Linux 输入函数避坑指南:scanf、gets、fgets 怎么选?
在 Linux 下写 C 程序,输入函数看起来是入门知识,但很多线上问题都栽在这里:测试时输入几行数据一切正常,换成真实终端、管道、配置文件或脚本喂数据,就开始出现空行、截断、越界、解析失败、死循环。
这类问题的根源通常不是“函数不会用”,而是把读取、解析、边界控制混在了一起。scanf、gets、fgets 的差别,真正影响的是三个工程问题:谁负责限制写入长度,谁负责处理缓冲区残留,谁负责判断输入是否可信。
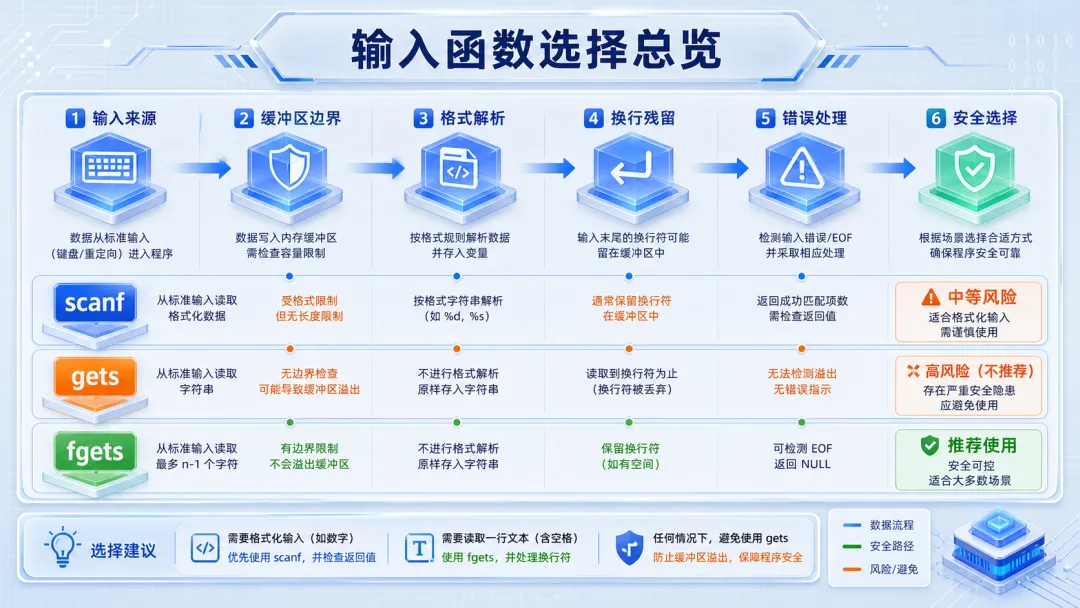
1 输入函数选择总览
1.1 先问清楚:你要读字段,还是读一行
scanf 的核心能力是“按格式解析字段”。比如从输入里取一个整数、一个短字符串,它很顺手。但它不是一个理想的“读一行”工具,因为空白字符、换行符、匹配失败都会参与控制流。
fgets 的核心能力是“按边界读一段文本”。它不会帮你理解字段含义,只负责把最多 n - 1 个字符放进缓冲区,并补上字符串结束符。后续怎么解析,是业务代码自己的事。
gets 则不应该再进入选项列表。它没有长度参数,不知道目标缓冲区有多大,输入一旦超过数组容量,就可能覆盖栈上的其他数据。现代 C 标准已经移除了它,编译器告警不是唠叨,是在替你挡事故。
1.2 选型的主线:边界优先于方便
工程代码里,输入函数的第一原则不是“少写几行”,而是“先把写入边界收敛住”。输入可能来自键盘,也可能来自重定向文件、管道、串口日志、自动化脚本。只要来源不是完全可控,就不能假设它一定短、一定规范、一定有换行。
一个实用判断是:
- 只读取少量格式化字段,并且能写清楚最大宽度:可以用 scanf,但必须检查返回值。 - 读取用户输入、命令行交互、配置行、协议行:优先用 fgets,再解析。 - 任何新代码:不要使用 gets。
2 边界与缓冲区:很多坑不是解析错,而是读入阶段已经失控
2.1 scanf 的危险常来自“看起来很短”
很多示例会写:
●●●char name[32];
// 危险:%s 不知道 name 只有 32 字节
scanf("%s", name);
这段代码的问题不在 scanf 本身,而在 %s 没有限制最大宽度。只要输入超过 31 个字符,就可能写出数组边界。正确写法至少要把字段宽度写进格式字符串:
●●●char name[32];
// 最多读入 31 个非空白字符,给 '\0' 留 1 个位置
if (scanf("%31s", name) != 1) {
// 输入不符合预期,不能继续使用 name
}
注意 %31s 里的 31 不是数组长度,而是最多读入的字符数。数组长度是 32,因为还要给字符串结束符留位置。
2.2 gets 的问题没有补丁
gets(buf) 没有参数告诉它 buf 有多大,所以调用者无法阻止越界。你可以在前面检查输入长度吗?不行,因为长度检查本身就需要先读入,而读入动作已经可能越界。
这就是 gets 与“用错的 scanf”最大的区别:scanf 可以通过宽度、返回值和格式控制降低风险;gets 的接口设计本身缺失边界信息,工程上没有可靠补救。
2.3 fgets 把边界放回调用者手里
fgets 的优势是明确:
●●●char line[128];
// 最多写入 sizeof(line) - 1 个字符,并自动补 '\0'
if (fgets(line, sizeof(line), stdin) == NULL) {
// EOF 或读取错误,不能继续解析 line
}
它还有一个容易被忽略的特点:如果读到了换行,换行符会保留在缓冲区里。这不是缺陷,而是信息。你可以据此判断是否读到完整一行,也可以在解析前主动去掉它。
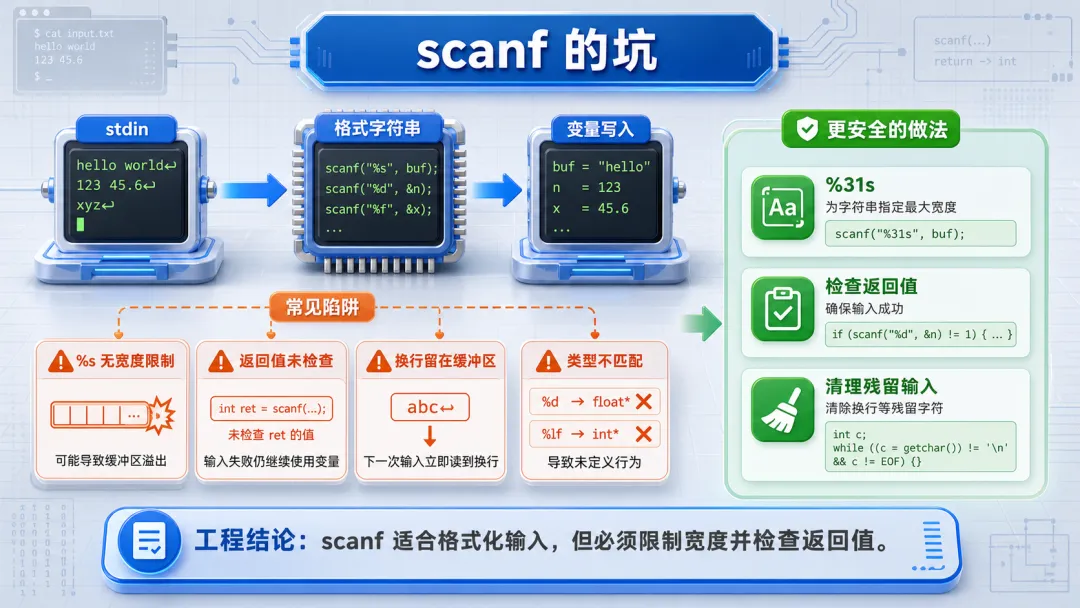
3 scanf 的坑:适合格式化输入,但别把它当万能读取器
3.1 返回值不检查,后面都是错的
scanf 的返回值表示成功匹配并赋值的项目数。很多异常路径都藏在这里:输入不是数字、字段缺失、遇到 EOF,都可能让返回值小于预期。
●●●int port;
// 必须确认成功读到了 1 个整数
if (scanf("%d", &port) != 1) {
// 输入不是合法整数,后续不能使用 port
}
如果不检查返回值,变量可能保留旧值或未初始化值。后续逻辑再严谨,也是在处理一个不可信的状态。
3.2 换行残留会影响下一次读取
scanf("%d", &n) 读取整数时,会把数字取走,但用户敲下的回车通常还留在输入缓冲区。下一次如果立刻用 fgets 读一行,就可能读到这个残留的 \n,表现为“怎么刚进来就读到空字符串”。
一种简单处理方式是,在切换到按行读取前清理掉当前行剩余内容:
●●●int ch;
// 丢弃当前行剩余字符,直到换行或 EOF
while ((ch = getchar()) != '\n' && ch != EOF) {
// 这里不做业务处理,只清理输入残留
}
这段代码看起来朴素,但它把“字段解析”和“行边界清理”分开了,调试时会清楚很多。
3.3 scanf 更适合小范围、强格式场景
scanf 不是不能用。它适合输入结构很简单、字段数量少、格式明确的场景,比如教学程序、临时调试工具、少量数字读取。问题出在把它用于复杂交互:用户可能输入空格,可能漏字段,可能复制一整行配置,也可能通过管道喂入大量数据。
一旦输入开始接近“文本协议”或“配置行”,就应该让 fgets 先把一行安全收进来,再使用 sscanf、strtol 等工具解析。这样失败路径更可控,错误提示也更容易写明白。
4 fgets 的工程写法:先读行,再解析
4.1 推荐模板
fgets 的常见模板可以分成五步:读一行、判断失败、去掉换行、识别超长行、解析字段。
●●●char line[128];
// 1. 先按边界读取一行
if (fgets(line, sizeof(line), stdin) == NULL) {
// EOF 或读取错误,直接走失败路径
}
// 2. 查找换行位置
size_t pos = strcspn(line, "\n");
if (line[pos] == '\n') {
// 3. 读到了完整一行,去掉换行
line[pos] = '\0';
} else {
// 4. 没读到换行,说明这一行可能太长,需要丢弃剩余输入
int ch;
while ((ch = getchar()) != '\n' && ch != EOF) {
// 清理超长行剩余内容
}
}
这段模板的价值不只是安全,还在于它把状态讲清楚了:读不到、读完整、被截断,是三种不同结果。工程代码最怕把这三种情况混成“反正有个字符串”。
4.2 解析不要急着写进业务变量
读到一行后,再解析字段。对数字输入,strtol 往往比直接 scanf("%d") 更利于错误处理,因为它能告诉你解析停在哪里。
●●●char *end = NULL;
long value;
// line 已经由 fgets 安全读入,并去掉换行
value = strtol(line, &end, 10);
if (end == line || *end != '\0') {
// 没有解析出数字,或后面还有非法字符
} else {
// value 是可信的解析结果
}
如果一行里有多个简单字段,也可以用 sscanf,但仍然要检查返回值:
●●●int id;
char name[32];
// name 仍然要限制宽度,避免解析阶段越界
if (sscanf(line, "%d %31s", &id, name) != 2) {
// 字段数量不足或格式不匹配
}
4.3 交互程序也需要处理 EOF
很多命令行程序只按“用户会一直输入”的方式写,结果一旦接到管道、文件重定向,或者用户按下 Ctrl+D,就进入奇怪状态。fgets 返回 NULL 时,不要立刻当成空字符串处理,而要明确退出或上报错误。
这也是推荐 fgets 的原因之一:它让 EOF、错误、空行这几件事可以被清楚地区分。空行是读到了 "\n",EOF 是根本没有读到新数据,二者在交互体验和业务含义上完全不同。
5 最后给一个选型表
5.1 scanf 怎么用才算克制
可以使用 scanf 的前提是:格式简单、字段少、宽度明确、返回值检查完整。尤其是字符串字段,必须写宽度;数字字段,必须检查返回值;混用 fgets 时,必须意识到换行残留。
5.2 gets 为什么应该彻底删除
gets 最大的问题不是“不推荐”,而是它无法表达安全边界。任何需要上线、交付、给别人复用的代码,都不应该保留它。看到旧代码里有 gets,优先替换成 fgets,再补上换行处理和超长行处理。
5.3 fgets 为什么更适合工程默认值
fgets 不替你解析业务,但它先解决了最关键的写入边界。把输入行读到一个受控缓冲区,再用专门的解析逻辑处理字段,代码会稍微多几行,却换来更稳定的失败路径、更清楚的日志和更少的隐性越界风险。
总结一句话:scanf 适合小范围格式化输入,gets 不要再用,fgets 更适合作为工程代码的默认入口。输入函数的选择,本质上是在决定风险由谁来兜底。让边界先落地,后面的解析才有可靠性可谈。