大家好,我是木木。
今天给大家分享一个扎实的 Python 库,llama-index。
llama-index
很多 LLM 应用真正的难点,不是模型会不会回答,而是你的数据怎么进来、怎么切分、怎么索引、怎么检索、怎么交给模型。llama-index 就是围绕这条数据链路设计的框架。
它很适合讲知识库、RAG、文档问答和企业内部资料助手。相比只调用模型,llama-index 更关注“模型怎么可靠地使用你的数据”。
项目地址:https://github.com/run-llama/llama_index
官方文档:https://docs.llamaindex.ai/en/stable/
三大特点
数据链路完整
从文档加载、节点切分、索引构建、检索到查询引擎,RAG 常见环节都有对应抽象。
检索友好
可以把向量检索、关键词检索、路由、重排和多种索引组合起来,适合做复杂文档问答。
生态丰富
模型、向量库、数据库、文件格式和观测工具都有大量集成,原型和生产落地都比较顺。
最佳实践
安装方式:python -m pip install llama-index==0.14.21
下面的 Demo 使用 MockEmbedding 和 MockLLM,不调用外部模型,也不会消耗 API 额度。
功能一:把文档切成节点
这段代码解决什么问题:RAG 的第一步通常不是直接把整篇文档塞给模型,而是先切成可检索的节点。节点粒度会直接影响召回质量和回答稳定性。
importwarningswarnings.filterwarnings('ignore')fromllama_index.coreimportDocumentfromllama_index.core.node_parserimportSentenceSplitterdocs=[Document(text='LlamaIndex 连接文档、索引、检索器和查询引擎,适合构建 RAG 应用。')]splitter=SentenceSplitter(chunk_size=80,chunk_overlap=0)nodes=splitter.get_nodes_from_documents(docs)print('documents:',len(docs))print('nodes:',len(nodes))print('node type:',type(nodes[0]).__name__)print('node text:',nodes[0].get_content()[:40])
切分不是越细越好。太细会丢上下文,太粗会影响检索精准度。真实项目里可以按标题、段落、表格和业务字段来设计节点策略。
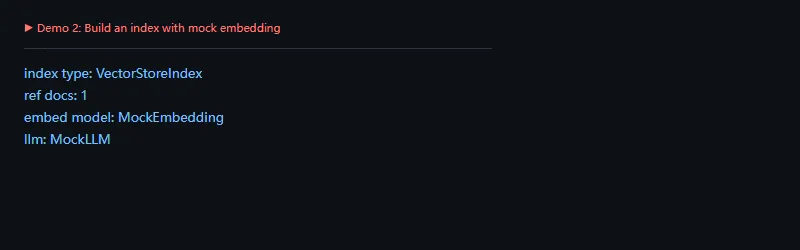
功能二:用 Mock 组件构建索引
这段代码解决什么问题:在没有真实 embedding 和 LLM 的情况下,也可以先验证索引构建流程。这样适合本地 demo、单元测试和 CI。
importwarningswarnings.filterwarnings('ignore')fromllama_index.coreimportDocument,VectorStoreIndex,Settingsfromllama_index.core.embeddingsimportMockEmbeddingfromllama_index.core.llmsimportMockLLMSettings.embed_model=MockEmbedding(embed_dim=8)Settings.llm=MockLLM(max_tokens=20)docs=[Document(text='LlamaIndex can connect private documents with LLM workflows.')]index=VectorStoreIndex.from_documents(docs)print('index type:',type(index).__name__)print('ref docs:',len(index.ref_doc_info))print('embed model:',type(Settings.embed_model).__name__)print('llm:',type(Settings.llm).__name__)
上线时再把 Mock 组件换成真实 embedding、真实 LLM 和真实向量库。这样可以把“流程正确”和“模型效果”分开排查。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 本文安装的
llama-index 版本:0.14.21 - 当前包要求 Python:
>=3.10,<4.0 - 关键依赖版本:
llama-index-core 0.14.21、llama-index-workflows 2.20.0 - 官方定位:Interface between LLMs and your data
高级功能
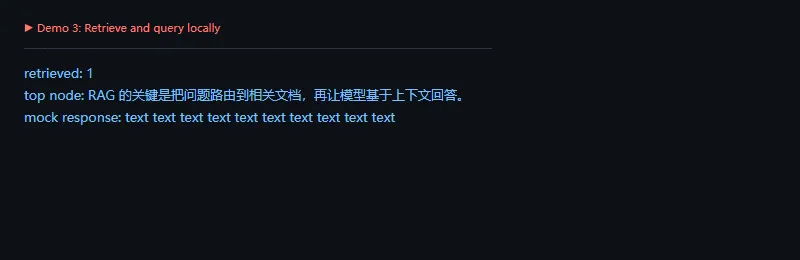
这段代码解决什么问题:从索引里检索相关节点,再交给查询引擎组织回答。这个过程就是很多知识库问答的核心骨架。
importwarningswarnings.filterwarnings('ignore')fromllama_index.coreimportDocument,VectorStoreIndex,Settingsfromllama_index.core.embeddingsimportMockEmbeddingfromllama_index.core.llmsimportMockLLMSettings.embed_model=MockEmbedding(embed_dim=8)Settings.llm=MockLLM(max_tokens=16)docs=[Document(text='RAG 的关键是把问题路由到相关文档,再让模型基于上下文回答。')]index=VectorStoreIndex.from_documents(docs)retriever=index.as_retriever(similarity_top_k=1)results=retriever.retrieve('RAG 的关键是什么?')response=index.as_query_engine(similarity_top_k=1).query('总结这段文档')print('retrieved:',len(results))print('top node:',results[0].node.get_content()[:32])print('mock response:',str(response)[:50])
RAG 的上线重点不只是“能回答”,还要看召回是否准确、上下文是否足够、答案是否引用来源、低置信度时是否拒答。
适用场景
- 数据来源多,既有 PDF、网页、数据库,也有内部文档和结构化字段
不适用场景
- 文档量很小,直接把上下文塞进 Prompt 就足够
上线检查
- 给索引更新、删除、权限过滤和低置信度拒答设计机制。
总结
llama-index 很适合把 LLM 应用和私有数据连接起来。它的核心价值不是让模型“更会聊天”,而是把文档、索引、检索和查询这条 RAG 链路变得更清楚、更可控。

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
