现在很多语音转文字工具不是收费,就是有次数或时间限制。使用起来总不尽兴。于是我和deepseek自己做了一个程序,我是项目经理,他是程序员,做了一个小巧的语音转文字程序。
一、缺点:
1、借助termux App(手机小型Linux模拟器)命令行执行,所以是命令行执行。
2、正因为还是Linux下运行,所以需要安装依赖。
3、也有失败的时候,不过重新运行可解决,可能和第三方的网络和高峰期有关,如果有失败时段较为集中,往往某时段失败后,再试还是失败。换个时段就好了。失败的情况是极少数。
二、特点:
1、因为核心还是Linux的所以pc应该也能执行,只是安装的依赖手机和pc的区别,可能不同。因为自己还开发了pc版的,所以手机版本没有在pc上印证,很可能该版本同时也能在PC上使用。手机版用起来更短小方便,所以以前开发pc版的就没在用了,因此不给大家推荐了pc版le。
2、虽说是语音转文字,实际上视频转文字也支持。程序先下载视频,(视频真正网址可通过其他工具获取,见我上篇文章),然后解析成音频文件,如果直接是音频文件则跳过转换成音频步骤,打包上传至第三方识别文字,识别后返回结果,可通过命令行文字复制功能,将识别结果copy到剪贴板。
3、如果是本地音频或视频,在直接转换上传,跳过下载。
4、要转换的音频或视频不限制长短大小,只要网络支持,可以很大,但也遇到特别大的文件没有正确完成的情况,时间或大小边界还需同志们自行测试,一般我们的需求都能满足。自己亲试过接近一个小时的视频文件都没有问题。
5、没有次数、大小的限制。如果有限制,我已经在程序中让他自行切分成小段进行解析,原则上没有大小限制。
三、具体程序如下:
(文本文件创建即可,不用专门的编辑器)
文件名:main.py
程序内容如下:
""" 音视频语音转文字 · 稳定版 - 使用 ffmpeg 处理音频,稳定可靠 - 支持本地文件和远程URL - 本地文件不会删除 - 远程文件下载后自动清理 """
import os import uuid import requests import time import sys import subprocess import tempfile
# ==================== 配置区 ==================== API_KEY = "sk-txeytxntkjafqulwhgkyagaruomfekwdqdzppdvrkpmaltas" # 使用抗干扰能力更强的模型 MODEL_ID = "FunAudioLLM/SenseVoiceSmall" # =============================================
# 临时下载目录 DOWNLOAD_DIR = os.path.join(os.getcwd(), "temp_downloads") os.makedirs(DOWNLOAD_DIR, exist_ok=True)
def is_url(path): """判断是否为网络链接""" return path.startswith(('http://', 'https://'))
def download_file(url): """下载远程文件""" filename = f"remote_{uuid.uuid4().hex[:8]}.mp4" filepath = os.path.join(DOWNLOAD_DIR, filename) print(f"📥 正在下载: {filename}") headers = {'User-Agent': 'Mozilla/5.0'} resp = requests.get(url, headers=headers, stream=True, timeout=60) resp.raise_for_status() total = int(resp.headers.get('content-length', 0)) downloaded = 0 with open(filepath, 'wb') as f: for chunk in resp.iter_content(chunk_size=1024*1024): if chunk: f.write(chunk) downloaded += len(chunk) if total > 0: percent = int(downloaded / total * 100) print(f"\r下载进度: {percent}%", end='') sys.stdout.flush() print(f"\n✅ 下载完成 ({downloaded/1024/1024:.1f}MB)") return filepath
def convert_to_wav(file_path): """使用 ffmpeg 将文件转换为 WAV 格式""" print("🎵 正在转换音频...") # 创建一个临时 WAV 文件 with tempfile.NamedTemporaryFile(suffix=".wav", delete=False) as tmpfile: wav_path = tmpfile.name # 构建 ffmpeg 命令: 提取音频,转为单声道16k WAV cmd = [ 'ffmpeg', '-i', file_path, '-ac', '1', # 单声道 '-ar', '16000', # 16kHz 采样率 '-y', # 覆盖输出文件 wav_path ] try: # 执行转换,隐藏输出信息 subprocess.run(cmd, capture_output=True, check=True) print("✅ 转换完成") return wav_path except subprocess.CalledProcessError as e: # 清理临时文件 if os.path.exists(wav_path): os.unlink(wav_path) raise Exception(f"音频转换失败: {e.stderr.decode()}")
def transcribe(wav_path): """调用 API 识别""" print("🎤 正在识别...") with open(wav_path, 'rb') as f: files = {'file': ('audio.wav', f, 'audio/wav')} data = { 'model': MODEL_ID, 'language': 'zh', 'response_format': 'text' } headers = {"Authorization": f"Bearer {API_KEY}"} try: response = requests.post( 'https://api.siliconflow.cn/v1/audio/transcriptions', headers=headers, files=files, data=data, timeout=300 ) if response.status_code == 200: result = response.json() text = result.get("text", "") return text.strip() else: return f"识别失败 (HTTP {response.status_code})" except Exception as e: return f"API调用失败: {e}"
def play_ding(): """提示音(三声蜂鸣)""" for _ in range(3): print('\a', end='', flush=True) time.sleep(0.2)
def main(): print("=" * 50) print("🎬 音视频语音转文字 · 稳定版") print("=" * 50) print("📢 说明:支持本地文件和网络链接") print(" 本地文件不会被删除") print(" 远程文件下载后自动清理\n") while True: print("\n" + "=" * 50) path = input("📁 请输入路径或链接(直接回车退出): ").strip() if not path: print("👋 退出程序") break is_remote = is_url(path) file_path = None wav_path = None try: # 1. 获取文件(下载或直接使用) if is_remote: print("🌐 检测到网络链接,开始下载...") file_path = download_file(path) else: if not os.path.exists(path): print(f"❌ 文件不存在: {path}") continue file_path = path print(f"📁 使用本地文件: {file_path}") # 2. 转换为 WAV wav_path = convert_to_wav(file_path) # 3. 识别 text = transcribe(wav_path) # 4. 显示结果 print("\n" + "=" * 50) print("📝 识别结果:") print("=" * 50) print(text) print("=" * 50) # 5. 播放提示音 play_ding() except Exception as e: print(f"\n❌ 错误: {e}") play_ding() finally: # 清理文件 if wav_path and os.path.exists(wav_path): os.unlink(wav_path) print("🧹 临时音频文件已清理") if is_remote and file_path and os.path.exists(file_path): os.unlink(file_path) print("🧹 下载的临时文件已清理") elif file_path and os.path.exists(file_path): print(f"📁 本地文件已保留: {file_path}") print("\n感谢使用,再见!")
if __name__ == "__main__": main()
四、执行
1、将以上main.py复制到手机指定目录,如手机根目录下的 \myai\
2、安装termux App
termux下载地址
下载地址github国内有时访问不了,可自行想办法,或找其他网址下载。
我在自己网盘也备份一份(不敢保证长期有效)
下载地址:通过网盘分享的文件:termux 链接: https://pan.baidu.com/s/1g7NeCOk5uZ9PKE3jdNsLIQ 提取码: 7344
3、运行termux
4、在termux中安装依赖 #先确保存储权限已授权
termux-setup-storage
# 更新包管理器
pkg update && pkg upgrade
# 安装 Python 3.11 pkg install python
# 确保 pip 是最新版 pip install --upgrade pip
# 安装我们程序需要的库 pip install requests
#安装 ffmpeg(你的程序需要它来转换音频)
pkg install ffmpeg # 验证安装 ffmpeg -version
# 进入程序目录并运行我们的程序 cd ~/storage/shared/myai python main.py
注意:如果中间出错可将错误结果给deepseek,他会告诉你如何用命令纠错继续完成
五、为方便以后执行,做批处理
# 添加到 bash 配置文件 echo "alias myai='cd ~/storage/shared/myai && python main.py'" >> ~/.bashrc
# 重新加载配置 source ~/.bashrc
# 测试运行
myai 回车
六、操作说明(以后都这样运行)
myai 回车
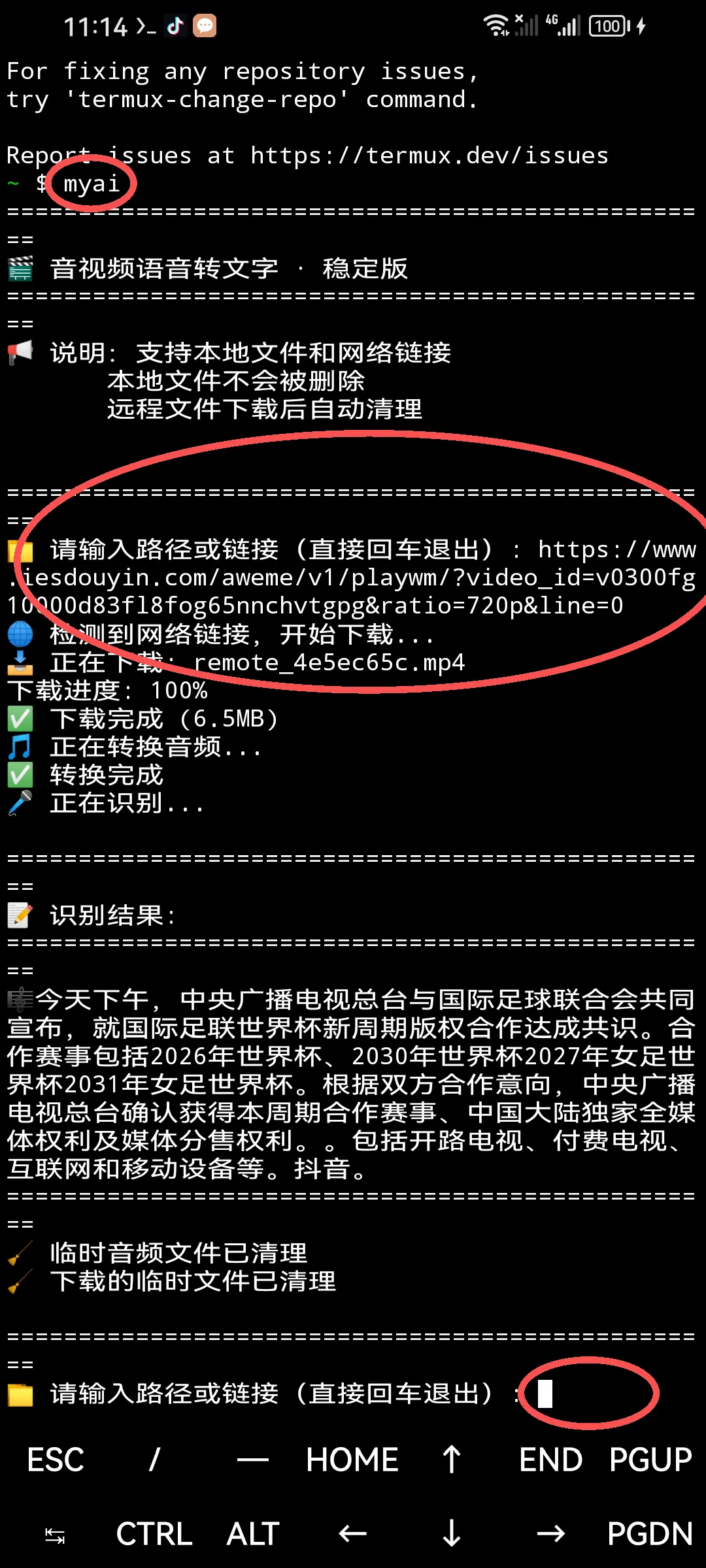
#录入音频或视频的网址,回车。(本地文件也可)
#系统开始下载,下载完毕自动转换成音频文件,然后自动上传第三方转换文字,完成后呈现结果,选中文字复制即可。过程中有提示。
#继续录入其他视频网址回车,可再进行下一个视频文字转换。
#转换后自动清理下载文件。不留垃圾。
#只录入回车则退出。
运行效果展示,红色标记是录入命令或网址区域。此处网址是抖音真实网址。(如何获取抖音视频真实网址的方法看我上篇文章)
七、termux打开声音配置,保证程序完成后能听到三声蜂鸣
# 创建配置目录(如果不存在) mkdir -p ~/.termux
# 编辑配置文件 nano ~/.termux/termux.properties
#此时在命令行打开配置文件需要编辑
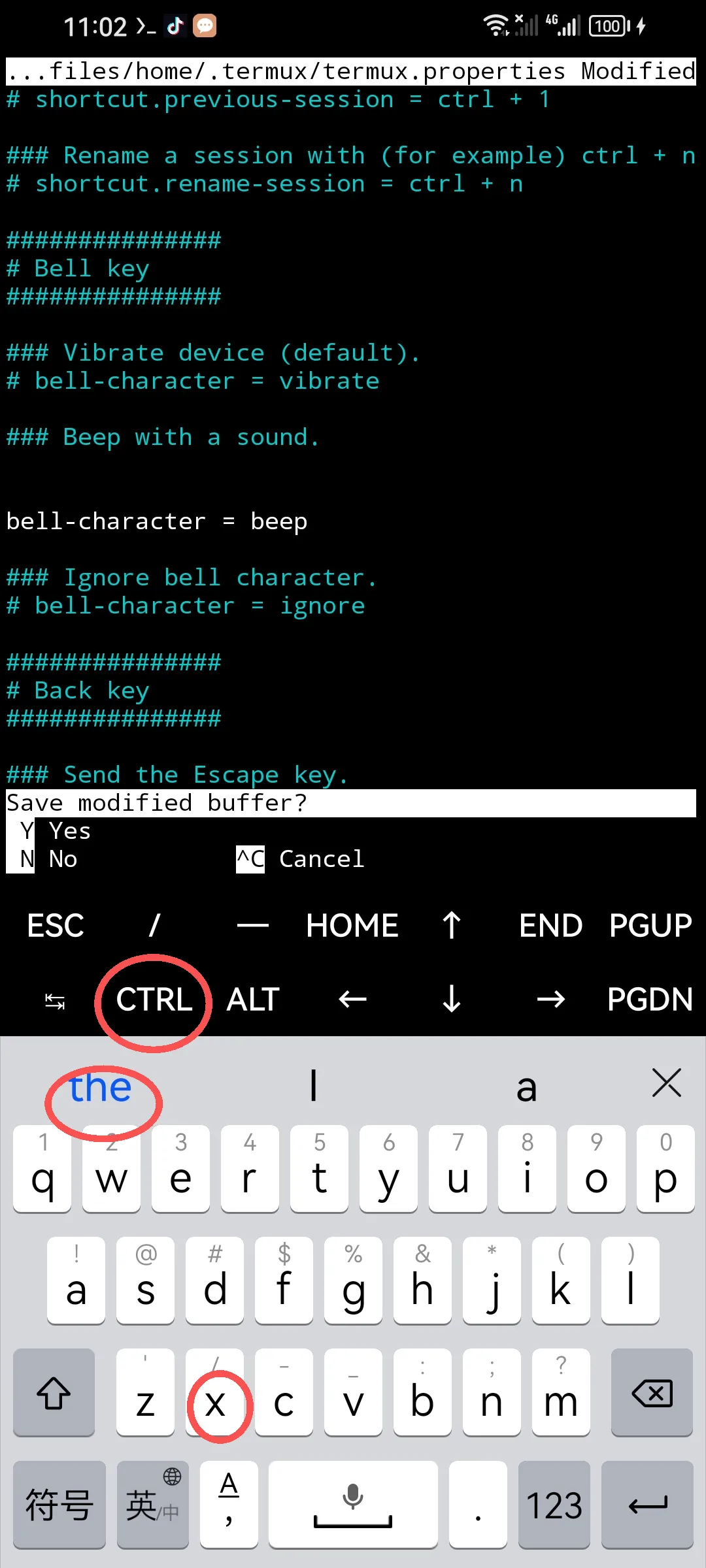
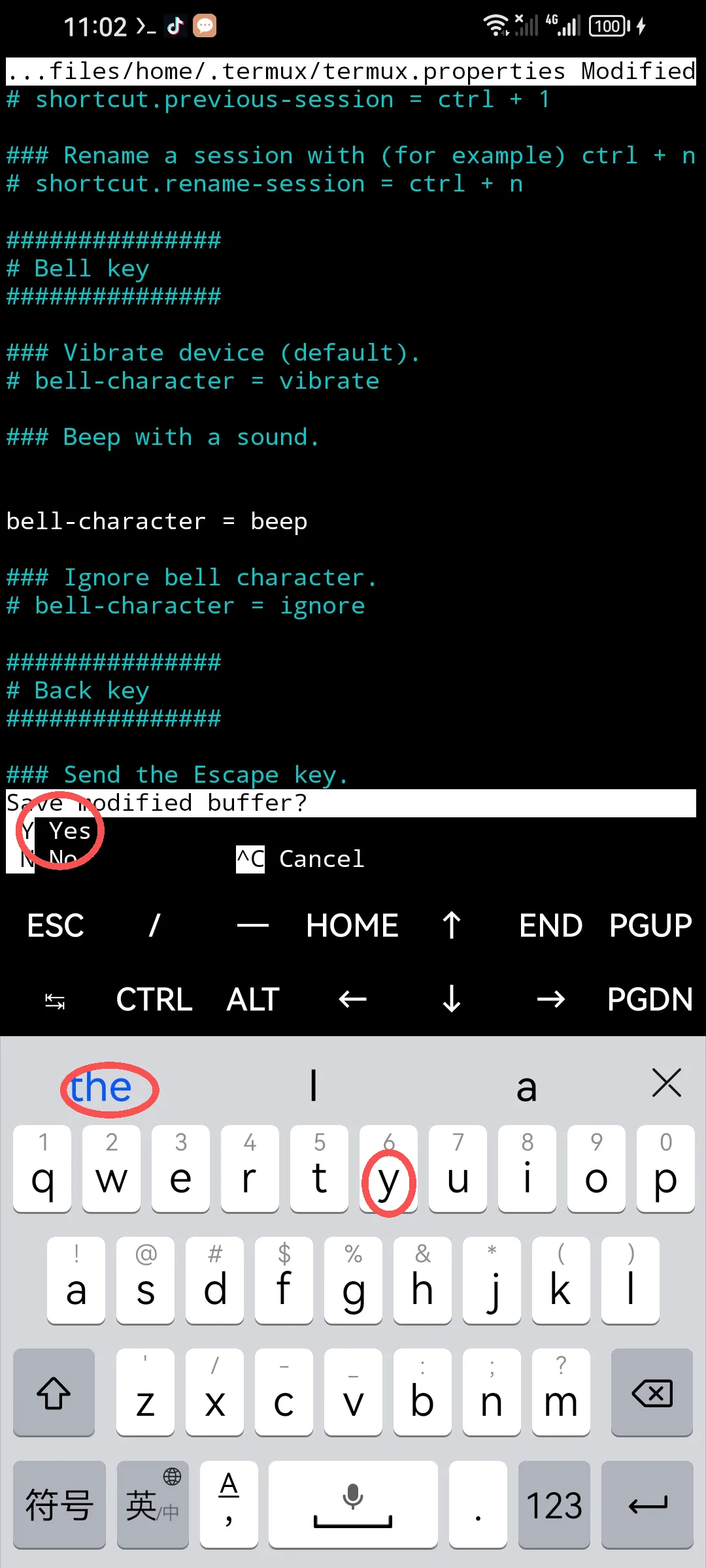
#用虚拟箭头移动光标到 #bell-character=beep 这一行,去掉前面的“#”即可,退出(ctrl+x),提问是否保存,选择y回车完成。
#重启termux即可
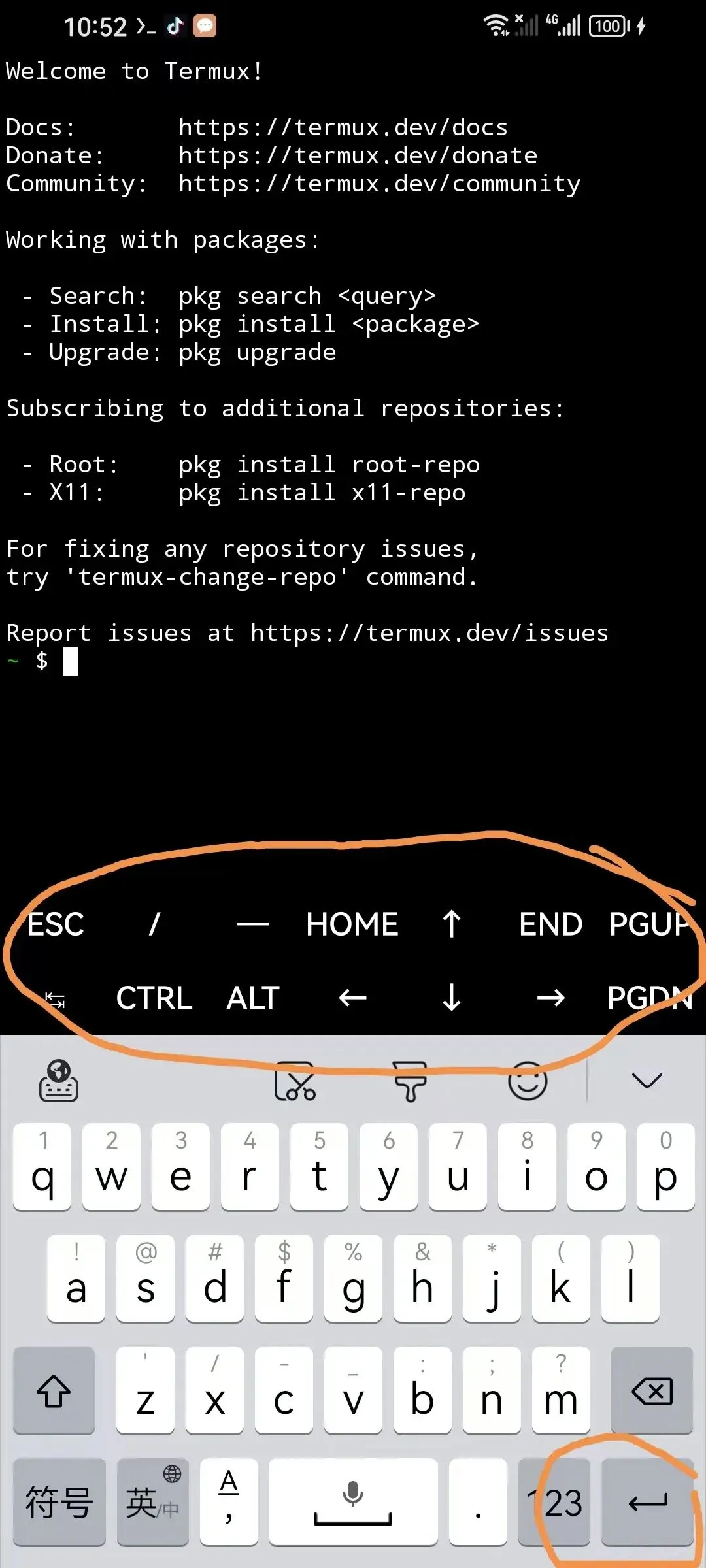
这是刚进入termux界面,标注区域是虚拟键盘和回车
这是运行nano ~/.termux/termux.properties编辑配置后的界面,如白字字体,已经去掉“#”后按ctrl+x退出,其中蓝色字体是输入法区域,按x后蓝色地方应该显示x,再按蓝色x处生效。不同手机操作略有出入。
退出时先询问是否保存,按y后蓝字显示y再点击后退出。
以上方法,平板同样有效。
我的其他作品也很有价值,和此文章也有些许关系,欢迎阅读。 :)
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
