Python应用实例 :使用 edge_tts 模型实现文字批量转换语音
- 2026-06-23 08:46:18
点击蓝字,关注我们

前言
上次我介绍使用python批量“语言转文字”时,有朋友留言是否可以实现批量“文字转语音”。正好我们家孩子学说话,我给她做了几个绘本,需要用到这个功能,今天我就通过示例:如何使用批量“文字转语音”给小朋友做唐诗绘本配音,介绍这个功能。
1.程序目标效果
2.关键库:语音转换模型——edge_tts
3.程序设计核心
4.总结
一、程序目标效果
根据我的需要,程序设计目标至少应该包含以下几个基本功能:
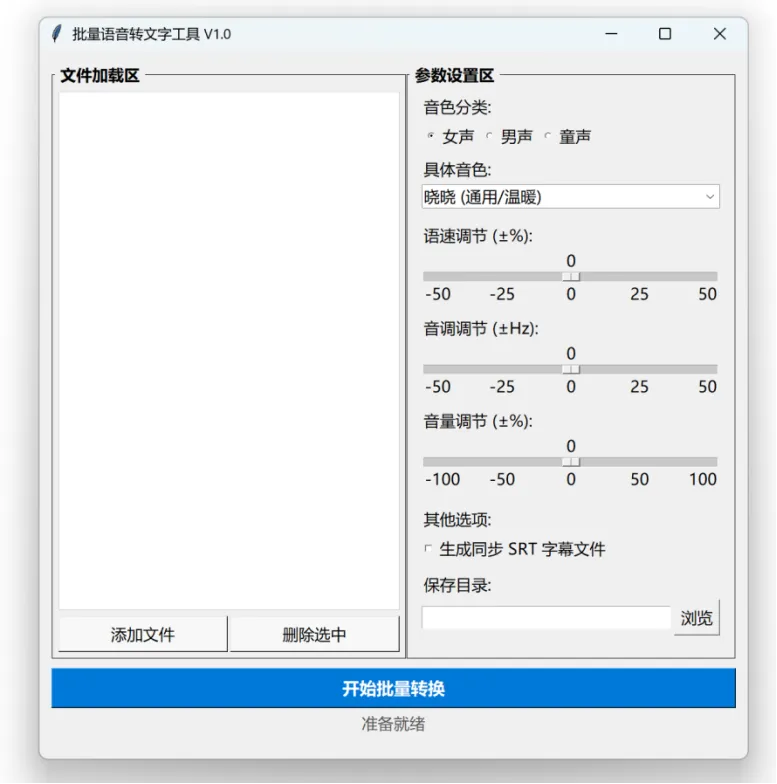
程序自带GUI(采用tkinter设计),至少包含文件选择、音色选择和文件保存等基础功能。
由用户提供文字稿件(如唐诗宋词),格式为txt或word常用文本格式,可以用程序批量选择需要转换的文稿。对窗口内的文稿,可以进行添加和删除。
参数设置区:可以选择音色、语速等基础参数,对语音效果进行调参。
可以指定语音的保存位置,选择是否输出字幕。
可以对文稿进行批量化一次性语音生成,提高转换效率。

程序执行效果:
二、关键库:语音转换模型——edge_tts
这个项目除了GUI的设计,我们需要用到的最关键的库是edge_tts,所以这里我需要介绍下edge_tts的功能和使用:
edge_tts介绍:
edge_tts 是一个免费、开源的 Python 库,它直接调用微软 Azure Edge 浏览器的官方语音合成接口,无需申请 API Key、无需付费、无需安装额外软件,就能生成自然流畅、媲美真人的语音。光是无需申请 API Key这项,就是天然的最优选择。
edge_tts主要功能:
文本转音频:支持读入txt和word格式文字,输出 MP3 音频文件
海量音色选择:支持中文男女声(多种音色选择)、方言、英文、多语种
调节语音参数:音量、音调、语速等
支持字幕生成:生成语音可同步导出 srt 字幕文件
安装及调用方式:
# 安装命令pip install edge_tts# 调用模型及配套库import edge_ttsimport asyncioimport threadingedge_tts免费且功能强大,可以使用于自媒体与短视频配音、有声阅读、辅助学习与教育、语音播报等场景,我认为还是非常实用的。
三、程序设计核心
1.程序设计流程
✅ 读取模块:
负责导入用户选择的文本文件,比如txt和word格式,解析其内容:
def add_files(self):# 打开文件选择对话框,只允许选 txt/docx/doc 文档 files = filedialog.askopenfilenames(filetypes=[("文档", "*.txt *.docx *.doc")])# 遍历用户选中的所有文件for f in files:if f notin self.file_paths: self.file_paths.append(f) self.file_listbox.insert(tk.END, f" 📄 {os.path.basename(f)}") # 把文件名显示在界面列表里✅ 语音参数调整:
涉及内容比较多,我就不一一展示了,这里主要介绍音色的选择。edge_tts可供选择模型很多,这里使用“嵌套字典”预设了几种常用的类型:
self.voice_map = {"女声": {"晓晓 (通用/温暖)": "zh-CN-XiaoxiaoNeural","晓伊 (温柔)": "zh-CN-XiaoyiNeural","晓涵 (专业)": "zh-CN-XiaohanNeural","晓妮 (陕西口音)": "zh-CN-XiaoniNeural","晓佳 (粤语)": "zh-HK-HiuGaaiNeural" },"男声": {"云杨 (新闻/主播风格)": "zh-CN-YunyangNeural","云希 (阳光)": "zh-CN-YunxiNeural","云健 (解说)": "zh-CN-YunjianNeural","云扬 (新闻/主播风格)": "zh-CN-YunyangNeural","云龙 (粤语)": "zh-HK-WanLungNeural" },"童声": {"云夏 (活泼童声)": "zh-CN-YunxiaNeural" }✅ 语音转换生成:
这里定义了一个异步函数,用于语音转换,注意使用async def。转换函数依次调用以下功能函数,然后循环执行完列表里的所有文件:
输出目录 out_dir
待转换文件列表 file_paths
语音分类 voice_cate
具体音色 voice_combo
语速 speed_scale
音调 pitch_scale
音量 vol_scale
是否生成字幕 srt_var
2.GUI设计
GUI设计我使用的仍然是前面介绍的tkinter库,窗口组成主要包括:
Frame:GUI窗口
PanedWindow:左右分栏布局(文件区、参数区)
LabelFrame:带标题的功能分组框(文件加载区、参数设置区)
Listbox:批量导入的文件列表
Button:按钮(添加文件、删除、浏览路径、开始转换)
Entry:输入或显示输出目录路径
Radiobutton:选择音色分类(女声、男声、童声)
Combobox:选择具体语音模型
Scale:调节语速、音调、音量参数
Checkbutton:控制是否生成srt字幕文件
Label:显示提示信息和当前处理状态
具体的控件名称和功能可以对照《Tkinter控件全解-Python原生GUI开发指南》这期的内容。
四、总结
本期主要是介绍使用“edge_tts 模型”实现文字批量转换语音。这个程序简单实用,可以提高工作效率。程序的代码和exe文件我都放在评论区,感兴趣的小伙伴可以下载体验。如果你还有其它好的想法和需求,也可以在评论区留言或者给我私信交流,我将作为后续更新的内容。
本期内容就到此为止,如果你也对 Python 编程技巧和应用实例感兴趣,欢迎点赞,收藏,关注,我将以应用案例为基础持续更新公众号文章。你也可以在公众号后台,获取 Python 编程的资料和工具,也可以与我私信交流想法和需求,我们下期再见~
求点赞

求分享

求喜欢


