从 Claude Python SDK 代码看 Claude Managed Agents 的架构野心
- 2026-06-30 21:15:58
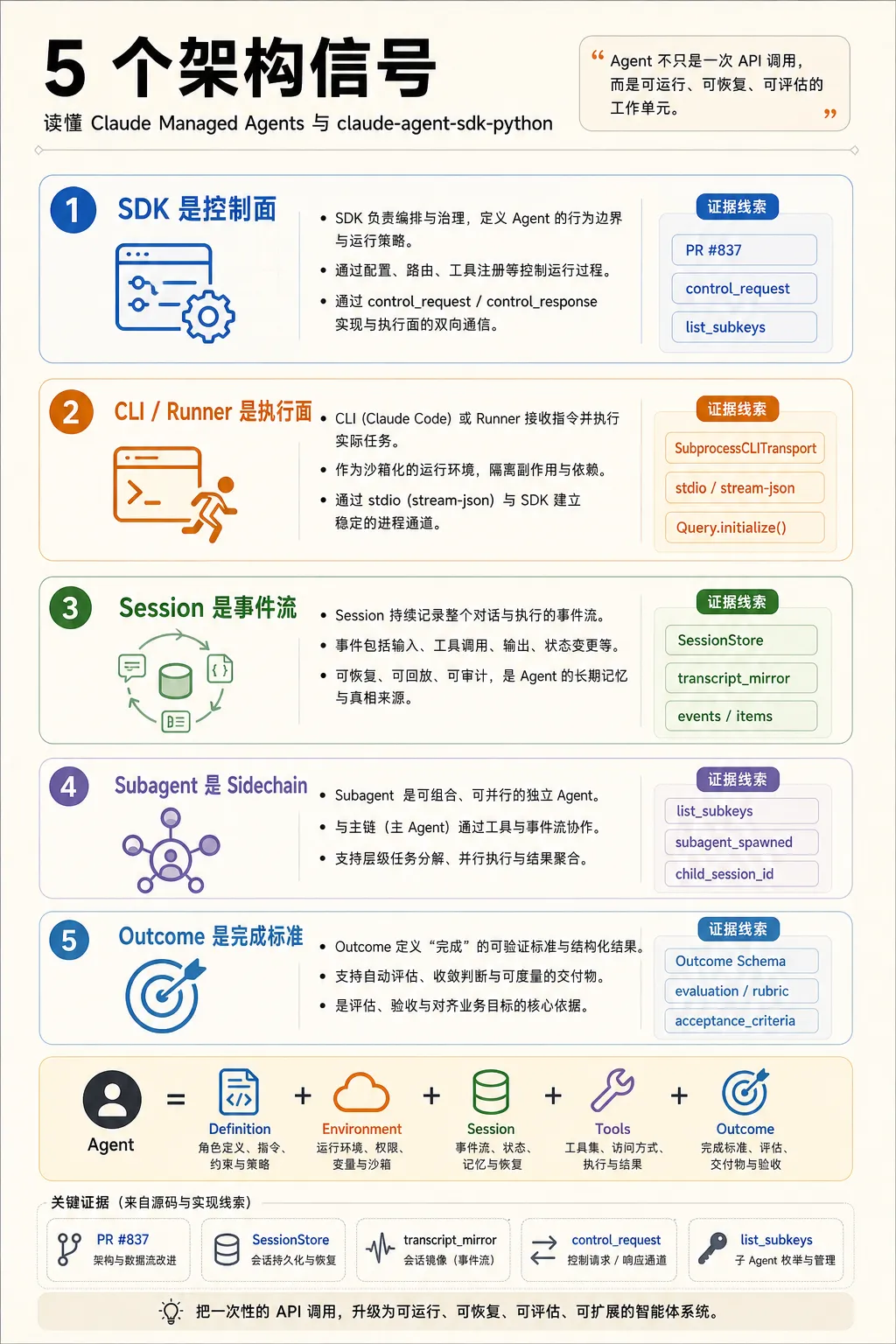
Anthropic 的 Managed Agents 文档里有一句很直接的话:它提供的是 pre-built, configurable agent harness。这个措辞挺关键。它没有把自己描述成一个更长上下文的 Messages API,也没有只说工具调用能力更完整,重点放在 harness 上。
如果只读产品文档,容易把它理解成云端版 Claude Code。顺着 Python SDK 的调用入口往下看,味道会变得更清楚:Anthropic 想交付的是一套 agent 运行时。模型只是其中一部分,真正被工程化的是 agent、环境、session、事件流、工具、权限、状态和评估。
调用入口透露的分层
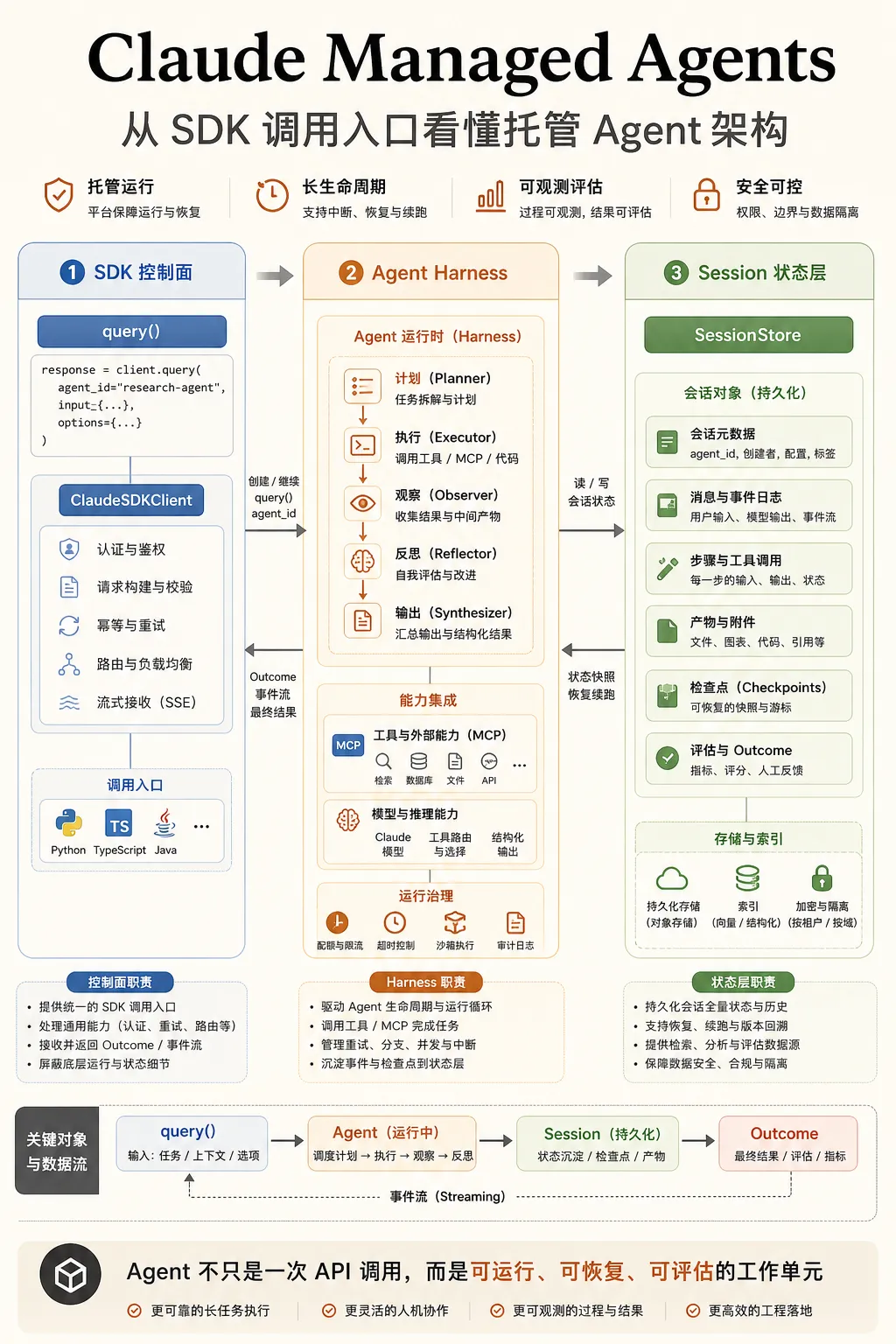
Python SDK 里有两个公开入口:query() 和 ClaudeSDKClient。
query() 看起来是一次性调用,适合脚本和自动化任务。代码里它只是创建 InternalClient,再调用 process_query()。有意思的是,虽然文档把它叫 one-shot,内部仍然总是走 streaming mode。原因也写在注释里:agents 和大配置要通过 initialize request 送进去。
ClaudeSDKClient 是长连接入口。connect() 启动 transport 和 Query,后面每次 client.query() 都只是继续往同一个 stream-json 会话里写 user message。这个设计说明 SDK 的会话边界落在背后的 agent runtime 上,而不在 Python 函数调用上。
再往下走,会看到 SubprocessCLITransport。它负责找到 Claude Code CLI,然后把 ClaudeAgentOptions 编译成命令行参数:模型、工具、权限、MCP、resume、session id、sandbox、plugin、output schema,同时固定加上 --input-format stream-json。
这就把边界划清楚了:Python SDK 是宿主侧控制面,Claude Code CLI 是本地执行面。云端 Managed Agents 只是把这个执行面换成 Anthropic 托管的 runner 和 container。
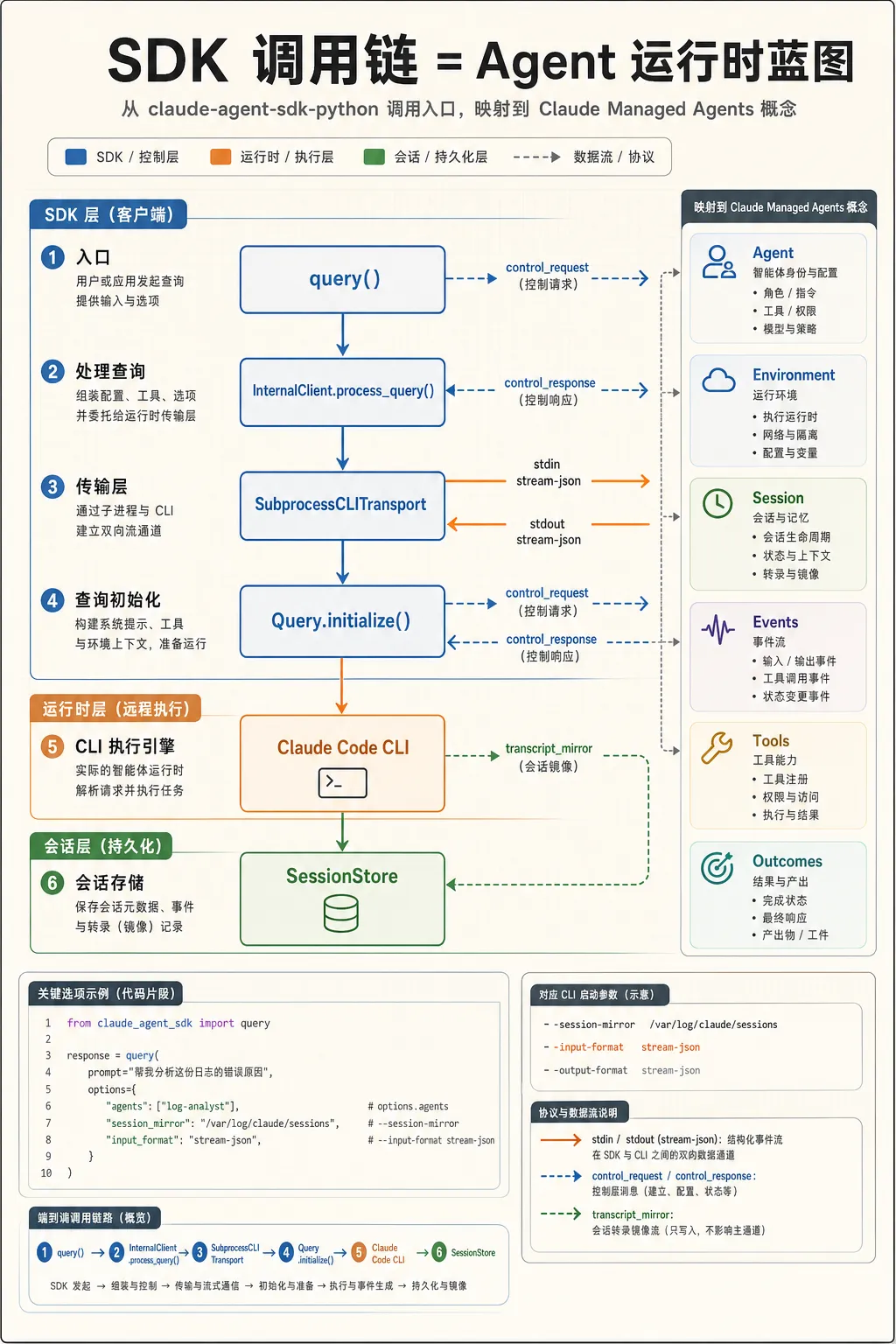
ClaudeAgentOptions 更像运行规格
ClaudeAgentOptions 不是普通请求参数。它覆盖了 agent runtime 的大部分维度。
工具层有 tools、allowed_tools、disallowed_tools、mcp_servers。治理层有 permission_mode、can_use_tool、hooks、sandbox。运行环境有 cwd、env、add_dirs、settings、plugins。会话层有 resume、continue_conversation、session_id、fork_session、session_store。推理预算还有 thinking、effort、task_budget。
这就是一个本地版的 agent spec。Managed Agents 文档里说 Agent 由 model、system prompt、tools、MCP servers、skills 组成;Environment 是带包、网络和文件系统的容器;Session 是环境里的运行实例;Events 是应用和 agent 之间交换的消息。SDK 代码把同一组概念摊在了 Python 类型系统里。
AgentDefinition 更明显。它可以配置 prompt、tools、model、skills、memory、mcpServers、initialPrompt、maxTurns、background、effort、permissionMode。这已经超出了让模型临时扮演某个角色的范围,代码在定义一个可被主 agent 调度的子 agent。
Control Protocol 是编排入口
Query.initialize() 会把 hooks、agents、skills、excludeDynamicSections 发给 CLI。这里有个细节:agents 不走命令行 flag,会通过 initialize control request 进入运行时。
这个选择很工程化。agent roster、hook callback、skills filter 这些配置可能很大,也可能需要在运行时扩展。放进控制协议,比塞进 argv 更适合长期演进。
运行过程中,CLI 还能反向给 SDK 发 control_request。SDK 处理三类请求。
can_use_tool 负责工具权限。CLI 发现某个工具需要确认时,把 tool name、input、tool_use_id、agent_id、blocked_path、decision_reason 传给 SDK。企业系统可以在这里接 IAM、审批、DLP、审计规则。
hook_callback 负责事件钩子。它可以在 PreToolUse、PostToolUse、Stop 等阶段插入逻辑。对于企业 agent,hook 的价值通常比 prompt 更稳定,因为它能把治理策略放在模型外面。
mcp_message 负责 SDK 进程内 MCP。也就是说,Python 应用可以把自己的函数包装成 MCP tool,让 Claude Code CLI 通过 JSON-RPC 调过来。工具能力留在宿主进程里,agent runtime 只看到 MCP 协议。
这套结构和云端 Managed Agents 很像:用户事件、工具确认、自定义工具结果、线程状态,都通过事件通道驱动。agent 被启动后不会变成黑盒,它一直和外部控制面保持事件通信。
PR #837 里真正重要的是 SessionStore
PR #837 的标题是 SessionStore adapter — TS parity (protocol, mirror, resume, helpers)。这个 PR 很值得看,因为它把 Python SDK 的 session 存储抽象补齐了。
SessionStore 协议只强制两个方法:append() 和 load()。
append() 的注释很关键:它在子进程本地写入 transcript 成功之后调用。也就是说,本地 JSONL 仍然是第一份耐久记录,外部 store 是镜像副本。失败不会中断会话,只会重试、记录 mirror error,然后继续跑。
load() 也很关键:它在子进程启动前调用,把外部 store 里的完整 session 读出来,然后 SDK 写入临时 CLAUDE_CONFIG_DIR,让 CLI 继续使用原来的 resume 逻辑。
这就是一个桥接设计。SDK 没有强行重写 CLI 的 session 机制,它把外部存储 materialize 成 CLI 能认识的本地文件布局。企业可以用 S3、Redis、Postgres 或自己的存储,CLI 仍然只关心 JSONL transcript。
TranscriptMirrorBatcher 负责接 transcript_mirror frame。默认模式会把 entries 缓冲起来,在 result 前 flush;eager 模式可以近实时写入。慢 store 不会卡住 read loop,这个点对长任务很重要。

Session 是事件流,不只是聊天记录
Managed Agents 文档里说 session 是 agent instance within an environment。SDK 代码把它拆得更细。
SessionKey 有三个字段:project_key、session_id、subpath。主 transcript 没有 subpath,subagent transcript 会放在类似 subagents/agent-{id} 的路径下。
file_path_to_session_key() 直接把本地路径映射成这样的 key:主文件是 <project>/<session>.jsonl,子 agent 文件是 <project>/<session>/subagents/.../agent-id.jsonl。恢复时,如果 store 实现了 list_subkeys(),SDK 会把 subagent transcripts 一起 materialize。
这说明多 agent 的状态结构不是一堆孤立会话。它更像一个主 session 下挂着多个 sidechain。主 agent 是 coordinator,子 agent 有自己的上下文和 transcript,但状态仍然归属于同一个任务实例。
再对照 Managed Agents 的 multiagent 文档,云端说法是:所有 agent 共享同一个容器和文件系统,但每个 agent 在自己的 session thread 里运行,有独立上下文和事件流。SDK 侧的 subpath 和云端的 session thread,概念上能对上。
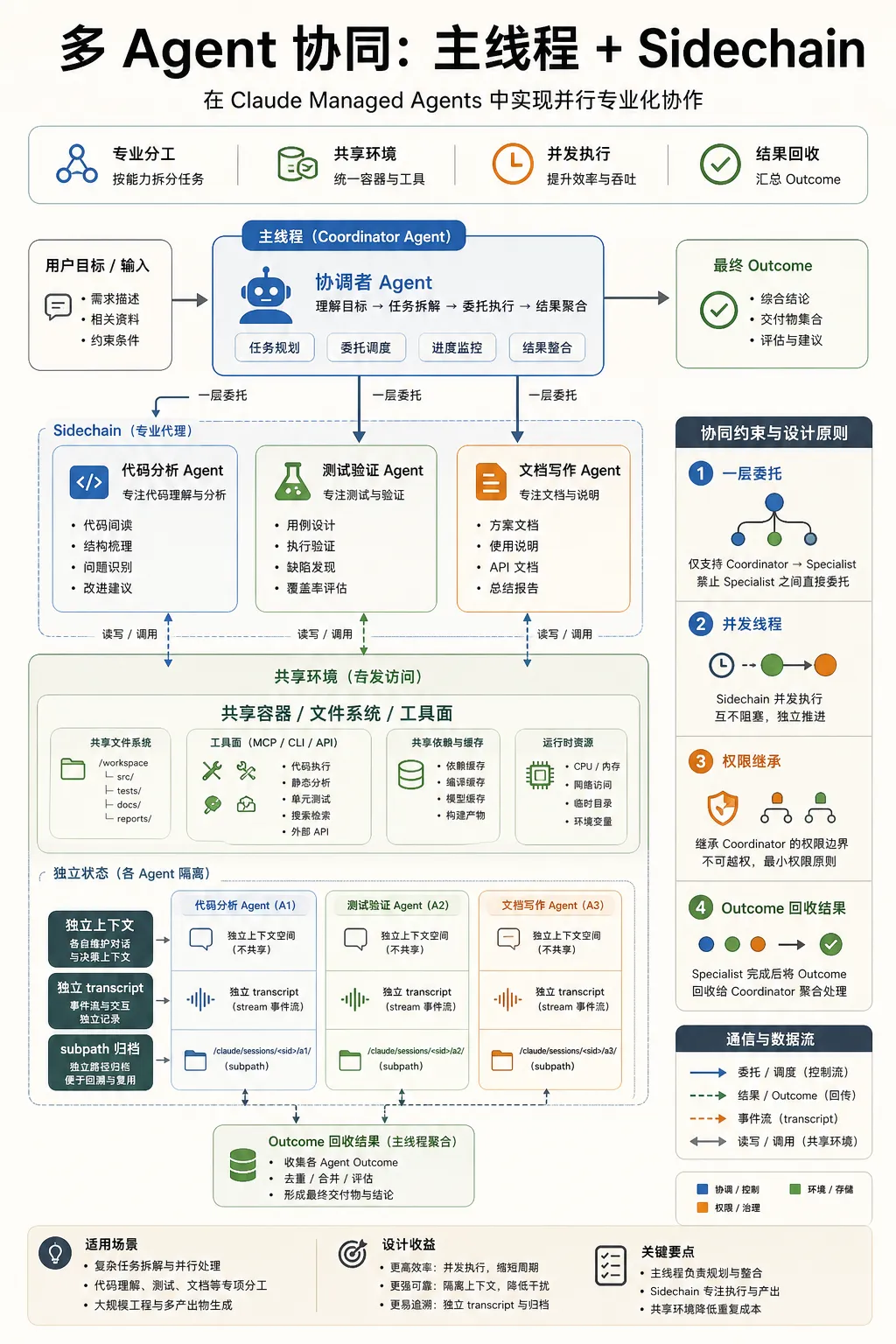
多 Agent 协同的关键不是数量
很多多 agent 框架容易走向堆角色。Claude 这套设计的重点更克制:coordinator 只能委托一层 agent,roster 最多 20 个 unique agents,最多 25 个并发 threads。这个限制其实很合理。
企业任务里,多 agent 真正有价值的地方是三类。
一类是并行化,比如同时读多个 repo、多个文档、多个数据源。
一类是专业化,比如 reviewer、tester、security analyst、doc writer 使用不同 prompt、工具和模型。
还有一类是升级处理,比如 coordinator 把某个高难子问题交给更强模型或更高 effort 的 agent。
SDK 的 AgentDefinition 已经把这些参数拆出来了。不同 agent 可以有不同 model、tools、skills、MCP servers 和 permission mode。这样主 agent 不需要把所有工具和所有上下文都塞进自己窗口里。
Outcome 把 agent 从对话推向工作单元
Managed Agents 的 outcome 设计也值得单独看。它让用户定义 done 的样子,再给 rubric。平台会自动 provision 一个 grader,用单独上下文窗口评估产物,然后把差距反馈给 agent 继续迭代。
这和传统 agent loop 的区别很大。普通 agent 通常停在 stop reason、max turns 或模型自认为完成。Outcome 把完成条件外置成 rubric,并且把评价动作从主 agent 的上下文里拆出去。
Python SDK 当前更多暴露的是 output_format、task_budget、hooks 这些局部能力。完整 outcome 更像云端 Managed Agents 的平台层能力。但从 SDK 的控制协议看,它已经具备了把外部评价、状态事件和后续输入接回 session 的结构。
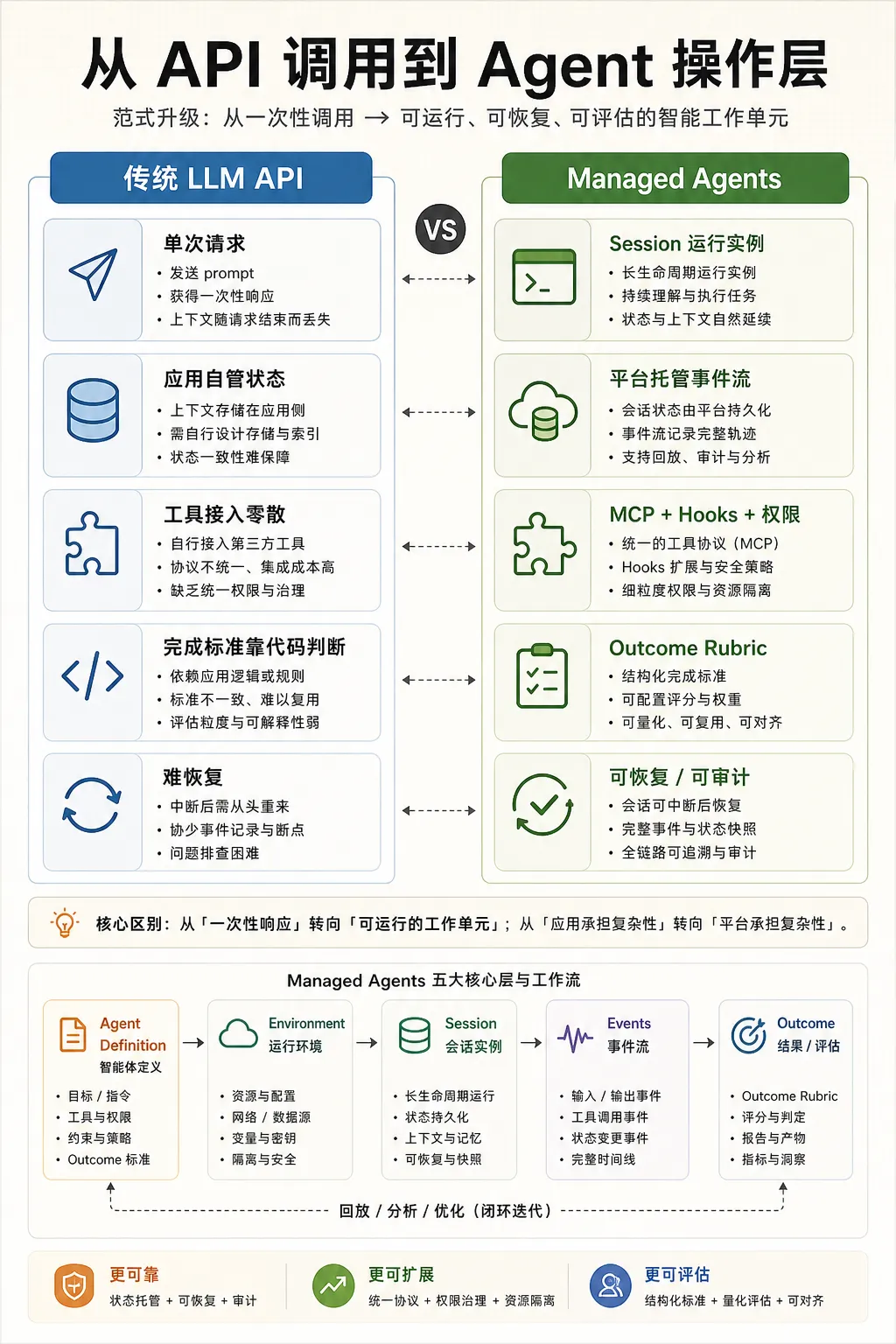
企业真正需要的是可运营
这套架构最有价值的地方,不是让 agent 回答更聪明一点。企业需要的是可运营。
可配置:agent 可以被定义成岗位型资源,而不是散落在代码里的 prompt。
可隔离:每个 session 有环境边界,云端是 container,本地是 cwd/env/sandbox 的组合。
可治理:工具权限、hooks、MCP、sandbox 都在模型外面。
可恢复:session transcript 可以外部化,resume 时重新 materialize。
可审计:事件流、tool use、permission request、subagent thread 都能被记录。
可评估:outcome rubric 把完成质量变成可检查对象。
这也是我看 SDK 后的主要判断:Managed Agents 的新意在于把 agent 从一次调用变成一个生命周期对象。它有定义,有环境,有事件,有状态,有分支,有协作线程,还有评价闭环。
落地方式
企业如果要基于这套模式设计自己的 agent 平台,可以按这条线拆。
先把 Agent Definition 做成资源。模型、系统提示词、工具、MCP、skills、权限策略都版本化。不要让业务系统临时拼 prompt。
再把 Environment 做成资源。依赖、网络、文件挂载、凭据、沙箱边界都提前配置。任务开始时只引用 environment id。
然后把 Session 当成任务实例。每个 session 有状态机,有事件流,有文件产物,有 transcript,有可中断和可恢复能力。
工具确认和自定义工具结果都走事件通道。这样 UI、审批系统、策略服务、后台 worker 可以共同参与,而不是让模型直接拥有所有权限。
加上 outcome。不要只问 agent 做完没有,要让它按 rubric 被独立检查。检查结果进入下一轮迭代,直到满足条件或达到上限。
总结
Claude Agent SDK 的代码入口很薄,但薄入口后面的结构很清楚:SDK 负责宿主侧控制,CLI 或云 runner 负责 agent 执行,SessionStore 和事件流负责状态,MCP 和 hooks 负责外部能力,AgentDefinition 负责多 agent 编排。
这条路线对开发者的提醒也很直接。做企业 agent,prompt 工程只是一小段。真正决定能不能落地的是运行时边界、状态模型、权限治理、事件协议和评估闭环。
如果把 Managed Agents 当成一个托管 Claude Code,容易低估它。更准确的看法是:Anthropic 正在把 Claude Code 这类 agent runtime 的工程经验,抽象成一套企业可接入的 agent 操作层。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 这个网站真的把python揉碎了教给我们啊~
- 【一起学Python】第88天:NumPy文件读写全攻略,数据持久化不再难!
- 数据分析师到底是干什么的?从Python应用到业务决策,深度拆解岗位本质与成长路径
- 别盯着原厂系统了!PS5“魔改”Linux实测:运行《黑神话》竟能反超原生性能?
- 完全由AI编写代码开发的一款Linux智能运维助手,只需说话提要求让工具帮你配置服务器
- 吃透Linux命令,这个手册就够了!
- 复现与修复指南:Linux内核本地提权漏洞Fragnesia(CVE-2026-46300)
- 嵌入式Linux--按键输入实验详解
- 科技晚报5月14日:Linux内核革命·普林斯顿监考回归
- DeepSeek接入Python,普通电脑飞速运行
