图解 Linux 内存管理:malloc 一块内存,内核背后做了什么?
- 2026-07-02 16:45:38
作者:小康,C/C++编程博主
关键词:伙伴系统、slab分配器、NUMA、内存管理、Linux内核、malloc、内存碎片
前言
写 C/C++ 的人每天都在用 malloc,但很少有人认真想过:
这一块内存,内核是怎么给你的?
物理内存那么大一块,怎么分给成千上万个进程用?为什么频繁 malloc/free 会产生内存碎片?slab 分配器又是什么?服务器有几十个 CPU、几百 GB 内存,NUMA 架构对性能有什么影响?
这篇文章,从物理内存的管理讲起,把伙伴系统、slab 分配器、NUMA 架构串成一条线,一次讲透 Linux 内存管理的核心设计。
一、物理内存的基本单位:页
Linux 管理物理内存,不是按字节管,而是按页(Page)管。
x86-64 架构下,一页默认是 4KB。4GB 内存就是 100 万个页,内核用一个叫 struct page 的结构体描述每一个物理页:
structpage {unsignedlong flags; // 页的状态标志(脏页、锁定等)atomic_t _refcount; // 引用计数structlist_headlru;// LRU 链表,用于页面回收// ...};内存再大,最终都是在管理这些 page 对象。
但问题来了:内核自己需要分配内存,进程需要内存,设备驱动需要内存……怎么高效地把这些 page 分出去,用完了再收回来,还不产生大量碎片?
这就是伙伴系统要解决的问题。
二、伙伴系统:大块内存的管家
伙伴系统(Buddy System) 是 Linux 管理物理页的核心机制,负责页级别的内存分配,最小单位是一个页(4KB),最大一次能分配 4MB(1024 个连续页)。
核心思路是:把所有空闲页按 2 的幂次 分组管理,共 11 个等级(order 0 到 order 10):
order 0:每块 1 个页(4KB)order 1:每块 2 个页(8KB)order 2:每块 4 个页(16KB)...order 10:每块 1024 个页(4MB)每个 order 维护一个空闲块链表。
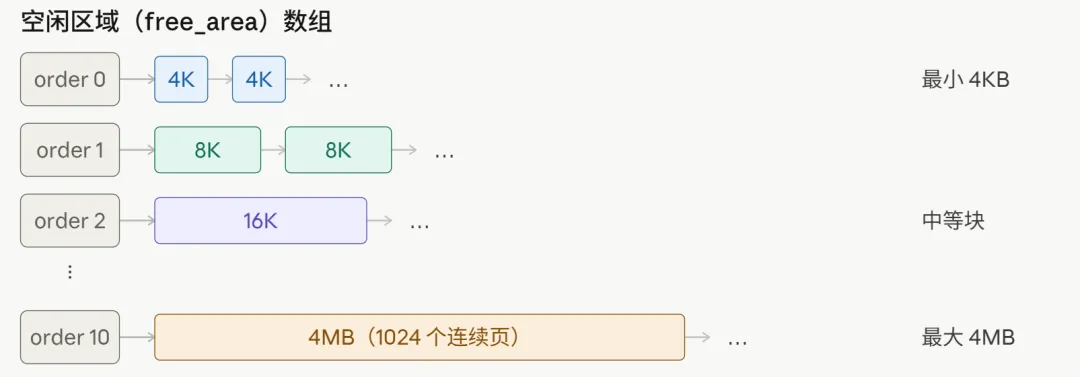
分配过程:申请 order N 的内存块,先去 order N 的链表找,找到了直接给;找不到,就去 order N+1 找一块,劈成两半,一半给申请方,另一半放到 order N 的链表里。
回收过程:释放一个块,检查它的"伙伴"(相邻的、大小相同的那块)是否也是空闲的。如果是,两块合并成一个 order+1 的大块,继续往上合并,直到无法合并为止。
这就是"伙伴"名字的由来——分配和回收都在找伙伴、和伙伴合并。
伙伴系统的优势:分配和释放都是 O(log N) 的操作,合并机制能有效减少外部碎片(大块空闲内存被切散的问题)。
伙伴系统的局限:最小单位是一个页(4KB)。你只需要一个 100 字节的结构体,内核给你 4096 字节,浪费了 4KB 里的大部分——这叫内部碎片。
解决这个问题,靠 slab 分配器。
三、slab 分配器:小对象的专属管家
内核里有大量频繁创建销毁的小对象:task_struct、inode、dentry、file……如果每次都向伙伴系统申请一整个页,用完就还,浪费极大,而且频繁的分配/释放会引起严重碎片。
slab 分配器的核心思路:
从伙伴系统拿来一大块内存(一个或几个页),把它切成等大的小格子,专门用来分配某种固定大小的对象。对象释放后,格子不还给伙伴系统,而是留着给下次同类对象用。
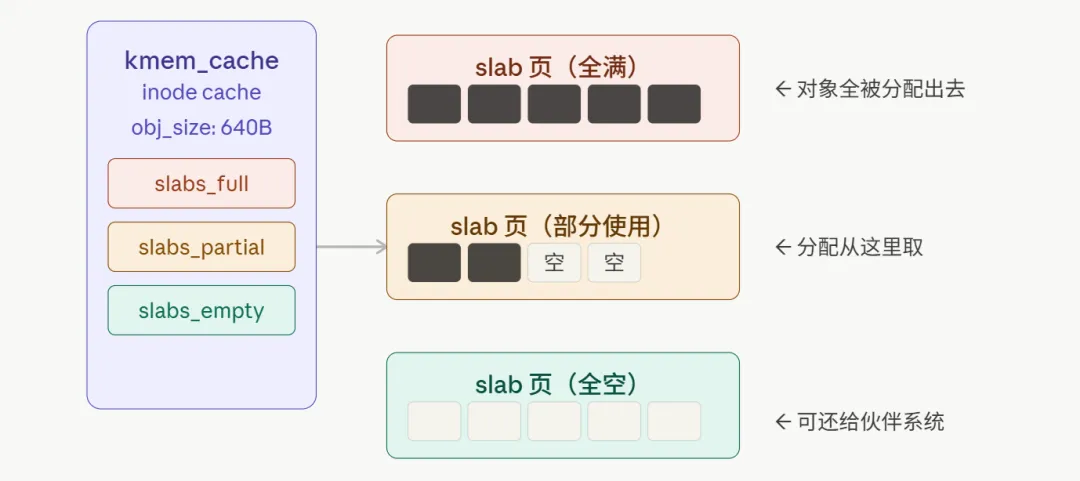
每个 kmem_cache 管理三类 slab 页:
slabs_full:格子全满,没有空闲对象 slabs_partial:有空有满,分配时优先从这里取 slabs_empty:全空,可以归还给伙伴系统
分配一个 inode 对象,内核从对应的 kmem_cache 的 partial slab 里取一个格子,标记为已用,返回指针——速度极快。
释放时,格子标回空闲,不还给伙伴系统,等下次分配直接复用。
# 查看当前系统的 slab 缓存cat /proc/slabinfo | head -20# 或者sudo slabtop你会看到 inode_cache、dentry、tcp_bind_bucket 等内核对象的 slab 信息,数量、大小一目了然。
slab 的核心价值:消灭内部碎片,避免频繁向伙伴系统申请/归还,对象复用还能保留 CPU cache 热度(刚释放的对象内存还在 cache 里,下次分配直接用)。
现代 Linux 内核默认用的是 slab 的改进版 slub 分配器,结构更简单,多核扩展性更好,原理类似。
四、用户态的 malloc:站在内核肩膀上
讲完内核,再说说用户态的 malloc。
malloc 不是每次都直接调系统调用的。glibc 的 ptmalloc 自己维护了一个内存池,策略大致是:
小对象(< 128KB): → 用 brk() 扩展堆,在用户态内存池里切块给你 → free 后放回内存池,不立刻还给内核大对象(>= 128KB): → 直接用 mmap() 向内核申请匿名映射 → free 后立刻用 munmap() 还给内核// 底层两个系统调用brk(addr); // 移动堆顶指针,扩展/收缩堆mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); // 匿名内存映射所以 malloc 的调用链是:
malloc() → ptmalloc 内存池(用户态) → 池子不够时:brk() 或 mmap()(系统调用) → 内核虚拟内存管理 → 缺页中断时:伙伴系统分配物理页 → 小内核对象:slab 分配器每一层都有自己的缓存,尽量减少穿透到下一层的频率。
五、NUMA:多路服务器的内存陷阱
前面说的都是单 CPU 的情况。现代服务器往往有几十个 CPU 核,分布在多个物理 CPU 上,这时候内存架构就变了。
UMA(Uniform Memory Access):所有 CPU 访问同一块内存,延迟相同。适合核数少的情况。
NUMA(Non-Uniform Memory Access):每个 CPU 有自己的本地内存,访问本地内存快,访问其他 CPU 的远端内存要经过 QPI/UPI 总线,延迟高出 2-3 倍甚至更多。
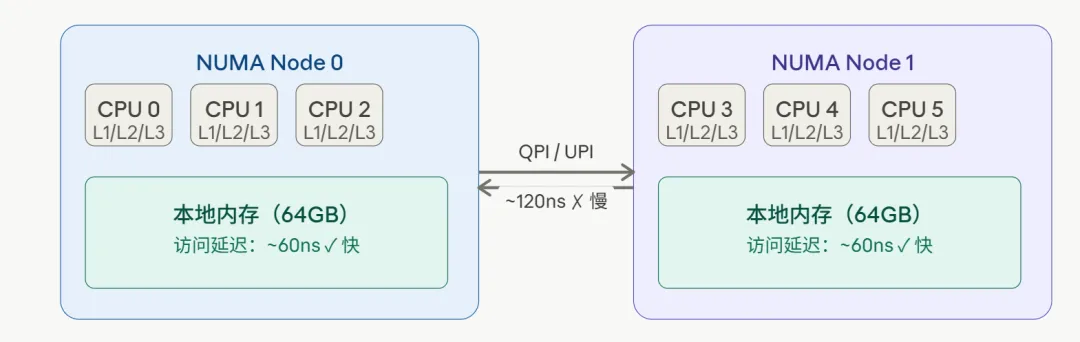
Linux 内核感知 NUMA 拓扑,伙伴系统也是按 NUMA 节点分区管理的:每个节点有自己的 zone 和 free_area,分配内存时优先从当前 CPU 所在节点的本地内存分配,实在不够才去远端节点"借"。
# 查看 NUMA 节点信息numactl --hardware# 查看各节点内存使用numastat# 绑定进程到指定 NUMA 节点运行numactl --membind=0 --cpunodebind=0 ./my_serverNUMA 对性能的影响有多大? 在内存密集型应用(数据库、内存缓存)里,跨 NUMA 节点访问内存,延迟可能是本地的 2-3 倍。同样的代码,NUMA 绑定做好了,性能提升 20%-50% 不罕见。Redis、MySQL 在多路服务器上都会做 NUMA 绑定优化。
六、整体架构:从 malloc 到物理页
把三个部分串起来,一次内存分配的完整路径:
用户 malloc(100B) ↓ptmalloc 内存池(用户态) ↓ 池子不够,调 brk/mmap内核虚拟内存管理(VMA 记录映射关系) ↓ 访问时触发缺页中断伙伴系统(分配物理页,按 NUMA 节点就近分配) ↓ 内核小对象走另一条路slab/slub 分配器(inode、dentry、tcp_sock 等)用户态看到的是连续的虚拟地址,内核在背后把物理内存拼凑好,中间还有 TLB、页表、缺页中断这一套机制负责虚实映射。
七、高频面试题精析
Q:为什么频繁 malloc/free 会导致内存碎片?
两种碎片。外部碎片:内存里有很多小块空闲空间,但不连续,无法满足大块连续内存申请——伙伴系统的合并机制缓解了这个问题。内部碎片:申请 100 字节,给你一个 128 字节的格子,剩下 28 字节白白浪费——slab 分配器对固定大小的对象效果好,ptmalloc 对随机大小的对象有一定碎片。
Q:slab 分配器和 malloc 有什么区别?
slab 是内核态的分配器,专门用于内核内部固定类型对象(inode、dentry 等)的分配,对象大小固定,复用率高。malloc 是用户态接口,底层依赖 ptmalloc/tcmalloc 等实现,处理任意大小的分配请求。ptmalloc 本身对小对象也有类似 slab 的缓存机制(bins),但灵活性更高。
Q:NUMA 下内存分配慢,怎么优化?
核心是"本地优先":让进程绑定在固定的 NUMA 节点上跑(numactl --cpunodebind),内存也从同一节点分配(--membind);避免进程在不同节点的 CPU 之间迁移。对于数据库和缓存服务,还要考虑数据结构的 NUMA 感知设计——让热点数据尽量放在操作它的 CPU 本地节点内存里。
Q:/proc/meminfo 里的 Slab 字段是什么?
cat /proc/meminfo | grep -i slab# Slab: 512MB ← slab 分配器占用的总内存# SReclaimable: 480MB ← 可回收部分(dentry/inode cache)# SUnreclaim: 32MB ← 不可回收部分(内核核心结构)内存紧张时,内核会回收 SReclaimable 部分(清掉文件系统缓存),腾出内存给应用用。
结语
Linux 内存管理是分层设计的典范:
伙伴系统 管大块物理页,用 2 的幂次分组,靠合并伙伴消灭外部碎片;slab 分配器 管小内核对象,固定大小、预分配、高复用,消灭内部碎片;NUMA 架构 让每个 CPU 有自己的本地内存,分配时就近原则,最大化内存带宽利用率。
三层各司其职,合力撑起了 Linux 在各种硬件规模下的高性能内存管理。
下次再看到 OOM Killer 把你的进程干掉,或者服务器内存莫名其妙高居不下,打开 /proc/meminfo 和 slabtop 看一眼,你会知道从哪里开始查。
觉得有收获,点赞、推荐、转发给朋友,让更多人看到,感谢~ 🙏
小康的C++项目实战课程了解下
如果你对 Linux C/C++ 后台开发感兴趣,想真正上手做项目,可以了解小康的 C/C++ 项目实战课程:
C/C++ 项目实战课程海报:

近 10 个月来,小康陆续完成了 23 个 C++ 硬核项目课程:线程池、内存池、MySQL连接池、日志库、无锁队列、协程库、高性能网络库、LSM 存储引擎、WebSocket 聊天室、FlashHTTP Server、Mini-STL、Mini-Redis、XRPC 分布式RPC…… 带领 430+ 同学从零实现这些项目,每个都是能跑、能上简历的那种。
想系统补齐项目经验、丰富简历、提升面试可聊内容,可以点击下面这篇查看完整介绍:
对C++项目实战课程感兴趣的朋友,加我微信:jkfwdkf,备注「 项目实战 」,打包购买有优惠。
或者扫码加小康微信: