由于借助 AI 工具学习编程已经变得非常容易了,因此之后的课程就不再默认进行视频讲解了,如果特别需要视频讲解也可以联系李老师预约讲解~讲义材料学习过程中遇到的问题也可以及时与李老师联系。
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/4f17013021be4a2d88a310ad6fbceb98
指标来源
该碳排放测算方法来自吴超鹏等(2025)发表于《中国工业经济》的论文《高管股权激励与企业碳排放:绿色发展背景下的企业激励机制研究》。该论文采用排放因子法,基于全国税收调查数据(税调)中企业层面的能源消费信息来估算上市公司的碳排放量。
论文原文中对碳排放测算方法的描述(第144页脚注②)如下:
本文的碳排放量指标参考现有文献(Lee et al., 2022; 周泽将等, 2022)的做法,根据全国税收调查数据中的企业用电量、煤炭、石油和天然气的消费量数据,利用排放系数法计算得到。
核心思路是:上市公司自身的能源消费数据通常不可直接获取,但通过将上市公司及其子公司与税调企业进行名称匹配,可以间接获得这些企业的能源消费数据,再利用各能源品种的碳排放系数计算出碳排放量。
计算过程
排放系数
论文中使用的各能源品种碳排放系数如下:
论文中提到的 “每兆瓦时电力的碳排放因子为 7.5 吨” 应该是笔误,10兆瓦时 = 1万kwh,按照《节能低碳技术推广管理暂行办法》里面的描述 0.75kgCO2/kWh = 7.5吨CO2/万千瓦时。
碳排放量的计算公式为:
其中 E 为各能源的消费量,α 为对应的碳排放系数。
数据匹配与汇总流程
整个测算流程分为以下几个步骤:
- 读取税调企业能源消费数据(2007~2020年各税调企业电力、煤炭、燃油、天然气消费量面板数据)
- 计算各税调企业的碳排放量(消费量 × 碳排放系数)
- 对税调企业层面的碳排放进行缩尾处理(1%和99%分位数)
- 计算上市公司碳排放(母公司层面):将税调与上市公司匹配结果合并,按上市公司-年份汇总
- 计算全资子公司碳排放:筛选持股比例为100%的全资子公司,与税调匹配后汇总
关于全资子公司的筛选
论文中特别指出,对于子公司的碳排放,仅保留持股比例为100%的全资子公司。总持股比例的计算方式为:
仅保留总持股比例等于100%的子公司,这是为了确保对子公司碳排放的归因准确性。
变量说明
最终生成的数据包含以下变量:
total_carbon_emission_ton:总碳排放量(母公司 + 全资子公司),单位:吨CO2ln_carbon_emission:总碳排放量加1取自然对数asinh_carbon_emission:总碳排放量的反双曲正弦变换total_carbon_emission_ton_winsor:缩尾处理后的总碳排放量parent_carbon_emission_ton:母公司层面碳排放量sub_carbon_emission_ton:全资子公司碳排放量
使用 reticulate 创建与管理 Python 虚拟环境
在 R 中通过 reticulate 包来调用 Python,最好的实践是为项目创建一个专属的 Python 虚拟环境,将所需依赖隔离到独立空间,避免与系统 Python(如 Anaconda)发生版本冲突。
重要说明(避免"已初始化"报错):reticulate 在 R 会话中只能绑定一次 Python——一旦某个 {python} 代码块运行,Python 解释器就被锁定,之后再调用 use_virtualenv() 会报错:
ERROR: The requested version of Python cannot be used, as another version has already been initialized.因此,虚拟环境的激活必须在所有 {python} 代码块之前完成。本文档的解决方案是在 setup chunk 中通过 Sys.setenv(RETICULATE_PYTHON = ...) 提前锁定 Python 路径,这是 reticulate 选取 Python 的最高优先级入口。
安装 reticulate(仅首次)
options(repos = c(CRAN = "https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))if (!requireNamespace("reticulate", quietly = TRUE)) { install.packages("reticulate") message("reticulate 安装完成!") message("reticulate 已安装,版本:", packageVersion("reticulate"))虚拟环境初始化原理(已在 setup chunk 中完成)
本文档的 setup chunk(隐藏运行)包含如下逻辑:
.venv_python <- virtualenv_python(.venv_name)if(!file.exists(.venv_python)){ virtualenv_create(.venv_name) .venv_python <- virtualenv_python(.venv_name)# 通过环境变量抢先锁定 Python(优先级最高,早于任何 {python} chunk)Sys.setenv(RETICULATE_PYTHON = .venv_python)use_virtualenv(.venv_name, required =TRUE)这样做的关键在于:knitr 在处理第一个 {python} chunk 时,reticulate 已经通过 RETICULATE_PYTHON 环境变量知道要使用 .venv,不会再去碰 Anaconda。
在虚拟环境中安装 Python 包(仅首次)
py_pkgs <- c("pandas", "numpy", "pyreadstat")installed <- py_list_packages(".venv")$packageneed_install <- setdiff(py_pkgs, installed)if (length(need_install) > 0) { virtualenv_install(".venv", packages = need_install) message("已安装缺失的包:", paste(need_install, collapse = ", ")) message("所有 Python 包已就绪,无需安装")验证激活状态
计算代码
下面使用 Python 完成整个测算过程。需要安装 pandas 和 numpy 两个包。
第一步:读取数据文件
energy_data = pd.read_stata("2007~2020年各税调企业电力、煤炭、燃油、天然气消费量面板数据.dta"match_tax_listed = pd.read_stata("2007~2020年税调与上市公司匹配结果.dta"match_tax_subsidiary = pd.read_stata("2007~2020年税调数据与上市公司子公司数据匹配结果.dta"第二步:定义排放系数
# - 每兆瓦时电力的碳排放因子为 7.5 吨 = 7.5 吨CO2/万千瓦时# - 每吨煤炭的碳排放因子为 1.89 吨 = 1.89 吨CO2/吨煤炭# - 每吨油的碳排放因子为 3.02 吨 = 3.02 吨CO2/吨油# - 每万标立方米天然气的碳排放因子为 21.68 吨 = 21.68 吨CO2/万标立方米ELECTRICITY_EMISSION_FACTOR =7.5# 电力:7.5 吨CO2/万千瓦时COAL_EMISSION_FACTOR =1.89# 煤炭:1.89 吨CO2/吨OIL_EMISSION_FACTOR =3.02# 石油:3.02 吨CO2/吨GAS_EMISSION_FACTOR =21.68# 天然气:21.68 吨CO2/万标立方米第三步:计算各税调企业的碳排放量
第四步:缩尾处理
# 对税调企业层面的碳排放进行缩尾处理(1%和99%分位数)p1 = carbon_emission["total_co2_ton"].quantile(0.01)p99 = carbon_emission["total_co2_ton"].quantile(0.99)carbon_emission["total_co2_ton_winsor"] = carbon_emission["total_co2_ton"].clip(print("缩尾处理后碳排放统计摘要(吨CO2):")print(carbon_emission["total_co2_ton_winsor"].describe())第五步:计算上市公司碳排放(母公司层面)
print(f"母公司层面观测值数量:{len(listed_company_carbon)}")第六步:筛选全资子公司并计算碳排放
match_tax_subsidiary["直接持股"] = match_tax_subsidiary["直接持股"].fillna(0)match_tax_subsidiary["间接持股"] = match_tax_subsidiary["间接持股"].fillna(0)match_tax_subsidiary["总持股"] = ( match_tax_subsidiary["直接持股"] + match_tax_subsidiary["间接持股"]match_tax_subsidiary_full = match_tax_subsidiary[ match_tax_subsidiary["总持股"] == 100print(f"筛选前子公司观测值数量:{len(match_tax_subsidiary)}")print(f"筛选后全资子公司观测值数量:{len(match_tax_subsidiary_full)}")第七步:合并母公司和子公司碳排放数据
combined_carbon = listed_company_carbon.merge( subsidiary_company_carbon,# 只有子公司没有母公司的行,用证券代码填充股票代码combined_carbon["股票代码"] = combined_carbon["股票代码"].fillna(combined_carbon["证券代码"])combined_carbon["carbon_emission_ton"] = combined_carbon["carbon_emission_ton"].fillna(0)combined_carbon["carbon_emission_ton_winsor"] = combined_carbon["carbon_emission_ton_winsor"].fillna(0)combined_carbon["subsidiary_carbon_emission_ton"] = combined_carbon["subsidiary_carbon_emission_ton"].fillna(0)combined_carbon["subsidiary_carbon_emission_ton_winsor"] = combined_carbon["subsidiary_carbon_emission_ton_winsor"].fillna(0)combined_carbon["parent_carbon_emission_ton"] = combined_carbon["carbon_emission_ton"]combined_carbon["parent_carbon_emission_ton_winsor"] = combined_carbon["carbon_emission_ton_winsor"]combined_carbon["sub_carbon_emission_ton"] = combined_carbon["subsidiary_carbon_emission_ton"]combined_carbon["sub_carbon_emission_ton_winsor"] = combined_carbon["subsidiary_carbon_emission_ton_winsor"]combined_carbon["total_carbon_emission_ton"] = ( combined_carbon["parent_carbon_emission_ton"] + combined_carbon["sub_carbon_emission_ton"]combined_carbon["total_carbon_emission_ton_winsor"] = ( combined_carbon["parent_carbon_emission_ton_winsor"] + combined_carbon["sub_carbon_emission_ton_winsor"]combined_carbon["ln_carbon_emission"] = np.log( combined_carbon["total_carbon_emission_ton"] + 1combined_carbon["ln_carbon_emission_winsor"] = np.log( combined_carbon["total_carbon_emission_ton_winsor"] + 1第八步:查看结果
print(f"上市公司数量:{combined_carbon['股票代码'].nunique()}")print(f"总观测值:{len(combined_carbon)}")print("\n【碳排放量统计摘要】(吨CO2):")print(combined_carbon["total_carbon_emission_ton"].describe())print("\n【缩尾处理后碳排放量统计摘要】(吨CO2):")print(combined_carbon["total_carbon_emission_ton_winsor"].describe())print("\n【对数碳排放量(ln(Carbon Emission + 1))统计摘要】:")print(combined_carbon["ln_carbon_emission"].describe())第九步:各年份样本分布
平均碳排放=("total_carbon_emission_ton_winsor", "mean"), 中位数碳排放=("total_carbon_emission_ton_winsor", "median"),第十步:添加变量标签并保存结果
# 为各变量添加中文标签并保存为 Stata 格式(使用 pyreadstat 支持中文变量名)"2007~2020年上市公司碳排放数据.dta","total_carbon_emission_ton": "总碳排放量:母公司+全资子公司(吨CO2)","ln_carbon_emission": "总碳排放量加1取自然对数","asinh_carbon_emission": "总碳排放量的反双曲正弦变换","total_carbon_emission_ton_winsor": "缩尾处理后的总碳排放量(吨CO2)","ln_carbon_emission_winsor": "缩尾后总碳排放量加1取自然对数","asinh_carbon_emission_winsor": "缩尾后总碳排放量的反双曲正弦变换","parent_carbon_emission_ton": "母公司层面碳排放量(吨CO2)","carbon_emission_ton": "税调匹配的母公司碳排放量(吨CO2)","sub_carbon_emission_ton": "全资子公司碳排放量(吨CO2)","subsidiary_carbon_emission_ton": "税调匹配的全资子公司碳排放量(吨CO2)","electricity_consumption": "母公司电力消费量(万千瓦时)","coal_consumption": "母公司煤炭消费量(吨)","oil_consumption": "母公司石油消费量(吨)","gas_consumption": "母公司天然气消费量(万标立方米)","sub_elec_cons": "全资子公司电力消费量(万千瓦时)","sub_coal_cons": "全资子公司煤炭消费量(吨)","sub_oil_cons": "全资子公司石油消费量(吨)","sub_gas_cons": "全资子公司天然气消费量(万标立方米)","n_matched_firms": "母公司匹配到的税调企业数量","n_matched_subsidiaries": "匹配到的全资子公司数量",print("数据已保存为 2007~2020年上市公司碳排放数据.dta")如何参加课程?
购买 RStata 名师讲堂会员即可参加该课程啦(之前的和未来的都可以参加)!
价格:2800/年 或者 4800/长期
购买会员可以从这里下单:https://rstata.duanshu.com/#/card/list/
名师讲堂会员权益:
- 参加平台上的其他 R 语言和 Stata 的课程;
- 以会员折扣价购买我们分享的数据资料(10 元/份);
* 如果发票可添加小编微信 r_stata2 (RStata 李老师)开具。如需数据资料,购买后可添加小编微信免费领取数据折扣卡。
更多关于 RStata 会员的更多信息可添加微信号 r_stata2 咨询:

课程主页(点击文末的阅读原文即可跳转):https://rstata.duanshu.com/#/brief/course/4f17013021be4a2d88a310ad6fbceb98








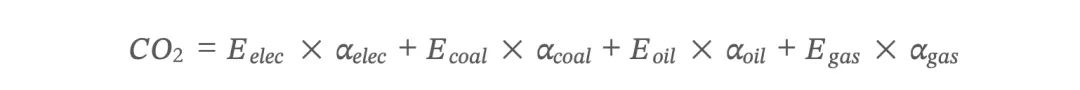

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
