在日常文本操作中,我們知道head -n 組合tail -n可文本進行豎向的定位,快速的找到所在的行。
所在列呢,我們對不固定長度,固定格式。簡單的可以用cut,再雜一點的可以用awk。但對固定長度,固定格式分割。對初學者來說,這兩個法就是有點不好掌握。
我今就引入我要說的命令colrm(中譯列之刪除 ,column remove的縮寫)。
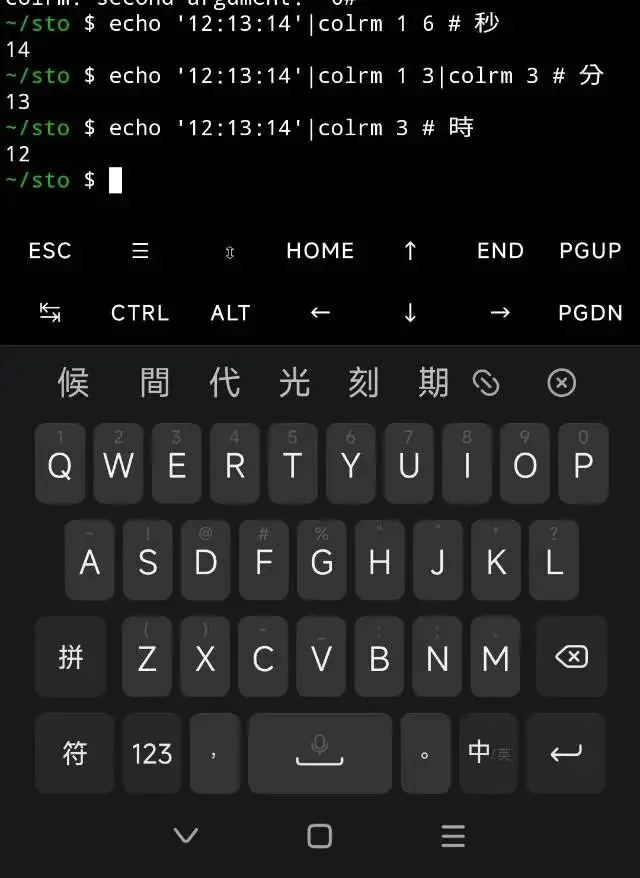
開胃菜——我們有一個時間文本。分別用colrm裁剪出,小時、分鐘和秒數。
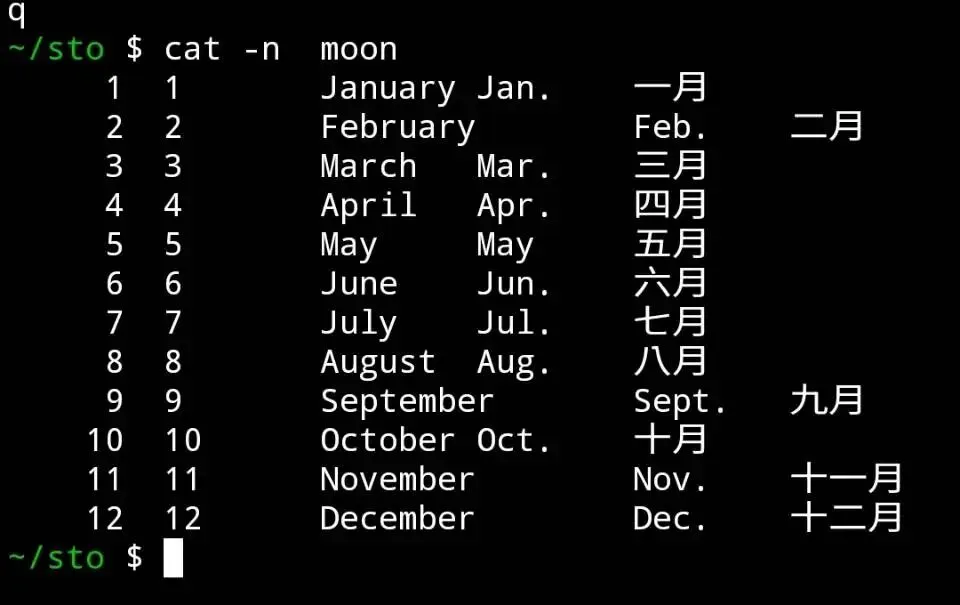
我們有一文件,要求找出月份,併將其前三個字母print做為簡寫。
用cat -n,帶行號顯示
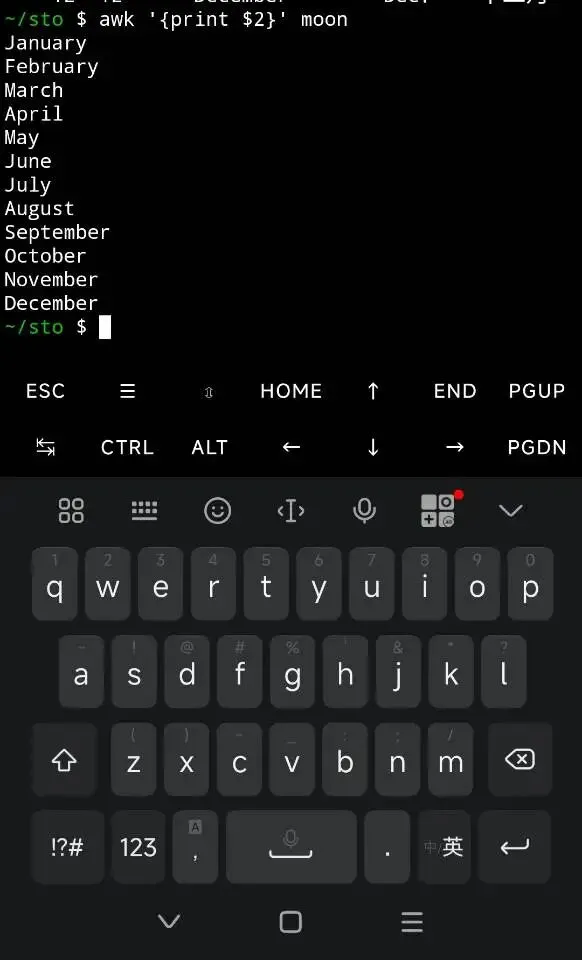
用awk找到位置
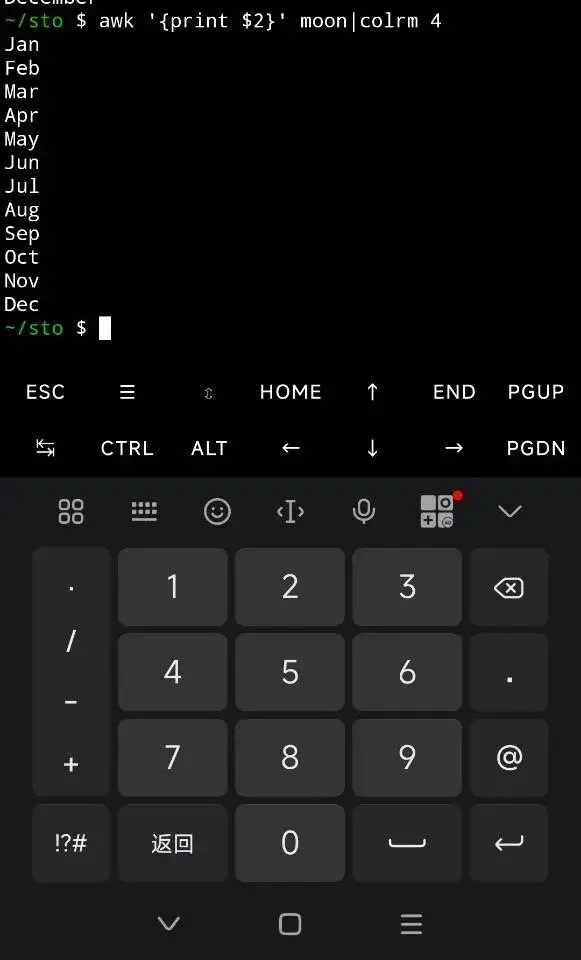
用colrm切,實現前三個字母print做為簡寫。
用fold加grep方法,fold把一行以3字符做分割(註意一個中文字符大過1字符)。
fold,對一行文本固定長度分割,最後一個是餘數。
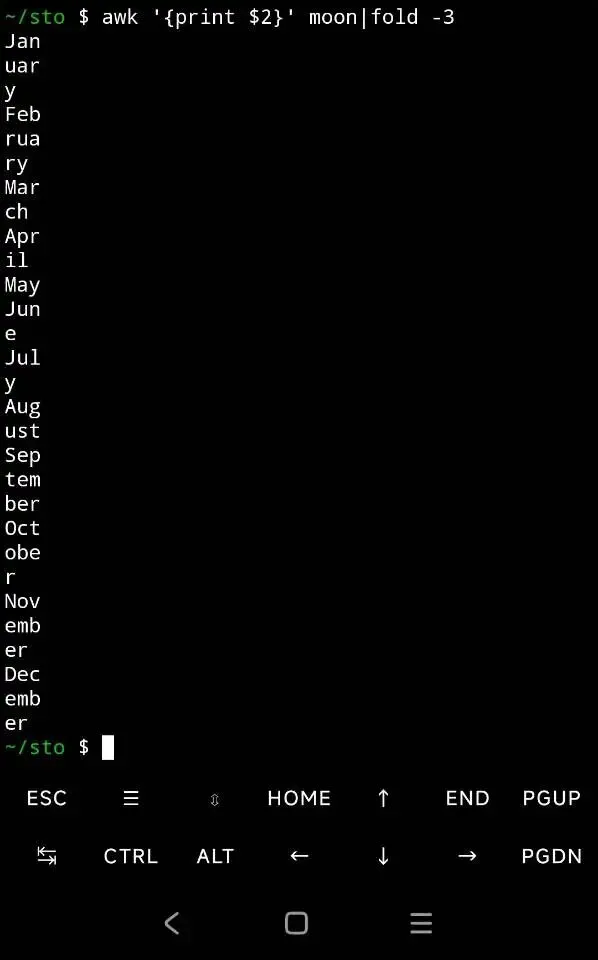
grep方法1,因為我們知道第一個是大寫的English,下面就可以可控操作了。
用upper
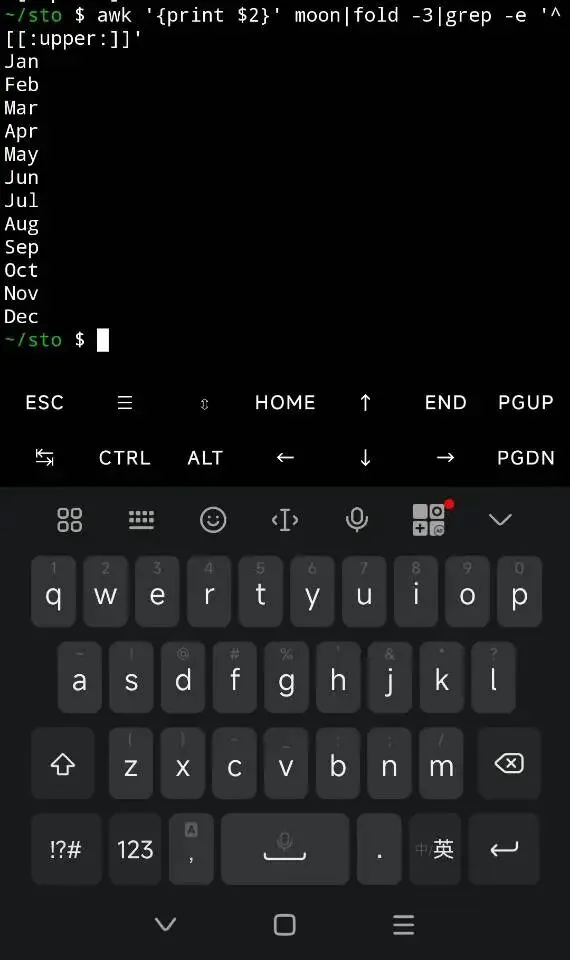
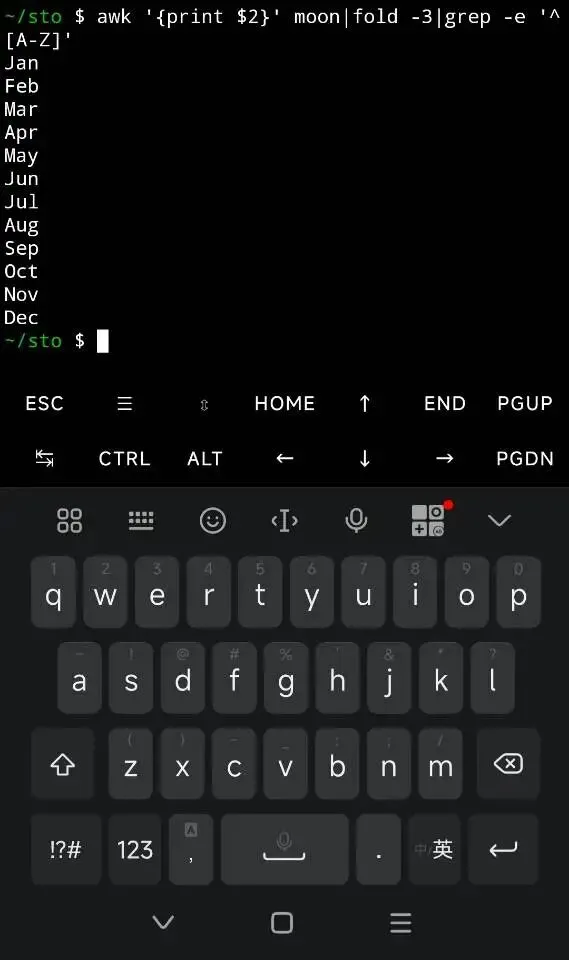
grep 方法2
用[A-Z]
當然實現三個字母print做為簡寫,用printf也可不用管道,一行完成。但printf substr不是每個人都理解的,沒有colrm好理解。
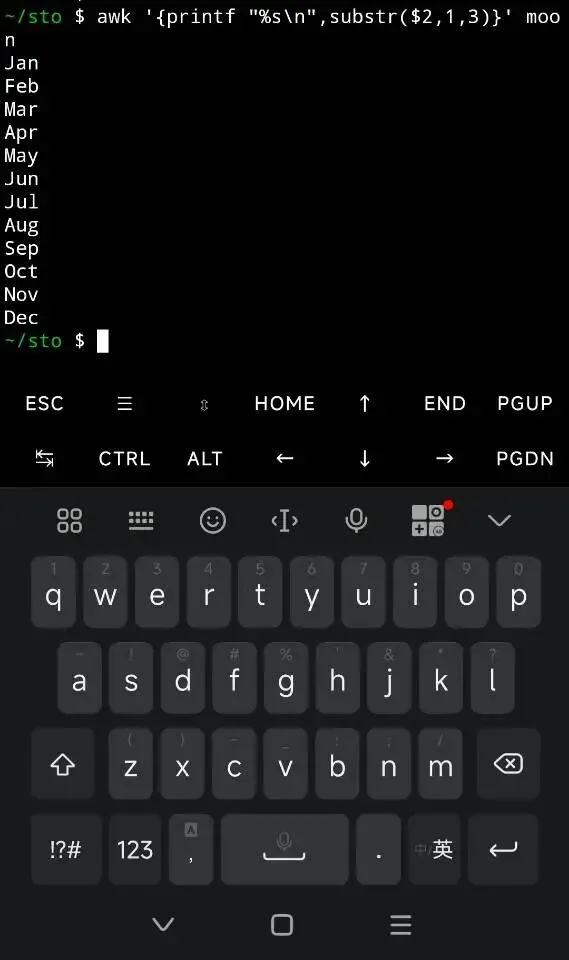
以上三個方法,colrm簡單,fold次之,awk最困難。
其實上面的操作也可以用head -c tail -c來實現
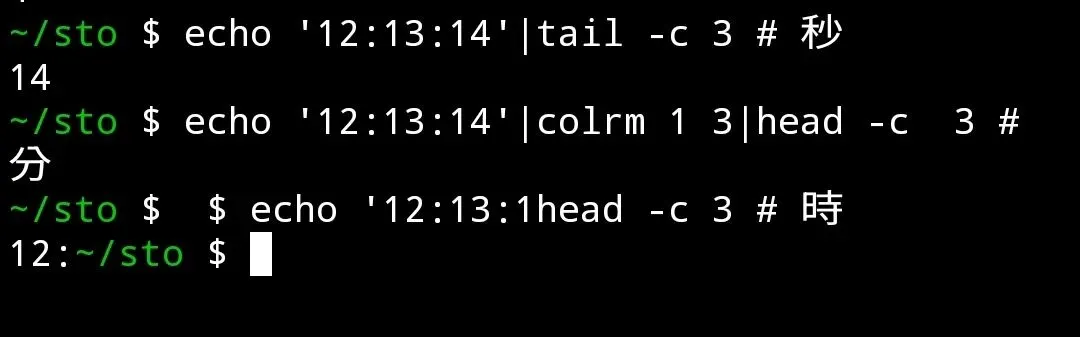
和awk head tail比較起來,用colrm操作可以不用離開主鍵盤。大大提高輸入效率。在大型攻擊當中,少個幾ms,就是天上地下。
colrm可以用在什麼地方呢,比如批量生成一些編號和文件名字,build一些錯誤的蜜罐信息。
colrm 配合 seq 是构建蜜罐信息的利器。利用 seq 生成序列号,再用 colrm 裁剪出符合真实格式特征的假 ID、假学号、假文件名。可以有效的進行反信息收集。
實現兵法上的,"虛之實也,實之虛也",讓對方知難而退,實現進攻級的防守。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
