完整代码获取:回复“ 箱线图01”即可获得通道
各位科研朋友们,大家好,感谢大家关注与支持“八宝粥的科研日记”。
今天我们继续拆解一类非常适合论文结果展示的可视化工具,散点箱线图+显著性检验图。它不仅能够展示不同实验组、处理组或样本组之间的数据分布差异,还能够自动完成统计检验,并在图中标注显著性字母,帮助我们把看起来有差异的数据进一步转化为统计学上是否真的有差异的可视化图谱。
在材料性能、生物医学、农业生态、环境科学、交通行为分析等研究中,我们经常会面对多组数据比较。例如不同处理条件下的强度、不同药物干预后的指标、不同天气条件下的交通参数,或者不同样地中的生态变量。此时,单纯画柱状图往往会遮蔽数据的真实离散程度,而箱线图则能够更加完整地呈现中位数、四分位范围、极值范围以及样本分布。
一、代码简介
这份代码的核心价值在于:它不是简单地把 Excel 数据画成箱线图,而是将数据读取、缺失值清理、分组识别、Welch’s t-test、Bonferroni 多重校正、显著性字母分配、箱线图绘制、原始散点叠加和 PDF/PNG 高清导出整合到同一个脚本中。
也就是说,大家只需要准备一份 Excel 表格,第一列放分组名称,第二列放需要比较的数值变量,代码就可以自动识别每一个分组,并完成从统计分析到图表输出的完整流程。对于需要频繁绘制论文图、毕业论文图、实验结果图的同学来说,这种自动化脚本可以显著减少重复劳动。
传统的分组比较图经常存在两个问题:第一,只展示均值或柱状高度,忽略了数据内部的离散程度;第二,显著性标注依赖人工计算和手动添加,既容易出错,也不方便批量处理。相比之下,这段代码将箱线图与散点图结合起来,既保留了统计摘要,又展示了每一个原始数据点,从视觉上更加透明,也更符合当前论文图表对数据完整性的要求。
二、这张图里包含的关键信息
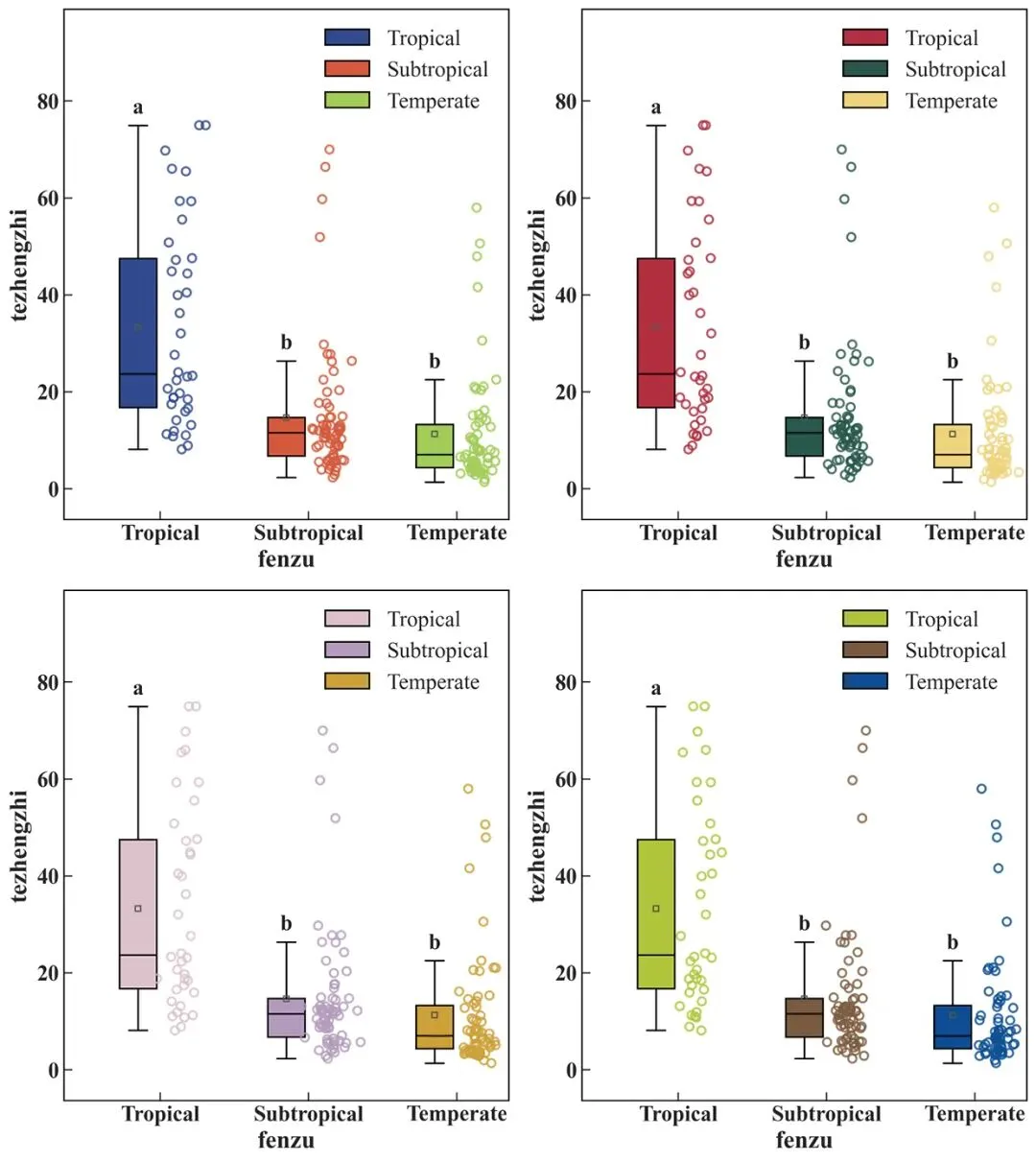
彩色箱体:每一个箱体代表一个分组的数据分布,箱体中间的横线为中位数,箱体范围反映四分位区间,须线展示主要数据范围。不同分组使用不同颜色,便于读者快速区分。
空心散点:每一个散点对应一个真实样本值。代码加入了轻微水平抖动,避免多个点完全重叠。空心散点能够让读者直观看到样本数量、离散程度和潜在异常趋势。
均值标记:箱体中加入了小方形均值点,用于辅助判断均值和中位数之间是否存在偏离。如果均值明显偏离中位数,往往提示数据可能存在偏态分布。
显著性字母:代码会根据组间统计检验结果自动生成 a、b、ab 等字母。拥有相同字母的组之间通常表示差异不显著;字母完全不同的组之间则提示差异具有统计学意义。
高清输出:脚本会同时保存 PDF 和 PNG 文件。PDF 适合后续排版、投稿和矢量编辑,PNG 适合汇报、公众号展示和普通文档插图。
三、代码背后的统计逻辑
这段代码使用的是 Welch’s t-test,而不是最普通的独立样本 t 检验。Welch’s t-test 的优点在于不强制假设各组方差完全相等,因此在真实实验数据方差不齐、样本量不完全一致的情况下更加稳健。
在多组比较中,如果我们直接两两进行 t 检验,随着比较次数增加,假阳性风险也会升高。代码中加入 Bonferroni 校正,就是为了控制多重比较带来的错误发现概率。虽然 Bonferroni 方法相对保守,但对于论文图表中的初步组间差异展示而言,它是一种容易解释、逻辑清楚、审稿人也比较容易接受的校正方式。
显著性字母的意义并不是给图表增加装饰,而是把复杂的两两比较结果压缩成一套直观的分组标记。例如某一组标注为 a,另一组标注为 b,说明两者之间存在显著差异;如果某组标注为 ab,则说明它可能同时与 a 组和 b 组没有显著差异。这样读者不需要阅读大段统计表,也能够快速理解组间关系。
四、代码运行方法
1. 示范数据准备:准备一份 Excel 文件,后缀为 .xlsx。第一列放分组变量,例如示范数据里面的 Control、Model、Treatment,或者不同材料处理工艺;第二列放数值变量,例如强度、含量、表达量、速度、误差率等。第一行建议写清楚列名,因为代码会自动读取第一列作为横轴分组名称,第二列作为纵轴指标名称。
2. 文件放置方式:将 Excel 数据文件和 Python 代码文件放在同一个文件夹中。如果不放在同一个文件夹,也可以在代码的 input_excel_path 中填写完整路径。
3. 安装运行库:运行前需要安装 pandas、numpy、matplotlib、seaborn、scipy 和 openpyxl。openpyxl 用于读取 .xlsx 文件,不安装时 pd.read_excel 可能会报错。
4. 修改输入输出名称:在代码开头找到 input_excel_path、output_pdf_path 和 output_png_path。将 input_excel_path 改成自己的 Excel 文件名,将输出文件名改成自己想要保存的图片名称。
5. 运行代码:在 PyCharm、VS Code、Jupyter 或命令行中运行脚本。运行成功后,程序会在当前文件夹中生成 PDF 和 PNG 两个结果文件,并在控制台输出每个分组对应的显著性字母。
五、需要安装的库
如果使用 pip,可以直接在命令行中输入以下命令:
pip install pandas numpy matplotlib seaborn scipy openpyxl
六、使用时需要注意什么?
第一,代码默认使用 Times New Roman 和 SimSun(宋体)。如果电脑里没有这些字体,程序会提示未检测到字体,但通常不影响绘图,只是最终字体可能被系统自动替换。正式投稿或排版前,建议检查图片中的中英文和负号是否显示正常。
第二,显著性字母的自动分配适合常规分组比较图,但它本质上仍然依赖统计假设。若数据严重偏态、样本量极小,或实验设计存在配对、重复测量、嵌套结构等情况,就不应直接套用普通两两 t 检验,而需要根据研究设计选择更合适的统计模型。
第三,箱线图不是为了追求“好看”,而是为了真实表达数据。散点分布、箱体高度和显著性字母应该共同解读。不要只盯着 p 值,也要观察组内离散程度是否过大、样本数量是否不足、个别点是否对结果产生明显影响。
不同配色效果展示:
完整代码获取:回复“ 箱线图01”即可获得通道
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
