大家好,我是蟹老板~
前几天,公众号后台收到有留言,说看 Linux 内核源码像是在读天书。特别是看到网络协议栈那一块,满屏幕的 sk_buff 绕得人头晕。
想真正搞懂 LInux 网络协议栈,先过了sk_buff这一关再说别的。
这还真不是我在危言耸听。sk_buff —— 套接字缓存,它是 Linux 内核网络子系统的绝对核心。所有的数据包,不管是收还是发,都被装在这个结构体里。不夸张地说:你写的每一行涉及网络的操作,背后都有它在兜底。
所以,我今天想和大家聊聊 sk_buff。读完这篇文章,我不敢打包票说你马上就精通内核,但你至少敢去改改内核代码了。
一、为什么 sk_buff 是网络栈的命根子?
很多人学Linux网络,一开始都在背协议。TCP 三次握手、滑动窗口、拥塞控制。背得飞起,背完以为自己入门了。
其实不然。
协议栈里的所有数据,不管是应用层的HTTP请求,还是链路层的以太网帧,都要靠一个“容器”来承载、传递、处理。这个容器,就是 sk_buff(全称 socket buffer)。
你可以把它理解成网络数据的“快递盒”。数据包从网卡进来,到应用程序出去,每一层协议的解析、封装,本质上都是在操作这个“快递盒”——要么给盒子加层包装(加协议头),要么拆层包装(解协议头),要么调整盒子里的东西(修改数据)。
sk_buff 被设计成整个网络栈的枢纽,几乎所有协议操作都离不开它。不理解它的设计逻辑、数据结构和操作方式,你对协议栈的理解,大概率还停留在“会背八股”的阶段。,没法真正上手开发、排查问题。
不服气?
请你作答以下问题:
CPU 飙高了,为什么?
驱动丢包了,为什么?
GRO 没生效,为什么?
内核 panic 了,又为什么?
二、sk_buff 是什么?
Linux 网络栈,本质上是“包”的流动,而 sk_buff。就是 Linux 内核里“数据包”的唯一合法载体。
注意这句话:
不是“之一”。而是“唯一”。
不管是网卡接收的原始数据,还是应用程序发送的业务数据,无论你是: TCP、UDP、ICMP、VLAN、VXLAN、Netfilter、eBPF、qdisc 最后处理的,都是 sk_buff。它不仅装着数据包本身,还记录着数据包的长度、协议类型、内存位置等关键信息,供内核各层协议调用。
你可以把它理解成: 网络栈中的“快递盒子” ,真正的数据放里面, 协议头贴外面, 内核各层模块不断修改这个盒子,最后交给网卡,所以 sk_buff 有点像“网络栈里的 std::string”。
看着简单, 实际上内部还蛮复杂的,如果你是第一次看源码,真的容易裂开。
sk_buff 的设计,设计哲学可以用六个字概括:高性能、零拷贝。理解这6个字,就能抓住它的本质,我也不知道这么说对不对,反正我是这么记的。
第一个,零拷贝支撑。传统的内存操作,数据会在用户态和内核态之间反复拷贝,开销极大。而 sk_buff 通过指针偏移,实现了“数据不动,指针动”——比如给数据包加协议头时,不用拷贝整个数据,只需要移动指针,预留出头部空间即可,极大减少了拷贝开销。这一点被广泛用在高吞吐场景中,比如DPDK就借鉴了类似思路。
第二个,内存弹性管理。网络数据包的长度是不固定的,从几十字节(比如ARP包)到几KB(比如TCP包)都有可能。sk_buff 支持线性区和分页区结合的内存布局,既能高效存储小数据包,也能灵活处理大数据包,避免内存浪费。
第三个,协议无关抽象。链路层、网络层、传输层的协议各不相同,对数据的处理方式也不一样。sk_buff 把这些差异屏蔽掉,给所有协议提供了统一的操作接口——不管是以太网头、IP头还是TCP头,都能通过 sk_buff 的API快速访问、修改,不用关心底层内存细节。
很多人问,为什么不直接用一个简单的字符数组?
因为网络包在传输过程中,每一层协议都要往上贴标签(加包头)或者撕标签(剥离包头)。如果是普通数组,每次加头都要进行内存拷贝,CPU 早就被累瘫了。
所以 sk_buff 被设计成了一个内存弹性管理的怪胎。它在内存里预留了一堆空间,通过移动几个指针就能实现“加头”和“去尾”,完全不需要动真实的数据。
三、数据结构剖析
很多人怕看 sk_buff 的源码,觉得太复杂。其实不用死记所有成员,真正高频的成员。其实就几个,能应对80%的开发和排查场景。
3.1 必须掌握的核心成员
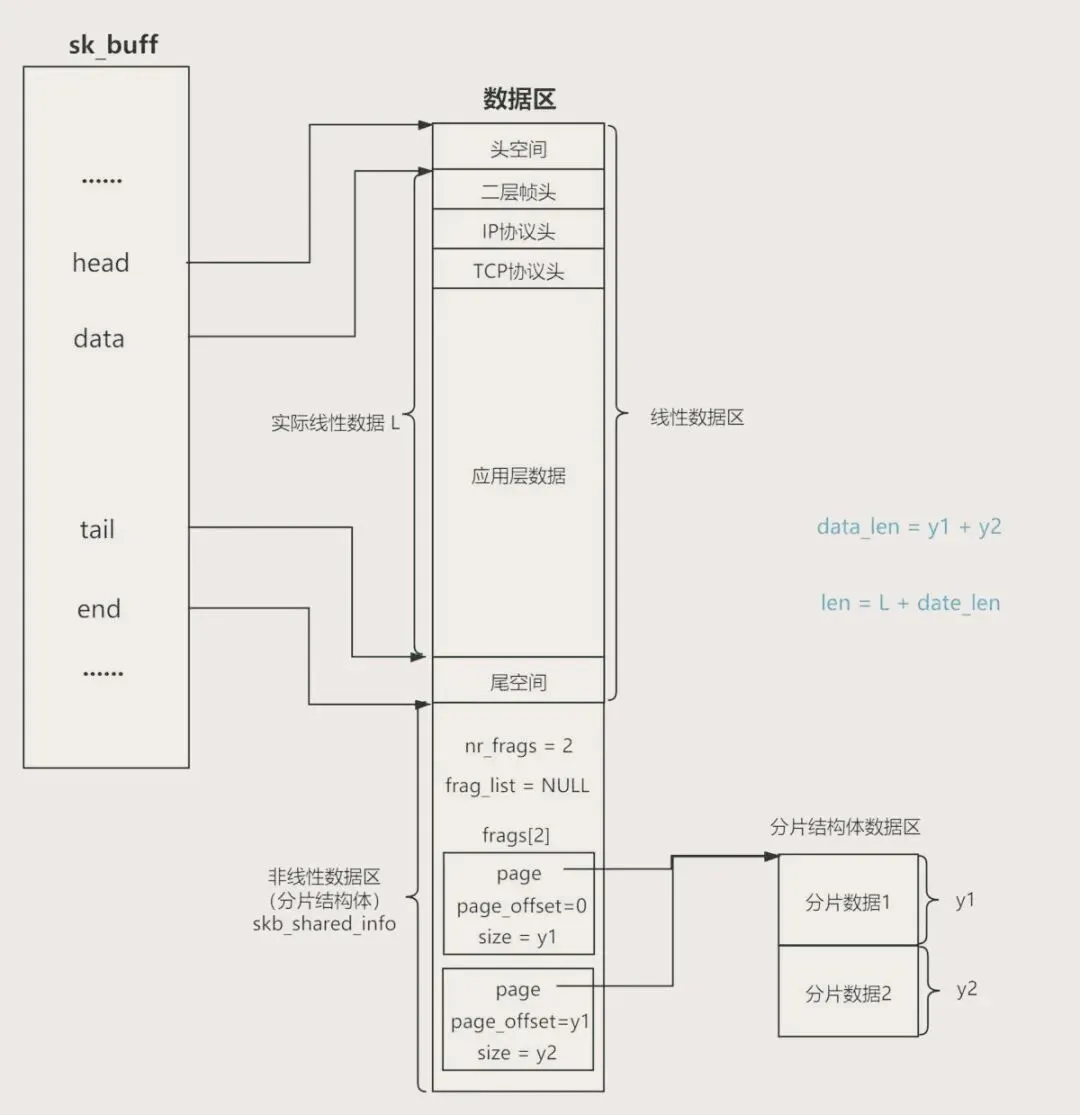
data、tail、end,这三个核心指针,决定了数据包在 sk_buff 中的位置。
data:指向数据包的起始位置(也就是有效数据的开头);tail:指向数据包的结束位置(有效数据的末尾);end:指向 sk_buff 缓冲区的末尾(整个内存块的最后)。
len、data_len、mac_len。len 是整个数据包的总长度(有效数据+所有协议头);data_len 是分页区的数据长度(如果数据包太大,会分成线性区和分页区存储);mac_len 是链路层头部(比如以太网头)的长度,用来快速定位网络层头部。
还有一个关键结构:skb_shared_info,它用来管理分页数据。当数据包超过线性区的长度时,多余的数据会被存放在分页区,skb_shared_info 就记录着分页的数量、每个分页的地址等信息,避免数据丢失。这里容易被忽略,后面避坑指南会重点说。
举个例子:当你给数据包加一个TCP头时,不需要拷贝数据,只需要把 data 指针向前移动(skb_push操作),腾出的空间就用来存放TCP头——这就是零拷贝的核心实现,是不是很巧妙?
3.2 内存布局
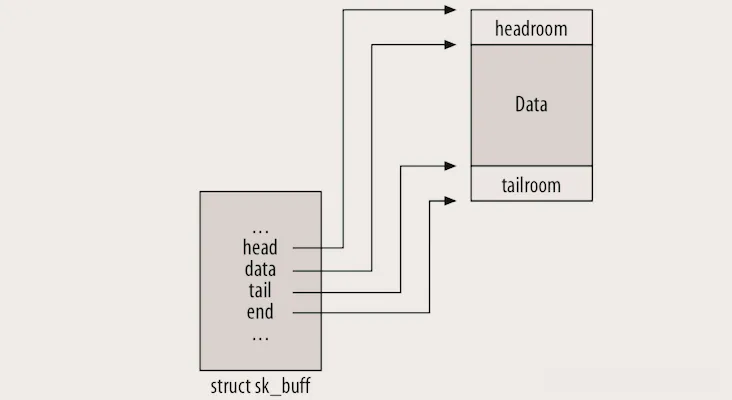
sk_buff 的内存布局,其实可以分成三个部分:Headroom、Data、Tailroom,新手记这三个分区就够了。
| Headroom | Data | Tailroom | ^ ^ data tailend --------------------^
Headroom:头部预留空间,用来存放后续要添加的协议头(比如从链路层到网络层,需要加IP头,就用这里的空间)。这个空间是在分配 sk_buff 时预留的,避免后续添加协议头时,需要重新扩容、拷贝数据,这也是提升效率的关键技巧之一。
Data:有效数据区,存放实际的数据包内容(从应用层数据到各层协议头),data 和 tail 指针之间的区域,就是Data区。
Tailroom:尾部预留空间,用来存放后续要添加的尾部数据(比如CRC校验码),或者临时扩展数据。
sk_buff 的内存分为线性区和分页区:线性区是连续的内存,适合存小数据包,速度快;分页区是离散的内存页,适合存放大数据包,由 skb_shared_info 管理。这样的设计特别合理,既能保证小数据包的处理效率,又能灵活应对大数据包,避免出现连续内存分配失败的情况。
还有一点要注意,sk_buff 有自己的内存分配器和缓存池,内核会提前分配一批 sk_buff 缓存,不用每次用的时候都重新分配、释放,这样能减少很多开销——这也是高吞吐场景下,优化 sk_buff 性能的关键,大家可以记一下。
3.3 链表与引用计数
sk_buff 通常是用双向链表的形式存在的,通过 next 和 prev 指针串起来,这样内核就能批量处理多个数据包,比如一次接收多个数据包,形成一个链表统一处理,效率会高很多。
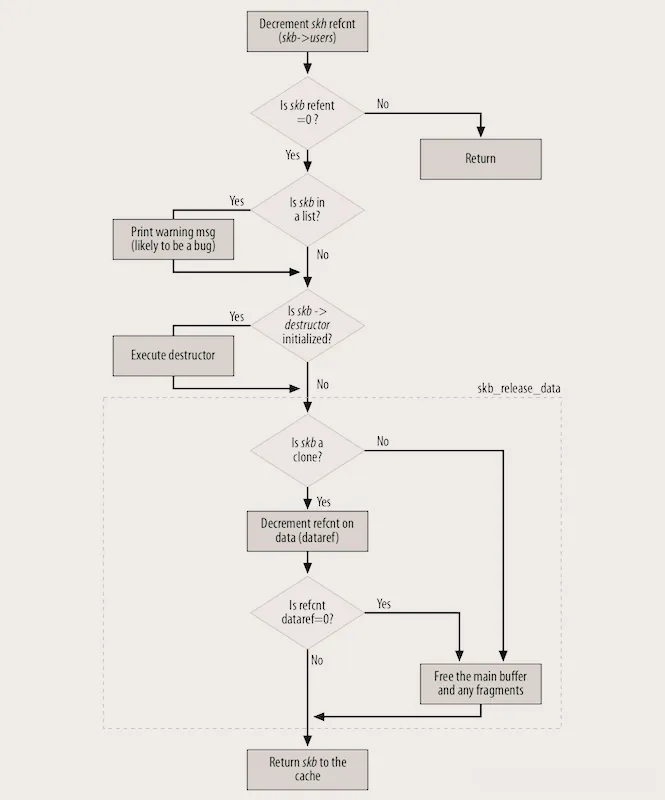
refcnt (引用计数)记着当前有多少个内核组件(比如协议层、驱动、应用程序)在使用这个 sk_buff,只有当 refcnt 减到0的时候,内核才会释放这个 sk_buff 的内存,就掌握着 sk_buff 的“生死大权”。
这里特别容易踩坑,我跟大家说句实在的:如果引用计数处理不好,要么导致内存泄漏(refcnt一直不为0,内存没法释放),要么导致重复释放(refcnt减到0后,又去操作 sk_buff),这两种情况都会引发内核panic——我之前就踩过这个坑。
四、生命周期全流程
sk_buff 的生命周期其实就是:分配→初始化→接收/发送→释放,全程闭环。大家只要掌握这个流程,就知道每个阶段该做什么、不该做什么,不容易出错。
4.1 分配与初始化
分配 sk_buff 主要用两个函数:alloc_skb() 和 dev_alloc_skb()。
dev_alloc_skb(size):这是最常用的分配函数,特别省心,它会自动预留16字节的Headroom(适合链路层处理,比如加以太网头),而且会把 sk_buff 加入内核缓存池,效率更高,适合网卡接收路径这种高频场景,大家平时用,优先选这个。
alloc_skb(size, gfp_mask):这个函数更灵活,但也更麻烦,需要手动预留Headroom(用 skb_reserve() 函数),gfp_mask 参数还能指定内存分配的场景(比如是否允许睡眠),适合一些自定义场景。但新手很容易忘记预留Headroom,导致后面操作报错,大家用的时候一定要注意。
初始化的核心,其实就是预留Headroom。一般用 skb_reserve(skb, len) 函数,比如预留16字节,就写 skb_reserve(skb, 16),这样后面加以太网头、IP头的时候,就不用临时扩容了,省很多事。这里提醒一句,skb_reserve() 只能在分配 sk_buff 后、添加数据前调用,不然会覆盖有效数据,这点一定要记牢。
4.2 接收路径
数据包的接收路径说简单点就是:网卡接收数据→DMA填充到 sk_buff→协议栈逐层解析。
经典 RX 流程:
NIC DMA ↓Ring Buffer ↓NAPI poll ↓构造 skb ↓eth_type_trans() ↓IP 层 ↓TCP/UDP
这里的重点是: DMA 并不会直接写 skb 结构。 DMA 写的是 data buffer。 skb 只是描述符。
网卡收到数据后,不会直接通知CPU(主要是避免频繁中断,太耗资源),而是通过DMA(直接内存访问),把数据直接写入内核提前分配好的 sk_buff 里——这一步也是零拷贝的体现,数据不用经过CPU中转,效率特别高。
然后,网卡会触发硬中断,通知内核“有数据进来了”,内核会通过ksoftirqd线程,在软中断上下文中轮询接收环缓冲区,把填充好数据的 sk_buff 交给协议栈。之后就从链路层开始,逐层解析协议头(先解以太网头,再解IP头,最后解TCP/UDP头),最终把有效数据交给应用程序。
这里必须提醒大家一句:接收路径中,sk_buff 是内核分配的,应用程序只能读,不能直接修改,不然会破坏协议栈的正常处理,很容易出问题。
4.3 发送路径
发送路径和接收路径正好相反,就是:应用程序数据→协议栈逐层封装→sk_buff 写入网卡发送队列。
用户态 write/send ↓TCP 封装 ↓IP header ↓MAC header ↓qdisc ↓driver xmit ↓DMA
应用程序调用send()函数后,数据就进入内核了,内核会分配一个 sk_buff,把应用数据写入Data区,然后从传输层开始,逐层加协议头(先加TCP/UDP头,再加IP头,最后加以太网头)——每加一层协议头,就用 skb_push() 移动一下 data 指针,腾出头部空间,操作起来很简单。
封装完成后,sk_buff 会被交给网卡驱动,驱动会把 sk_buff 里的数据,转换成网卡能理解的格式,填充到发送环缓冲区的描述符里,最后由网卡发送到网络中。发送完成后,驱动会处理中断,把已经发送的 sk_buff 释放掉,整个发送流程就结束了。
4.4 销毁与释放
sk_buff 的释放,核心就是管理好引用计数,常用的函数有 kfree_skb() 和 consume_skb(),还有 skb_clone() 和 skb_copy() 两个辅助函数,大家记清楚它们的用法,别用混了。
kfree_skb(skb)这个函数会直接减少 sk_buff 的引用计数,如果引用计数减到0,就会释放内存。但有个坑,这个函数不能在软中断中直接调用,后面避坑指南里,我会详细说这个问题。
consume_skb(skb)函数就安全多了,专门用于软中断上下文,能安全地减少引用计数,避免内存泄漏或内核panic,比 kfree_skb() 靠谱,软中断里释放 sk_buff,优先用这个。
还有一个常用场景:当需要复制一个 sk_buff 时,新手很容易直接用 skb_copy()(完全拷贝,数据和结构都复制),但这样开销很大,没必要。如果只是需要共享数据,不用修改,建议用 skb_clone()——只拷贝 sk_buff 的结构,不拷贝数据,数据通过引用计数共享,效率高很多。但要注意,克隆后不能修改共享数据,不然会导致多个 sk_buff 数据混乱,踩过这个坑的都懂。
五、必API
跟大家说句实在的,不用死记所有API,掌握下面这几个,就能应对大部分 sk_buff 的操作场景,真的绝了,我平时开发,也主要用这几个。
5.1 数据指针调整:四个核心API
这四个API,都是用来调整 data 和 tail 指针的,对应不同的操作场景,大家记清楚它们的作用,别用反了,用反了很容易出问题。
skb_reserve(skb, len):作用是预留Headroom,把 data 和 tail 指针同时向后移动 len 字节,腾出头部空间。只能在分配 sk_buff 后、添加数据前调用,主要用来预留协议头空间,这个之前咱们说过,就不啰嗦了。
skb_put(skb, len):用来向 sk_buff 的尾部添加数据,把 tail 指针向后移动 len 字节,len 就是添加的数据长度。比如把应用数据写入 sk_buff 时,就用这个函数;如果数据本身包含完整的协议头,也可以用这个函数直接拷贝整个数据包,很方便。
skb_push(skb, len):用来向 sk_buff 的头部添加数据(比如加协议头),把 data 指针向前移动 len 字节,len 就是协议头的长度。比如加IP头时,就写 skb_push(skb, sizeof(struct iphdr)),简单好记。
skb_pull(skb, len):用来从 sk_buff 的头部移除数据(比如解析完协议头后,把协议头丢弃),把 data 指针向后移动 len 字节,len 就是要移除的长度。比如解析完以太网头后,用 skb_pull(skb, skb->mac_len) 丢弃以太网头,特别方便。
5.2 协议头快捷访问
解析协议头的时候,大家别傻乎乎地手动计算指针偏移,太麻烦了,sk_buff 早就给我们提供了快捷方式,能快速获取L2(链路层)、L3(网络层)、L4(传输层)的头指针,省很多事。
比如:skb->mac_header 指向L2头(以太网头),skb->network_header 指向L3头(IP头),skb->transport_header 指向L4头(TCP/UDP头)。直接通过这些指针,就能快速访问协议头的成员,不用自己计算 data 指针的偏移量,效率高多了。
还有一个常用标志:ip_summed,用来控制校验和卸载。开启校验和卸载后,内核会把校验和计算交给网卡硬件处理,能减少CPU开销,这也是高吞吐场景的优化技巧之一。比如设置 skb->ip_summed = CHECKSUM_UNNECESSARY,就表示网卡已经完成校验和计算,内核不用再处理,大家可以记一下。
5.3 高级特性
对于大数据包(超过MTU),sk_buff 支持分片链表 frag_list,能把大数据包分成多个小分片,每个分片都是一个独立的 sk_buff,通过 frag_list 串起来。这样不用一次性分配大量连续内存,也能处理大数据包,特别灵活。
还有GSO/TSO支持,大家也可以了解一下:GSO(通用分段卸载)和TSO(TCP分段卸载),都是把分段操作交给网卡硬件处理,内核只需要处理一个大数据包,能减少内核的处理压力,提升发送效率。另外,sk_buff 还支持时间戳记录,能记录数据包的接收、发送时间,排查延迟问题时特别有用。
六、性能优化
光会用 sk_buff 还不够,实际开发中,经常会遇到 sk_buff 导致的性能瓶颈,比如高吞吐下分配延迟高、CPU飙高等。下面结合我自己遇到的实战场景,给大家分享我的“问题→方案→验证”经验。
6.1 问题:高吞吐下 sk_buff 分配延迟过高
场景:高并发、高吞吐的场景(比如网关、负载均衡),经常出现 sk_buff 分配失败,导致丢包、延迟升高,特别影响业务。
方案:调大 skbmem_max 参数(这是内核 sk_buff 内存池的最大容量),同时启用内存池预分配,让内核提前分配足够的 sk_buff 缓存,避免频繁分配内存,减少延迟。
具体操作:修改 /etc/sysctl.conf 文件,添加 net.core.skbmem_max = 16777216(也就是16MB,大家可以根据自己的实际场景调整),然后执行 sysctl -p 生效,很简单。
验证:执行 netstat -s | grep -i "socket fails",查看 sk_buff 分配失败的次数,如果次数为0或者明显减少,就说明优化生效了,亲测好用。
6.2 问题:线性区频繁扩容导致拷贝开销
场景:数据包大小波动很大,经常出现线性区空间不足,需要扩容,导致频繁拷贝数据,CPU开销居高不下,影响性能。
方案:分配 sk_buff 时,合理估算Headroom和数据长度,一次分配足够的空间,避免后续扩容。比如根据自己的业务场景,预留20字节Headroom(应对各种协议头),数据长度按最大可能值分配,这样就能减少拷贝开销。
验证:用 perf top -g 观察内核函数热点,如果 skb_copy 函数的占比明显降低,就说明优化生效了。我之前优化过一个网关,就用的这个方法,CPU使用率直接降了20%,有点东西吧?
6.3 问题:硬件卸载未生效,CPU飙高
场景:明明开启了校验和卸载、GSO/TSO,但CPU使用率依然很高,排查了半天,发现硬件卸载根本没生效,等于白设置了。
方案:先确认网卡及驱动是否支持TSO/GRO(GRO是接收侧的分段卸载),如果支持,就用 ethtool 命令开启相应选项;如果不支持,就升级网卡驱动。
具体操作:执行 ethtool -K eth0 tso on gro on(开启TSO和GRO,eth0是网卡名称,大家根据自己的网卡名称修改)。另外,对于ARM嵌入式设备,还要确认CPU调速器是否设置为performance模式,避免CPU低频导致处理瓶颈,这个细节很容易被忽略。
验证:执行 ethtool -k eth0 | grep generic,查看TSO、GRO是否为on,如果显示on,就说明硬件卸载已经生效了。
6.4 零拷贝技术选用指南
零拷贝是提升 sk_buff 性能的核心,常用的有两种方式,大家根据自己的场景选择,不用盲目跟风。
DMA映射:适合网卡接收/发送场景,数据直接通过DMA在网卡和内核内存之间传输,不经过CPU中转,能减少CPU开销,这也是内核默认的零拷贝方式。如果是高频访问的DMA缓冲区,建议用流式DMA映射+显式同步,性能会更好。
sendfile()/splice():适合应用程序向网卡发送文件的场景(比如静态文件服务器),数据直接从用户态文件缓存,通过 sk_buff 发送到网卡,避免用户态和内核态之间的拷贝,能提升发送效率,大家可以根据自己的业务场景选用。
6.5 调试与监控:快速定位问题
遇到 sk_buff 相关的问题(比如丢包、延迟、内存泄漏),大家不用慌,用下面这两个工具,能快速定位问题,节省排查时间,我平时排查问题,全靠它们。
bpftrace:能追踪 sk_buff 的流动过程,比如追踪 sk_buff 的分配、释放、协议头修改等操作。命令示例:bpftrace -e 'kprobe:alloc_skb { printf("alloc skb: %p\n", arg0); }',能快速找到 sk_buff 分配异常的地方,特别好用。
dropwatch:专门用来定位丢包点,执行 dropwatch -l kas,就能实时查看内核丢包的位置。比如丢包发生在 __netif_receive_skb_core 函数,大概率是bonding模式配置错误导致的,我之前排查银行系统丢包时,就用这个工具找到了问题根源,省了很多事。
七、避坑指南
这一节,全是事故。真的,每个坑我都见过。
7.1 错误:在软中断中直接调用 kfree_skb()
错误代码示例:
// 软中断上下文staticvoidsoftirq_handler(struct softirq_action *h) { struct sk_buff *skb = get_skb(); if (skb) { kfree_skb(skb); // 错误:软中断中直接调用kfree_skb() }}
严重后果:软中断上下文是不能睡眠的,而 kfree_skb() 在某些情况下会触发内存回收,可能导致睡眠,进而引发内核panic,或者内存泄漏(skb无法被正确释放)。我之前就因为这个错误,导致服务器重启,被领导骂了一顿,现在想起来还记忆犹新。
正确修复:改用 consume_skb(),这个函数专门用于软中断上下文,能安全地释放 sk_buff,同时还会检查 skb->destructor(如果有自定义的销毁函数,会自动调用),比 kfree_skb() 安全多了。
// 正确写法staticvoidsoftirq_handler(struct softirq_action *h) { struct sk_buff *skb = get_skb(); if (skb) { consume_skb(skb); // 正确:软中断中用consume_skb() }}
7.2 错误:克隆后修改私有数据未复制
错误模式:用 skb_clone() 克隆 sk_buff 后,直接修改克隆后的 sk_buff 的私有数据(比如 skb->cb),还以为克隆后的 sk_buff 是独立的,随便改都没事。
严重后果:skb_clone() 只克隆 sk_buff 的结构,不克隆私有数据和有效数据,私有数据是共享的。你修改克隆后的私有数据,原 sk_buff 的私有数据也会被修改,进而引发协议状态错误(比如TCP连接异常、数据包解析错误),排查起来特别麻烦。
正确修复:如果需要修改私有数据,或者需要独立的数据空间,就别用 skb_clone() 了,改用 skb_copy(),完全拷贝 sk_buff 的结构和数据,确保数据独立;如果不需要修改数据,只是共享,再用 skb_clone(),这样就不会踩坑了。
7.3 错误:忽略 skb_shared_info 中的分页引用
错误模式:释放 sk_buff 时,只调用 kfree_skb(),完全忽略了 skb_shared_info 中的分页数据(frag_list),没有释放分页内存,以为这样就完事了。
严重后果:分页内存没法被释放,会导致内存泄漏,长期运行后,内核内存会被耗尽,服务器会出现卡顿、丢包,甚至panic。我之前排查一个内存泄漏问题,查了整整三天,最后才发现,就是忽略了分页引用的释放,当时真的欲哭无泪。
正确修复:释放 sk_buff 前,先遍历 skb_shared_info 中的 frag_list,对每个分页调用 put_page() 释放分页内存,然后再调用 kfree_skb() 释放 sk_buff 本身,一步都不能少。
7.4 错误:在 NAPI 轮询中睡眠或调度
错误模式:在NAPI(New API)轮询函数中,调用 msleep()、schedule() 等会导致睡眠或调度的函数,或者执行一些耗时操作,觉得没什么问题。
严重后果:NAPI轮询运行在软中断上下文,是不能睡眠或调度的,否则会导致软死锁(整个软中断被阻塞,没法处理其他数据包),进而导致吞吐量崩塌,服务器无法正常处理网络请求。尤其是在ARM嵌入式设备上,这个问题会更明显,因为单队列网卡的中断处理,全靠一个CPU核心。
正确修复:在NAPI轮询中,严格使用原子操作,避免耗时操作;如果有耗时任务(比如复杂的数据处理),就把它推入工作队列(workqueue),由内核线程在进程上下文处理,这样就不会阻塞NAPI轮询了。
最后想跟大家说一句,sk_buff 是Linux网络栈的“基石”,也是入门网络栈的“敲门砖”。
它其实不是“一个结构体”。
而是:
Linux 网络栈的统一数据模型
协议栈所有层,都围绕它协作。
你理解了 skb。
很多以前模模糊糊的问题。会突然串起来。
比如:
为什么 GRO 能减少 CPU
为什么 TSO 能提升吞吐
为什么 clone 比 copy 快
为什么 headroom 不够性能会崩
为什么 page frag 能减少大包开销
这些东西。会彻底通。
如果大家想进一步深入学习,下面这几个方向可以看看,都是 sk_buff 的进阶内容,适合有一定基础后再学,难度不算太高:
eBPF 如何直接操作 sk_buff:eBPF 是Linux内核的动态追踪工具,通过 bpf_skb_load_bytes、bpf_skb_store_bytes 等函数,可以直接读取、修改 sk_buff 中的数据,不用修改内核源码,适合调试和性能优化;
DPDK 绕过内核的 sk_buff 思路对比:DPDK 为了追求极致性能,绕开了内核协议栈,自己实现了一套类似 sk_buff 的数据结构(mbuf),通过用户态驱动直接操作网卡,减少内核开销,对比两者的设计思路,能更深入理解 sk_buff 的局限性和优势;
现代多队列网卡与 NAPI 协同原理简述:多队列网卡可以将不同的数据包分配到不同的CPU核心,结合NAPI轮询,能提升并发处理能力,而 sk_buff 的链表和引用计数机制,是实现多队列协同的关键,理解两者的协同原理,能更好地优化高并发场景的性能。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
