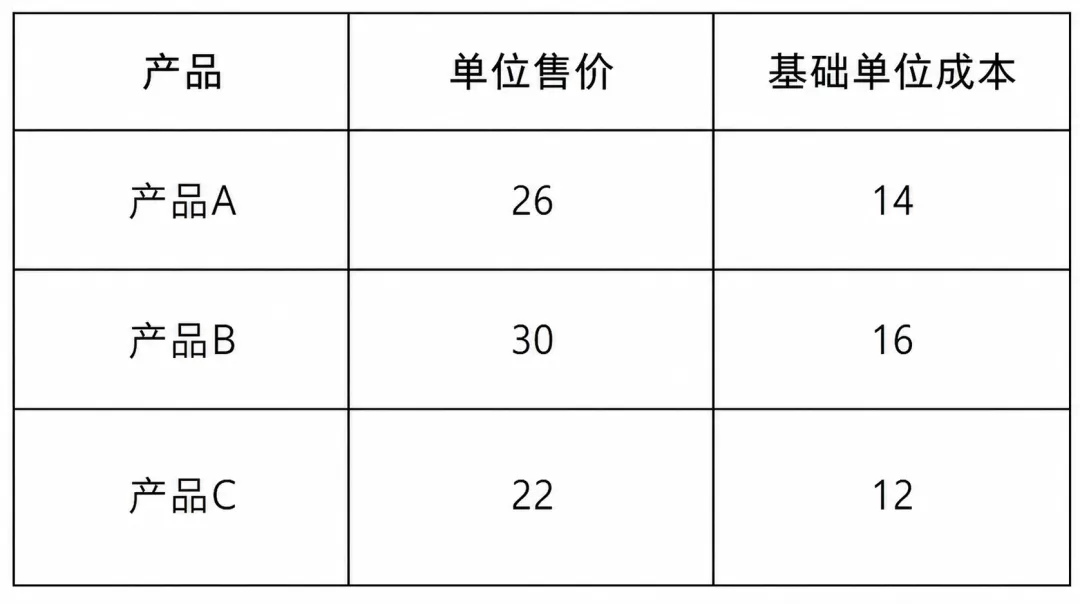
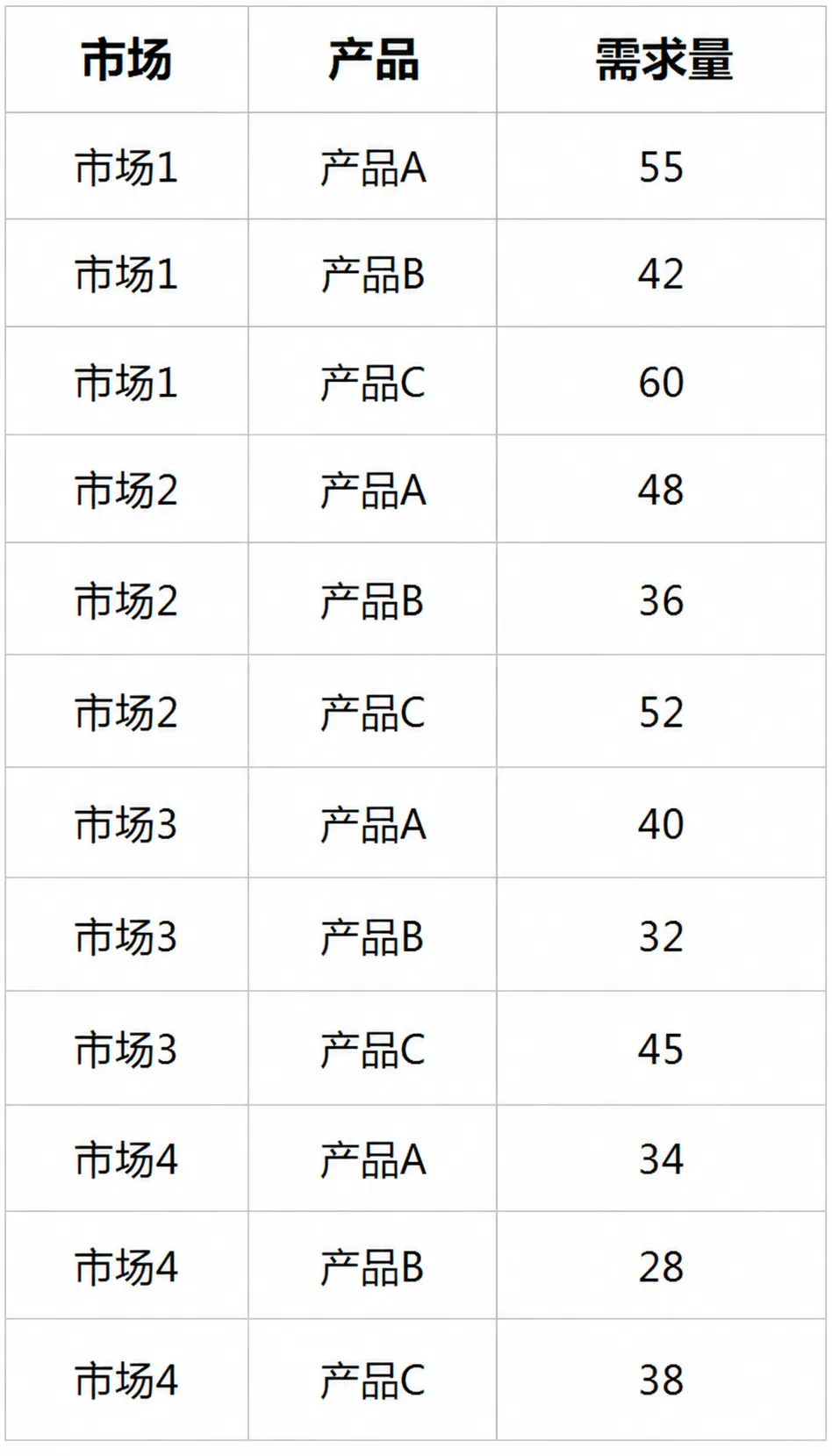
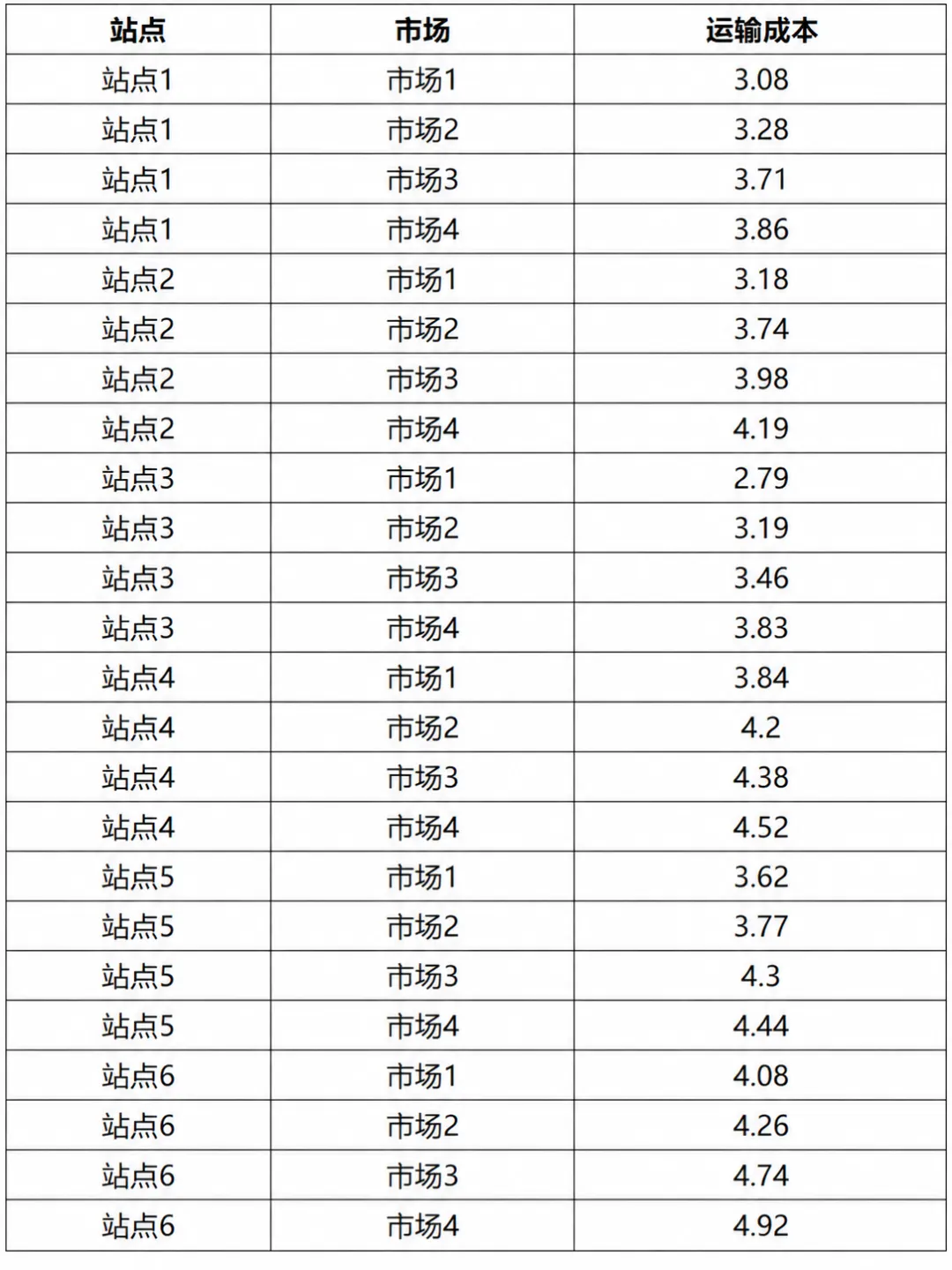
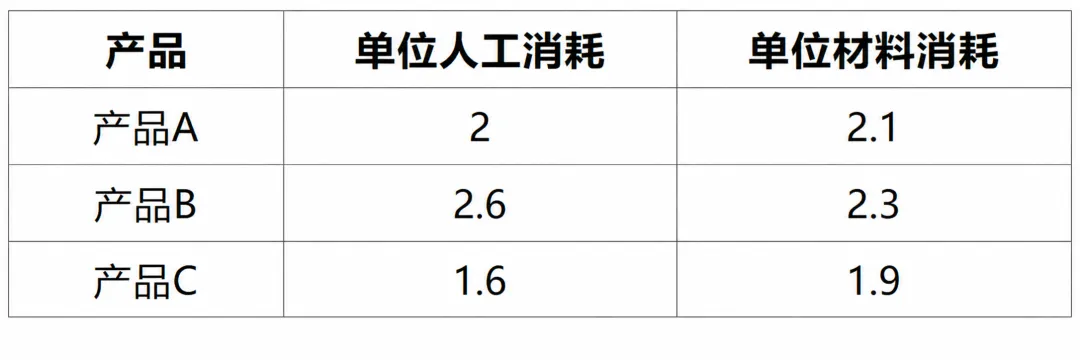
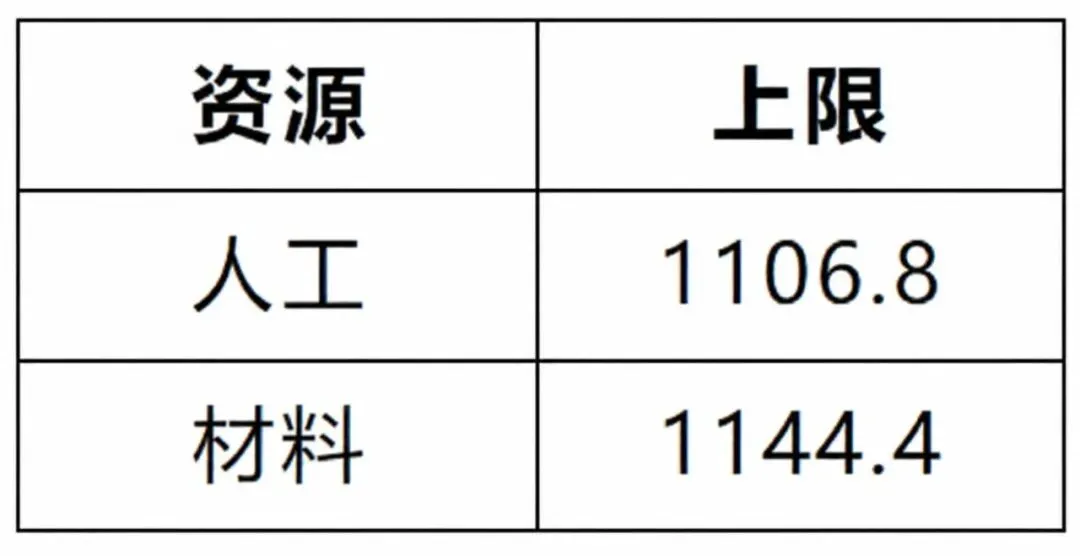
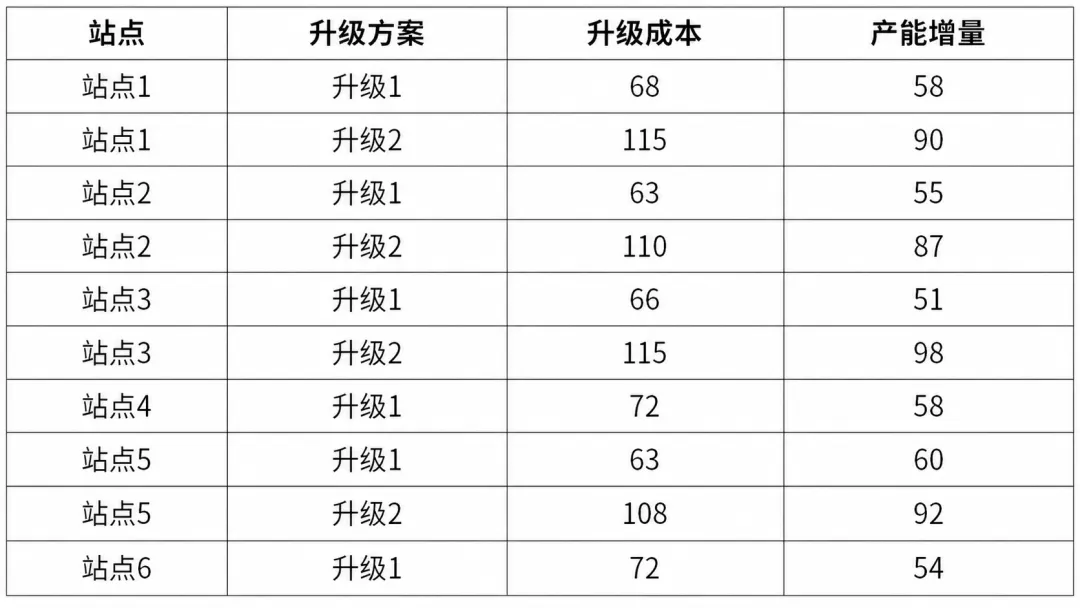
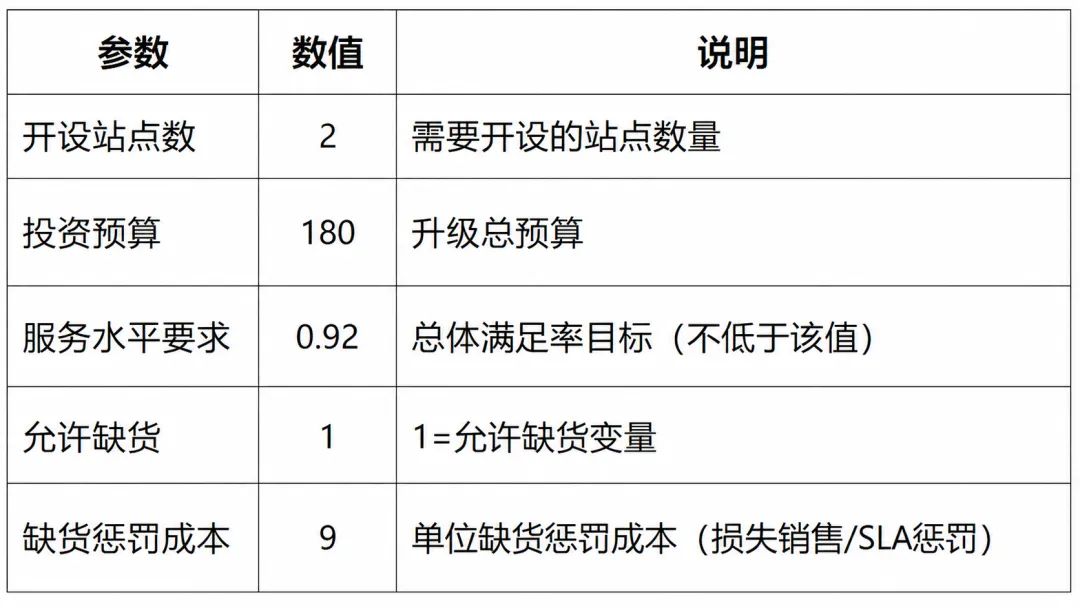
为此,数据被拆分为选址、投资与生产三类核心信息。选址相关数据描述候选工厂的固定建设成本、基础产能以及区位差异;投资数据刻画不同工厂可选的产能升级方案及其成本;生产与配送数据则给出产品价格、需求规模、运输成本以及全局资源约束。此外,部分关键参数(如选址数量、投资预算、服务水平要求)被集中存放,便于统一调整。
在建模前,首先从 Excel 文件中读取各类数据,并整理为 Python 中便于索引的字典与列表结构,为后续线性规划建模做准备。
import pandas as pdimport pulp as plFILE = "lp_realistic_data_v2.xlsx"sites_df = pd.read_excel(FILE, sheet_name="sites")mkts_df = pd.read_excel(FILE, sheet_name="markets")prod_df = pd.read_excel(FILE, sheet_name="products")demand_df = pd.read_excel(FILE, sheet_name="demand")ship_df = pd.read_excel(FILE, sheet_name="shipping")bom_df = pd.read_excel(FILE, sheet_name="bom")rlim_df = pd.read_excel(FILE, sheet_name="resource_limits")upg_df = pd.read_excel(FILE, sheet_name="site_upgrades")params_df = pd.read_excel(FILE, sheet_name="params")sites = sites_df["site"].tolist()markets = mkts_df["market"].tolist()products = prod_df["product"].tolist()fixed_cost = dict(zip(sites_df["site"], sites_df["fixed_cost"]))base_cap = dict(zip(sites_df["site"], sites_df["base_capacity"]))site_addon = dict(zip(sites_df["site"], sites_df["prod_cost_addon"]))mkt_weight = dict(zip(mkts_df["market"], mkts_df["weight"]))price = dict(zip(prod_df["product"], prod_df["unit_price"]))base_unit_cost = dict(zip(prod_df["product"], prod_df["base_unit_cost"]))demand = {(r["market"], r["product"]): float(r["demand"]) for _, r in demand_df.iterrows()}ship_cost = {(r["site"], r["market"]): float(r["ship_cost"]) for _, r in ship_df.iterrows()}labor_use = dict(zip(bom_df["product"], bom_df["labor_per_unit"]))mat_use = dict(zip(bom_df["product"], bom_df["material_per_unit"]))res_limit = dict(zip(rlim_df["resource"], rlim_df["limit"]))params = dict(zip(params_df["param"], params_df["value"]))K = int(params["K"])INVEST_BUDGET = float(params["INVEST_BUDGET"])SERVICE_LEVEL = float(params["SERVICE_LEVEL"])ALLOW_BACKORDER = int(params["ALLOW_BACKORDER"])SHORT_PENALTY = float(params.get("SHORT_PENALTY", 0.0))TOTAL_DEMAND = sum(demand[(m, p)] for m in markets for p in products)mkt_total_demand = {m: sum(demand[(m, p)] for p in products) for m in markets}
选址阶段回答的是一个结构性问题:在多个候选工厂中,应当选择哪些地点进行建设。该决策一旦做出,将长期影响后续的投资与生产安排,因此需要从整体成本角度进行优化。
在模型中,每个候选工厂对应一个 0–1 决策变量,表示是否选址。目标函数由两部分构成:固定建设成本,以及基于市场需求加权后的运输成本,用以刻画不同区位带来的长期差异。约束条件则要求最终选出的工厂数量恰好等于预设的 K。
代码的核心逻辑是:在满足“选址数量约束”的前提下,寻找使综合成本最小的一组工厂组合。
m1 = pl.LpProblem("Location", pl.LpMinimize)open_site = pl.LpVariable.dicts("open", sites, 0, 1, cat=pl.LpBinary)m1 += (pl.lpSum(fixed_cost[s] * open_site[s] for s in sites)+ pl.lpSum(mkt_weight[m] * mkt_total_demand[m] * ship_cost[(s, m)] * open_site[s]for s in sites for m in markets))m1 += pl.lpSum(open_site[s] for s in sites) == Km1.solve(pl.PULP_CBC_CMD(msg=False))selected_sites = [s for s in sites if pl.value(open_site[s]) > 0.5]print("Status:", pl.LpStatus[m1.status])print("Selected sites:", selected_sites)print("Objective (location):", pl.value(m1.objective))print()if pl.LpStatus[m1.status] != "Optimal":raise RuntimeError("Part 1 did not solve to optimal. Check data/constraints.")

在确定选址之后,投资阶段的目标转为:在预算约束下,决定是否对已选工厂进行产能升级,以最大化可用产能。
模型中为每一个“工厂–升级方案”组合设置 0–1 决策变量。目标函数最大化产能增量总和,同时通过约束保证:升级只能发生在已选址工厂、每个工厂最多选择一个升级方案、且总投资不超过预算。
代码本质上是在做一件事:在给定预算内,为已选工厂挑选“性价比最高”的升级组合。
m2 = pl.LpProblem("Investment", pl.LpMaximize)upg_pairs = [(r["site"], r["upgrade"]) for _, r in upg_df.iterrows()]upg_cost = {(r["site"], r["upgrade"]): float(r["upgrade_cost"]) for _, r in upg_df.iterrows()}upg_gain = {(r["site"], r["upgrade"]): float(r["capacity_gain"]) for _, r in upg_df.iterrows()}x = pl.LpVariable.dicts("upgrade", upg_pairs, 0, 1, cat=pl.LpBinary)m2 += pl.lpSum(upg_gain[pair] * x[pair] for pair in upg_pairs)for (s, u) in upg_pairs:m2 += x[(s, u)] <= (1 if s in selected_sites else 0)for s in selected_sites:m2 += pl.lpSum(x[(ss, u)] for (ss, u) in upg_pairs if ss == s) <= 1m2 += pl.lpSum(upg_cost[pair] * x[pair] for pair in upg_pairs) <= INVEST_BUDGETm2.solve(pl.PULP_CBC_CMD(msg=False))chosen_upgrades = [pair for pair in upg_pairs if pl.value(x[pair]) > 0.5]final_cap = {}for s in sites:cap = base_cap[s] * (1 if s in selected_sites else 0)for (ss, u) in chosen_upgrades:if ss == s:cap += upg_gain[(ss, u)]final_cap[s] = capTOTAL_CAP = sum(final_cap[s] for s in selected_sites)INV_USED = sum(upg_cost[pair] for pair in chosen_upgrades)print("Status:", pl.LpStatus[m2.status])print("Chosen upgrades:", chosen_upgrades if chosen_upgrades else "None")print(f"Invest used: {INV_USED} / {INVEST_BUDGET}")print("Final capacity (selected sites):", {s: final_cap[s] for s in selected_sites})print("Total final capacity:", TOTAL_CAP)print()if pl.LpStatus[m2.status] != "Optimal":raise RuntimeError("Part 2 did not solve to optimal. Check data/constraints.")
结果表明,在预算允许范围内,对 S1 与 S3 同时实施 U1 升级可以获得最大的产能提升,形成后续生产阶段的产能上限。

在选址与投资结果确定后,生产阶段关注的是运营层面的配置问题:如何在既定产能和资源约束下,安排生产与配送以实现利润最大化。
模型的连续型决策变量表示各工厂向各市场供应不同产品的数量,并允许在需求无法完全满足时产生缺货。目标函数综合考虑销售收入、生产成本、运输成本以及缺货惩罚;约束条件则包括需求平衡、产能限制、劳动力与材料上限,以及整体服务水平要求。
代码的整体逻辑是:在满足服务水平底线的前提下,将有限产能优先分配给“边际贡献更高”的市场与产品组合。
m3 = pl.LpProblem("Production_and_Shipping", pl.LpMaximize)ship = pl.LpVariable.dicts("ship",[(s, m, p) for s in selected_sites for m in markets for p in products],lowBound=0,cat=pl.LpContinuous)short = pl.LpVariable.dicts("short",[(m, p) for m in markets for p in products],lowBound=0,cat=pl.LpContinuous)m3 += pl.lpSum(price[p] * ship[(s, m, p)]- (base_unit_cost[p] + site_addon[s]) * ship[(s, m, p)]- ship_cost[(s, m)] * ship[(s, m, p)]for s in selected_sites for m in markets for p in products) - SHORT_PENALTY * pl.lpSum(short[(m, p)] for m in markets for p in products)for m in markets:for p in products:m3 += pl.lpSum(ship[(s, m, p)] for s in selected_sites) + short[(m, p)] == demand[(m, p)]if ALLOW_BACKORDER == 0:for m in markets:for p in products:m3 += short[(m, p)] == 0for s in selected_sites:m3 += pl.lpSum(ship[(s, m, p)] for m in markets for p in products) <= final_cap[s]m3 += pl.lpSum(labor_use[p] * ship[(s, m, p)] for s in selected_sites for m in markets for p in products) <= res_limit["labor"]m3 += pl.lpSum(mat_use[p] * ship[(s, m, p)] for s in selected_sites for m in markets for p in products) <= res_limit["material"]m3 += pl.lpSum(ship[(s, m, p)] for s in selected_sites for m in markets for p in products) >= SERVICE_LEVEL * TOTAL_DEMANDm3.solve(pl.PULP_CBC_CMD(msg=False))
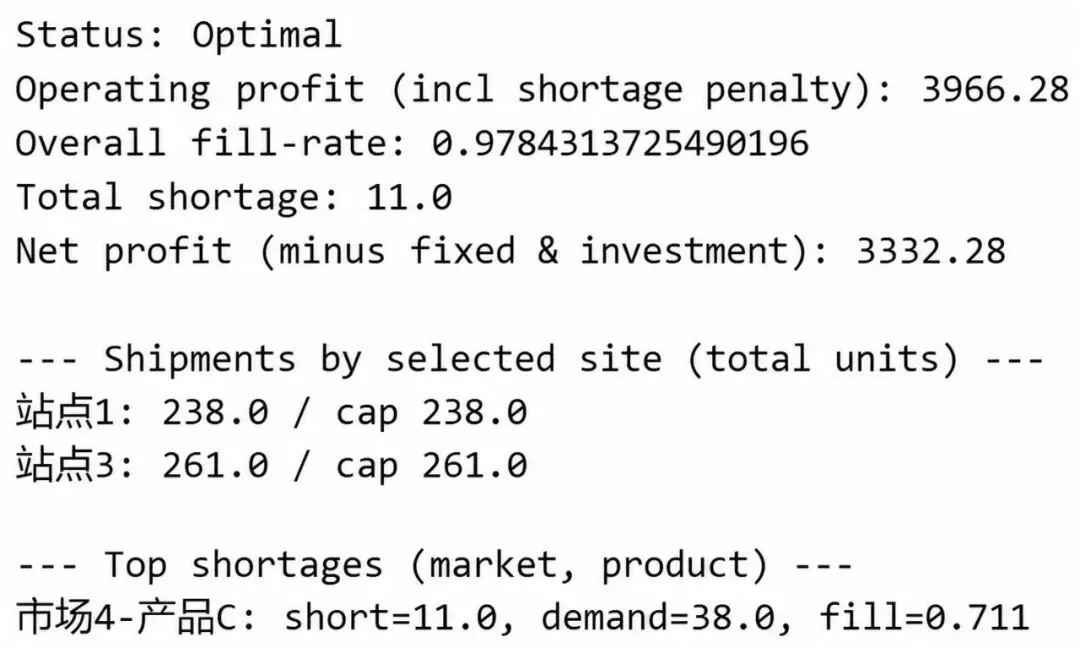


通过将选址、投资与生产三个决策阶段拆分建模,可以清晰地看到不同层级决策之间的约束传导关系。线性规划在此过程中并不依赖历史样本拟合,而是直接刻画“在给定规则下,什么配置是最优的”。
PuLP 提供了一种将数学模型与代码结构高度对齐的实现方式,使复杂运营问题可以被透明地建模、求解与复核。对于存在明确约束、且决策变量之间关系可线性刻画的场景,这类方法能够为实际决策提供稳定、可解释的定量支持。
声明:代码仅供学习使用,请勿用做任何商业行为!
重磅福利!为了更好地服务各位同学的研究,爬虫俱乐部将在小鹅通平台上持续提供金融研究所需要的各类指标,包括上市公司十大股东、股价崩盘、投资效率、融资约束、企业避税、分析师跟踪、净资产收益率、资产回报率、国际四大审计、托宾Q值、第一大股东持股比例、账面市值比、沪深A股上市公司研究常用控制变量等一系列深加工数据,基于各交易所信息披露的数据利用Stata在实现数据实时更新的同时还将不断上线更多的数据指标。我们以最前沿的数据处理技术、最好的服务质量、最大的诚意望能助力大家的研究工作!相关数据链接,请大家访问:(https://appbqiqpzi66527.h5.xiaoeknow.com/homepage/10)或扫描二维码:
对我们的推文累计打赏超过1000元,我们即可给您开具发票,发票类别为“咨询费”。用心做事,不负您的支持!
往期推文推荐 Stata入门:statsby命令详解—分组统计的“效率神器” Python实战:DrissionPage 一键查询商品历史价格 Stata中codebook命令介绍及应用
Stata绘制热力图 自动化报告生成:sum2docx与reg2docx深度应用指南 Python库:【Tableau】气候数据可视化 Stata | 从字节串到Unicode:Stata ustrfrom使用手册
Seminar|CEO言行不一,审计师如何“明察秋毫”?——一项关于诚信、审计与公司治理的深度研究
《赌神》 里的发哥能赢赌场?蒙特卡洛模拟:现实里“赌神”赢不了这5.26%”
Python | 别让Emoji毁了你的模型!Python机器学习中的Emoji “神翻译”指南 Stata爬虫——我的数据去哪里了?
python爬虫 | 获取港股基本信息
Stata入门:tempvar命令与tempfile命令详解
Python绘图:用matplotlib库绘制好看的折线图
Seminar | 注意力独特性与企业绩效:增长行动的中介作用
Stata | 从sum2docx到reg2docx——基于《中国工业经济》期刊文章的结果输出 Seminar | 邻避效应:内在动机与企业污染治理
Stata爬取豆瓣读书,一键获取你的读书清单
Seminar | 自动化对企业报告质量的影响
识别处理重复值duplicates命令
Pandas 数据筛选的多种方法
Python交互可视化实战:构建动态数据仪表盘 关于我们 微信公众号“Stata and Python数据分析”分享实用的Stata、Python等软件的数据处理知识,欢迎转载、打赏。我们是由李春涛教授领导下的研究生及本科生组成的大数据处理和分析团队。
我们团队一直为广大用户提供数据采集和分析的服务工作,如果您有这方面的需求,请发邮件到statatraining@163.com。
此外,欢迎大家踊跃投稿,介绍一些关于Stata和Python的数据处理和分析技巧。
投稿邮箱:statatraining@163.com投稿要求:1)必须原创,禁止抄袭;2)必须准确,详细,有例子,有截图;注意事项:1)所有投稿都会经过本公众号运营团队成员的审核,审核通过才可录用,一经录用,会在该推文里为作者署名,并有赏金分成。 2)邮件请注明投稿,邮件名称为“投稿+推文名称”。3)应广大读者要求,现开通有偿问答服务,如果大家遇到有关数据处理、分析等问题,可以在公众号中提出,只需支付少量赏金,我们会在后期的推文里给予解答。

随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- Python量化实战:用AKShare搭建自己的日线数据库,手把手完整教程
- 豆包AI之Python 绘制带断裂的柱状图(解决数值差距过大问题)
- Linux内核高危0day漏洞Dirty Frag:PoC已公开,暂无补丁(附临时缓解措施)
- Python | ConvLSTM NDVI预测
- Python开发从零开始-10.1-基础语法(控制结构-顺序和条件)
- Python常用正则表达式速查手册,建议收藏!
- Python数据分析:Pandas最详细教程来了!
- micawber,一个灵巧的 Python 库
- Linux Kernel "Dirty Frag" 本地权限提升高危漏洞风险通告QVD-2026-24699
- Python 编码问题:locale 影响字符串排序、正则表达式中的中文...你都会吗?
