手搓 Python /JMP搞定可靠性中的 Weibull 数据分
- 2026-07-01 14:11:39
所有原创文章均可转载,标记出处即可 推荐阅读:
----------以下为正文---------Weibull 的基本介绍可以看这两篇:
1. 可靠性角度下的威布尔分布/Weibull Distribution
2. 【数据分析|十七】一文看懂可靠性中的威布尔分布/Weibull Distribution
知道这些东西又怎么样呢?今天用python 和JMP 结合真实的应用场景,手搓一下weibull
一、试验数据
还是给出假数据,对于确定数据、删失数据概念不再赘述;数据如下:
确定数据:5个样品在[450, 520, 680, 750, 810]小时时失效;
区间删失:2个样品[400, 600], 2个样品[600, 800], 3个样品[800, 1000]分别失效;
右删失:3个样品做到1000小时没有失效,终止试验;14个样品做到1500小时没有失效,终止试验;
二、python 代码
import numpy as npfrom scipy.optimize import minimizefrom scipy.special import gamma# =====================================================================# 1. 录入数据 (包含 确切失效、区间失效、右删失 三种类型)# =====================================================================# 1.1 确切失效时间格式: (发生故障的具体时间 t, 数量 qty)exact_failures = [(450, 1),(520, 1),(680, 1),(750, 1),(810, 1)]# 1.2 区间失效时间格式: (起始时间 t1, 结束时间 t2, 数量 qty)interval_failures = [(400, 600, 2), # 400到600小时巡检时,发现坏了2个(600, 800, 3), # 600到800小时巡检时,发现坏了3个(800, 1000, 3) # 800到1000小时巡检时,发现坏了3个]# 1.3 悬挂/右删失时间格式: (中止测试时产品仍完好的时间 t, 数量 qty)suspensions = [(1000, 3), # 有 3 个产品跑了 1000 小时没坏,中止了(1500, 14) # 有 14 个产品跑了 1500 小时没坏,结束测试]# =====================================================================# 2. 定义负对数似然函数 (Negative Log-Likelihood)# =====================================================================def neg_log_likelihood(params):beta, eta = params# 设定物理边界:形状参数和尺度参数都必须大于0if beta <= 0 or eta <= 0:return np.inflog_likelihood = 0.0# 2.1 计算【确切失效数据】的似然 (使用的是 Weibull 概率密度函数 PDF)for t, q in exact_failures:# PDF = (beta/eta) * (t/eta)**(beta-1) * exp(-(t/eta)**beta)pdf = (beta / eta) * ((t / eta)**(beta - 1)) * np.exp(-(t / eta)**beta)if pdf <= 1e-15: return np.inflog_likelihood += q * np.log(pdf)# 2.2 计算【区间失效数据】的似然 (使用的是 F(t2) - F(t1) 累积概率差)for t1, t2, q in interval_failures:# F(t) = 1 - exp(-(t/eta)**beta)p = np.exp(-(t1 / eta)**beta) - np.exp(-(t2 / eta)**beta)if p <= 1e-15: return np.inflog_likelihood += q * np.log(p)# 2.3 计算【悬挂/右删失数据】的似然 (使用的是 可靠度函数 R(t))for t, q in suspensions:# R(t) = exp(-(t/eta)**beta)log_likelihood -= q * (t / eta)**beta# 优化器默认求函数的最小值,所以我们要返回负的对数似然值return -log_likelihood# =====================================================================# 3. 运行优化器求解最佳参数# =====================================================================# 给出初始猜测值 [beta_guess, eta_guess]# 对于常规机械或电子产品,可以粗略猜测 beta=1.5, eta 取大致的试验平均时长initial_guess = [1.5, 2000.0]# 使用 Nelder-Mead 算法寻找极值点 (该算法对无需计算梯度的似然函数非常稳定)result = minimize(neg_log_likelihood, initial_guess, method='Nelder-Mead')beta, eta = result.x# =====================================================================# 4. 计算工程中常用的衍生指标# =====================================================================# B10 寿命:预期有 10% 产品发生失效的时间b10 = eta * (-np.log(0.9))**(1/beta)# MTTF 平均寿命:期望寿命mttf = eta * gamma(1 + 1/beta)# =====================================================================# 5. 打印结果对齐商业软件# =====================================================================print("=" * 45)print("📊 混合数据 Weibull 极大似然估计 (MLE) 结果")print("=" * 45)print(f"优化状态 : {'✅ 成功'if result.success else'❌ 失败'}")print(f"形状参数 (Beta) : {beta:.3f}")print(f"尺度参数 (Eta) : {eta:.1f} (在 JMP 中也称为 Alpha)")print("-" * 45)print(f"B10 寿命 : {b10:.1f} 小时")print(f"MTTF (平均寿命) : {mttf:.1f} 小时")print("=" * 45)
结果如下:

三、JMP分析对比
一般不用这么麻烦,直接用现成工具;
JMP数据格式
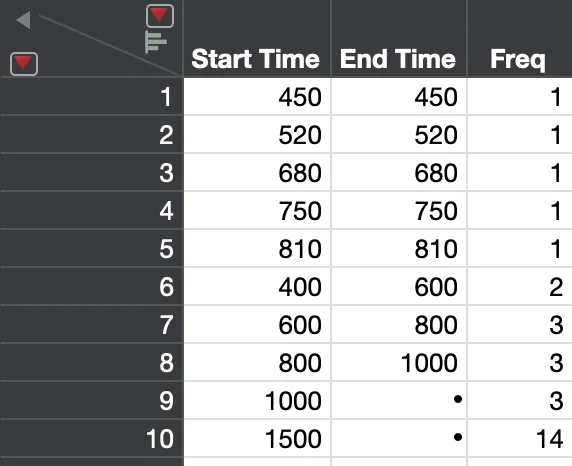
结果:
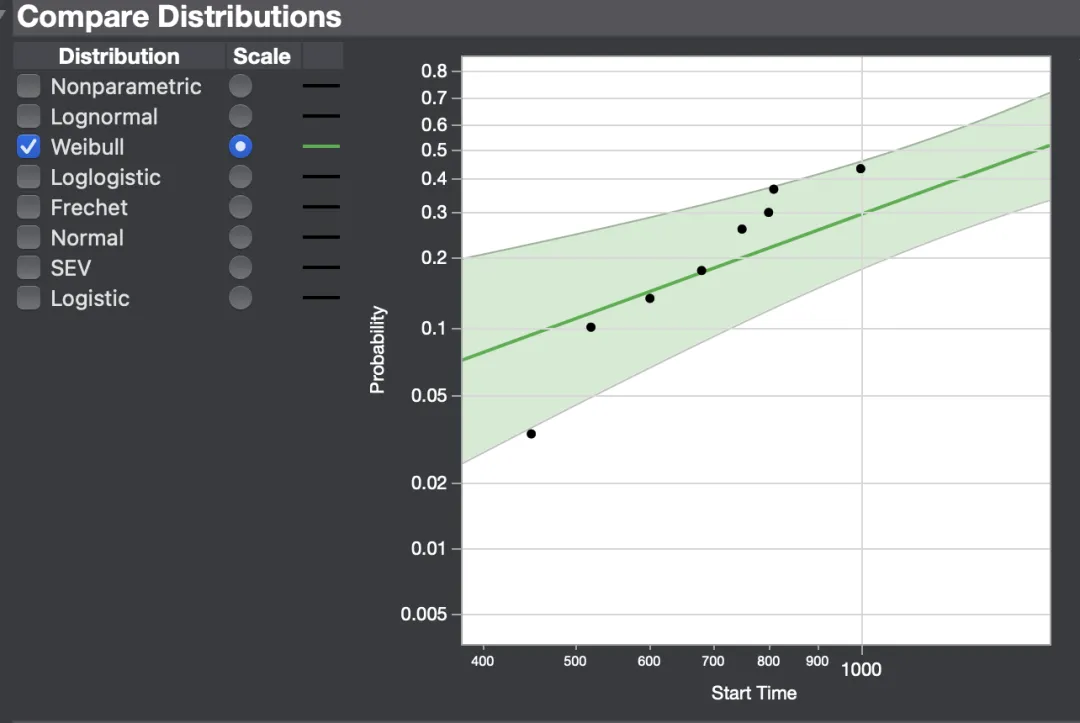
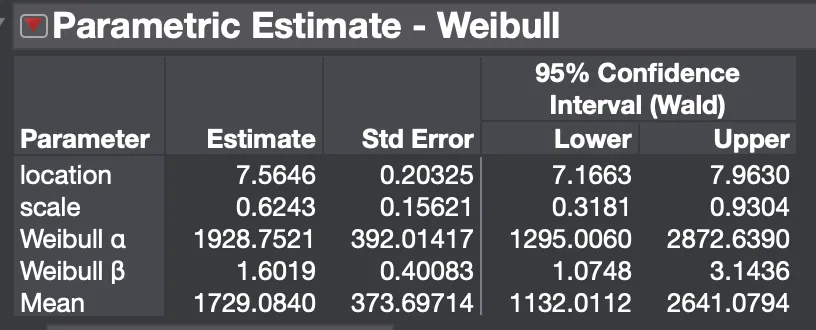
看,两个结果非常接近。(当然:python设置参数和一些似然计算方法对结果有一定影响,导致两个结果有差异)
然后呢?算出来这些东西了又干嘛?
四、Weibull 分析价值
1. 利用β 定位失效模式
β<1 :早期失效/婴儿夭折 β≈1 :随机失效 β>1 :耗损失效)
在此不再赘述;知道了β值后再进行相应的动作(不同阶段的失效应该知道怎么去操作?);
通常的特征寿命(η)可能没有这么好用了,因为此时的可靠度为1- 63.2% ,此时更希望用B10寿命来看这批产品在市场段会有多少失效;
那么:
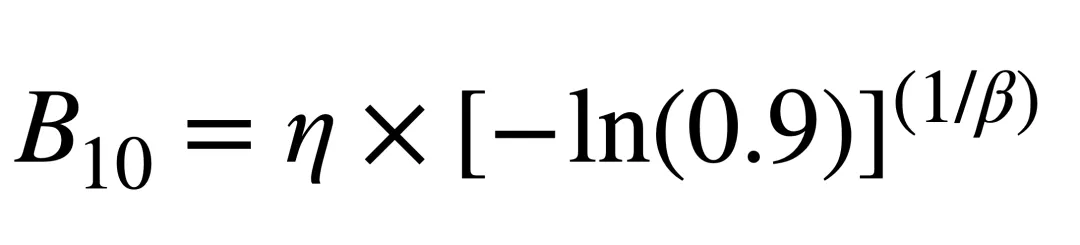
带入公式计算有B10 ==1928 * (-LN(0.9))^(1/1.6019) = 473H,当然了,此时结合加速寿命外推正常环境下使用寿命为473*48=22704H(AF=48,瞎写的),而用户的正常使用习惯是每年 1000H,那么3 年质保期(3000H)内的退修率能控制在 10% 以内,财务兜得住。
对Weibull,其可靠的函数为:
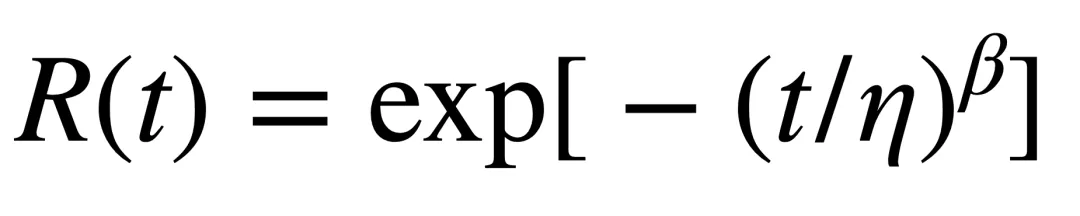
假设一批产品在市场段已经运行到5000H(5年),想知道这个时候还有多少样品是活着的,
有:
R(5000) = exp(-1 * ((5000/48)/1928)^1.6019) = 0.991 即99.1%。
可见产品非常牛逼,市场上跑了5年才有近10%的产品出问题;当然了,如果算出来的可靠度比较低,是效率高,那么到了一定spec后就需要提前把这批高风险隐患部件换掉,彻底避免损失。
阿超|北航硕士,可靠性工程实践者,毕业后从事可靠性工作至今:从试验设计到数据分析的完整闭环。持续深耕可靠性工程前沿技术,用数据驱动产品可靠性提升。(加我iMe_ever, 一起探讨呀)
点击关注:
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 新版红帽企业Linux来了,赋能后量子就绪能力与AI驱动的自动化
- 为什么MX Linux在DistroWatch上力压Ubuntu、Fedora和Zorin OS?
- Linux 爆出“核弹级”漏洞:CVE-2026-31431 ,十几行代码拿下 root
- 紧急安全更新丨修复Linux Kernel Dirty Frag漏洞(含详细修复方法)
- Linux xargs 命令深度解析:从管道到命令构建的桥梁
- 如果你有Linux基础,那你学习网络安全会有多简单!
- Linux 与 PCIe:深入理解PCIe在内核中的实现
- SparkyLinux 8.3 发布!
- 重磅预警!Linux内核Dirty Frag高危漏洞爆发,全平台可一键Root提权
- 这个网站让我学python的兴趣到达了10000%!
