字数 9116,阅读大约需 46 分钟
第六章:文件系统
文件系统是操作系统为用户提供的持久化数据存储机制,它将磁盘上的数据块组织成目录和文件的层次结构,为用户程序提供简单一致的文件访问接口。Linux 0.12采用了Minix文件系统,这是一个简单而经典的文件系统实现,包含了现代文件系统的核心要素:超级块、i节点、目录项、数据块、以及缓冲区高速缓存机制。通过文件系统,程序可以用文件名而非磁盘块号来访问数据,极大地简化了数据管理。
6.1 Minix文件系统布局
Minix文件系统将磁盘分区划分为几个区域:引导块、超级块、i节点位图、块位图、i节点区和数据区。引导块位于第0块,用于存放引导程序。超级块位于第1块,保存文件系统的元信息,包括总i节点数、总数据块数、空闲i节点数、空闲块数等关键统计信息。
i节点位图和块位图各占若干块,用位图方式记录i节点和数据块的分配情况。每个位对应一个i节点或数据块,位值为1表示已分配,0表示空闲。通过扫描位图可以快速找到空闲的i节点或数据块。i节点区包含所有i节点,每个i节点32字节,记录文件的元数据(文件类型、权限、大小、修改时间、数据块索引等)。数据区存放文件和目录的实际内容。
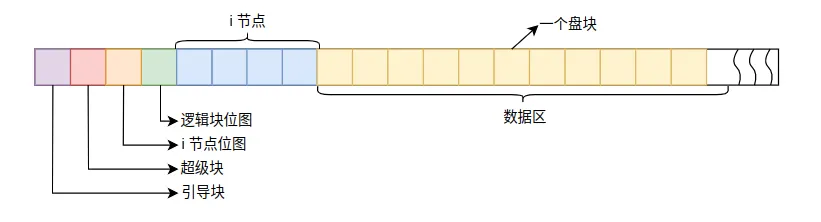 MINIX 文件系统
MINIX 文件系统每个文件或目录都对应一个i节点。i节点包含9个块号数组:前7个是直接块号,直接指向文件的前7KB数据块;第8个是一次间接块号,指向一个索引块,该索引块包含512个块号,可索引512KB数据;第9个是二次间接块号,指向一个二级索引块,可索引256MB数据。这种混合索引结构既能高效处理小文件,也支持较大文件。
超级块结构定义
超级块(super_block)保存文件系统的全局元数据,位于磁盘块1:
/* include/linux/fs.h - 超级块结构 */
struct super_block {
unsigned short s_ninodes; /* i节点总数
* 文件系统最多支持多少个文件/目录 */
unsigned short s_nzones; /* 逻辑块总数(数据区块数)
* 文件系统总容量 = s_nzones * 1024 字节 */
unsigned short s_imap_blocks; /* i节点位图占用的块数
* 每块1024字节=8192位,可管理8192个i节点 */
unsigned short s_zmap_blocks; /* 块位图占用的块数
* 每块可管理8192个数据块 */
unsigned short s_firstdatazone; /* 第一个数据块号
* 数据区起始位置 = 1+1+s_imap_blocks+
* s_zmap_blocks+i节点区块数 */
unsigned short s_log_zone_size; /* log2(块大小/1024)
* Linux 0.12中块大小固定为1024,所以=0 */
unsigned long s_max_size; /* 文件最大长度,受i节点索引结构限制
* 直接块7KB+一次间接512KB+二次间接256MB */
unsigned short s_magic; /* 文件系统魔数,Minix: 0x137F
* 用于识别文件系统类型 */
/* 以下字段仅存在于内存中的超级块,不写入磁盘 */
struct buffer_head * s_imap[8]; /* i节点位图缓冲块指针数组(最多8块)
* 指向缓冲区中的i节点位图 */
struct buffer_head * s_zmap[8]; /* 块位图缓冲块指针数组(最多8块)
* 指向缓冲区中的块位图 */
unsigned short s_dev; /* 设备号,例如 0x301 表示/dev/hda1
* 高8位主设备号,低8位次设备号 */
struct m_inode * s_isup; /* 被挂载的i节点(挂载点)
* NULL表示根文件系统 */
struct m_inode * s_imount; /* 挂载到此设备的i节点
* 指向挂载的文件系统根i节点 */
unsigned long s_time; /* 修改时间(Unix时间戳) */
struct task_struct * s_wait; /* 等待此超级块的进程队列
* 用于锁机制 */
unsigned char s_lock; /* 锁标志: 1=已锁定,0=未锁定
* 防止并发修改超级块 */
unsigned char s_rd_only; /* 只读标志: 1=只读,0=可写
* 只读文件系统不允许写操作 */
unsigned char s_dirt; /* 修改标志: 1=已修改,0=未修改
* 已修改的超级块需要写回磁盘 */
};
磁盘i节点结构
磁盘上的i节点(d_inode)占32字节,保存文件元数据:
/* include/linux/fs.h - 磁盘i节点,32字节 */
struct d_inode {
unsigned short i_mode; /* 文件类型和权限
* 位15-12: 文件类型
* 0100(0x4000) 目录
* 0010(0x2000) 字符设备
* 0110(0x6000) 块设备
* 0010(0x8000) 普通文件
* 位11-9: 特殊权限(setuid/setgid/sticky)
* 位8-6: 属主权限(rwx)
* 位5-3: 组权限(rwx)
* 位2-0: 其他用户权限(rwx) */
unsigned short i_uid; /* 属主用户ID */
unsigned long i_size; /* 文件大小(字节)
* 对于目录是目录项总长度 */
unsigned long i_time; /* 修改时间(Unix时间戳,从1970-01-01起的秒数) */
unsigned char i_gid; /* 属主组ID */
unsigned char i_nlinks; /* 链接计数(硬链接数)
* 当降为0时文件被删除 */
unsigned short i_zone[9]; /* 数据块索引数组(块号)
* i_zone[0-6]: 直接块号,每块1KB,共7KB
* i_zone[7]: 一次间接块号
* 指向索引块,索引块包含512个块号(512KB)
* i_zone[8]: 二次间接块号
* 指向二级索引,每个二级索引512个块号
* 512*512*1KB = 256MB
* 最大文件大小: 7KB+512KB+256MB ≈ 256MB */
};
内存i节点结构
内存中的i节点(m_inode)扩展了磁盘i节点,增加了管理字段:
/* include/linux/fs.h - 内存i节点结构 */
struct m_inode {
unsigned short i_mode; /* 同d_inode */
unsigned short i_uid; /* 同d_inode */
unsigned long i_size; /* 同d_inode */
unsigned long i_mtime; /* 修改时间 */
unsigned char i_gid; /* 同d_inode */
unsigned char i_nlinks; /* 同d_inode */
unsigned short i_zone[9]; /* 同d_inode */
/* 以下字段仅在内存中,用于管理i节点缓存 */
struct task_struct * i_wait; /* 等待此i节点的进程队列
* 用于i节点锁机制 */
unsigned long i_atime; /* 最后访问时间 */
unsigned long i_ctime; /* i节点改变时间(元数据修改时间) */
unsigned short i_dev; /* 设备号(所在设备) */
unsigned short i_num; /* i节点号(1-based,i节点0未使用)
* 在设备上的i节点索引 */
unsigned short i_count; /* 引用计数
* 多个文件描述符/进程可能引用同一i节点
* 降为0时才能释放 */
unsigned char i_lock; /* 锁标志: 1=已锁定,0=未锁定
* 防止并发修改i节点 */
unsigned char i_dirt; /* 修改标志: 1=已修改,需要写回磁盘 */
unsigned char i_pipe; /* 管道标志: 1=这是管道,0=普通文件
* 管道使用i节点但无磁盘数据块 */
unsigned char i_mount; /* 挂载标志: 1=挂载点,0=普通文件
* 该i节点是其他文件系统的挂载点 */
unsigned char i_seek; /* 搜索标志(用于lseek) */
unsigned char i_update; /* 更新标志: 需要更新i_atime或i_ctime */
};
目录在Minix文件系统中是特殊的文件,其数据块存放的是目录项数组。每个目录项包含i节点号和文件名(最长14字符)。读取目录就是读取其数据块,解析目录项结构。查找文件时,从根目录的i节点开始,逐层解析路径中的每一级目录,最终找到目标文件的i节点号。
6.2 缓冲区高速缓存
缓冲区高速缓存(buffer cache)是文件系统性能的关键。所有对块设备的读写操作都通过缓冲区进行,缓存命中时可以避免慢速的磁盘访问。buffer_head结构描述一个缓冲块,包含设备号、块号、数据指针、锁标志、修改标志、更新标志等。
buffer_init()在系统初始化时构建缓冲区。它从物理内存高端向下分配空间,每个buffer_head管理1KB数据缓冲区。所有buffer_head通过双向链表组织成free_list空闲链表,还通过hash_table哈希表按(设备号,块号)进行索引,以加速查找。
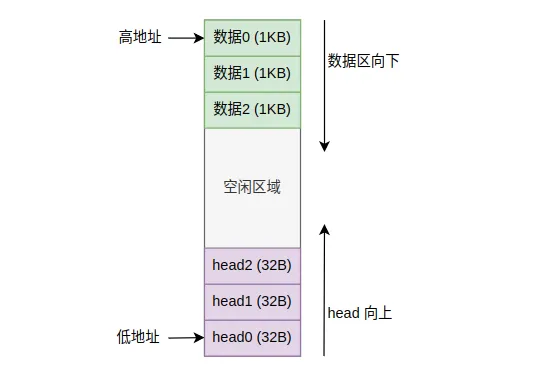 缓冲区高速缓存 (Buffer Cache) 内存布局
缓冲区高速缓存 (Buffer Cache) 内存布局getblk()函数是缓冲区管理的核心。它根据设备号和块号查找缓冲块:首先在hash_table中查找,如果找到就等待其解锁并返回;如果未找到就从free_list分配一个空闲缓冲块,将其插入hash_table并返回。如果缓冲块是脏的(b_dirt=1),getblk()会先将其写回磁盘再重用。这种LRU策略保证了热点数据留在缓存中。
bread()函数读取指定块到缓冲区。它调用getblk()获取缓冲块,如果缓冲块的b_uptodate标志为0(数据无效),就发起磁盘读操作ll_rw_block(READ, bh),等待读完成后返回。breada()实现预读优化,一次读取多个连续块,提高顺序访问性能。bwrite()将缓冲块标记为脏(b_dirt=1)并加入写队列,由后台定期将脏块写入磁盘。
buffer_head缓冲块头结构
每个缓冲块由buffer_head结构管理:
/* include/linux/fs.h - 缓冲块头结构 */
struct buffer_head {
char * b_data; /* 指向实际数据缓冲区(1KB)
* 从内存高端向下分配 */
unsigned long b_blocknr; /* 逻辑块号(在设备上的块号)
* 与b_dev一起唯一标识一个磁盘块 */
unsigned short b_dev; /* 设备号(0x0300=hda, 0x0301=hda1等)
* 高8位主设备号,低8位次设备号 */
unsigned char b_uptodate; /* 数据有效标志
* 1=缓冲区数据与磁盘同步,可直接使用
* 0=数据无效,需要从磁盘读取 */
unsigned char b_dirt; /* 脏标志
* 1=数据已修改,需要写回磁盘
* 0=数据未修改或已写回 */
unsigned char b_count; /* 引用计数
* 正在使用此缓冲块的进程数
* >0时不能被重用 */
unsigned char b_lock; /* 锁标志
* 1=缓冲块被锁定(正在进行I/O操作)
* 0=未锁定,可以访问 */
struct task_struct * b_wait; /* 等待此缓冲块解锁的进程队列
* 当b_lock=1时,其他进程在此等待 */
struct buffer_head * b_prev; /* 空闲链表中的前一个缓冲块
* free_list双向链表指针 */
struct buffer_head * b_next; /* 空闲链表中的下一个缓冲块 */
struct buffer_head * b_prev_free;/* hash队列中的前一个缓冲块
* hash_table用于快速查找 */
struct buffer_head * b_next_free;/* hash队列中的下一个缓冲块 */
};
buffer_init初始化缓冲区
系统初始化时,buffer_init()从内存高端向下分配缓冲区:
/* fs/buffer.c - 缓冲区初始化 */
#define NR_BUFFERS nr_buffers /* 缓冲块数量,根据内存大小计算 */
#define HASH_TABLE_SIZE 307 /* 哈希表大小(素数,减少冲突) */
struct buffer_head * start_buffer; /* 缓冲块头数组起始地址 */
struct buffer_head * hash_table[HASH_TABLE_SIZE]; /* 哈希表 */
staticstruct buffer_head * free_list; /* 空闲链表头 */
static int nr_buffers = 0; /* 缓冲块总数 */
void buffer_init(long buffer_end)
{
struct buffer_head * h = start_buffer;
void * b = (void *) buffer_end; /* 从内存高端向下分配数据缓冲区 */
int i;
/* 如果buffer_end在16MB以上,只使用到16MB为止 */
if (buffer_end == 1 << 20)
b = (void *) (640 * 1024); /* 640KB以下是传统内存 */
else
b = (void *) buffer_end;
/* 循环分配缓冲块,直到空间不足 */
while ((b -= BLOCK_SIZE) >= ((void *) (h + 1))) {
h->b_dev = 0; /* 设备号0表示空闲 */
h->b_dirt = 0; /* 未修改 */
h->b_count = 0; /* 无引用 */
h->b_lock = 0; /* 未锁定 */
h->b_uptodate = 0; /* 数据无效 */
h->b_wait = NULL; /* 无等待进程 */
h->b_next = NULL;
h->b_prev = NULL;
h->b_data = (char *) b; /* 指向1KB数据缓冲区 */
h->b_prev_free = h - 1; /* 构建双向链表 */
h->b_next_free = h + 1;
h++; /* 下一个buffer_head */
nr_buffers++; /* 缓冲块计数+1 */
if (b == (void *) 0x100000) /* 跳过1MB边界 */
b = (void *) 0xA0000; /* 640KB-1MB是系统保留区 */
}
h--; /* 最后一个buffer_head */
free_list = start_buffer; /* 空闲链表头 */
free_list->b_prev_free = h; /* 构成循环链表 */
h->b_next_free = free_list;
/* 初始化哈希表为空 */
for (i = 0; i < HASH_TABLE_SIZE; i++)
hash_table[i] = NULL;
}
getblk获取缓冲块
getblk()是缓冲区管理的核心函数,实现查找或分配缓冲块:
/* fs/buffer.c - 获取指定设备和块号的缓冲块 */
struct buffer_head * getblk(int dev, int block)
{
struct buffer_head * bh;
/*=== 步骤1: 在哈希表中查找缓冲块 ===*/
repeat:
if ((bh = get_hash_table(dev, block))) {
/* 找到了,等待解锁 */
wait_on_buffer(bh); /* 如果b_lock=1则睡眠等待 */
if (bh->b_dev == dev && bh->b_blocknr == block)
return bh; /* 返回缓冲块 */
goto repeat; /* 可能在等待期间被换出,重新查找 */
}
/*=== 步骤2: 未找到,从空闲链表分配 ===*/
/* 扫描空闲链表,寻找空闲缓冲块(b_count=0) */
bh = free_list;
do {
if (bh->b_count) /* 引用计数>0,正在使用,跳过 */
continue;
if (!bh->b_dirt && !bh->b_lock) /* 找到干净且未锁定的块 */
break; /* 最佳选择,立即使用 */
/* 否则继续寻找更好的候选 */
} while ((bh = bh->b_next_free) != free_list);
/*=== 步骤3: 如果分配的块是脏的,先写回磁盘 ===*/
if (bh->b_dirt) {
sync_dev(bh->b_dev); /* 同步该设备的所有脏块 */
goto repeat; /* 写回后重新查找 */
}
/*=== 步骤4: 如果缓冲块在哈希表中,先移除 ===*/
if (bh->b_dev)
remove_from_queues(bh); /* 从哈希队列移除 */
/*=== 步骤5: 初始化缓冲块并插入哈希表 ===*/
bh->b_dev = dev; /* 设置设备号 */
bh->b_blocknr = block; /* 设置块号 */
bh->b_dirt = 0; /* 标记为干净 */
bh->b_uptodate = 0; /* 数据无效(稍后需要读取) */
bh->b_count = 1; /* 引用计数设为1 */
remove_from_queues(bh); /* 从空闲链表移除 */
insert_into_queues(bh); /* 插入哈希表 */
return bh; /* 返回缓冲块 */
}
/* 辅助函数: 在哈希表中查找缓冲块 */
static struct buffer_head * get_hash_table(int dev, int block)
{
struct buffer_head * bh;
/* 计算哈希值: (dev ^ block) % HASH_TABLE_SIZE */
for (bh = hash_table[_hashfn(dev, block)]; bh != NULL; bh = bh->b_next)
if (bh->b_dev == dev && bh->b_blocknr == block)
return bh; /* 找到匹配的缓冲块 */
return NULL; /* 未找到 */
}
/* 哈希函数 */
#define _hashfn(dev, block) (((dev) ^ (block)) % HASH_TABLE_SIZE)
bread读取磁盘块
bread()读取指定块到缓冲区,如果缓存未命中则从磁盘读取:
/* fs/buffer.c - 读取磁盘块到缓冲区 */
struct buffer_head * bread(int dev, int block)
{
struct buffer_head * bh;
/*=== 步骤1: 调用getblk获取缓冲块 ===*/
if (!(bh = getblk(dev, block))) {
printk("bread: getblk failed\n");
return NULL; /* 内存不足,分配失败 */
}
/*=== 步骤2: 检查数据是否有效 ===*/
if (bh->b_uptodate) /* 数据有效,缓存命中 */
return bh; /* 直接返回,无需读盘 */
/*=== 步骤3: 数据无效,从磁盘读取 ===*/
ll_rw_block(READ, bh); /* 调用底层块设备驱动读取
* READ=0, 读操作
* 驱动会填充bh->b_data */
wait_on_buffer(bh); /* 等待I/O完成
* I/O完成后中断处理程序会:
* 1. 设置b_uptodate=1
* 2. 设置b_lock=0
* 3. 唤醒等待进程 */
/*=== 步骤4: 检查读取结果 ===*/
if (bh->b_uptodate) /* 读取成功 */
return bh;
/* 读取失败,释放缓冲块 */
brelse(bh); /* 减少引用计数 */
return NULL;
}
/* 释放缓冲块(减少引用计数) */
void brelse(struct buffer_head * bh)
{
if (!bh)
return;
wait_on_buffer(bh); /* 等待解锁 */
if (!(bh->b_count--))
panic("Trying to free free buffer");
wake_up(&buffer_wait); /* 唤醒等待空闲缓冲块的进程 */
}
sync()系统调用将所有脏缓冲块写回磁盘,保证数据持久化。它先调用sync_inodes()写i节点,再扫描所有缓冲块,对脏块调用ll_rw_block(WRITE)。sync_dev(dev)只同步指定设备的缓冲块。系统定期(通常每30秒)调用sync(),以防止系统崩溃时丢失过多数据。
6.3 i节点管理
内存中维护一个i节点表inode_table(64项),缓存最近访问的i节点。m_inode结构是内存i节点,包含磁盘i节点的所有字段,还增加了引用计数、锁、修改标志等字段。i节点在内存和磁盘之间同步,修改后的i节点最终写回磁盘。
iget(dev, nr)函数获取指定设备的i节点。它首先在inode_table中查找,如果找到就增加引用计数并返回;如果未找到就分配一个空闲i节点项,调用read_inode()从磁盘读取i节点内容到内存。iput(inode)释放i节点,将引用计数减1,如果降为0且i节点已修改,则调用write_inode()写回磁盘,如果i节点的链接数为0(文件被删除),则释放其数据块和i节点本身。
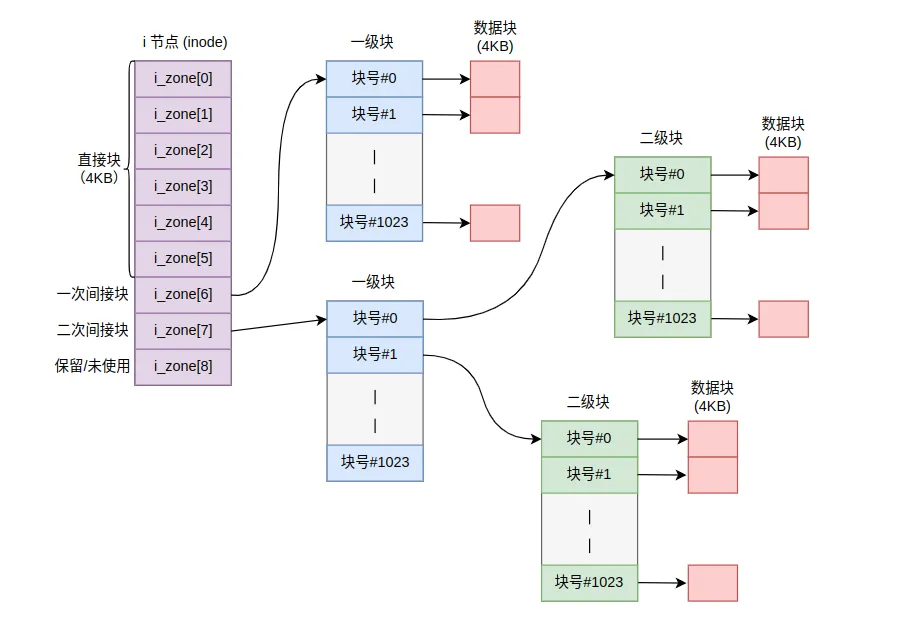 i节点索引结构示意图
i节点索引结构示意图bmap(inode, block)函数将文件的逻辑块号映射为磁盘块号。它根据block值选择使用直接块、一次间接块或二次间接块。如果对应块号为0(块未分配),且create标志置位,bmap()会调用new_block()分配新块。new_block()扫描块位图找空闲块,设置位图并更新超级块,返回新块号。free_block()释放块,清除位图位。
iget获取i节点
iget()从内存缓存或磁盘获取i节点:
/* fs/inode.c - i节点表,64项 */
struct m_inode inode_table[NR_INODE]; /* NR_INODE=64 */
/* 获取指定设备和i节点号的i节点 */
struct m_inode * iget(int dev, int nr)
{
struct m_inode * inode, * empty;
if (!dev)
panic("iget with dev==0");
empty = NULL;
/*=== 步骤1: 在inode_table中查找匹配的i节点 ===*/
inode = inode_table + 0; /* 从inode_table[0]开始 */
repeat:
for (; inode < inode_table + NR_INODE; inode++) {
if (inode->i_dev != dev || inode->i_num != nr) {
/* 不匹配,记录第一个空闲项 */
if (!inode->i_count && !empty)
empty = inode;
continue;
}
/*=== 找到匹配的i节点 ===*/
wait_on_inode(inode); /* 等待i节点解锁 */
/* 等待期间可能被修改,重新验证 */
if (inode->i_dev != dev || inode->i_num != nr) {
inode = inode_table + 0; /* 从头开始搜索 */
goto repeat;
}
inode->i_count++; /* 引用计数+1 */
/* 如果是挂载点,跟随i节点到被挂载的文件系统根目录 */
if (inode->i_mount) {
int i;
/* 搜索super_block表,找到挂载的文件系统 */
for (i = 0; i < NR_SUPER; i++)
if (super_block[i].s_imount == inode)
break;
if (i >= NR_SUPER) {
printk("Mounted inode hasn't got sb\n");
return inode;
}
/* 返回被挂载文件系统的根i节点(1号) */
iput(inode); /* 释放当前i节点 */
dev = super_block[i].s_dev;
nr = ROOT_INO; /* ROOT_INO=1 */
inode = inode_table + 0;
goto repeat;
}
return inode; /* 返回找到的i节点 */
}
/*=== 步骤2: 未找到,使用空闲i节点项 ===*/
if (!empty)
return NULL; /* 无空闲项,返回失败 */
inode = empty; /* 使用空闲项 */
inode->i_dev = dev; /* 设置设备号 */
inode->i_num = nr; /* 设置i节点号 */
/*=== 步骤3: 从磁盘读取i节点 ===*/
read_inode(inode); /* 读取磁盘i节点到内存 */
return inode;
}
/* 从磁盘读取i节点 */
static void read_inode(struct m_inode * inode)
{
struct super_block * sb;
struct buffer_head * bh;
int block;
/*=== 步骤1: 计算i节点所在的磁盘块号 ===*/
lock_inode(inode); /* 锁定i节点 */
sb = get_super(inode->i_dev); /* 获取超级块 */
/* i节点区起始块 = 2 + s_imap_blocks + s_zmap_blocks
* 每块1024字节 / 32字节每个i节点 = 32个i节点
* i节点nr所在块 = i节点区起始 + (nr-1)/32 */
block = 2 + sb->s_imap_blocks + sb->s_zmap_blocks +
(inode->i_num - 1) / INODES_PER_BLOCK;
/*=== 步骤2: 读取包含i节点的磁盘块 ===*/
if (!(bh = bread(inode->i_dev, block))) {
panic("unable to read i-node block");
}
/*=== 步骤3: 从缓冲块中复制i节点数据 ===*/
/* 计算i节点在块内的偏移: (nr-1) % 32 */
*((struct d_inode *) inode) =
((struct d_inode *) bh->b_data)[(inode->i_num - 1) % INODES_PER_BLOCK];
brelse(bh); /* 释放缓冲块 */
/*=== 步骤4: 初始化其他字段 ===*/
inode->i_count = 1; /* 引用计数=1 */
inode->i_lock = 0; /* 解锁 */
inode->i_dirt = 0; /* 未修改 */
inode->i_pipe = 0; /* 非管道 */
inode->i_mount = 0; /* 非挂载点 */
inode->i_seek = 0;
inode->i_update = 0;
unlock_inode(inode); /* 解锁i节点 */
}
iput释放i节点
iput()减少i节点引用计数,必要时写回磁盘或释放资源:
/* fs/inode.c - 释放i节点 */
void iput(struct m_inode * inode)
{
if (!inode)
return;
wait_on_inode(inode); /* 等待i节点解锁 */
if (!inode->i_count)
panic("iput: trying to free free inode");
/*=== 步骤1: 处理管道i节点 ===*/
if (inode->i_pipe) {
wake_up(&inode->i_wait); /* 唤醒等待管道的进程 */
if (--inode->i_count)
return; /* 还有其他引用 */
/* 最后一个引用,释放管道缓冲区 */
free_page(inode->i_size); /* i_size存放管道缓冲区地址 */
inode->i_count = 0; /* 清零引用计数 */
inode->i_dirt = 0;
inode->i_pipe = 0;
return;
}
/*=== 步骤2: 处理块设备i节点 ===*/
if (!inode->i_dev) {
inode->i_count--; /* 无设备号,直接减引用计数 */
return;
}
repeat:
/*=== 步骤3: 处理被删除的文件(链接数=0) ===*/
if (inode->i_count > 1) {
inode->i_count--; /* 还有其他引用 */
return;
}
/* 现在i_count=1,即将清零 */
if (!inode->i_nlinks) {
/* 文件链接数=0,文件已被删除 */
truncate(inode); /* 释放所有数据块 */
free_inode(inode); /* 释放i节点,清除i节点位图 */
return; /* 注意:不减少i_count */
}
/*=== 步骤4: 将修改的i节点写回磁盘 ===*/
if (inode->i_dirt) {
write_inode(inode); /* 同步i节点到磁盘 */
wait_on_inode(inode); /* 等待写入完成 */
goto repeat; /* 重新检查 */
}
inode->i_count--; /* 减少引用计数 */
}
/* 将内存i节点写回磁盘 */
static void write_inode(struct m_inode * inode)
{
struct super_block * sb;
struct buffer_head * bh;
int block;
lock_inode(inode); /* 锁定i节点 */
/* 计算i节点所在磁盘块 */
sb = get_super(inode->i_dev);
block = 2 + sb->s_imap_blocks + sb->s_zmap_blocks +
(inode->i_num - 1) / INODES_PER_BLOCK;
/* 读取磁盘块 */
if (!(bh = bread(inode->i_dev, block))) {
panic("unable to read i-node block");
}
/* 将内存i节点复制到缓冲块 */
((struct d_inode *) bh->b_data)[(inode->i_num - 1) % INODES_PER_BLOCK] =
*((struct d_inode *) inode);
bh->b_dirt = 1; /* 标记为脏,稍后写回 */
inode->i_dirt = 0; /* 清除脏标志 */
brelse(bh); /* 释放缓冲块 */
unlock_inode(inode); /* 解锁 */
}
bmap映射逻辑块到磁盘块
bmap()将文件的逻辑块号转换为磁盘物理块号:
/* fs/inode.c - 块号映射 */
int bmap(struct m_inode * inode, int block)
{
int i;
if (block < 0)
panic("bmap: block < 0");
/*=== 情凵1: 直接块(0-6),共7KB ===*/
if (block < 7) {
if (!inode->i_zone[block]) { /* 块未分配 */
/* 分配新块 */
if (!(inode->i_zone[block] = new_block(inode->i_dev)))
return 0; /* 分配失败 */
inode->i_ctime = CURRENT_TIME;
inode->i_dirt = 1; /* 标记i节点修改 */
}
return inode->i_zone[block]; /* 返回磁盘块号 */
}
/*=== 情凵2: 一次间接块(7-518),共512KB ===*/
block -= 7; /* 减去直接块 */
if (block < 512) {
/* 检查一次间接块是否分配 */
if (!inode->i_zone[7]) {
if (!(inode->i_zone[7] = new_block(inode->i_dev)))
return 0;
inode->i_dirt = 1;
inode->i_ctime = CURRENT_TIME;
}
/* 读取一次间接块(索引块) */
struct buffer_head * bh;
if (!(bh = bread(inode->i_dev, inode->i_zone[7])))
return 0;
/* 索引块包含512个块号(unsigned short) */
i = ((unsigned short *) (bh->b_data))[block];
if (!i) { /* 该块未分配 */
if ((i = new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block] = i;
bh->b_dirt = 1; /* 标记索引块修改 */
}
}
brelse(bh); /* 释放索引块 */
return i; /* 返回磁盘块号 */
}
/*=== 情凵3: 二次间接块(519-262,658),共256MB ===*/
block -= 512; /* 减去一次间接 */
if (block < 512 * 512) {
/* 检查二次间接块是否分配 */
if (!inode->i_zone[8]) {
if (!(inode->i_zone[8] = new_block(inode->i_dev)))
return 0;
inode->i_dirt = 1;
inode->i_ctime = CURRENT_TIME;
}
/* 读取二级索引块 */
struct buffer_head * bh;
if (!(bh = bread(inode->i_dev, inode->i_zone[8])))
return 0;
/* 计算一级索引块的位置: block / 512 */
i = ((unsigned short *) bh->b_data)[block >> 9];
if (!i) { /* 一级索引块未分配 */
if ((i = new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block >> 9] = i;
bh->b_dirt = 1;
}
}
brelse(bh);
if (!i)
return 0;
/* 读取一级索引块 */
if (!(bh = bread(inode->i_dev, i)))
return 0;
/* 计算最终数据块的位置: block % 512 */
i = ((unsigned short *) bh->b_data)[block & 511];
if (!i) { /* 数据块未分配 */
if ((i = new_block(inode->i_dev))) {
((unsigned short *) (bh->b_data))[block & 511] = i;
bh->b_dirt = 1;
}
}
brelse(bh);
return i; /* 返回磁盘块号 */
}
/* 超出文件大小限制 */
panic("bmap: block > 7+512+512*512");
return 0;
}
6.4 文件操作
open()系统调用打开文件。sys_open()首先调用open_namei()根据路径名查找i节点,这个过程从根目录开始,逐层解析每个目录分量。找到i节点后,分配一个file结构和文件描述符,将file->f_inode指向i节点,file->f_pos设为0(文件位置),将文件描述符返回给用户。
read()系统调用读取文件内容。sys_read()根据文件描述符找到file结构和i节点,调用file_read()逐块读取数据。file_read()循环调用bmap()获取文件逻辑块对应的磁盘块号,然后用bread()读取块到缓冲区,将数据从内核缓冲区复制到用户缓冲区,更新文件位置f_pos。对于小于1KB的读取,只复制部分块内容。
write()系统调用写入文件。sys_write()调用file_write(),它与file_read()类似,但是将用户数据复制到缓冲区,并标记缓冲块为脏。如果写入位置超过文件末尾,file_write()会调用bmap()分配新块,并更新i节点的i_size字段。close()关闭文件,减少file和i节点的引用计数,如果i节点引用计数降为0则可能写回磁盘。
file结构和文件描述符
每个打开的文件都有一个file结构:
/* include/linux/fs.h - 文件结构 */
struct file {
unsigned short f_mode; /* 文件模式
* 1: 只读(O_RDONLY)
* 2: 只写(O_WRONLY)
* 3: 读写(O_RDWR) */
unsigned short f_flags; /* 文件标志
* O_CREAT, O_TRUNC, O_APPEND等 */
unsigned short f_count; /* 引用计数
* 多个fd可能指向同一file(如fork后) */
struct m_inode * f_inode; /* 指向i节点 */
off_t f_pos; /* 文件当前位置(字节偏移)
* read/write会更新此值 */
};
/* 全局文件表,最多64个打开文件 */
struct file file_table[NR_FILE]; /* NR_FILE=64 */
/* 每个进程的文件描述符表 */
struct task_struct {
...
struct file * filp[NR_OPEN]; /* NR_OPEN=20,每个进程最多20个fd */
...
};
sys_open打开文件
sys_open()实现文件打开:
/* fs/open.c - open系统调用 */
int sys_open(const char * filename, int flag, int mode)
{
struct m_inode * inode;
struct file * f;
int i, fd;
/*=== 步骤1: 检查模式标志 ===*/
mode &= 0777 & ~current->umask; /* 应用umask */
/*=== 步骤2: 解析路径名,获取i节点 ===*/
if (!(inode = open_namei(filename, flag, mode)))
return -1; /* 文件不存在或无权限 */
/*=== 步骤3: 分配文件描述符fd ===*/
for (fd = 0; fd < NR_OPEN; fd++) {
if (!current->filp[fd]) /* 找到空闲fd */
break;
}
if (fd >= NR_OPEN) { /* 进程打开文件太多 */
iput(inode);
return -1;
}
/*=== 步骤4: 从全局file_table中分配file结构 ===*/
for (f = file_table + 0; f < file_table + NR_FILE; f++) {
if (!f->f_count) { /* 找到空闲file */
f->f_count = 1; /* 引用计数=1 */
break;
}
}
if (f >= file_table + NR_FILE) { /* 系统打开文件太多 */
iput(inode);
return -1;
}
/*=== 步骤5: 初始化file结构 ===*/
current->filp[fd] = f; /* 关联fd和file */
f->f_mode = inode->i_mode; /* 设置文件模式 */
f->f_flags = flag; /* 设置标志 */
f->f_inode = inode; /* 指向i节点 */
f->f_pos = 0; /* 文件位置=0 */
/*=== 步骤6: 处理O_TRUNC标志 ===*/
if (flag & O_TRUNC) { /* 截断文件到长度0 */
truncate(inode); /* 释放所有数据块 */
inode->i_size = 0; /* 文件大小=0 */
inode->i_dirt = 1; /* 标记i节点修改 */
inode->i_mtime = CURRENT_TIME;
}
return fd; /* 返回文件描述符 */
}
file_read读取文件
file_read()从文件读取数据:
/* fs/file_dev.c - 文件读取 */
int file_read(struct m_inode * inode, struct file * filp, char * buf, int count)
{
int left, chars, nr;
struct buffer_head * bh;
/*=== 步骤1: 计算实际可读字节数 ===*/
if ((left = count) <= 0)
return 0;
/* 不能超过文件大小 */
if (filp->f_pos >= inode->i_size)
return 0; /* 已到文件末尾 */
if (filp->f_pos + left > inode->i_size)
left = inode->i_size - filp->f_pos;
/*=== 步骤2: 循环读取各个数据块 ===*/
while (left > 0) {
/* 计算当前位置所在的逻辑块号 */
nr = filp->f_pos / BLOCK_SIZE; /* 逻辑块号 = 位置/1024 */
/*=== 步骤2.1: 将逻辑块映射为磁盘块 ===*/
nr = bmap(inode, nr); /* 调用bmap转换为磁盘块号 */
if (!nr)
break; /* 没有分配块,读取结束 */
/*=== 步骤2.2: 读取磁盘块到缓冲区 ===*/
if (!(bh = bread(inode->i_dev, nr)))
break; /* 读取失败 */
/*=== 步骤2.3: 计算本次复制的字节数 ===*/
/* 块内偏移量 */
nr = filp->f_pos % BLOCK_SIZE;
/* 本块剩余可读字节 */
chars = MIN(BLOCK_SIZE - nr, left);
/*=== 步骤2.4: 从内核缓冲区复制到用户空间 ===*/
/* put_fs_byte: 将内核空间字节写入用户空间
* 从 bh->b_data + nr 处开始复制 chars 字节到 buf */
char * p = bh->b_data + nr;
while (chars-- > 0)
put_fs_byte(*(p++), buf++); /* 逐字节复制 */
brelse(bh); /* 释放缓冲块 */
/*=== 步骤2.5: 更新文件位置和剩余字节数 ===*/
filp->f_pos += chars; /* 移动文件指针 */
left -= chars; /* 减少剩余字节数 */
}
/*=== 步骤3: 更新i节点访问时间 ===*/
inode->i_atime = CURRENT_TIME;
/* 返回实际读取的字节数 */
return count - left;
}
file_write写入文件
file_write()向文件写入数据:
/* fs/file_dev.c - 文件写入 */
int file_write(struct m_inode * inode, struct file * filp, char * buf, int count)
{
off_t pos;
int block, c;
struct buffer_head * bh;
char * p;
int i = 0;
/*=== 步骤1: 处理O_APPEND模式 ===*/
if (filp->f_flags & O_APPEND)
pos = inode->i_size; /* 附加模式,从文件末尾开始 */
else
pos = filp->f_pos; /* 否则从当前位置开始 */
/*=== 步骤2: 循环写入各个数据块 ===*/
while (i < count) {
/* 计算目标位置的逻辑块号 */
block = pos / BLOCK_SIZE;
/*=== 步骤2.1: 映射逻辑块为磁盘块,必要时分配 ===*/
if (!(block = bmap(inode, block))) {
/* bmap会自动分配新块 */
break; /* 分配失败,停止写入 */
}
/*=== 步骤2.2: 读取目标块到缓冲区 ===*/
if (!(bh = bread(inode->i_dev, block)))
break; /* 读取失败 */
/*=== 步骤2.3: 计算本次写入的字节数 ===*/
c = pos % BLOCK_SIZE; /* 块内偏移量 */
p = bh->b_data + c; /* 写入位置 */
c = BLOCK_SIZE - c; /* 本块剩余空间 */
if (c > count - i)
c = count - i; /* 不超过剩余字节数 */
/*=== 步骤2.4: 从用户空间复制到内核缓冲区 ===*/
/* get_fs_byte: 从用户空间读取字节到内核空间 */
pos += c;
i += c;
while (c-- > 0)
*(p++) = get_fs_byte(buf++); /* 逐字节复制 */
/*=== 步骤2.5: 标记缓冲块为脏 ===*/
bh->b_dirt = 1; /* 脏块,稍后写回磁盘 */
brelse(bh); /* 释放缓冲块 */
}
/*=== 步骤3: 更新i节点信息 ===*/
inode->i_mtime = CURRENT_TIME; /* 修改时间 */
inode->i_ctime = CURRENT_TIME; /* 改变时间 */
/* 如果写入超过原文件大小,更新i_size */
if (pos > inode->i_size) {
inode->i_size = pos; /* 扩大文件 */
inode->i_dirt = 1; /* 标记i节点修改 */
}
filp->f_pos = pos; /* 更新文件位置 */
return i; /* 返回实际写入字节数 */
}
lseek()系统调用改变文件位置。它修改file->f_pos,支持从文件开头、当前位置或文件末尾偏移。stat()获取文件状态信息(i节点中的元数据),填充stat结构返回给用户。unlink()删除文件,它减少i节点的链接计数,如果降为0则在iput()时释放i节点和数据块。link()创建硬链接,增加i节点链接计数。
6.5 目录操作与路径解析
目录的数据块存放目录项数组,每个目录鞘16字节:2字节i节点号+14字节文件名。查找文件时,从根i节点(inode 1)开始,读取根目录的数据块,在目录项中查找路径的第一个分量,找到后获取其i节点,重复此过程直到解析完整路径。
namei()函数实现路径解析,返回路径对应的i节点。它处理绝对路径(从根目录开始)和相对路径(从当前工作目录开始),支持符号链接(跟随链接继续解析)。open_namei()是namei()的扩展,支持创建不存在的文件(当O_CREAT标志置位时)。
mkdir()系统调用创建目录。它分配新i节点,设置为目录类型,分配数据块,写入两个特殊目录项:"."指向自己,".."指向父目录,然后在父目录中添加新目录的目录项。rmdir()删除空目录,检查目录只包含"."和".."后删除i节点。
目录项结构
目录文件的数据块包含目录项数组:
/* include/linux/fs.h - 目录项结构,16字节 */
struct dir_entry {
unsigned short inode; /* i节点号(0表示目录项未使用/已删除)
* 1=根目录,2及以上是普通文件/目录 */
char name[NAME_LEN]; /* 文件名,NAME_LEN=14字节
* 不足的用'\0'填充,无结尾\0 */
};
/* 特殊目录项:
* "." - 指向当前目录自身的i节点
* ".." - 指向父目录的i节点
*/
namei路径解析
namei()将路径名解析为i节点:
/* fs/namei.c - 路径名解析 */
struct m_inode * namei(const char * pathname)
{
const char * basename;
int namelen;
struct m_inode * dir, * inode;
struct buffer_head * bh;
struct dir_entry * de;
/*=== 步骤1: 确定起始目录 ===*/
if (*pathname == '/') {
/* 绝对路径,从根目录开始 */
dir = current->root; /* 根目录i节点 */
pathname++; /* 跳过开头的'/' */
} else {
/* 相对路径,从当前工作目录开始 */
dir = current->pwd; /* 当前工作目录i节点 */
}
dir->i_count++; /* 增加引用计数 */
/*=== 步骤2: 逐层解析路径各个分量 ===*/
while (1) {
/* 跳过多余的'/' */
while (*pathname == '/')
pathname++;
/* 如果到达路径末尾,返回当前目录i节点 */
if (!*pathname)
return dir;
/*=== 步骤2.1: 提取下一个路径分量 ===*/
basename = pathname;
namelen = 0;
while (*pathname && *pathname != '/') {
pathname++;
namelen++;
}
if (namelen > NAME_LEN) /* 文件名过长 */
namelen = NAME_LEN;
/*=== 步骤2.2: 在当前目录中查找该分量 ===*/
inode = find_entry(&dir, basename, namelen, &de);
if (!inode) { /* 未找到 */
iput(dir);
return NULL;
}
/*=== 步骤2.3: 检查是否为目录(如果还有下一级) ===*/
if (*pathname) { /* 路径未结束 */
if (!S_ISDIR(inode->i_mode)) {
/* 不是目录,无法继续解析 */
iput(inode);
iput(dir);
return NULL;
}
}
/*=== 步骤2.4: 释放旧目录,移动到下一级 ===*/
iput(dir); /* 释放父目录i节点 */
dir = inode; /* 当前目录移动到下一级 */
}
}
/* 在目录中查找文件名 */
static struct m_inode * find_entry(struct m_inode ** dir,
const char * name, int namelen,struct dir_entry ** res_dir)
{
int entries, i;
struct buffer_head * bh;
struct dir_entry * de;
/*=== 步骤1: 计算目录项数量 ===*/
entries = (*dir)->i_size / sizeof(struct dir_entry);
/*=== 步骤2: 遍历目录的每个数据块 ===*/
for (i = 0; i < entries; i++) {
/* 计算i目录项所在的块号 */
int block = i * sizeof(struct dir_entry) / BLOCK_SIZE;
int offset = i * sizeof(struct dir_entry) % BLOCK_SIZE;
/* 读取目录数据块 */
if (!(block = bmap(*dir, block))) continue;
if (!(bh = bread((*dir)->i_dev, block))) continue;
/* 获取目录项 */
de = (struct dir_entry *) (bh->b_data + offset);
/*=== 步骤3: 比较文件名 ===*/
if (de->inode && namelen == strlen(de->name) &&
strncmp(name, de->name, namelen) == 0) {
/* 找到匹配的目录项 */
*res_dir = de; /* 返回目录项指针 */
return iget((*dir)->i_dev, de->inode); /* 返回i节点 */
}
brelse(bh); /* 未找到,释放缓冲块 */
}
return NULL; /* 未找到 */
}
6.6 管道机制
管道是进程间通信的一种机制。pipe()系统调用创建管道,分配一个i节点(i_pipe标志置位),分配一个物理页面作为管道缓冲区,返回两个文件描述符:读端和写端。写进程向写端写数据,数据保存在管道缓冲区;读进程从读端读数据,从缓冲区取出数据。
管道读写使用pipe_read()和pipe_write()函数。写进程将数据复制到管道缓冲区,如果缓冲区满则睡眠等待读进程读取腾出空间。读进程从缓冲区读取数据,如果缓冲区空则睡眠等待写进程写入数据。管道使用环形缓冲区,通过头尾指针管理。当所有写端关闭时,读进程读到EOF;当所有读端关闭时,写进程收到SIGPIPE信号。
 管道通信 Pipe
管道通信 Pipe通过本章的学习,我们深入理解了Linux 0.12的文件系统实现:从Minix文件系统的磁盘布局到缓冲区高速缓存机制,从i节点管理到文件操作,从路径解析到目录操作,以及管道通信机制。文件系统为用户程序提供了统一的数据存储接口,屏蔽了底层硬件细节,是操作系统的重要组成部分。
6.7 参考资料
本章内容基于以下资料编写:
Minix文件系统规范
- • Minix File System - 详细描述了Minix文件系统的磁盘布局和数据结构
Linux 0.12源代码文件
- • fs/buffer.c - 缓冲区管理、getblk、bread、bwrite、sync
- • fs/inode.c - i节点管理、iget、iput、bmap、read_inode、write_inode
- • fs/namei.c - 路径解析、namei、open_namei、mkdir、rmdir、link、unlink
- • fs/file_dev.c - file_read、file_write文件读写
- • fs/read_write.c - sys_read、sys_write、sys_lseek系统调用
- • fs/open.c - sys_open、sys_close、sys_creat系统调用
- • fs/pipe.c - pipe_read、pipe_write、sys_pipe管道机制
- • fs/super.c - 超级块管理、mount、umount
- • fs/bitmap.c - new_block、free_block、new_inode、free_inode位图操作
- • include/linux/fs.h - file、inode、buffer_head等结构定义
"以铜为镜,可以正衣冠;以古为镜,可以知兴替;以人为镜,可以明得失。" —— 《旧唐书》
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
