大家好,我是木木。
今天给大家分享一个精准的 Python 库,trafilatura。
trafilatura
做网页采集时,最麻烦的往往不是把 HTML 下载下来,而是把导航、广告、侧边栏、评论区和重复内容清掉,只留下真正有价值的正文。trafilatura 就是专门做这件事的:它可以从网页里抽取正文、标题、摘要、链接和元数据,适合接在爬虫、搜索索引、知识库或 RAG 数据清洗流程后面。
项目地址:https://github.com/adbar/trafilatura
官方文档:https://trafilatura.readthedocs.io
三大特点
正文精准
重点处理网页正文抽取,能过滤导航、页脚、广告和重复文本,减少后续清洗成本。
输出灵活
支持纯文本、JSON、XML、Markdown 等输出,方便接入搜索、数据分析和文档入库流程。
工程友好
既能在 Python 代码里调用,也能作为命令行工具使用,适合批量采集和离线处理。
最佳实践
安装方式:python -m pip install trafilatura==2.0.0
功能一:从噪声 HTML 里抽取正文
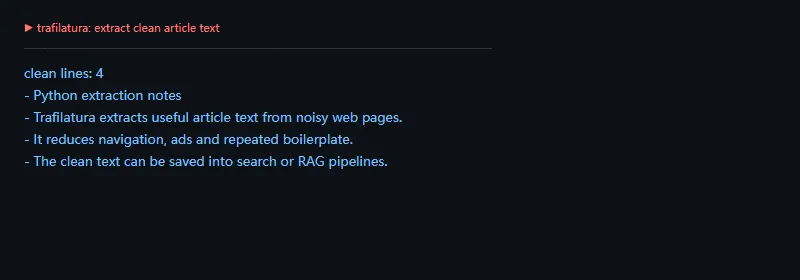
这段代码解决什么问题:把一个带有导航和页脚的 HTML 页面交给 trafilatura,只保留正文区域。实际做爬虫时,这一步可以放在下载页面之后、写入数据库之前。
importtrafilaturahtml="""<html><body> <nav>Home | Docs | Pricing</nav> <article> <h1>Python extraction notes</h1> <p>Trafilatura extracts useful article text from noisy web pages.</p> <p>It reduces navigation, ads and repeated boilerplate.</p> <p>The clean text can be saved into search or RAG pipelines.</p> </article> <footer>Copyright and newsletter links</footer></body></html>"""text=trafilatura.extract(html,include_comments=False)or""lines=list(dict.fromkeys(lineforlineintext.splitlines()ifline.strip()))print("clean lines:",len(lines))forlineinlines:print("-",line)
抽取结果不是简单地去掉 HTML 标签,而是尽量判断页面主内容。对新闻、博客、文档页这类正文明确的页面,它通常比自己写正则稳很多。
功能二:导出结构化结果
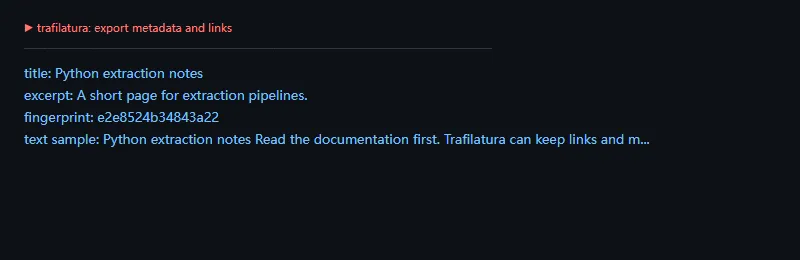
这段代码解决什么问题:当后续流程不只需要正文,还需要标题、摘要、指纹等信息时,可以直接使用 JSON 输出,减少自己拼装字段的工作。
importjsonimporttrafilaturahtml="""<html><head> <title>Python extraction notes</title> <meta name="description" content="A short page for extraction pipelines."></head><body> <article> <h1>Python extraction notes</h1> <p>Read the <a href="https://example.com/docs">documentation</a> first.</p> <p>Trafilatura can keep links and metadata for downstream jobs.</p> </article></body></html>"""raw=trafilatura.extract(html,output_format="json",include_links=True,include_comments=False,with_metadata=True,)data=json.loads(raw)print("title:",data["title"])print("excerpt:",data["excerpt"])print("fingerprint:",data["fingerprint"])print("text sample:",data["text"][:86]+"...")
如果你要把网页内容进入 Elasticsearch、向量库或离线分析任务,结构化输出会更好维护。尤其是 fingerprint 字段,可以作为去重或增量处理的参考。
环境与版本信息
- Demo 环境:Windows 11,Python 3.11
- 本文安装的
trafilatura 版本:2.0.0 - 关键依赖版本:
lxml 5.4.0、courlan 1.3.2、htmldate 1.9.4、justext 3.0.2 - 项目最近一次提交时间:
2025-09-12T15:24:16+02:00
高级功能
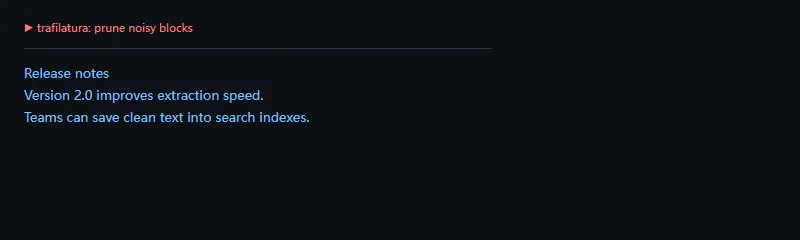
这段代码解决什么问题:真实页面里经常会有固定噪声块,比如广告、推荐栏、订阅框。prune_xpath 可以在抽取前先剪掉指定节点,让正文更干净。
importtrafilaturahtml="""<html><body> <main> <h1>Release notes</h1> <p>Version 2.0 improves extraction speed.</p> <div class="ad">Buy crawler credits now.</div> <p>Teams can save clean text into search indexes.</p> </main></body></html>"""text=trafilatura.extract(html,include_comments=False,prune_xpath=["//div[@class='ad']"],)print(text)
这个能力很适合处理同一站点的批量页面:先观察页面结构,再把稳定出现的噪声块加入剪枝规则。这样比事后在纯文本里二次删除更可控。
适用场景
- 你要给搜索索引、知识库或 RAG 流程准备干净文本。
- 你希望同时拿到标题、摘要、日期、指纹等结构化信息。
不适用场景
- 页面主要内容依赖登录、复杂交互或前端动态渲染,且没有先完成浏览器抓取。
- 你需要完整保留页面布局、表单、脚本行为或视觉样式。
- 页面结构极度混乱,仍需要针对站点写专门规则和人工校验。
上线检查
- 先准备一批真实页面样本,检查正文抽取率和误删情况。
- 对同一来源站点配置稳定的
prune_xpath 和去重策略。 - 保存原始 URL、抽取时间和 fingerprint,方便追踪和重跑。
总结
trafilatura 是一个很适合放在网页采集后半段的清洗工具。它不负责浏览器自动化,也不替你理解内容语义,但在“从 HTML 里拿出干净正文”这件事上非常扎实。做爬虫、搜索、RAG 或内容归档时,可以优先试试它。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
