你是不是也好奇那些能自主完成复杂任务的 AI 智能体是怎么实现的?市面上像 LangChain、CrewAI 这类框架虽然好用,但层层封装的逻辑总会让人摸不清背后的原理。今天就抛开这些框架,用最基础的 Python 代码和直接的 API 调用,手把手教你搭建一个稳定、能自我纠错的 AI 智能体,真正搞懂 AI 智能体的核心逻辑!
先回顾一个简单的定义:智能体(Agent) 就是配备了工具(Tools) 和循环逻辑(Loop) 的大语言模型(LLM)。
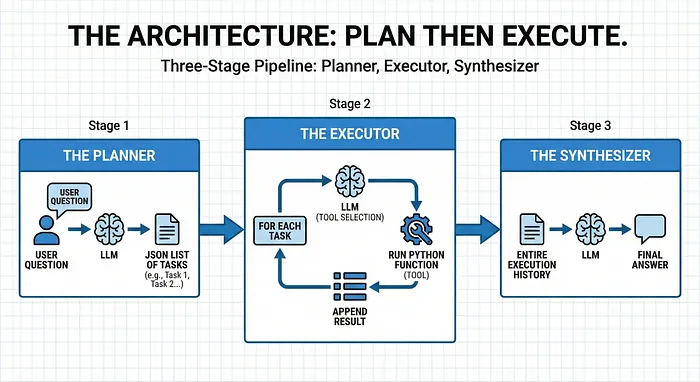
这次我们要搭建的是「结构化规划 - 执行智能体」,它属于 ReAct 架构体系,但对复杂工作流的适配性更强 —— 因为它会先把用户的查询拆解成基于 JSON 的任务列表,再执行任务,而非一步一动的即时反应。
(如果你本来是冲着 ReAct 智能体来的也别急,下篇内容我们会专门从零实现完整的 ReAct 智能体。不过对于刚接触智能体的朋友来说,先掌握「规划 - 执行」模式更合适,它的结构化和可预测性,是打造高精度、落地级 AI 系统的基础,也是真正吃透 AI 智能体的关键。)
动手能力: 定义 Python 函数,并为其编写适配 LLM 的 JSON 模式,让 AI 能「看懂」并调用这些函数;
规划能力: 调用擅长推理的 LLM,把复杂问题拆解成清晰的任务列表;
执行能力: 逐个处理任务,匹配对应的工具完成操作;
容错能力: 搭建 3 阶段重试循环,应对 JSON 格式不规范这类非确定性问题。
和经典的 ReAct 模式(边思考边行动)不同,我们的智能体遵循更有条理的三段式流程:
规划器(Planner): LLM 接收用户问题后,返回一个 JSON 格式的任务列表;
执行器(Executor): 针对每个任务,LLM 选择合适的工具,运行对应的 Python 函数,并记录结果;
合成器(Synthesizer): 最后,LLM 结合所有执行记录,生成通俗易懂的最终答案。
理解了这个流程,就有了搭建的方向。但要让这个蓝图落地,首先得搭建起 AI 和现实世界交互的桥梁 —— 也就是智能体的「手」。
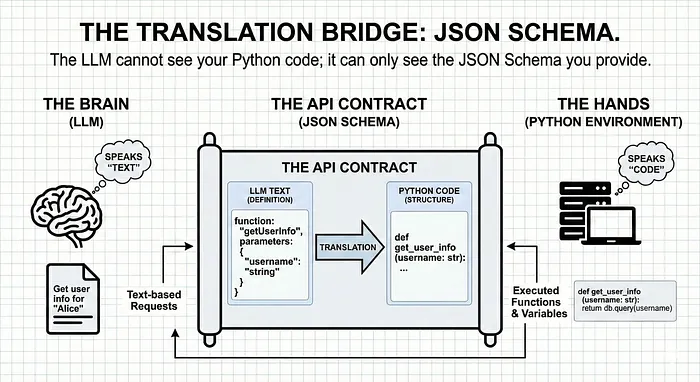
智能体要执行规划,得先知道自己能做什么。这一步的核心就是定义「工具」,相当于给 Python 环境和 LLM 之间制定一份「API 契约」。
LLM 看不到我们写的 Python 代码,只能识别我们提供的 JSON 模式,所以每个工具都包含两部分:
简单说,Python 环境说「代码语言」(函数、变量),LLM 说「文本语言」,JSON 模式就是连接两者的「翻译手册」。我们要做的,就是给智能体的「手」制定这份手册,明确每个工具的功能、所需参数,确保规划器说「查火星的质量」时,执行器能精准触发对应的函数。
举个例子:
# 1. 模式(LLM能识别的内容)tools_schema = [ { "type": "function", "name": "get_planet_mass", "description": "获取指定行星的质量", "parameters": { "type": "object", "properties": { "planet": {"type": "string", "description": "行星名称(例如:地球)"}, }, "required": ["planet"], }, }, # 可添加其他工具,比如计算工具'calculate']# 2. 逻辑(Python实际执行的代码)def get_planet_mass(planet_dict): planet = planet_dict["planet"].lower().strip() masses = {"earth": "5.972e24 千克", "mars": "6.39e23 千克", "jupiter": "1.898e27 千克"} return masses.get(planet, "未知行星")
有了「手」,接下来就要打造让「手」有序行动的「大脑」—— 规划器。
规划器的核心不是直接干活,而是把用户的复杂问题拆解成结构化、可执行的 JSON 任务列表。我们会给 LLM 一个「系统提示词」,相当于给它定规则,强制它输出规范的 JSON,而非口语化的回答。
为什么非要用 JSON?因为结构化的任务列表能让执行器不用「猜」下一步该做什么,只需按列表逐个执行,流程更清晰。
def __plan_tasks(self, user_prompt: str)-> json: '''让LLM规划要执行的任务''' planner_system_prompt = ( "你是一个专业的任务规划智能体。" "你的工作是把用户的复杂问题拆解成按顺序排列的简单任务。" "返回一个JSON对象,仅包含一个键:" " - 'tasks': list[string] # 存储任务列表的数组" ) action_plan = self.call_llm(planner_system_prompt, user_prompt) return json.loads(action_plan.output_text)
但光有规划还不够,得把规划落地 —— 这就需要执行器来匹配工具、完成操作。
执行器是智能体的「干活主力」。它会遍历规划器生成的任务列表,为每个任务匹配合适的工具,执行对应的 Python 函数,还会加入「重试逻辑」—— 就算 LLM 输出的格式出错,智能体也能自我纠正,而不是直接崩溃。
简单来说:对规划里的每个任务,先问 LLM「该用哪个工具?」,再执行工具函数,最后把结果记录到「执行计划」里。这样做的好处是,智能体能「记住」已完成的操作,后续任务可以基于前面的结果开展。
def __plan_tools(self, action_plan, tools): execution_plan = [] for task in action_plan["tasks"]: # 1. 询问LLM:这个任务该用哪个工具? response = self.call_llm(execution_system_prompt, user_prompt) # 2. 把LLM选中的工具名称映射到实际的Python函数 function_to_call = self.available_tools_dict[response["function"]] response["result"] = function_to_call(*kwargs) return execution_plan.append(response)
要让机器和机器顺畅沟通,提示词的设计很关键。我们会强制 LLM 返回包含指定键的 JSON 对象,还会明确告诉它「如果没有匹配的工具,就写 None」,避免智能体在没有合适工具时乱操作。
execution_system_prompt = ( "你是一个专业的工具匹配智能体。" "你的工作是为给定任务匹配系统中合适的工具。" "你会收到用户的任务和可用工具列表," "如果没有工具适配该任务,就写None。" "返回一个JSON对象,包含以下键:" " - 'id': int # 识别任务的唯一编号" " - 'task': {task} # 任务内容" " - 'function': string # 工具名称" " - 'properties': list # 执行函数所需的参数" " - 'dependencies': list # 依赖的其他任务编号(需用到其执行结果)")user_prompt = (f"我有一个任务需要完成:{task}" f"可使用的工具列表:{tools}" "请告诉我完成这个任务该用的正确工具" f"完整任务列表:{action_plan}" f"已完成的执行记录:{execution_plan}(需考虑依赖任务的结果)" )
有了执行结果,还需要把这些冰冷的数据转化成用户能看懂的答案 —— 这就是合成器的作用。
合成器就像智能体的「最后一道把关」,它会整合三类信息:
用户的原始问题;
规划器制定的任务列表;
执行器输出的工具运行结果(比如行星质量、计算数值等)。
它不会直接抛出「5.972e24 千克」这种原始数据,而是把这些信息梳理成自然、易懂的回答,让数据变得有意义。
def __synthesize_answer(self, user_prompt, execution_results): synthesis_prompt = ( "你是一个贴心的助手。你会收到用户的问题," "以及一系列工具的执行结果。" "你的目标是基于这些结果,给出最终、简洁的回答。" ) # 把所有信息整合为LLM能理解的「上下文」 context = f"用户问题:{user_prompt}\n执行结果:{execution_results}" return self.call_llm(synthesis_prompt, context)
把规划、执行、合成拆分开,让这个智能体比普通聊天机器人更抗造:
可追溯: 如果答案出错,能查规划器是不是逻辑有问题,或执行器是不是工具调用失败;
省算力: 不用让 LLM 反复读取整段对话,只需给它对应任务的具体上下文;
易理解: 最终的合成回答会把复杂的 JSON 流程藏起来,用户看到的是通俗易懂的结果。
玩过原型后会发现,LLM 其实很「任性」—— 哪怕是 GPT-4,偶尔也会输出格式错误的 JSON,或编造不存在的参数。实验室里这只是小 bug,但实际应用中可能导致系统崩溃。分享 3 个让智能体「落地可用」的小技巧:
别指望 LLM 能一直输出正确的 JSON,用 Pydantic 这类库在代码层面做「契约校验」吧。把工具定义成 Pydantic 模型,能在调用函数前自动校验 LLM 的输出,避免无效数据流入。
from pydantic import BaseModel, ValidationErrorclass PlanetQuery(BaseModel): planet: str include_moons: bool = False # 默认值让程序更健壮# 如果LLM传了"world"而非"planet",Pydantic会立刻检测到错误
我们的代码里不是「赌」一次成功,而是做了失败预案 —— 加了重试循环和错误捕获。如果 JSON 解析失败,智能体不会直接崩,而是重新尝试。
如果校验失败,还能把错误信息反馈给 LLM:「你给的格式不对,错误信息是 [ValidationError],请重新输出」。
max_retries = 3attempts = 0while attempts < max_retries and not success: try: response = self.call_llm(execution_system_prompt, user_prompt) response_json = json.loads(response.output_text) success = True except (json.JSONDecodeError, KeyError): attempts += 1
这个「3 次重试」的设计,能大幅提升结构化工作流的可靠性,让智能体从「实验室玩具」变成「能用的工具」。
实际应用中,「不知道它为啥这么做」是绝对不行的。要记录智能体的每一次「思考、行动、观察」,形成「执行轨迹」。这样就算出现问题(比如触发了高风险操作),也能追溯清楚决策过程。
我们举的例子是查行星质量、做简单计算,但这套架构完全能适配复杂的实际场景 —— 核心逻辑不变,只需替换智能体的「工具」就行:
数据库场景: 把get_planet_mass()换成query_sql_database(),规划器决定要查询的列,执行器处理数据库连接和数据读取;
金融分析场景: 把calculate()换成analyze_market_trends(ticker),智能体能拉取实时 API 数据、分析新闻情绪,输出风险评分;
库存管理场景: 用update_inventory_levels()这类工具,智能体不只是聊库存,还能在订单确认后自动更新仓库数据。
值得一提的是,从零搭建的好处是能掌控「安全层」—— 比如在执行器里加权限校验,确保 LLM 不会调用未授权的工具,这在实际应用中特别重要。
「规划 - 执行」模式虽然稳定,但有个短板:规划是静态的。如果第一个任务的结果让后续任务变得毫无意义,智能体还是会机械地执行下去。
这种模式适合可预测的任务,但缺少 ReAct 循环的「动态反馈」—— 比如任务 1 的结果让任务 2 无法完成,ReAct 智能体能及时调整,而纯「规划 - 执行」的智能体可能还会硬着头皮试。
下篇内容里,我们会聊聊「管理者 + 执行者」模式:先用规划器启动流程,再让「管理者智能体」根据「执行者智能体」的反馈,实时调整规划,兼顾结构化和灵活性。
从零搭建 AI 智能体,看似复杂,实则核心就是「规划 - 执行 - 合成」的逻辑,再加上灵活的工具适配和容错设计。你有没有想过让 AI 智能体帮你完成的任务?评论区聊聊

 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
